 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemory-Efficient Incremental Learning Through Feature Adaptation
Apr 01, 2020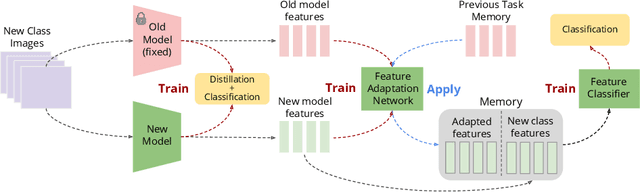
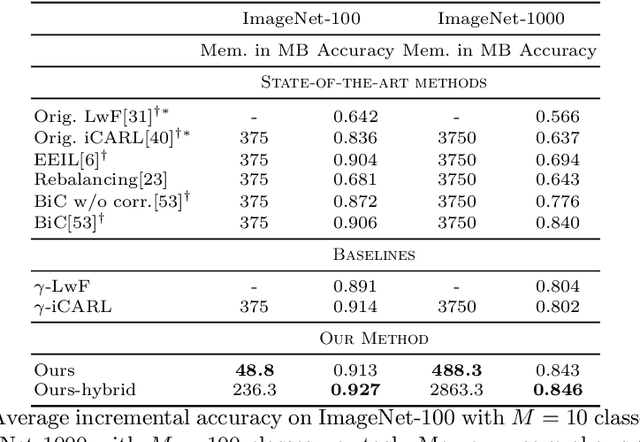
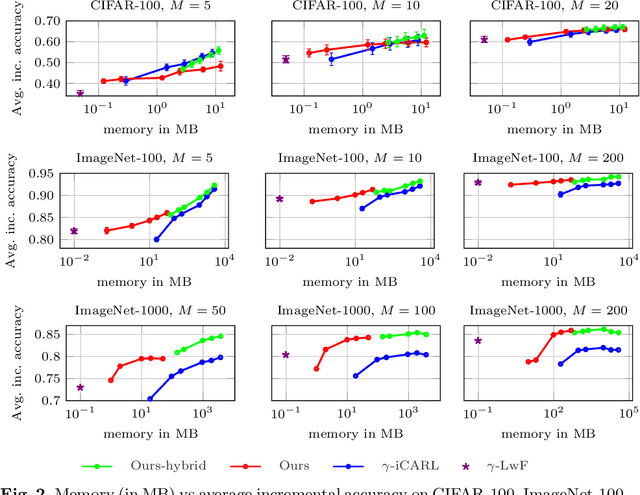
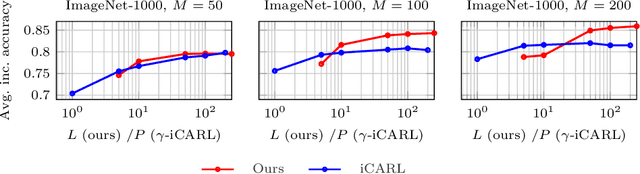
In this work we introduce an approach for incremental learning, which preserves feature descriptors instead of images unlike most existing work. Keeping such low-dimensional embeddings instead of images reduces the memory footprint significantly. We assume that the model is updated incrementally for new classes as new data becomes available sequentially. This requires adapting the previously stored feature vectors to the updated feature space without having access to the corresponding images. Feature adaptation is learned with a multi-layer perceptron, which is trained on feature pairs of an image corresponding to the outputs of the original and updated network. We validate experimentally that such a transformation generalizes well to the features of the previous set of classes, and maps features to a discriminative subspace in the feature space. As a result, the classifier is optimized jointly over new and old classes without requiring old class images. Experimental results show that our method achieves state-of-the-art classification accuracy in incremental learning benchmarks, while having at least an order of magnitude lower memory footprint compared to image preserving strategies.
