 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImage super-resolution via dynamic network
Oct 16, 2023



Convolutional neural networks (CNNs) depend on deep network architectures to extract accurate information for image super-resolution. However, obtained information of these CNNs cannot completely express predicted high-quality images for complex scenes. In this paper, we present a dynamic network for image super-resolution (DSRNet), which contains a residual enhancement block, wide enhancement block, feature refinement block and construction block. The residual enhancement block is composed of a residual enhanced architecture to facilitate hierarchical features for image super-resolution. To enhance robustness of obtained super-resolution model for complex scenes, a wide enhancement block achieves a dynamic architecture to learn more robust information to enhance applicability of an obtained super-resolution model for varying scenes. To prevent interference of components in a wide enhancement block, a refinement block utilizes a stacked architecture to accurately learn obtained features. Also, a residual learning operation is embedded in the refinement block to prevent long-term dependency problem. Finally, a construction block is responsible for reconstructing high-quality images. Designed heterogeneous architecture can not only facilitate richer structural information, but also be lightweight, which is suitable for mobile digital devices. Experimental results shows that our method is more competitive in terms of performance and recovering time of image super-resolution and complexity. The code of DSRNet can be obtained at https://github.com/hellloxiaotian/DSRNet.
A Distributed Computation Model Based on Federated Learning Integrates Heterogeneous models and Consortium Blockchain for Solving Time-Varying Problems
Jun 28, 2023The recurrent neural network has been greatly developed for effectively solving time-varying problems corresponding to complex environments. However, limited by the way of centralized processing, the model performance is greatly affected by factors like the silos problems of the models and data in reality. Therefore, the emergence of distributed artificial intelligence such as federated learning (FL) makes it possible for the dynamic aggregation among models. However, the integration process of FL is still server-dependent, which may cause a great risk to the overall model. Also, it only allows collaboration between homogeneous models, and does not have a good solution for the interaction between heterogeneous models. Therefore, we propose a Distributed Computation Model (DCM) based on the consortium blockchain network to improve the credibility of the overall model and effective coordination among heterogeneous models. In addition, a Distributed Hierarchical Integration (DHI) algorithm is also designed for the global solution process. Within a group, permissioned nodes collect the local models' results from different permissionless nodes and then sends the aggregated results back to all the permissionless nodes to regularize the processing of the local models. After the iteration is completed, the secondary integration of the local results will be performed between permission nodes to obtain the global results. In the experiments, we verify the efficiency of DCM, where the results show that the proposed model outperforms many state-of-the-art models based on a federated learning framework.
