 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCHOSEN: Contrastive Hypothesis Selection for Multi-View Depth Refinement
Apr 02, 2024



We propose CHOSEN, a simple yet flexible, robust and effective multi-view depth refinement framework. It can be employed in any existing multi-view stereo pipeline, with straightforward generalization capability for different multi-view capture systems such as camera relative positioning and lenses. Given an initial depth estimation, CHOSEN iteratively re-samples and selects the best hypotheses, and automatically adapts to different metric or intrinsic scales determined by the capture system. The key to our approach is the application of contrastive learning in an appropriate solution space and a carefully designed hypothesis feature, based on which positive and negative hypotheses can be effectively distinguished. Integrated in a simple baseline multi-view stereo pipeline, CHOSEN delivers impressive quality in terms of depth and normal accuracy compared to many current deep learning based multi-view stereo pipelines.
Light Stage Super-Resolution: Continuous High-Frequency Relighting
Oct 17, 2020
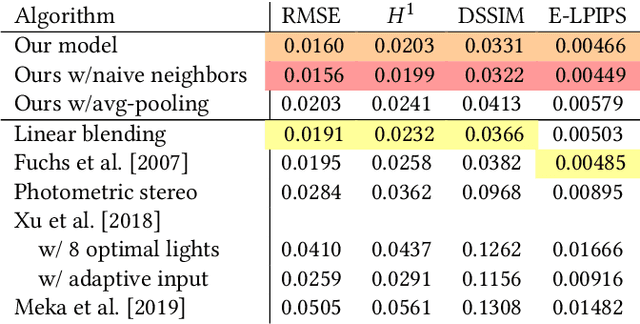
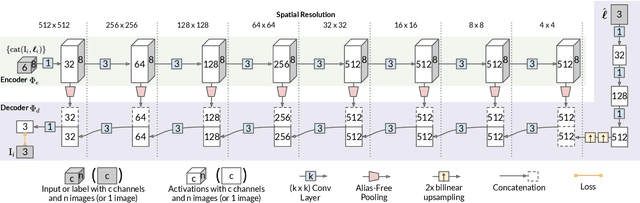
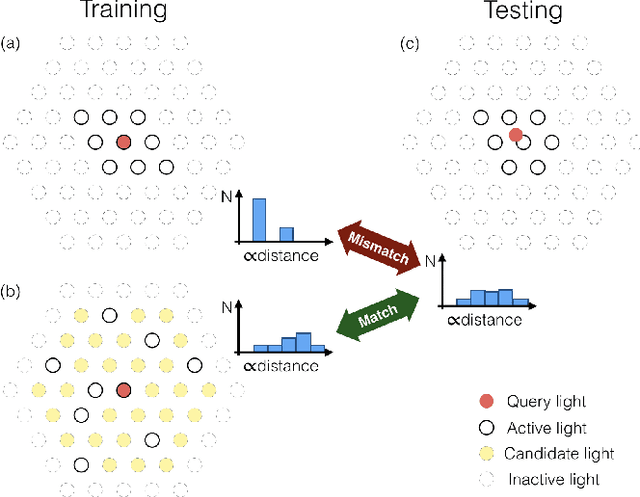
The light stage has been widely used in computer graphics for the past two decades, primarily to enable the relighting of human faces. By capturing the appearance of the human subject under different light sources, one obtains the light transport matrix of that subject, which enables image-based relighting in novel environments. However, due to the finite number of lights in the stage, the light transport matrix only represents a sparse sampling on the entire sphere. As a consequence, relighting the subject with a point light or a directional source that does not coincide exactly with one of the lights in the stage requires interpolation and resampling the images corresponding to nearby lights, and this leads to ghosting shadows, aliased specularities, and other artifacts. To ameliorate these artifacts and produce better results under arbitrary high-frequency lighting, this paper proposes a learning-based solution for the "super-resolution" of scans of human faces taken from a light stage. Given an arbitrary "query" light direction, our method aggregates the captured images corresponding to neighboring lights in the stage, and uses a neural network to synthesize a rendering of the face that appears to be illuminated by a "virtual" light source at the query location. This neural network must circumvent the inherent aliasing and regularity of the light stage data that was used for training, which we accomplish through the use of regularized traditional interpolation methods within our network. Our learned model is able to produce renderings for arbitrary light directions that exhibit realistic shadows and specular highlights, and is able to generalize across a wide variety of subjects.
