 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Sub-Layered Hierarchical Pyramidal Neural Architecture for Facial Expression Recognition
Mar 23, 2021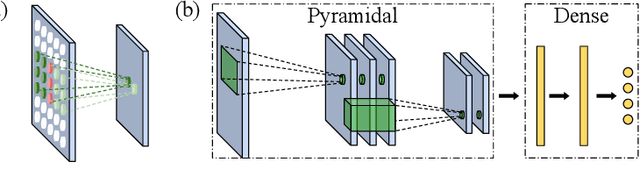

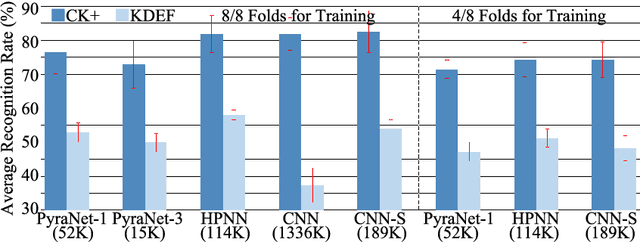

In domains where computational resources and labeled data are limited, such as in robotics, deep networks with millions of weights might not be the optimal solution. In this paper, we introduce a connectivity scheme for pyramidal architectures to increase their capacity for learning features. Experiments on facial expression recognition of unseen people demonstrate that our approach is a potential candidate for applications with restricted resources, due to good generalization performance and low computational cost. We show that our approach generalizes as well as convolutional architectures in this task but uses fewer trainable parameters and is more robust for low-resolution faces.
Improving Model-Based Reinforcement Learning with Internal State Representations through Self-Supervision
Feb 10, 2021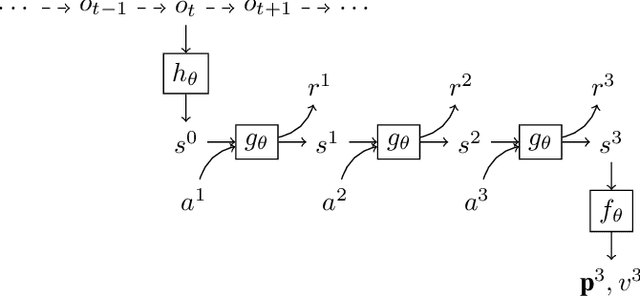
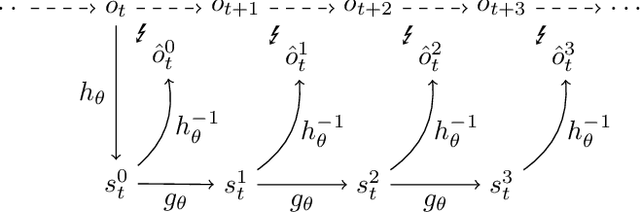
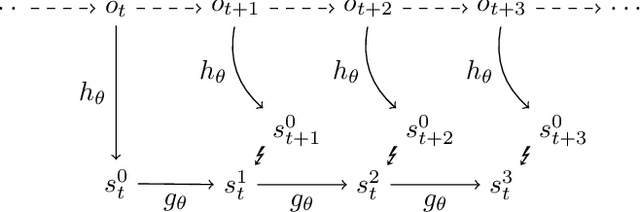
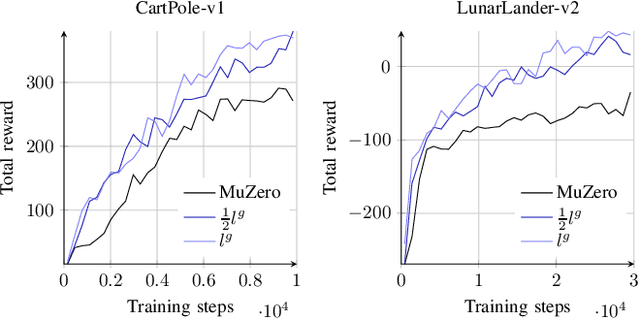
Using a model of the environment, reinforcement learning agents can plan their future moves and achieve superhuman performance in board games like Chess, Shogi, and Go, while remaining relatively sample-efficient. As demonstrated by the MuZero Algorithm, the environment model can even be learned dynamically, generalizing the agent to many more tasks while at the same time achieving state-of-the-art performance. Notably, MuZero uses internal state representations derived from real environment states for its predictions. In this paper, we bind the model's predicted internal state representation to the environment state via two additional terms: a reconstruction model loss and a simpler consistency loss, both of which work independently and unsupervised, acting as constraints to stabilize the learning process. Our experiments show that this new integration of reconstruction model loss and simpler consistency loss provide a significant performance increase in OpenAI Gym environments. Our modifications also enable self-supervised pretraining for MuZero, so the algorithm can learn about environment dynamics before a goal is made available.