Multi-stage image denoising with the wavelet transform
Oct 03, 2022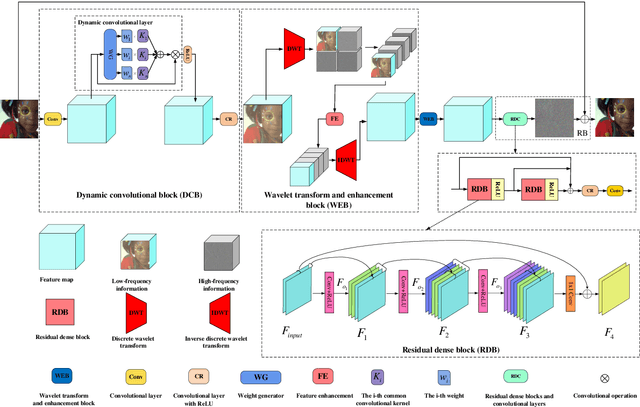
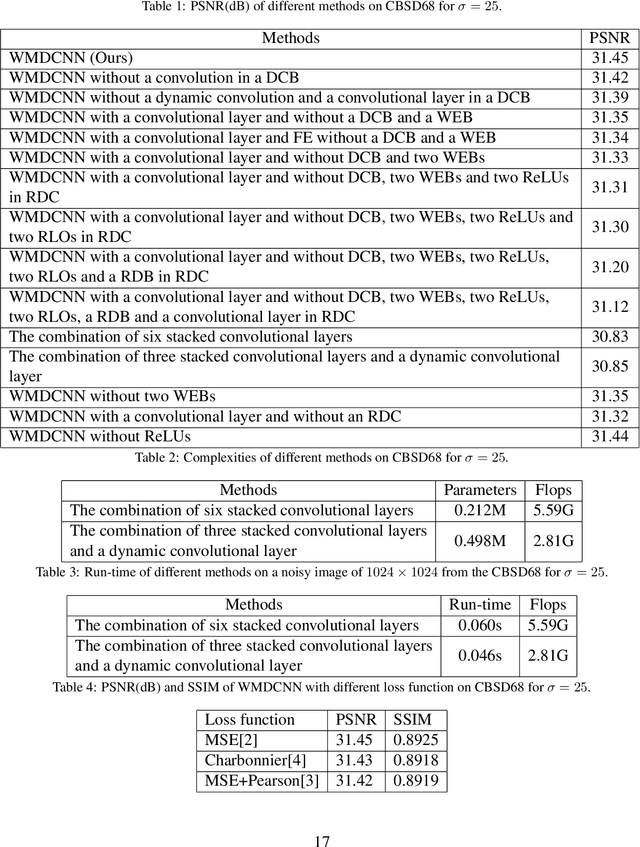
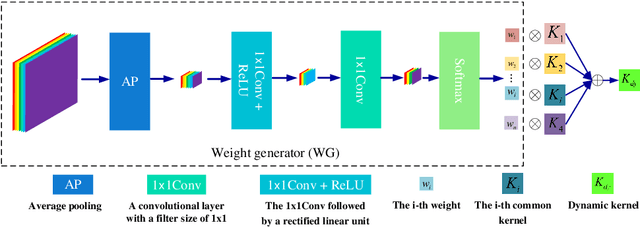
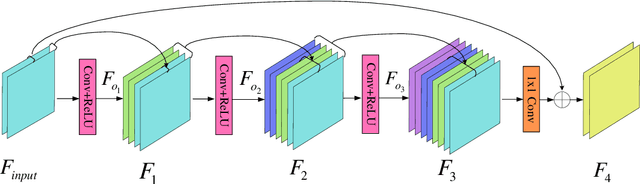
Deep convolutional neural networks (CNNs) are used for image denoising via automatically mining accurate structure information. However, most of existing CNNs depend on enlarging depth of designed networks to obtain better denoising performance, which may cause training difficulty. In this paper, we propose a multi-stage image denoising CNN with the wavelet transform (MWDCNN) via three stages, i.e., a dynamic convolutional block (DCB), two cascaded wavelet transform and enhancement blocks (WEBs) and a residual block (RB). DCB uses a dynamic convolution to dynamically adjust parameters of several convolutions for making a tradeoff between denoising performance and computational costs. WEB uses a combination of signal processing technique (i.e., wavelet transformation) and discriminative learning to suppress noise for recovering more detailed information in image denoising. To further remove redundant features, RB is used to refine obtained features for improving denoising effects and reconstruct clean images via improved residual dense architectures. Experimental results show that the proposed MWDCNN outperforms some popular denoising methods in terms of quantitative and qualitative analysis. Codes are available at https://github.com/hellloxiaotian/MWDCNN.
A heterogeneous group CNN for image super-resolution
Sep 26, 2022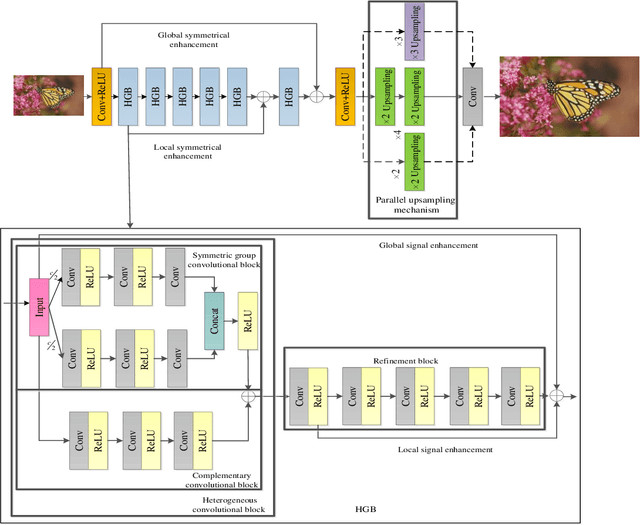


Convolutional neural networks (CNNs) have obtained remarkable performance via deep architectures. However, these CNNs often achieve poor robustness for image super-resolution (SR) under complex scenes. In this paper, we present a heterogeneous group SR CNN (HGSRCNN) via leveraging structure information of different types to obtain a high-quality image. Specifically, each heterogeneous group block (HGB) of HGSRCNN uses a heterogeneous architecture containing a symmetric group convolutional block and a complementary convolutional block in a parallel way to enhance internal and external relations of different channels for facilitating richer low-frequency structure information of different types. To prevent appearance of obtained redundant features, a refinement block with signal enhancements in a serial way is designed to filter useless information. To prevent loss of original information, a multi-level enhancement mechanism guides a CNN to achieve a symmetric architecture for promoting expressive ability of HGSRCNN. Besides, a parallel up-sampling mechanism is developed to train a blind SR model. Extensive experiments illustrate that the proposed HGSRCNN has obtained excellent SR performance in terms of both quantitative and qualitative analysis. Codes can be accessed at https://github.com/hellloxiaotian/HGSRCNN.