Speech2Action: Cross-modal Supervision for Action Recognition
Mar 30, 2020

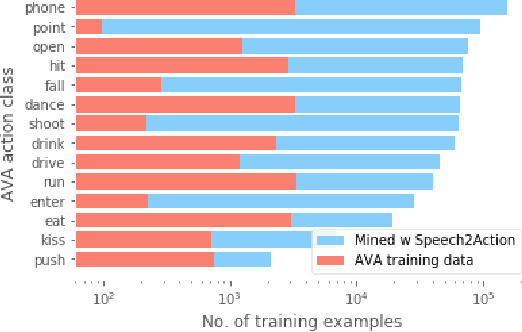
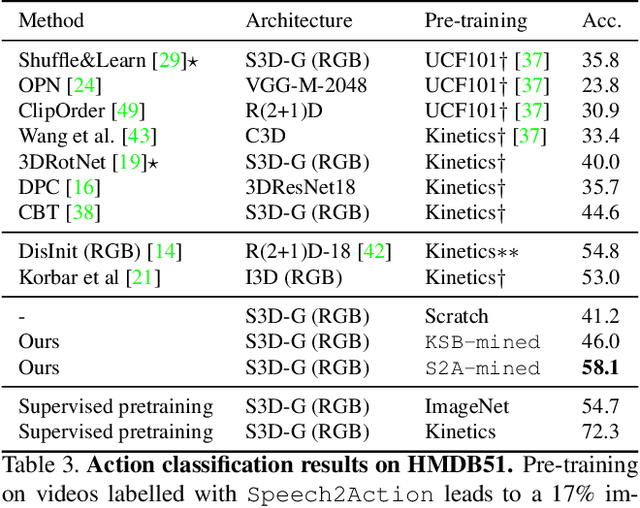
Is it possible to guess human action from dialogue alone? In this work we investigate the link between spoken words and actions in movies. We note that movie screenplays describe actions, as well as contain the speech of characters and hence can be used to learn this correlation with no additional supervision. We train a BERT-based Speech2Action classifier on over a thousand movie screenplays, to predict action labels from transcribed speech segments. We then apply this model to the speech segments of a large unlabelled movie corpus (188M speech segments from 288K movies). Using the predictions of this model, we obtain weak action labels for over 800K video clips. By training on these video clips, we demonstrate superior action recognition performance on standard action recognition benchmarks, without using a single manually labelled action example.
Selecting Relevant Features from a Universal Representation for Few-shot Classification
Mar 20, 2020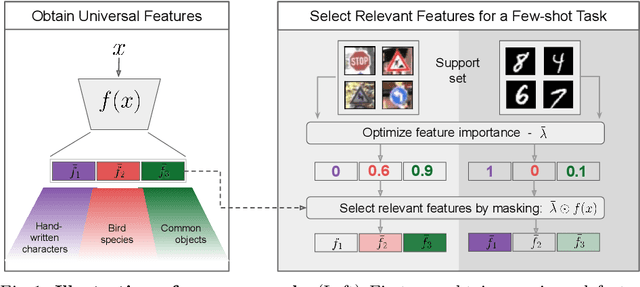
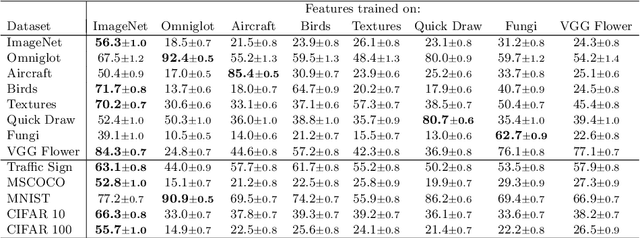
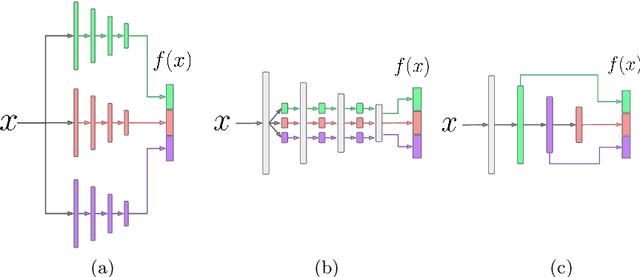
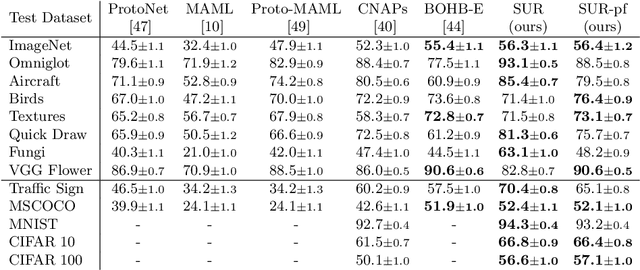
Popular approaches for few-shot classification consist of first learning a generic data representation based on a large annotated dataset, before adapting the representation to new classes given only a few labeled samples. In this work, we propose a new strategy based on feature selection, which is both simpler and more effective than previous feature adaptation approaches. First, we obtain a universal representation by training a set of semantically different feature extractors. Then, given a few-shot learning task, we use our universal feature bank to automatically select the most relevant representations. We show that a simple non-parametric classifier built on top of such features produces high accuracy and generalizes to domains never seen during training, which leads to state-of-the-art results on MetaDataset and improved accuracy on mini-ImageNet.