Crossmodal Language Grounding in an Embodied Neurocognitive Model
Jun 24, 2020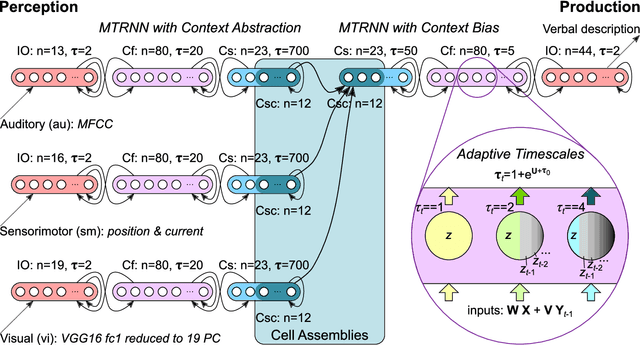

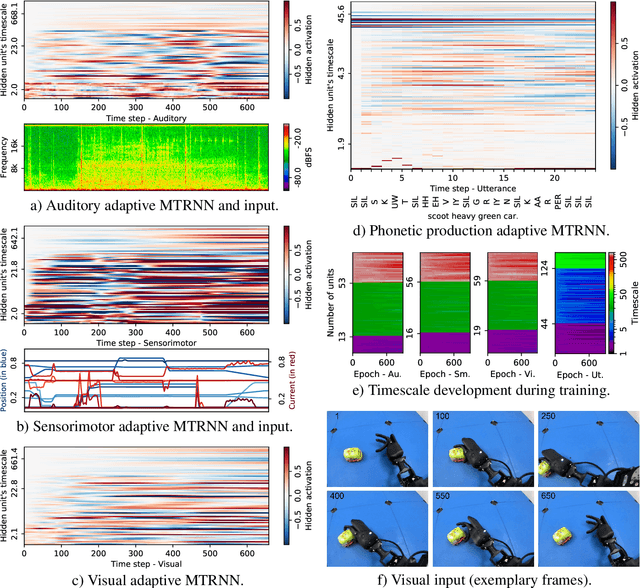
Human infants are able to acquire natural language seemingly easily at an early age. Their language learning seems to occur simultaneously with learning other cognitive functions as well as with playful interactions with the environment and caregivers. From a neuroscientific perspective, natural language is embodied, grounded in most, if not all, sensory and sensorimotor modalities, and acquired by means of crossmodal integration. However, characterising the underlying mechanisms in the brain is difficult and explaining the grounding of language in crossmodal perception and action remains challenging. In this paper, we present a neurocognitive model for language grounding which reflects bio-inspired mechanisms such as an implicit adaptation of timescales as well as end-to-end multimodal abstraction. It addresses developmental robotic interaction and extends its learning capabilities using larger-scale knowledge-based data. In our scenario, we utilise the humanoid robot NICO in obtaining the EMIL data collection, in which the cognitive robot interacts with objects in a children's playground environment while receiving linguistic labels from a caregiver. The model analysis shows that crossmodally integrated representations are sufficient for acquiring language merely from sensory input through interaction with objects in an environment. The representations self-organise hierarchically and embed temporal and spatial information through composition and decomposition. This model can also provide the basis for further crossmodal integration of perceptually grounded cognitive representations.