Image Super-resolution with An Enhanced Group Convolutional Neural Network
May 29, 2022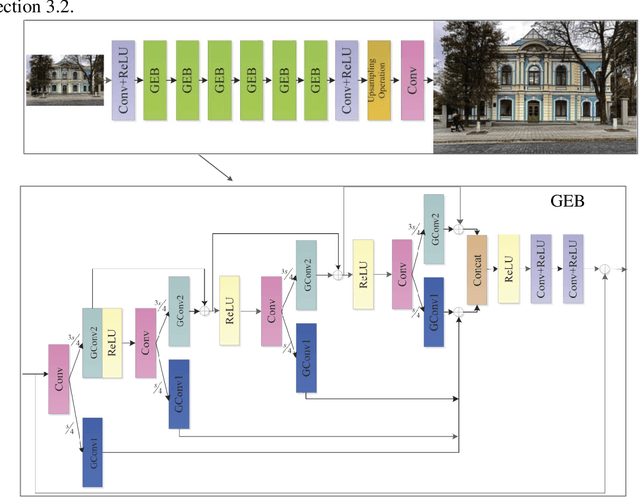

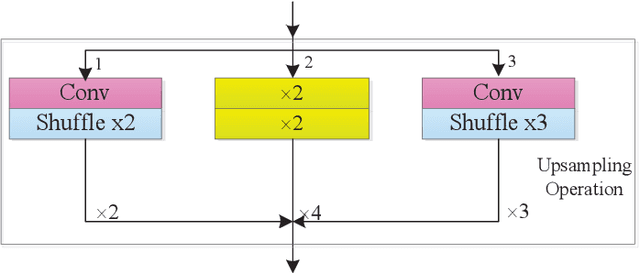
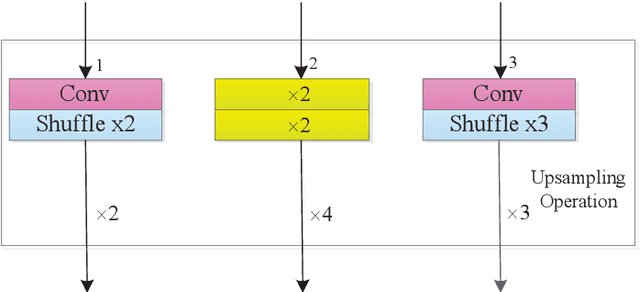
CNNs with strong learning abilities are widely chosen to resolve super-resolution problem. However, CNNs depend on deeper network architectures to improve performance of image super-resolution, which may increase computational cost in general. In this paper, we present an enhanced super-resolution group CNN (ESRGCNN) with a shallow architecture by fully fusing deep and wide channel features to extract more accurate low-frequency information in terms of correlations of different channels in single image super-resolution (SISR). Also, a signal enhancement operation in the ESRGCNN is useful to inherit more long-distance contextual information for resolving long-term dependency. An adaptive up-sampling operation is gathered into a CNN to obtain an image super-resolution model with low-resolution images of different sizes. Extensive experiments report that our ESRGCNN surpasses the state-of-the-arts in terms of SISR performance, complexity, execution speed, image quality evaluation and visual effect in SISR. Code is found at https://github.com/hellloxiaotian/ESRGCNN.
