 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContrastive Learning of Medical Visual Representations from Paired Images and Text
Oct 02, 2020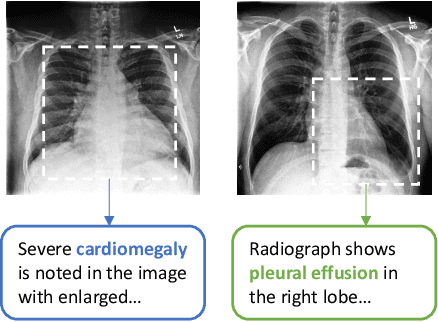
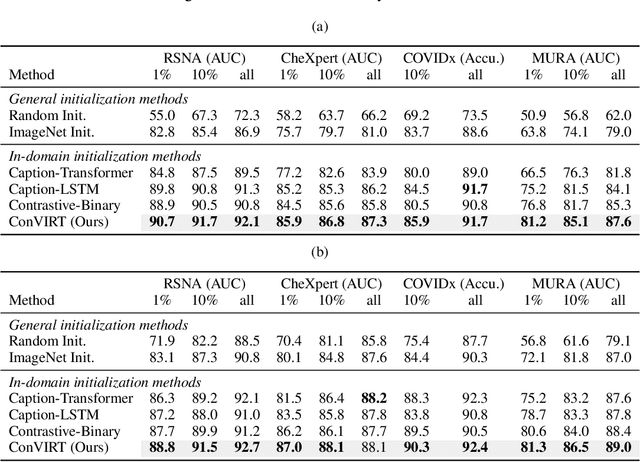
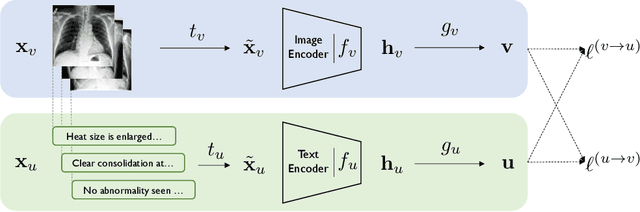
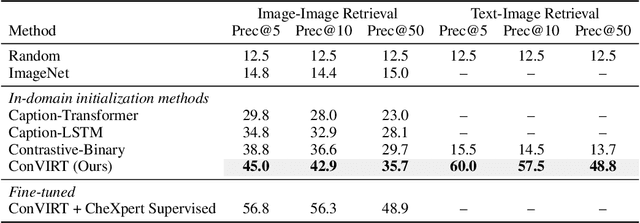
Learning visual representations of medical images is core to medical image understanding but its progress has been held back by the small size of hand-labeled datasets. Existing work commonly relies on transferring weights from ImageNet pretraining, which is suboptimal due to drastically different image characteristics, or rule-based label extraction from the textual report data paired with medical images, which is inaccurate and hard to generalize. We propose an alternative unsupervised strategy to learn medical visual representations directly from the naturally occurring pairing of images and textual data. Our method of pretraining medical image encoders with the paired text data via a bidirectional contrastive objective between the two modalities is domain-agnostic, and requires no additional expert input. We test our method by transferring our pretrained weights to 4 medical image classification tasks and 2 zero-shot retrieval tasks, and show that our method leads to image representations that considerably outperform strong baselines in most settings. Notably, in all 4 classification tasks, our method requires only 10% as much labeled training data as an ImageNet initialized counterpart to achieve better or comparable performance, demonstrating superior data efficiency.