Improving Robot Dual-System Motor Learning with Intrinsically Motivated Meta-Control and Latent-Space Experience Imagination
Apr 19, 2020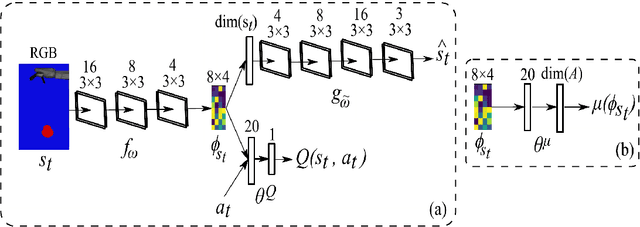
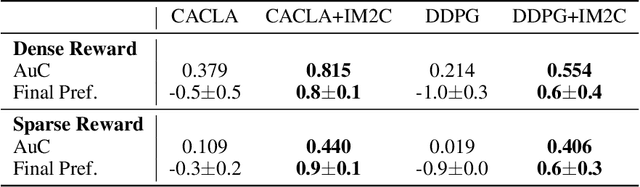
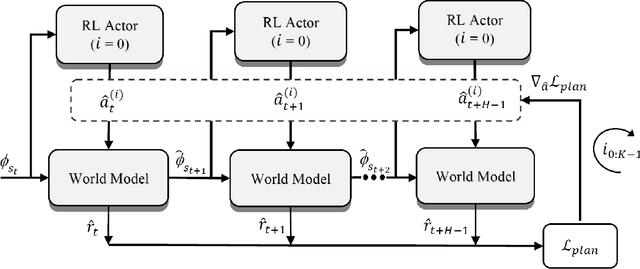

Combining model-based and model-free learning systems has been shown to improve the sample efficiency of learning to perform complex robotic tasks. However, dual-system approaches fail to consider the reliability of the learned model when it is applied to make multiple-step predictions, resulting in a compounding of prediction errors and performance degradation. In this paper, we present a novel dual-system motor learning approach where a meta-controller arbitrates online between model-based and model-free decisions based on an estimate of the local reliability of the learned model. The reliability estimate is used in computing an intrinsic feedback signal, encouraging actions that lead to data that improves the model. Our approach also integrates arbitration with imagination where a learned latent-space model generates imagined experiences, based on its local reliability, to be used as additional training data. We evaluate our approach against baseline and state-of-the-art methods on learning vision-based robotic grasping in simulation and real world. The results show that our approach outperforms the compared methods and learns near-optimal grasping policies in dense- and sparse-reward environments.