Beyond the Camera: Neural Networks in World Coordinates
Mar 12, 2020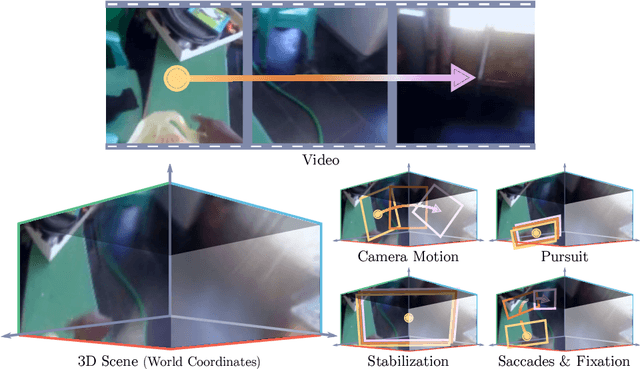
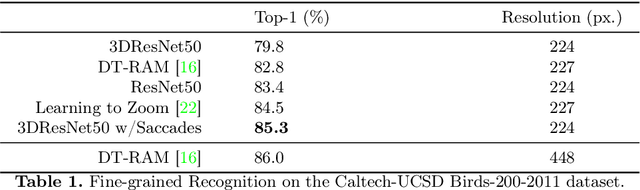
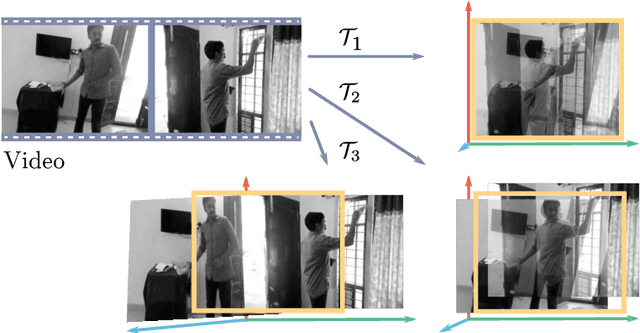

Eye movement and strategic placement of the visual field onto the retina, gives animals increased resolution of the scene and suppresses distracting information. This fundamental system has been missing from video understanding with deep networks, typically limited to 224 by 224 pixel content locked to the camera frame. We propose a simple idea, WorldFeatures, where each feature at every layer has a spatial transformation, and the feature map is only transformed as needed. We show that a network built with these WorldFeatures, can be used to model eye movements, such as saccades, fixation, and smooth pursuit, even in a batch setting on pre-recorded video. That is, the network can for example use all 224 by 224 pixels to look at a small detail one moment, and the whole scene the next. We show that typical building blocks, such as convolutions and pooling, can be adapted to support WorldFeatures using available tools. Experiments are presented on the Charades, Olympic Sports, and Caltech-UCSD Birds-200-2011 datasets, exploring action recognition, fine-grained recognition, and video stabilization.