Neural Generation Meets Real People: Towards Emotionally Engaging Mixed-Initiative Conversations
Sep 05, 2020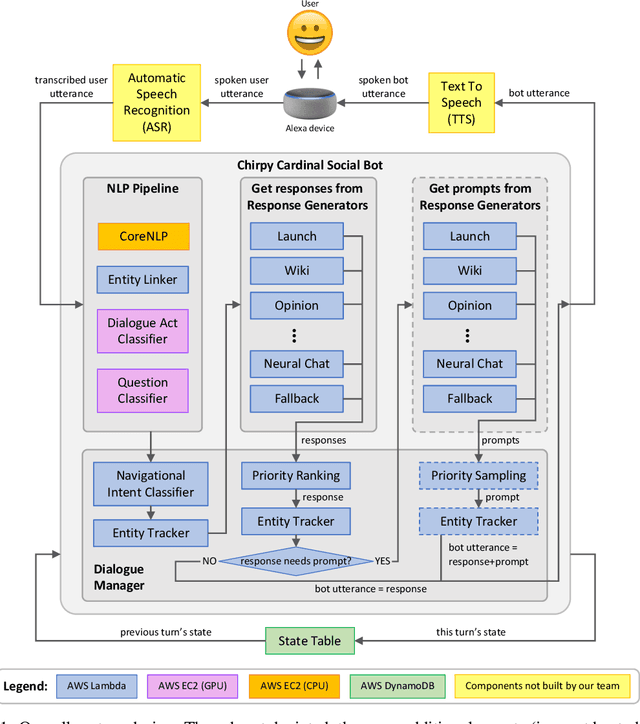
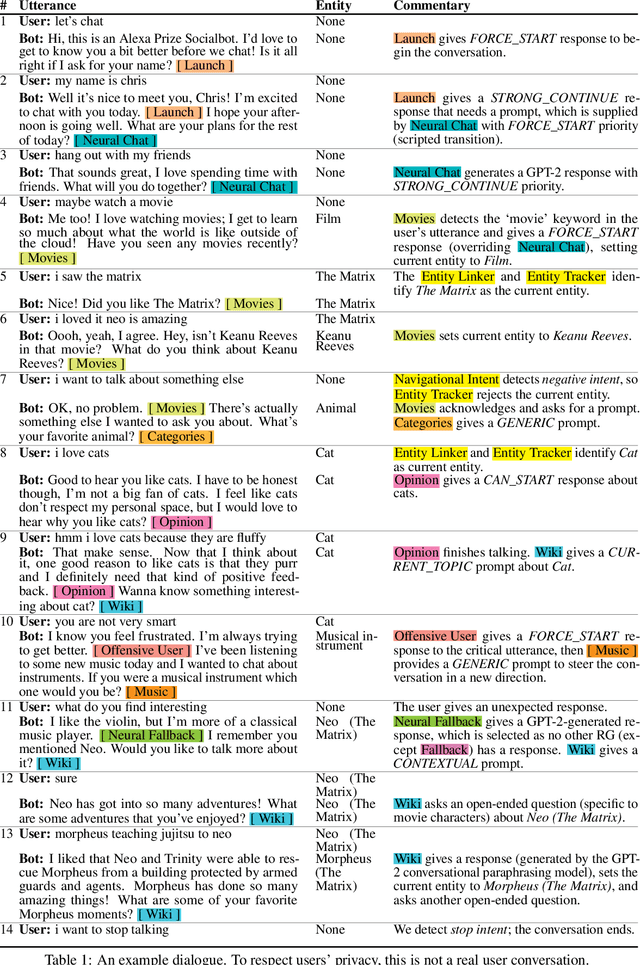

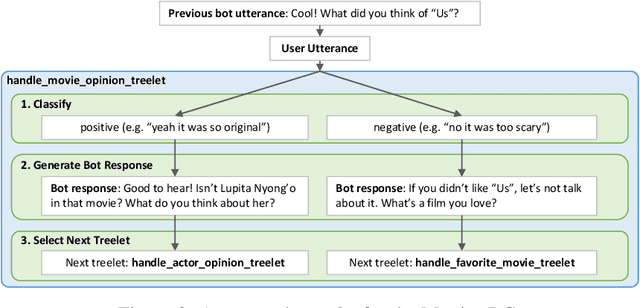
We present Chirpy Cardinal, an open-domain dialogue agent, as a research platform for the 2019 Alexa Prize competition. Building an open-domain socialbot that talks to real people is challenging - such a system must meet multiple user expectations such as broad world knowledge, conversational style, and emotional connection. Our socialbot engages users on their terms - prioritizing their interests, feelings and autonomy. As a result, our socialbot provides a responsive, personalized user experience, capable of talking knowledgeably about a wide variety of topics, as well as chatting empathetically about ordinary life. Neural generation plays a key role in achieving these goals, providing the backbone for our conversational and emotional tone. At the end of the competition, Chirpy Cardinal progressed to the finals with an average rating of 3.6/5.0, a median conversation duration of 2 minutes 16 seconds, and a 90th percentile duration of over 12 minutes.