Enriching Existing Conversational Emotion Datasets with Dialogue Acts using Neural Annotators
Dec 05, 2019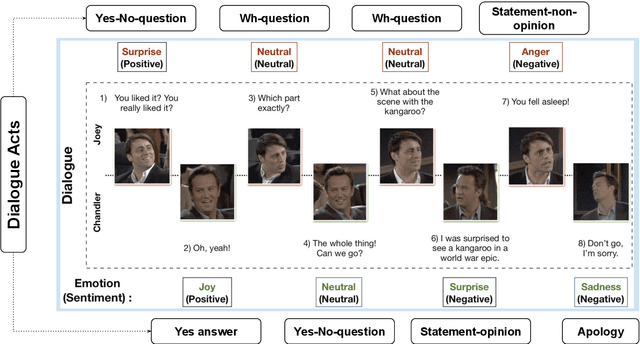

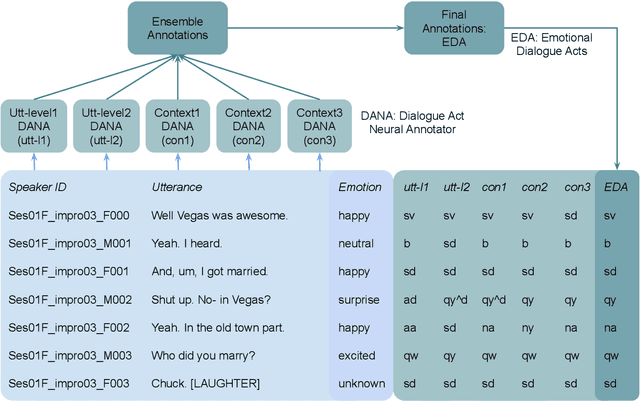
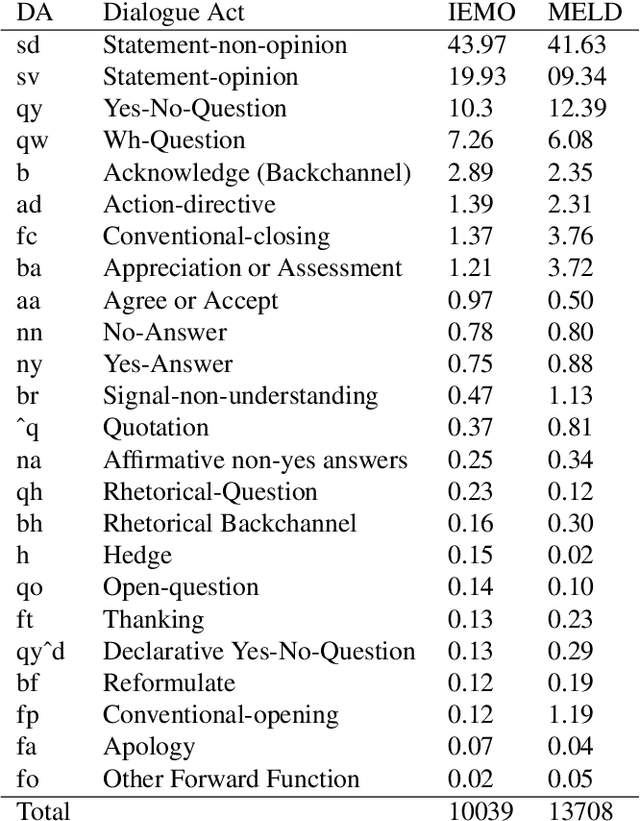
The recognition of emotion and dialogue acts enrich conversational analysis and help to build natural dialogue systems. Emotion makes us understand feelings and dialogue acts reflect the intentions and performative functions in the utterances. However, most of the textual and multi-modal conversational emotion datasets contain only emotion labels but not dialogue acts. To address this problem, we propose to use a pool of various recurrent neural models trained on a dialogue act corpus, with or without context. These neural models annotate the emotion corpus with dialogue act labels and an ensemble annotator extracts the final dialogue act label. We annotated two popular multi-modal emotion datasets: IEMOCAP and MELD. We analysed the co-occurrence of emotion and dialogue act labels and discovered specific relations. For example, Accept/Agree dialogue acts often occur with the Joy emotion, Apology with Sadness, and Thanking with Joy. We make the Emotional Dialogue Act (EDA) corpus publicly available to the research community for further study and analysis.