Generative Adversarial Networks for Image Super-Resolution: A Survey
Apr 28, 2022
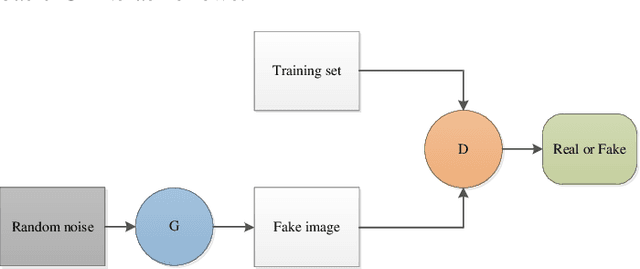
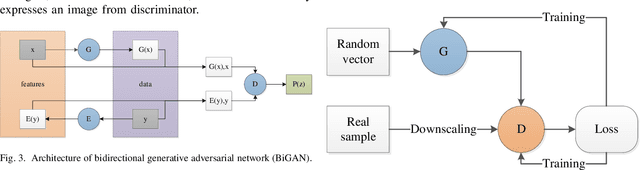
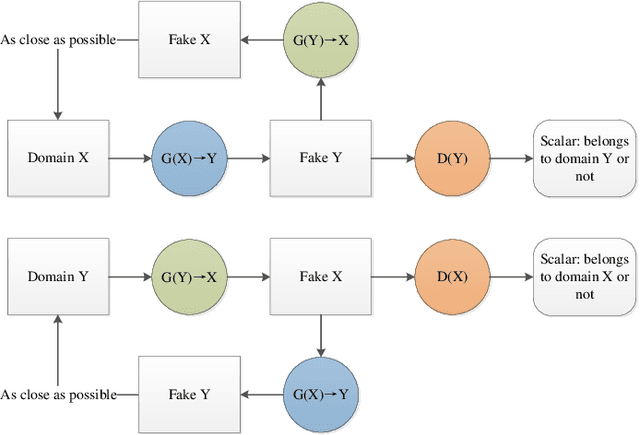
Single image super-resolution (SISR) has played an important role in the field of image processing. Recent generative adversarial networks (GANs) can achieve excellent results on low-resolution images with small samples. However, there are little literatures summarizing different GANs in SISR. In this paper, we conduct a comparative study of GANs from different perspectives. We first take a look at developments of GANs. Second, we present popular architectures for GANs in big and small samples for image applications. Then, we analyze motivations, implementations and differences of GANs based optimization methods and discriminative learning for image super-resolution in terms of supervised, semi-supervised and unsupervised manners. Next, we compare performance of these popular GANs on public datasets via quantitative and qualitative analysis in SISR. Finally, we highlight challenges of GANs and potential research points for SISR.
Asymmetric CNN for image super-resolution
Mar 30, 2021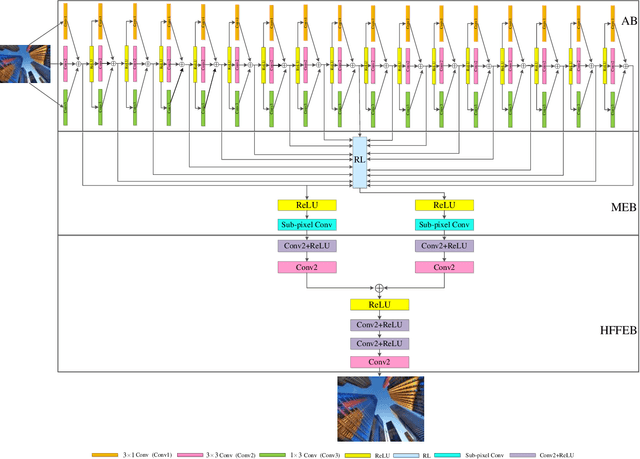
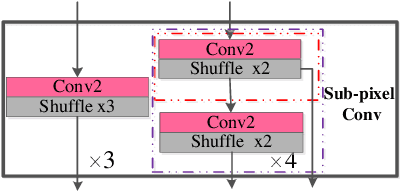
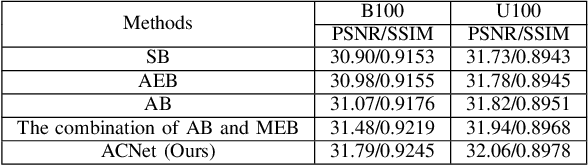
Deep convolutional neural networks (CNNs) have been widely applied for low-level vision over the past five years. According to nature of different applications, designing appropriate CNN architectures is developed. However, customized architectures gather different features via treating all pixel points as equal to improve the performance of given application, which ignores the effects of local power pixel points and results in low training efficiency. In this paper, we propose an asymmetric CNN (ACNet) comprising an asymmetric block (AB), a memory enhancement block (MEB) and a high-frequency feature enhancement block (HFFEB) for image super-resolution. The AB utilizes one-dimensional asymmetric convolutions to intensify the square convolution kernels in horizontal and vertical directions for promoting the influences of local salient features for SISR. The MEB fuses all hierarchical low-frequency features from the AB via residual learning (RL) technique to resolve the long-term dependency problem and transforms obtained low-frequency features into high-frequency features. The HFFEB exploits low- and high-frequency features to obtain more robust super-resolution features and address excessive feature enhancement problem. Addditionally, it also takes charge of reconstructing a high-resolution (HR) image. Extensive experiments show that our ACNet can effectively address single image super-resolution (SISR), blind SISR and blind SISR of blind noise problems. The code of the ACNet is shown at https://github.com/hellloxiaotian/ACNet.