Biomedical and Clinical English Model Packages in the Stanza Python NLP Library
Jul 29, 2020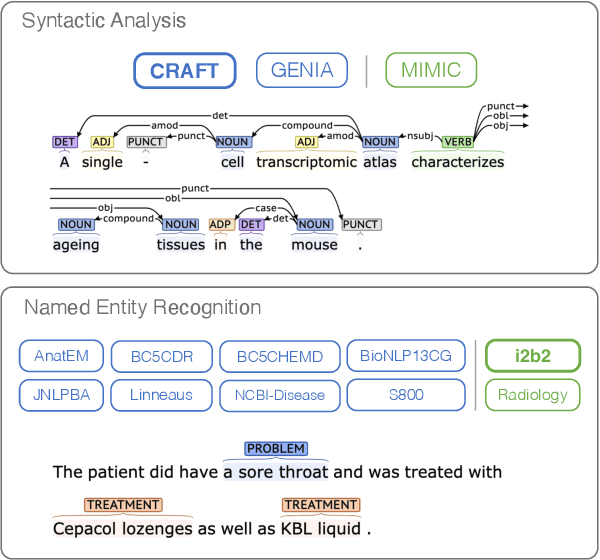
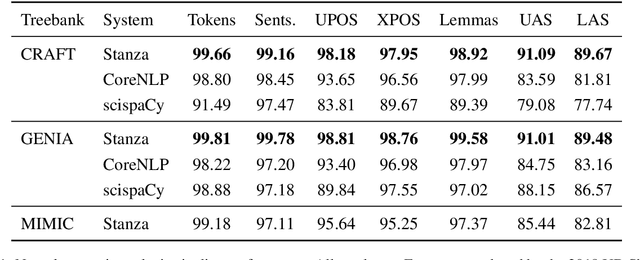
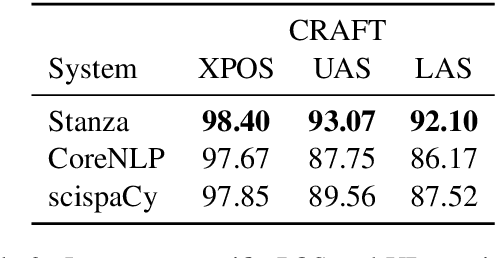
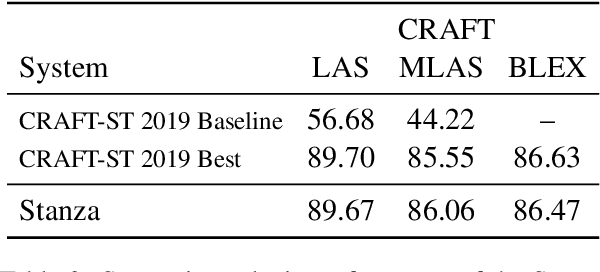
We introduce biomedical and clinical English model packages for the Stanza Python NLP library. These packages offer accurate syntactic analysis and named entity recognition capabilities for biomedical and clinical text, by combining Stanza's fully neural architecture with a wide variety of open datasets as well as large-scale unsupervised biomedical and clinical text data. We show via extensive experiments that our packages achieve syntactic analysis and named entity recognition performance that is on par with or surpasses state-of-the-art results. We further show that these models do not compromise speed compared to existing toolkits when GPU acceleration is available, and are made easy to download and use with Stanza's Python interface. A demonstration of our packages is available at: http://stanza.run/bio.