Periodic Spectral Ergodicity: A Complexity Measure for Deep Neural Networks and Neural Architecture Search
Nov 10, 2019
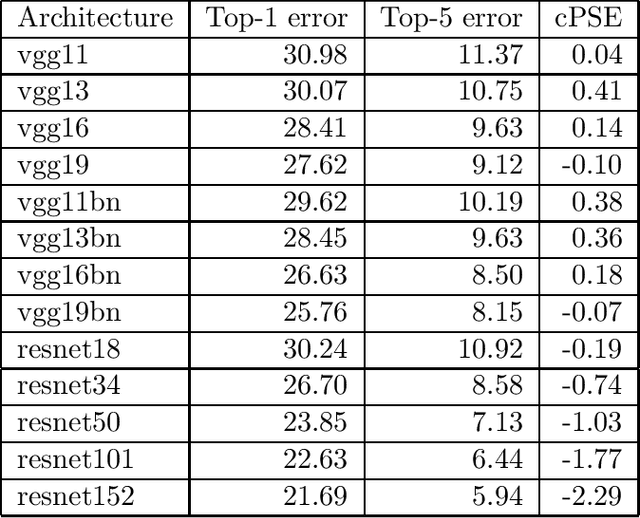
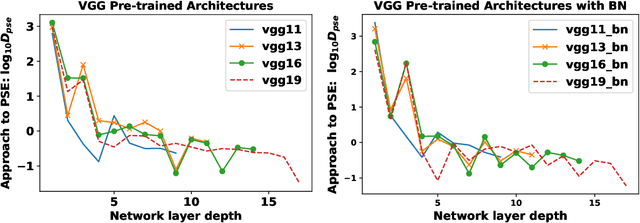
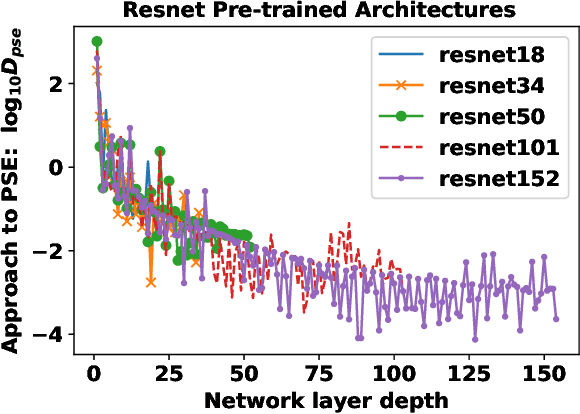
Establishing associations between the structure and the learning ability of deep neural networks (DNNs) is a challenging task in modern machine learning. Producing solutions to this challenge will bring progress both in the theoretical understanding of DNNs and in building new architectures efficiently. In this work, we address this challenge by developing a new simple complexity measure based on another new measure called Periodic Spectral Ergodicity (PSE) originating from quantum statistical mechanics. Based on this measure a framework is devised in quantifying the complexity of deep neural network from its learned weights and traversing network connectivity in a sequential manner, hence the term cascading PSE (cPSE) as an empirical complexity measure. Because of this cascading approach, i.e., a symmetric divergence of PSE on the consecutive layers, it is possible to use this measure in addition for Neural Architecture Search (NAS). We demonstrate the usefulness of this measure in practice on two sets of vision models, ResNet and VGG and sketch the computation of cPSE for more complex network structures.