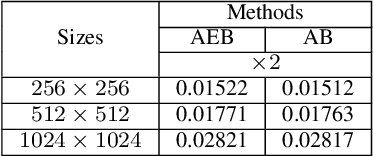
Lightweight Image Super-Resolution with Enhanced CNN
Jul 11, 2020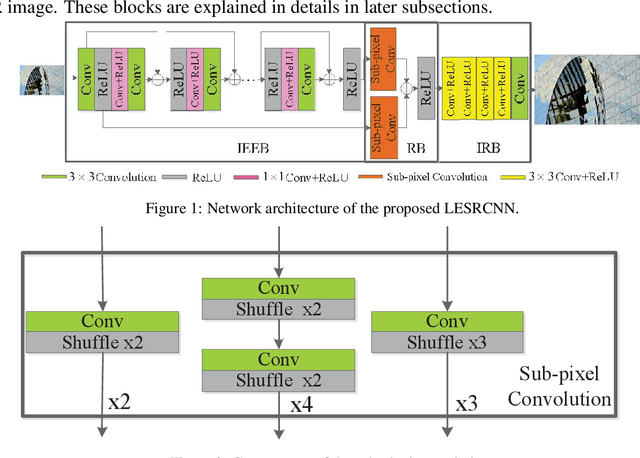
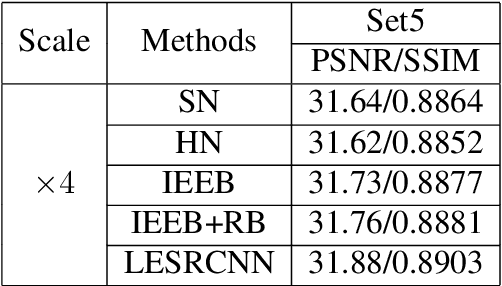
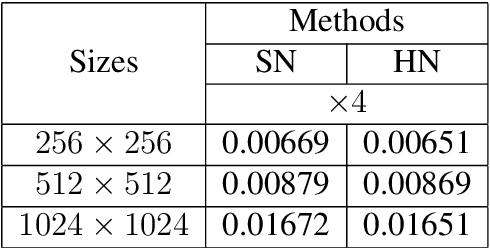
Deep convolutional neural networks (CNNs) with strong expressive ability have achieved impressive performances on single image super-resolution (SISR). However, their excessive amounts of convolutions and parameters usually consume high computational cost and more memory storage for training a SR model, which limits their applications to SR with resource-constrained devices in real world. To resolve these problems, we propose a lightweight enhanced SR CNN (LESRCN-N) with three successive sub-blocks, an information extraction and enhancement block (IEEB), a reconstruction block (RB) and an information refinement block (IRB). Specifically, the IEEB extracts hierarchical low-resolution (LR) features and aggregates the obtained features step-by-step to increase the memory ability of the shallow layers on deep layers for SISR. To remove redundant information obtained, a heterogeneous architecture is adopted in the IEEB. After that, the RB converts low-frequency features into high-frequency features by fusing global and local features, which is complementary with the IEEB in tackling the long-term dependency problem. Finally, the IRB uses coarse high-frequency features from the RB to learn more accurate SR features and construct a SR image. The proposed LESRCNN can obtain a high-quality image by a model for different scales. Extensive experiments demonstrate that the proposed LESRCNN outperforms state-of-the-arts on SISR in terms of qualitative and quantitative evaluation.