Finding Universal Grammatical Relations in Multilingual BERT
May 20, 2020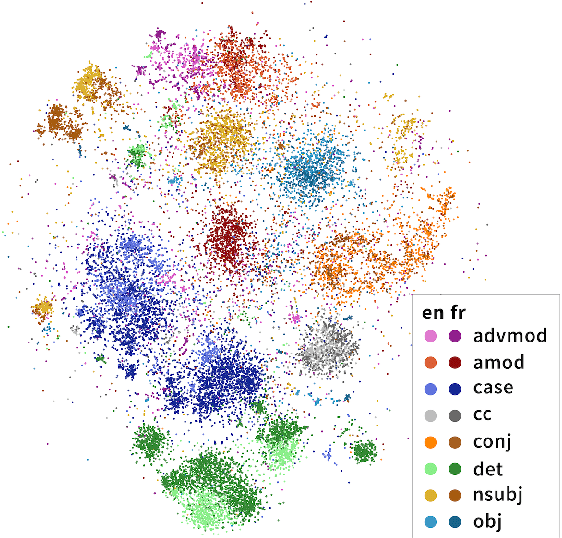
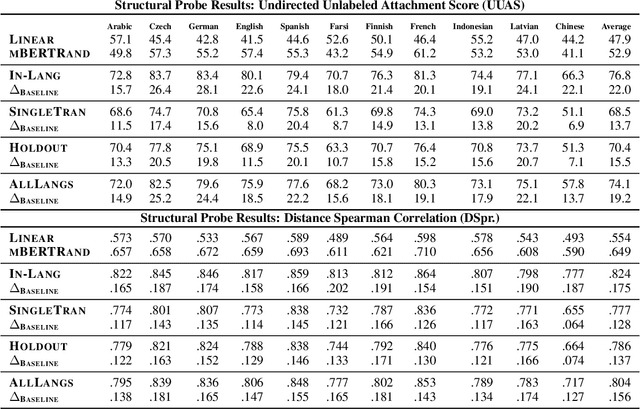
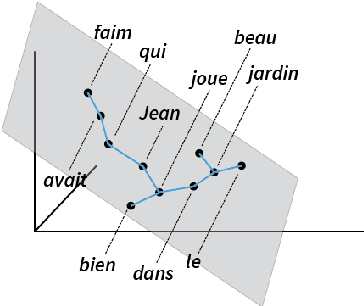
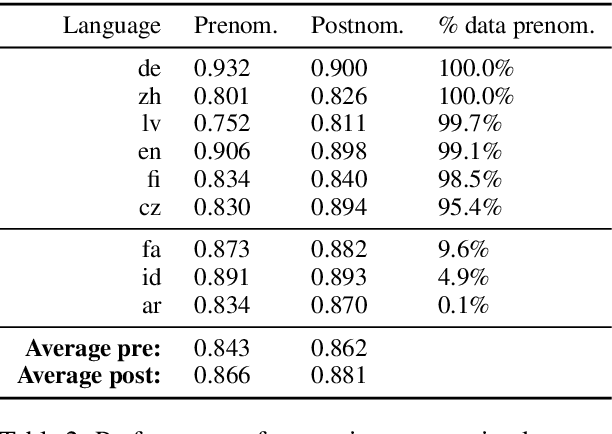
Recent work has found evidence that Multilingual BERT (mBERT), a transformer-based multilingual masked language model, is capable of zero-shot cross-lingual transfer, suggesting that some aspects of its representations are shared cross-lingually. To better understand this overlap, we extend recent work on finding syntactic trees in neural networks' internal representations to the multilingual setting. We show that subspaces of mBERT representations recover syntactic tree distances in languages other than English, and that these subspaces are approximately shared across languages. Motivated by these results, we present an unsupervised analysis method that provides evidence mBERT learns representations of syntactic dependency labels, in the form of clusters which largely agree with the Universal Dependencies taxonomy. This evidence suggests that even without explicit supervision, multilingual masked language models learn certain linguistic universals.