Efficient Intrinsically Motivated Robotic Grasping with Learning-Adaptive Imagination in Latent Space
Oct 10, 2019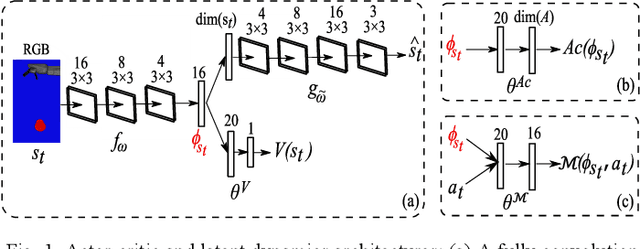
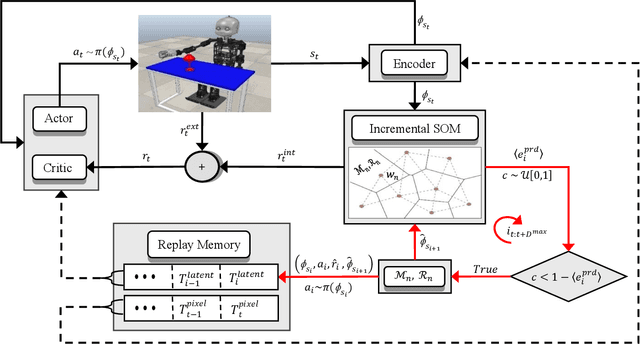
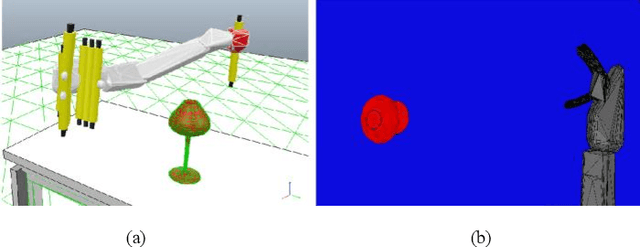
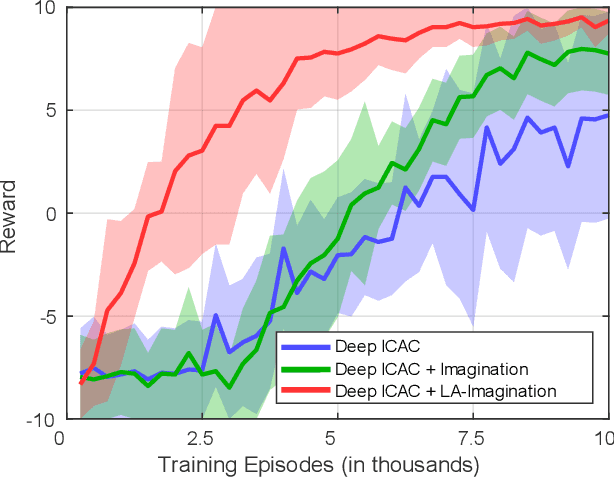
Combining model-based and model-free deep reinforcement learning has shown great promise for improving sample efficiency on complex control tasks while still retaining high performance. Incorporating imagination is a recent effort in this direction inspired by human mental simulation of motor behavior. We propose a learning-adaptive imagination approach which, unlike previous approaches, takes into account the reliability of the learned dynamics model used for imagining the future. Our approach learns an ensemble of disjoint local dynamics models in latent space and derives an intrinsic reward based on learning progress, motivating the controller to take actions leading to data that improves the models. The learned models are used to generate imagined experiences, augmenting the training set of real experiences. We evaluate our approach on learning vision-based robotic grasping and show that it significantly improves sample efficiency and achieves near-optimal performance in a sparse reward environment.
What can computational models learn from human selective attention? A review from an audiovisual crossmodal perspective
Sep 05, 2019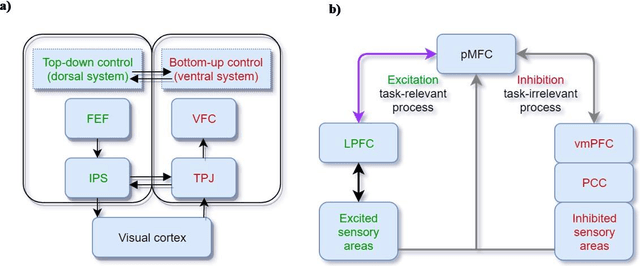

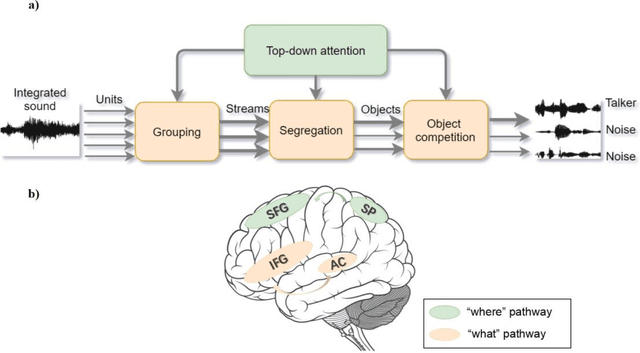
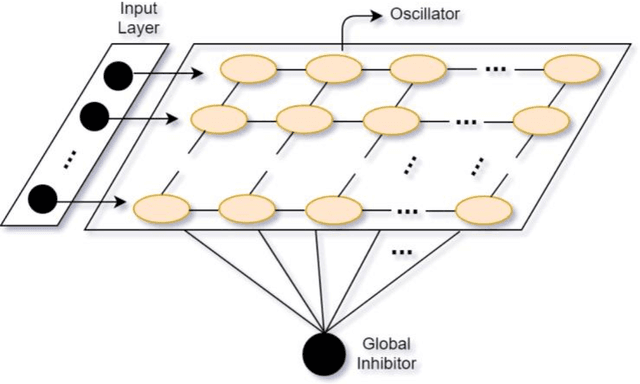
Selective attention plays an essential role in information acquisition and utilization from the environment. In the past 50 years, research on selective attention has been a central topic in cognitive science. Compared with unimodal studies, crossmodal studies are more complex but necessary to solve real-world challenges in both human experiments and computational modeling. Although an increasing number