Neural Light Transport for Relighting and View Synthesis
Aug 20, 2020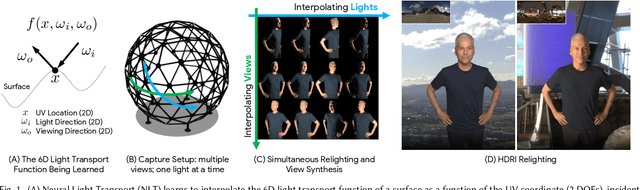
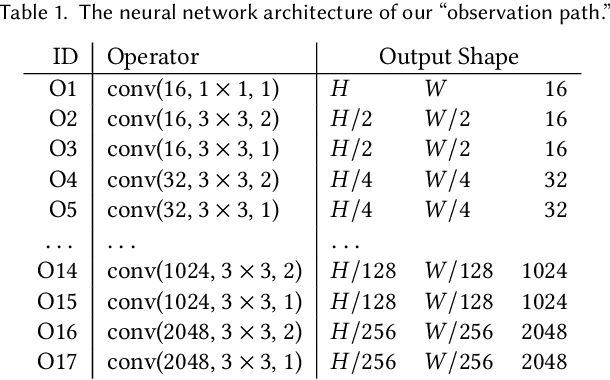

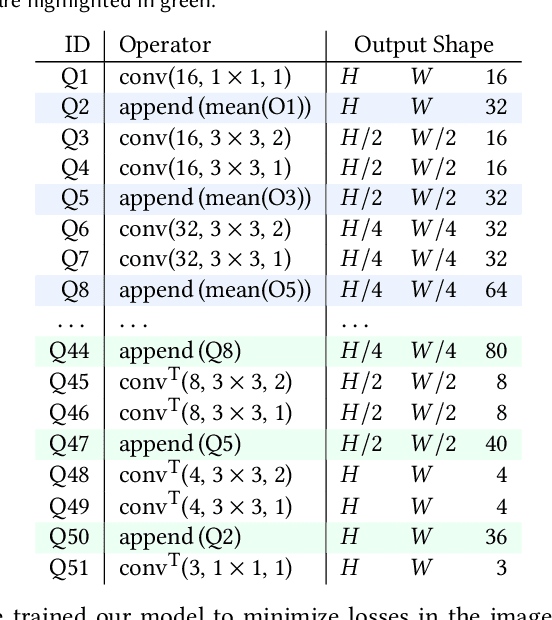
The light transport (LT) of a scene describes how it appears under different lighting and viewing directions, and complete knowledge of a scene's LT enables the synthesis of novel views under arbitrary lighting. In this paper, we focus on image-based LT acquisition, primarily for human bodies within a light stage setup. We propose a semi-parametric approach to learn a neural representation of LT that is embedded in the space of a texture atlas of known geometric properties, and model all non-diffuse and global LT as residuals added to a physically-accurate diffuse base rendering. In particular, we show how to fuse previously seen observations of illuminants and views to synthesize a new image of the same scene under a desired lighting condition from a chosen viewpoint. This strategy allows the network to learn complex material effects (such as subsurface scattering) and global illumination, while guaranteeing the physical correctness of the diffuse LT (such as hard shadows). With this learned LT, one can relight the scene photorealistically with a directional light or an HDRI map, synthesize novel views with view-dependent effects, or do both simultaneously, all in a unified framework using a set of sparse, previously seen observations. Qualitative and quantitative experiments demonstrate that our neural LT (NLT) outperforms state-of-the-art solutions for relighting and view synthesis, without separate treatment for both problems that prior work requires.