Syn-QG: Syntactic and Shallow Semantic Rules for Question Generation
May 01, 2020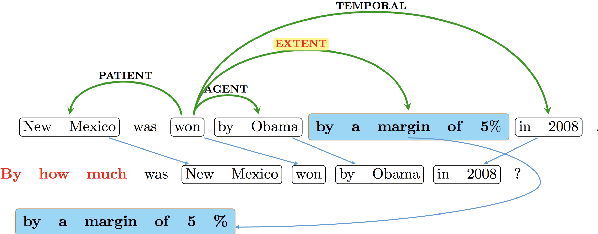
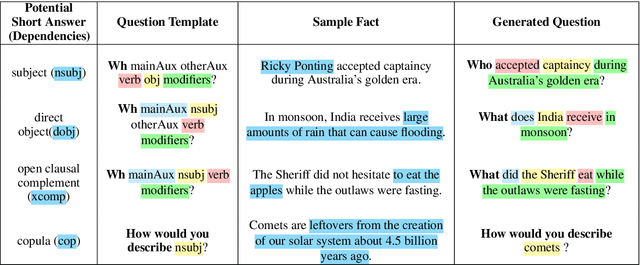
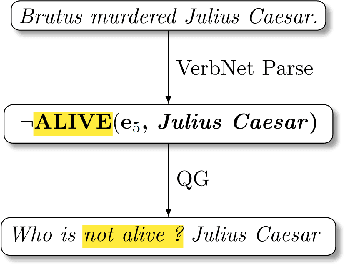
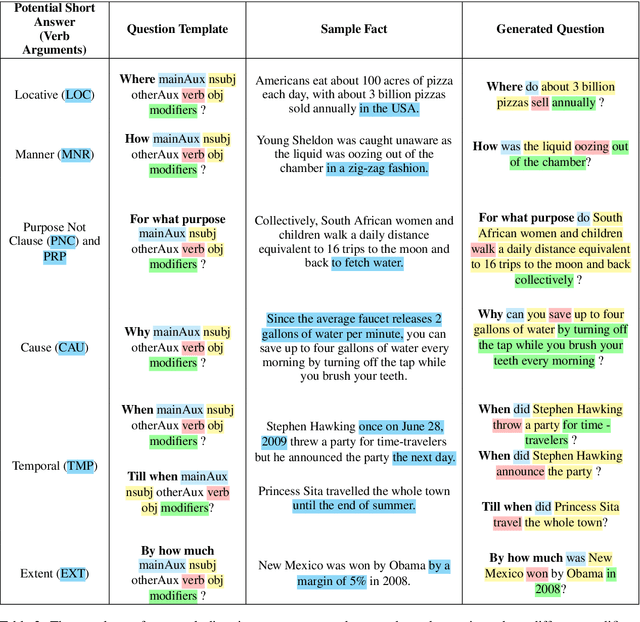
Question Generation (QG) is fundamentally a simple syntactic transformation; however, many aspects of semantics influence what questions are good to form. We implement this observation by developing Syn-QG, a set of transparent syntactic rules leveraging universal dependencies, shallow semantic parsing, lexical resources, and custom rules which transform declarative sentences into question-answer pairs. We utilize PropBank argument descriptions and VerbNet state predicates to incorporate shallow semantic content, which helps generate questions of a descriptive nature and produce inferential and semantically richer questions than existing systems. In order to improve syntactic fluency and eliminate grammatically incorrect questions, we employ back-translation over the output of these syntactic rules. A set of crowd-sourced evaluations shows that our system can generate a larger number of highly grammatical and relevant questions than previous QG systems and that back-translation drastically improves grammaticality at a slight cost of generating irrelevant questions.