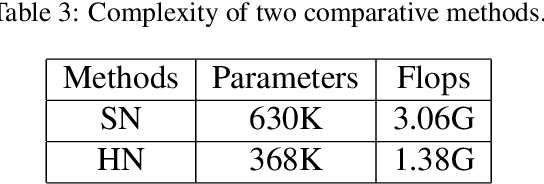
Designing and Training of A Dual CNN for Image Denoising
Jul 08, 2020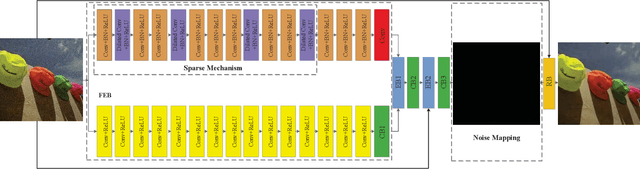



Deep convolutional neural networks (CNNs) for image denoising have recently attracted increasing research interest. However, plain networks cannot recover fine details for a complex task, such as real noisy images. In this paper, we propsoed a Dual denoising Network (DudeNet) to recover a clean image. Specifically, DudeNet consists of four modules: a feature extraction block, an enhancement block, a compression block, and a reconstruction block. The feature extraction block with a sparse machanism extracts global and local features via two sub-networks. The enhancement block gathers and fuses the global and local features to provide complementary information for the latter network. The compression block refines the extracted information and compresses the network. Finally, the reconstruction block is utilized to reconstruct a denoised image. The DudeNet has the following advantages: (1) The dual networks with a parse mechanism can extract complementary features to enhance the generalized ability of denoiser. (2) Fusing global and local features can extract salient features to recover fine details for complex noisy images. (3) A Small-size filter is used to reduce the complexity of denoiser. Extensive experiments demonstrate the superiority of DudeNet over existing current state-of-the-art denoising methods.
Deep Learning on Image Denoising: An overview
Jan 16, 2020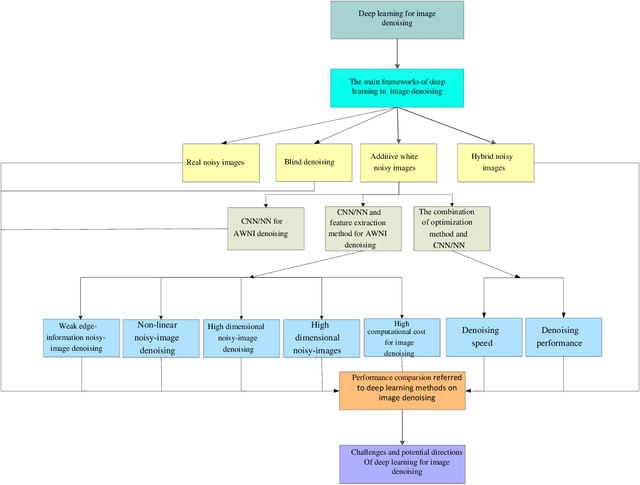
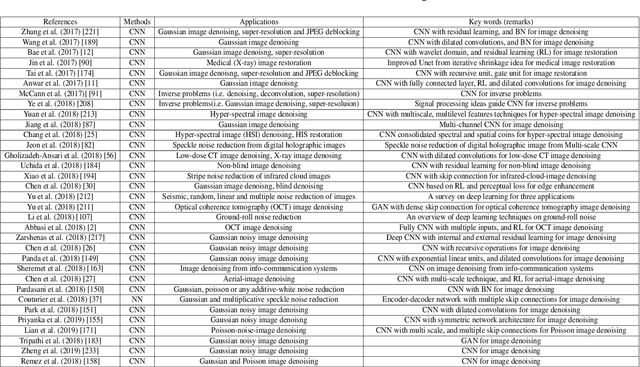
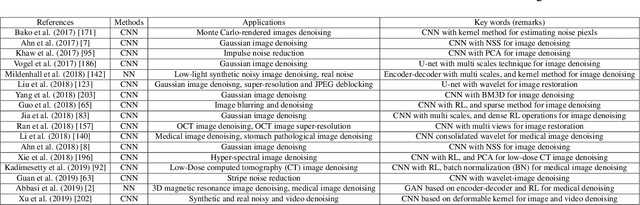
Deep learning techniques have obtained much attention in image denoising. However, deep learning methods of different types deal with the noise have enormous differences. Specifically, discriminative learning based on deep learning can well address the Gaussian noise. Optimization model methods based on deep learning have good effect on estimating of the real noise. So far, there are little related researches to summarize different deep learning techniques for image denoising. In this paper, we make such a comparative study of different deep techniques in image denoising. We first classify the (1) deep convolutional neural networks (CNNs) for additive white noisy images, (2) deep CNNs for real noisy images, (3) deep CNNs for blind denoising and (4) deep CNNs for hybrid noisy images, which is the combination of noisy, blurred and low-resolution images. Then, we analyze the motivations and principles of deep learning methods of different types. Next, we compare and verify the state-of-the-art methods on public denoising datasets in terms of quantitative and qualitative analysis. Finally, we point out some potential challenges and directions of future research.