Learning Illumination from Diverse Portraits
Aug 05, 2020
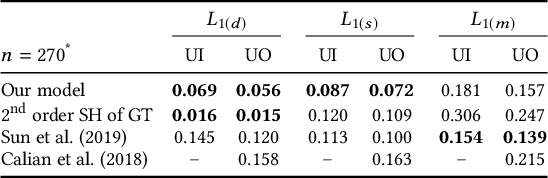
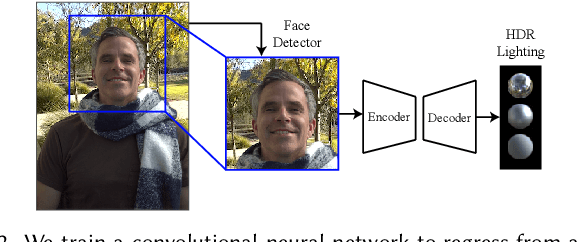
We present a learning-based technique for estimating high dynamic range (HDR), omnidirectional illumination from a single low dynamic range (LDR) portrait image captured under arbitrary indoor or outdoor lighting conditions. We train our model using portrait photos paired with their ground truth environmental illumination. We generate a rich set of such photos by using a light stage to record the reflectance field and alpha matte of 70 diverse subjects in various expressions. We then relight the subjects using image-based relighting with a database of one million HDR lighting environments, compositing the relit subjects onto paired high-resolution background imagery recorded during the lighting acquisition. We train the lighting estimation model using rendering-based loss functions and add a multi-scale adversarial loss to estimate plausible high frequency lighting detail. We show that our technique outperforms the state-of-the-art technique for portrait-based lighting estimation, and we also show that our method reliably handles the inherent ambiguity between overall lighting strength and surface albedo, recovering a similar scale of illumination for subjects with diverse skin tones. We demonstrate that our method allows virtual objects and digital characters to be added to a portrait photograph with consistent illumination. Our lighting inference runs in real-time on a smartphone, enabling realistic rendering and compositing of virtual objects into live video for augmented reality applications.
Single Image Portrait Relighting
May 02, 2019
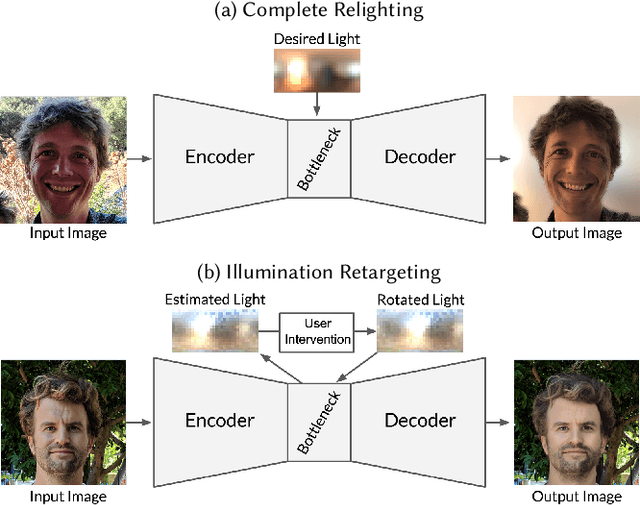

Lighting plays a central role in conveying the essence and depth of the subject in a portrait photograph. Professional photographers will carefully control the lighting in their studio to manipulate the appearance of their subject, while consumer photographers are usually constrained to the illumination of their environment. Though prior works have explored techniques for relighting an image, their utility is usually limited due to requirements of specialized hardware, multiple images of the subject under controlled or known illuminations, or accurate models of geometry and reflectance. To this end, we present a system for portrait relighting: a neural network that takes as input a single RGB image of a portrait taken with a standard cellphone camera in an unconstrained environment, and from that image produces a relit image of that subject as though it were illuminated according to any provided environment map. Our method is trained on a small database of 18 individuals captured under different directional light sources in a controlled light stage setup consisting of a densely sampled sphere of lights. Our proposed technique produces quantitatively superior results on our dataset's validation set compared to prior works, and produces convincing qualitative relighting results on a dataset of hundreds of real-world cellphone portraits. Because our technique can produce a 640 $\times$ 640 image in only 160 milliseconds, it may enable interactive user-facing photographic applications in the future.