Radioactive data: tracing through training
Feb 03, 2020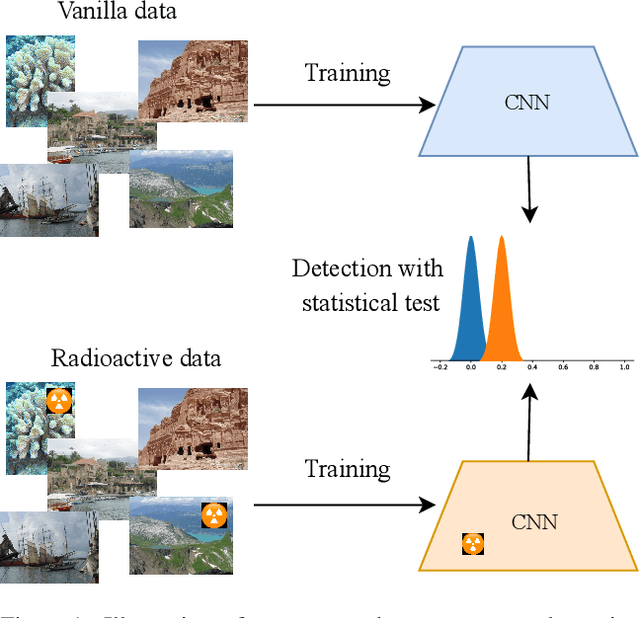
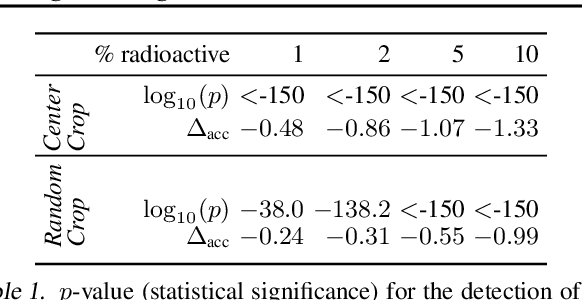
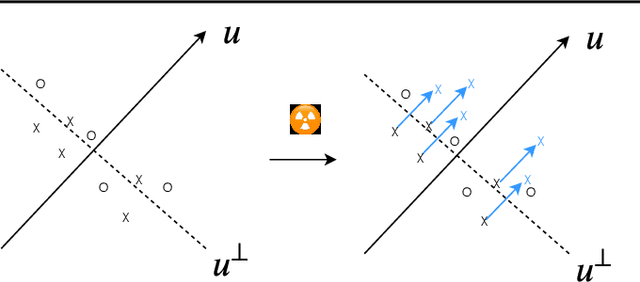
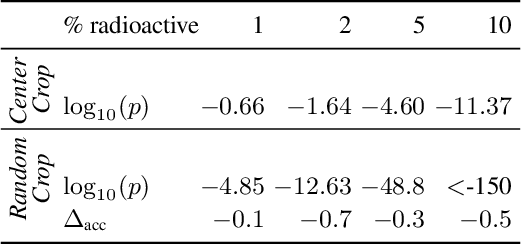
We want to detect whether a particular image dataset has been used to train a model. We propose a new technique, \emph{radioactive data}, that makes imperceptible changes to this dataset such that any model trained on it will bear an identifiable mark. The mark is robust to strong variations such as different architectures or optimization methods. Given a trained model, our technique detects the use of radioactive data and provides a level of confidence (p-value). Our experiments on large-scale benchmarks (Imagenet), using standard architectures (Resnet-18, VGG-16, Densenet-121) and training procedures, show that we can detect usage of radioactive data with high confidence (p<10^-4) even when only 1% of the data used to trained our model is radioactive. Our method is robust to data augmentation and the stochasticity of deep network optimization. As a result, it offers a much higher signal-to-noise ratio than data poisoning and backdoor methods.
Optimized Generic Feature Learning for Few-shot Classification across Domains
Jan 22, 2020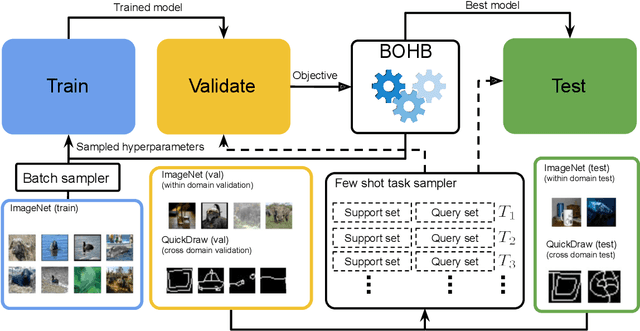

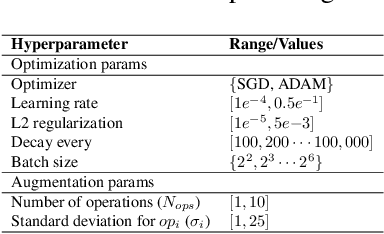
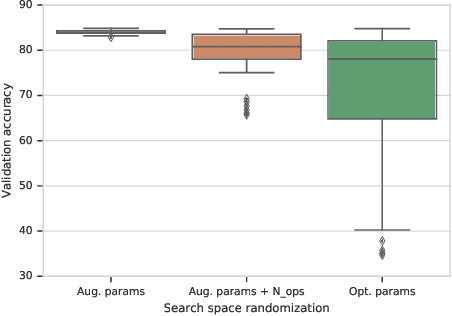
To learn models or features that generalize across tasks and domains is one of the grand goals of machine learning. In this paper, we propose to use cross-domain, cross-task data as validation objective for hyper-parameter optimization (HPO) to improve on this goal. Given a rich enough search space, optimization of hyper-parameters learn features that maximize validation performance and, due to the objective, generalize across tasks and domains. We demonstrate the effectiveness of this strategy on few-shot image classification within and across domains. The learned features outperform all previous few-shot and meta-learning approaches.