Stay Hungry, Stay Focused: Generating Informative and Specific Questions in Information-Seeking Conversations
Apr 30, 2020
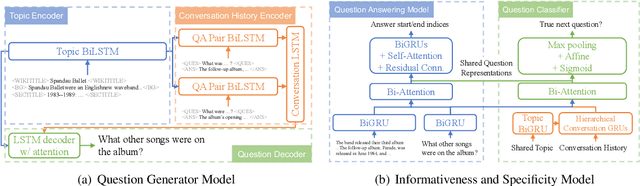
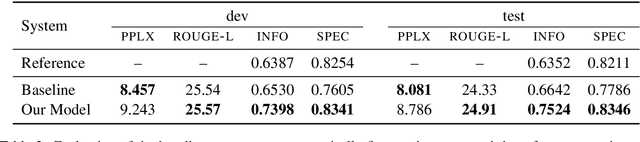
We investigate the problem of generating informative questions in information-asymmetric conversations. Unlike previous work on question generation which largely assumes knowledge of what the answer might be, we are interested in the scenario where the questioner is not given the context from which answers are drawn, but must reason pragmatically about how to acquire new information, given the shared conversation history. We identify two core challenges: (1) formally defining the informativeness of potential questions, and (2) exploring the prohibitively large space of potential questions to find the good candidates. To generate pragmatic questions, we use reinforcement learning to optimize an informativeness metric we propose, combined with a reward function designed to promote more specific questions. We demonstrate that the resulting pragmatic questioner substantially improves the informativeness and specificity of questions generated over a baseline model, as evaluated by our metrics as well as humans.
Stanza: A Python Natural Language Processing Toolkit for Many Human Languages
Apr 23, 2020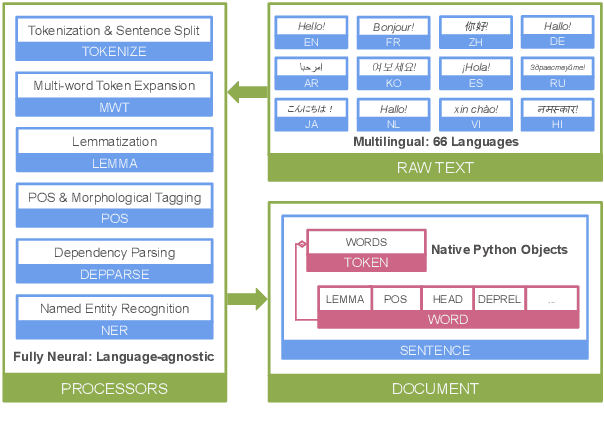
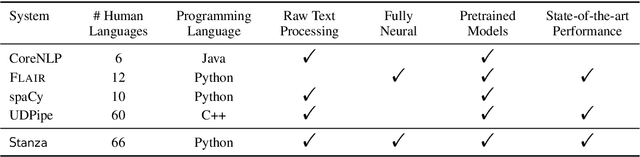
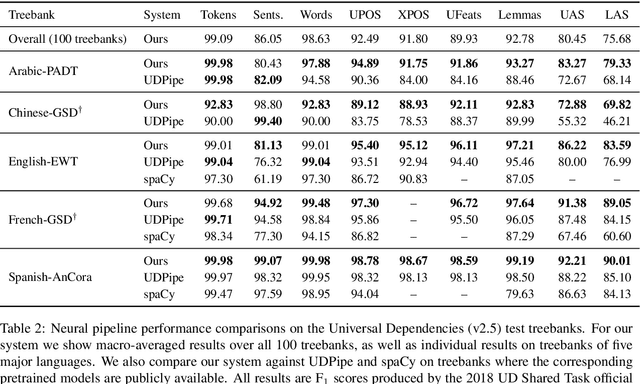
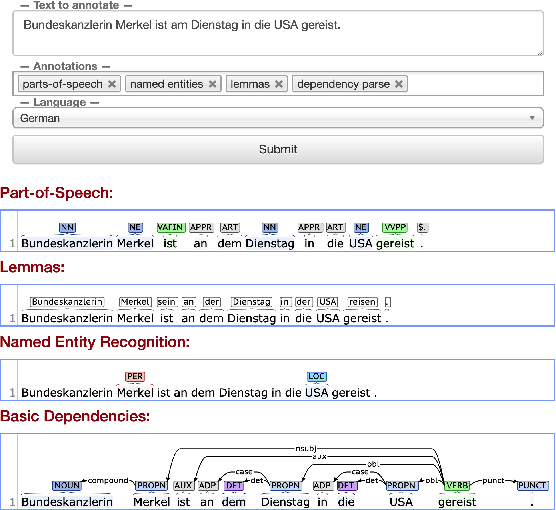
We introduce Stanza, an open-source Python natural language processing toolkit supporting 66 human languages. Compared to existing widely used toolkits, Stanza features a language-agnostic fully neural pipeline for text analysis, including tokenization, multi-word token expansion, lemmatization, part-of-speech and morphological feature tagging, dependency parsing, and named entity recognition. We have trained Stanza on a total of 112 datasets, including the Universal Dependencies treebanks and other multilingual corpora, and show that the same neural architecture generalizes well and achieves competitive performance on all languages tested. Additionally, Stanza includes a native Python interface to the widely used Java Stanford CoreNLP software, which further extends its functionality to cover other tasks such as coreference resolution and relation extraction. Source code, documentation, and pretrained models for 66 languages are available at https://stanfordnlp.github.io/stanza.