of findings on crossmodal selective attention have shed light on humans' behavioral patterns and neural underpinnings, a much better understanding is still necessary to yield the same benefit for computational intelligent agents. This article reviews studies of selective attention in unimodal visual and auditory and crossmodal audiovisual setups from the multidisciplinary perspectives of psychology and cognitive neuroscience, and evaluates different ways to simulate analogous mechanisms in computational models and robotics. We discuss the gaps between these fields in this interdisciplinary review and provide insights about how to use psychological findings and theories in artificial intelligence from different perspectives.
Curious Meta-Controller: Adaptive Alternation between Model-Based and Model-Free Control in Deep Reinforcement Learning
May 05, 2019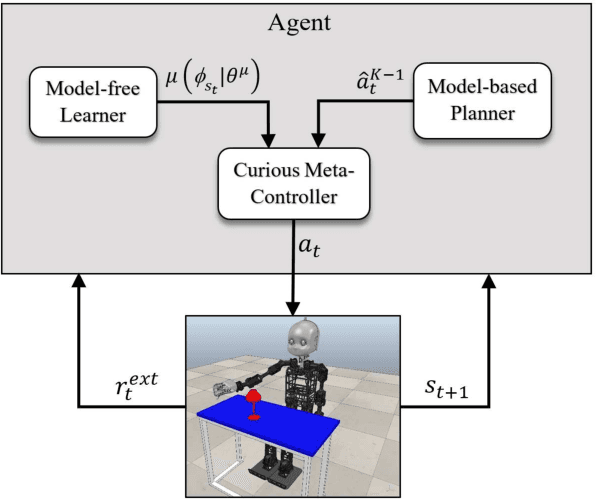
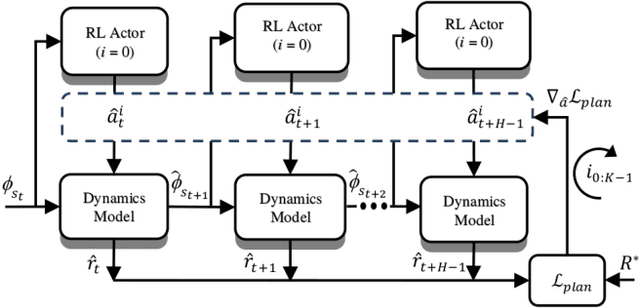
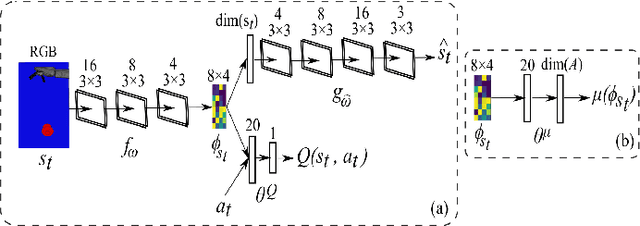

Recent success in deep reinforcement learning for continuous control has been dominated by model-free approaches which, unlike model-based approaches, do not suffer from representational limitations in making assumptions about the world dynamics and model errors inevitable in complex domains. However, they require a lot of experiences compared to model-based approaches that are typically more sample-efficient. We propose to combine the benefits of the two approaches by presenting an integrated approach called Curious Meta-Controller. Our approach alternates adaptively between model-based and model-free control using a curiosity feedback based on the learning progress of a neural model of the dynamics in a learned latent space. We demonstrate that our approach can significantly improve the sample efficiency and achieve near-optimal performance on learning robotic reaching and grasping tasks from raw-pixel input in both dense and sparse reward settings.