Synthetic Humans for Action Recognition from Unseen Viewpoints
Dec 09, 2019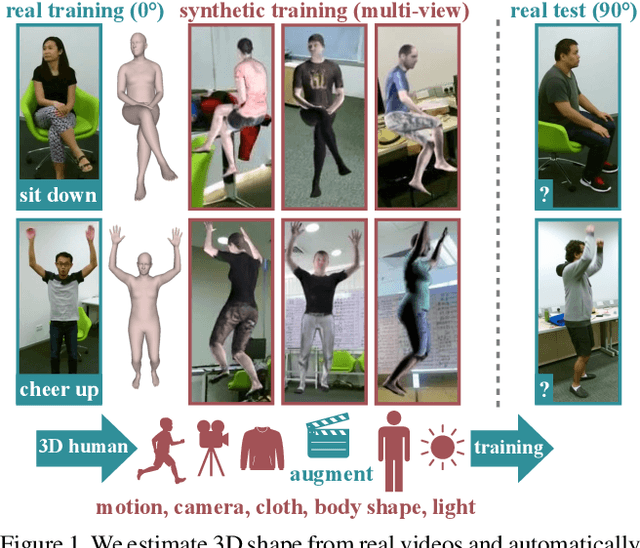
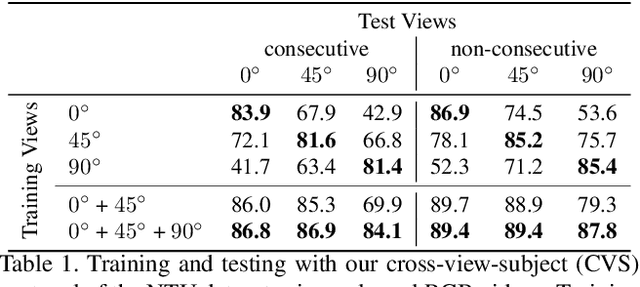

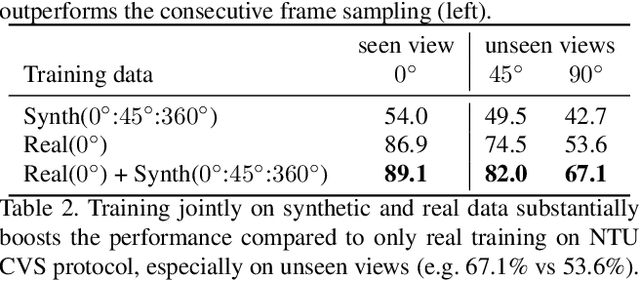
Our goal in this work is to improve the performance of human action recognition for viewpoints unseen during training by using synthetic training data. Although synthetic data has been shown to be beneficial for tasks such as human pose estimation, its use for RGB human action recognition is relatively unexplored. We make use of the recent advances in monocular 3D human body reconstruction from real action sequences to automatically render synthetic training videos for the action labels. We make the following contributions: (i) we investigate the extent of variations and augmentations that are beneficial to improving performance at new viewpoints. We consider changes in body shape and clothing for individuals, as well as more action relevant augmentations such as non-uniform frame sampling, and interpolating between the motion of individuals performing the same action; (ii) We introduce a new dataset, SURREACT, that allows supervised training of spatio-temporal CNNs for action classification; (iii) We substantially improve the state-of-the-art action recognition performance on the NTU RGB+D and UESTC standard human action multi-view benchmarks; Finally, (iv) we extend the augmentation approach to in-the-wild videos from a subset of the Kinetics dataset to investigate the case when only one-shot training data is available, and demonstrate improvements in this case as well.