Universal Dependencies v2: An Evergrowing Multilingual Treebank Collection
Apr 22, 2020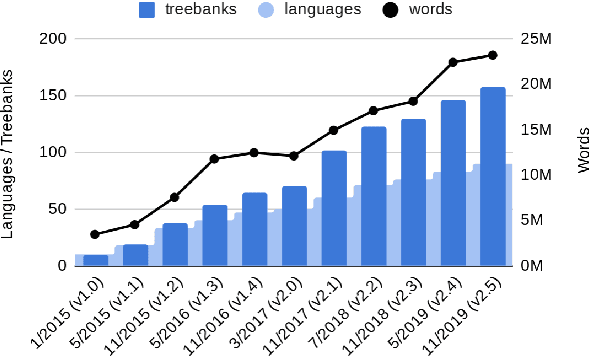
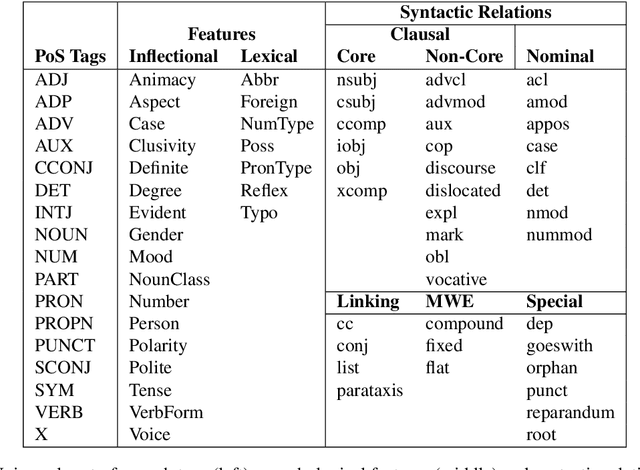
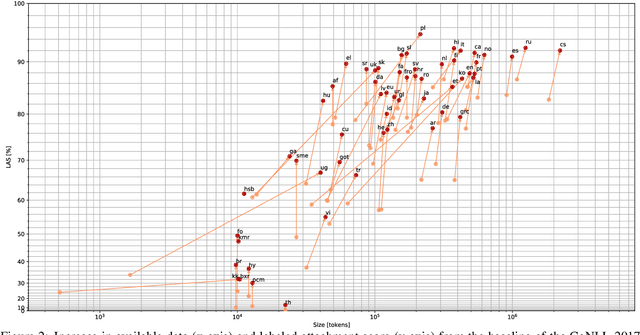
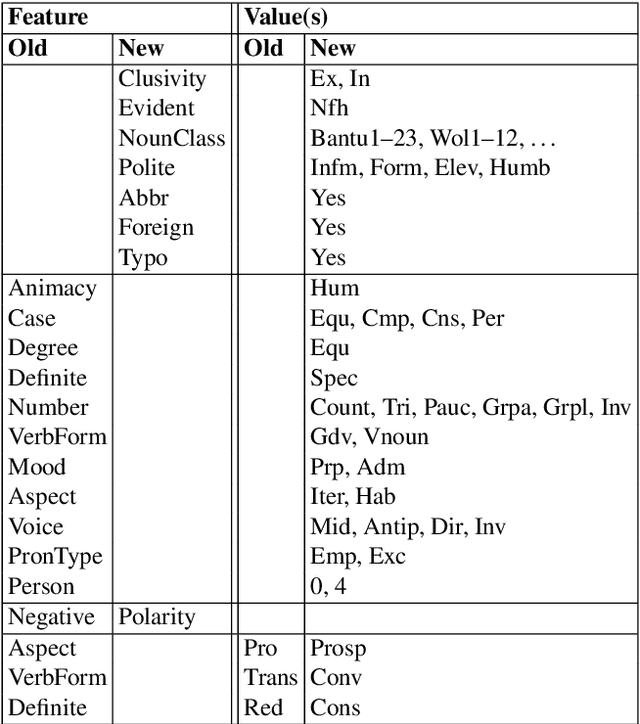
Universal Dependencies is an open community effort to create cross-linguistically consistent treebank annotation for many languages within a dependency-based lexicalist framework. The annotation consists in a linguistically motivated word segmentation; a morphological layer comprising lemmas, universal part-of-speech tags, and standardized morphological features; and a syntactic layer focusing on syntactic relations between predicates, arguments and modifiers. In this paper, we describe version 2 of the guidelines (UD v2), discuss the major changes from UD v1 to UD v2, and give an overview of the currently available treebanks for 90 languages.
ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators
Mar 23, 2020Masked language modeling (MLM) pre-training methods such as BERT corrupt the input by replacing some tokens with [MASK] and then train a model to reconstruct the original tokens. While they produce good results when transferred to downstream NLP tasks, they generally require large amounts of compute to be effective. As an alternative, we propose a more sample-efficient pre-training task called replaced token detection. Instead of masking the input, our approach corrupts it by replacing some tokens with plausible alternatives sampled from a small generator network. Then, instead of training a model that predicts the original identities of the corrupted tokens, we train a discriminative model that predicts whether each token in the corrupted input was replaced by a generator sample or not. Thorough experiments demonstrate this new pre-training task is more efficient than MLM because the task is defined over all input tokens rather than just the small subset that was masked out. As a result, the contextual representations learned by our approach substantially outperform the ones learned by BERT given the same model size, data, and compute. The gains are particularly strong for small models; for example, we train a model on one GPU for 4 days that outperforms GPT (trained using 30x more compute) on the GLUE natural language understanding benchmark. Our approach also works well at scale, where it performs comparably to RoBERTa and XLNet while using less than 1/4 of their compute and outperforms them when using the same amount of compute.
Optimizing the Factual Correctness of a Summary: A Study of Summarizing Radiology Reports
Nov 08, 2019
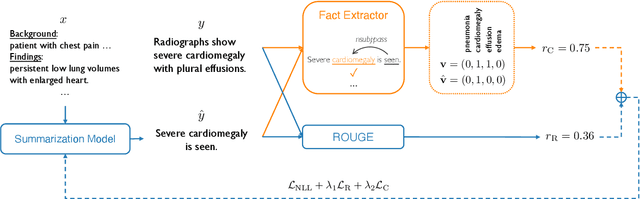
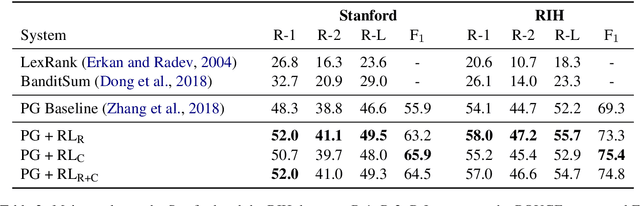
Neural abstractive summarization models are able to generate summaries which have high overlap with human references. However, existing models are not optimized for factual correctness, a critical metric in real-world applications. In this work, we develop a general framework where we evaluate the factual correctness of a generated summary by fact-checking it against its reference using an information extraction module. We further propose a training strategy which optimizes a neural summarization model with a factual correctness reward via reinforcement learning. We apply the proposed method to the summarization of radiology reports, where factual correctness is a key requirement. On two separate datasets collected from real hospitals, we show via both automatic and human evaluation that the proposed approach substantially improves the factual correctness and overall quality of outputs over a competitive neural summarization system.