KT-Speech-Crawler: Automatic Dataset Construction for Speech Recognition from YouTube Videos
Mar 01, 2019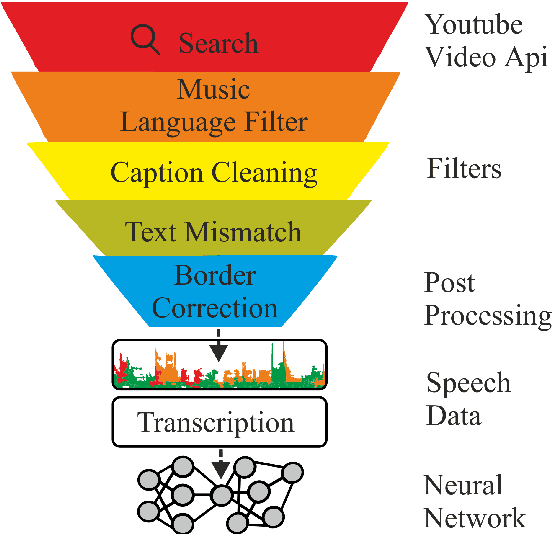
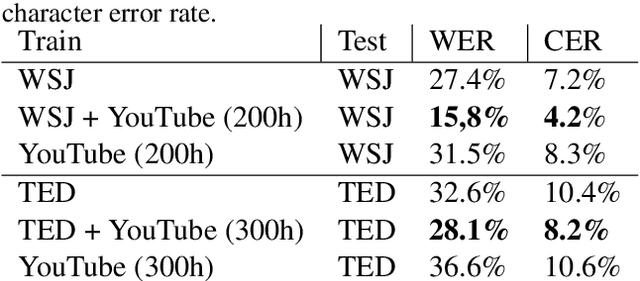
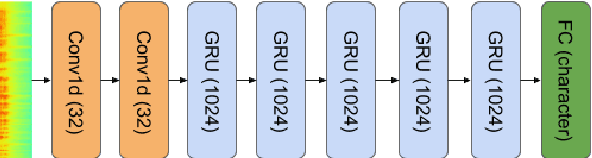
In this paper, we describe KT-Speech-Crawler: an approach for automatic dataset construction for speech recognition by crawling YouTube videos. We outline several filtering and post-processing steps, which extract samples that can be used for training end-to-end neural speech recognition systems. In our experiments, we demonstrate that a single-core version of the crawler can obtain around 150 hours of transcribed speech within a day, containing an estimated 3.5% word error rate in the transcriptions. Automatically collected samples contain reading and spontaneous speech recorded in various conditions including background noise and music, distant microphone recordings, and a variety of accents and reverberation. When training a deep neural network on speech recognition, we observed around 40\% word error rate reduction on the Wall Street Journal dataset by integrating 200 hours of the collected samples into the training set. The demo (http://emnlp-demo.lakomkin.me/) and the crawler code (https://github.com/EgorLakomkin/KTSpeechCrawler) are publicly available.