Learning to Track Any Object
Oct 25, 2019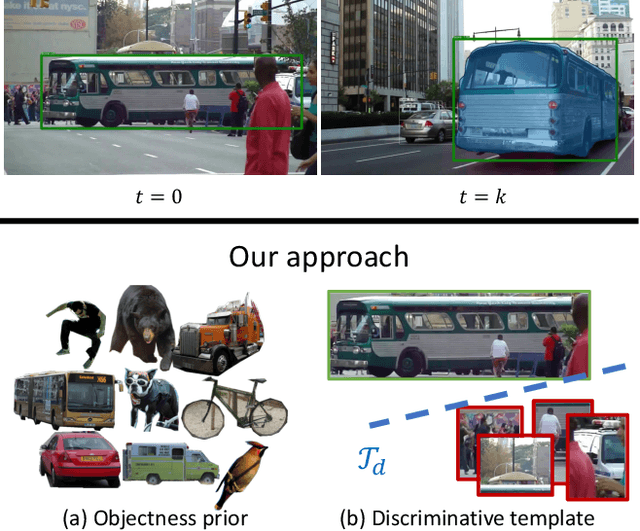
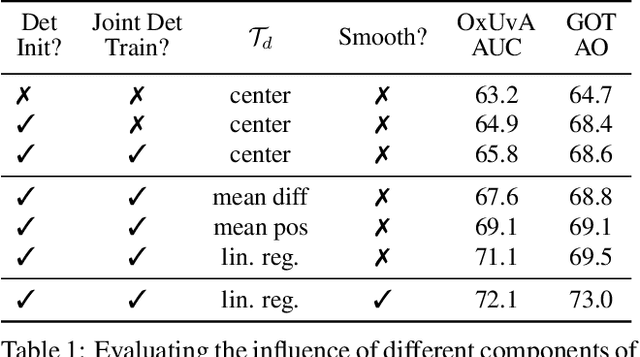
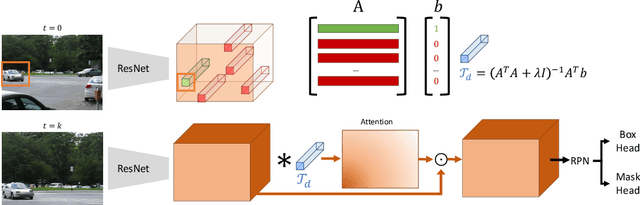
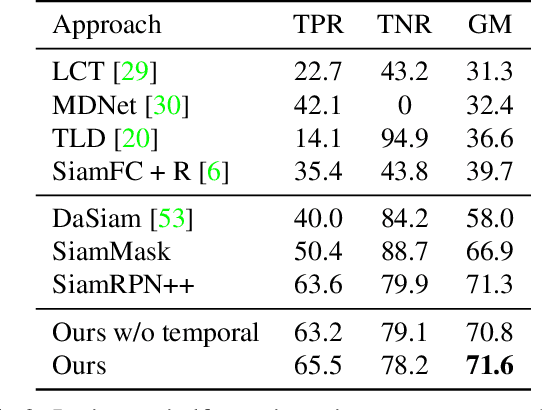
Object tracking can be formulated as "finding the right object in a video". We observe that recent approaches for class-agnostic tracking tend to focus on the "finding" part, but largely overlook the "object" part of the task, essentially doing a template matching over a frame in a sliding-window. In contrast, class-specific trackers heavily rely on object priors in the form of category-specific object detectors. In this work, we re-purpose category-specific appearance models into a generic objectness prior. Our approach converts a category-specific object detector into a category-agnostic, object-specific detector (i.e. a tracker) efficiently, on the fly. Moreover, at test time the same network can be applied to detection and tracking, resulting in a unified approach for the two tasks. We achieve state-of-the-art results on two recent large-scale tracking benchmarks (OxUvA and GOT, using external data). By simply adding a mask prediction branch, our approach is able to produce instance segmentation masks for the tracked object. Despite only using box-level information on the first frame, our method outputs high-quality masks, as evaluated on the DAVIS '17 video object segmentation benchmark.
Graph convolutional networks for learning with few clean and many noisy labels
Oct 01, 2019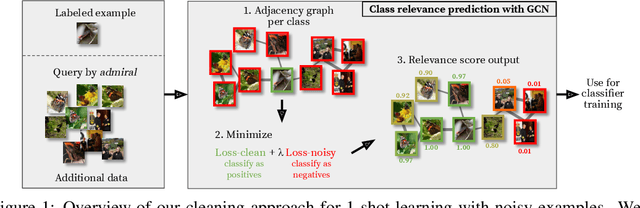
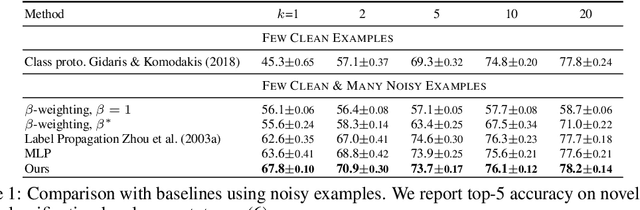

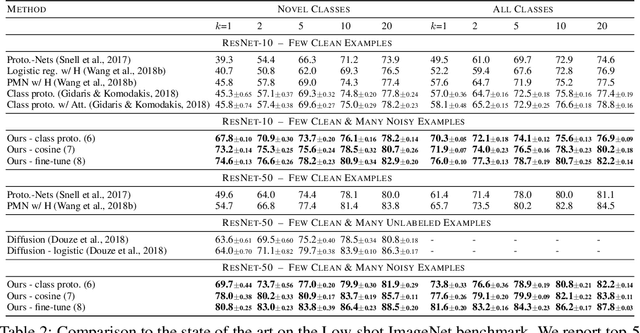
In this work we consider the problem of learning a classifier from noisy labels when a few clean labeled examples are given. The structure of clean and noisy data is modeled by a graph per class and Graph Convolutional Networks (GCN) are used to predict class relevance of noisy examples. For each class, the GCN is treated as a binary classifier learning to discriminate clean from noisy examples using a weighted binary cross-entropy loss function, and then the GCN-inferred "clean" probability is exploited as a relevance measure. Each noisy example is weighted by its relevance when learning a classifier for the end task. We evaluate our method on an extended version of a few-shot learning problem, where the few clean examples of novel classes are supplemented with additional noisy data. Experimental results show that our GCN-based cleaning process significantly improves the classification accuracy over not cleaning the noisy data and standard few-shot classification where only few clean examples are used. The proposed GCN-based method outperforms the transductive approach (Douze et al., 2018) that is using the same additional data without labels.
White-box vs Black-box: Bayes Optimal Strategies for Membership Inference
Aug 29, 2019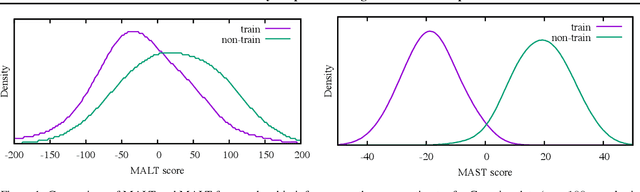
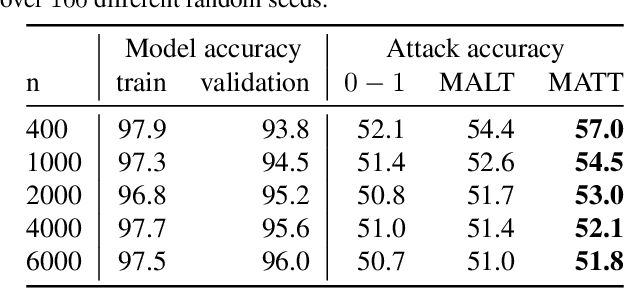

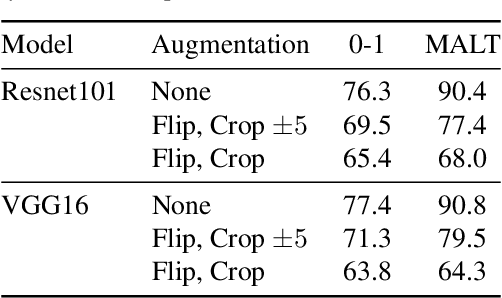
Membership inference determines, given a sample and trained parameters of a machine learning model, whether the sample was part of the training set. In this paper, we derive the optimal strategy for membership inference with a few assumptions on the distribution of the parameters. We show that optimal attacks only depend on the loss function, and thus black-box attacks are as good as white-box attacks. As the optimal strategy is not tractable, we provide approximations of it leading to several inference methods, and show that existing membership inference methods are coarser approximations of this optimal strategy. Our membership attacks outperform the state of the art in various settings, ranging from a simple logistic regression to more complex architectures and datasets, such as ResNet-101 and Imagenet.