* SIGGRAPH 2019 Technical Paper accepted
LookinGood: Enhancing Performance Capture with Real-time Neural Re-Rendering
Nov 12, 2018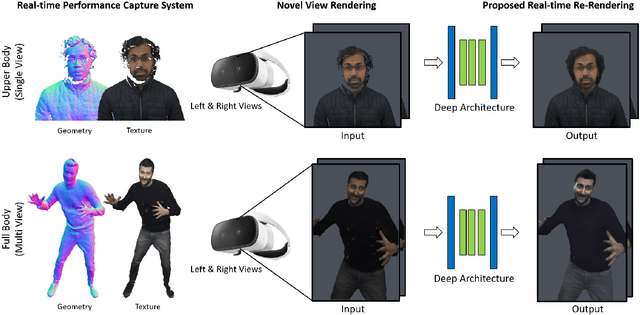



Motivated by augmented and virtual reality applications such as telepresence, there has been a recent focus in real-time performance capture of humans under motion. However, given the real-time constraint, these systems often suffer from artifacts in geometry and texture such as holes and noise in the final rendering, poor lighting, and low-resolution textures. We take the novel approach to augment such real-time performance capture systems with a deep architecture that takes a rendering from an arbitrary viewpoint, and jointly performs completion, super resolution, and denoising of the imagery in real-time. We call this approach neural (re-)rendering, and our live system "LookinGood". Our deep architecture is trained to produce high resolution and high quality images from a coarse rendering in real-time. First, we propose a self-supervised training method that does not require manual ground-truth annotation. We contribute a specialized reconstruction error that uses semantic information to focus on relevant parts of the subject, e.g. the face. We also introduce a salient reweighing scheme of the loss function that is able to discard outliers. We specifically design the system for virtual and augmented reality headsets where the consistency between the left and right eye plays a crucial role in the final user experience. Finally, we generate temporally stable results by explicitly minimizing the difference between two consecutive frames. We tested the proposed system in two different scenarios: one involving a single RGB-D sensor, and upper body reconstruction of an actor, the second consisting of full body 360 degree capture. Through extensive experimentation, we demonstrate how our system generalizes across unseen sequences and subjects. The supplementary video is available at http://youtu.be/Md3tdAKoLGU.
StereoNet: Guided Hierarchical Refinement for Real-Time Edge-Aware Depth Prediction
Jul 24, 2018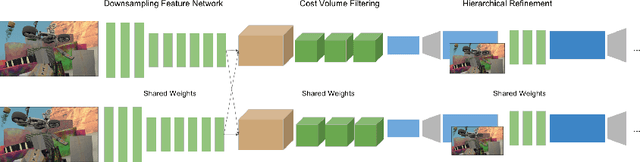
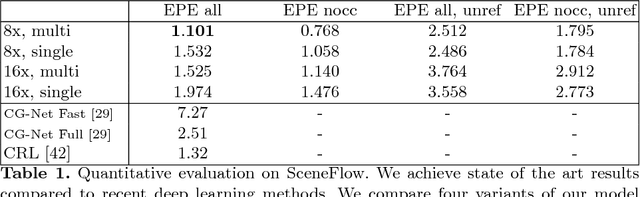
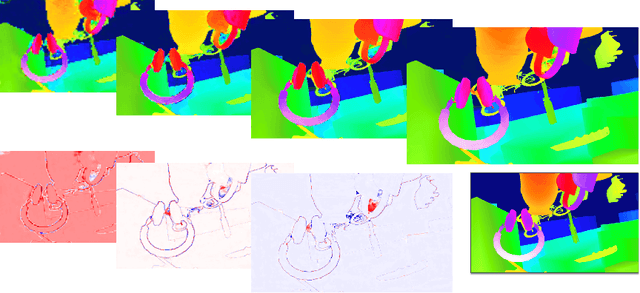
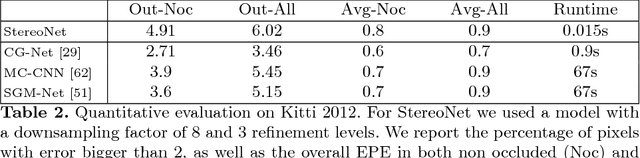
This paper presents StereoNet, the first end-to-end deep architecture for real-time stereo matching that runs at 60 fps on an NVidia Titan X, producing high-quality, edge-preserved, quantization-free disparity maps. A key insight of this paper is that the network achieves a sub-pixel matching precision than is a magnitude higher than those of traditional stereo matching approaches. This allows us to achieve real-time performance by using a very low resolution cost volume that encodes all the information needed to achieve high disparity precision. Spatial precision is achieved by employing a learned edge-aware upsampling function. Our model uses a Siamese network to extract features from the left and right image. A first estimate of the disparity is computed in a very low resolution cost volume, then hierarchically the model re-introduces high-frequency details through a learned upsampling function that uses compact pixel-to-pixel refinement networks. Leveraging color input as a guide, this function is capable of producing high-quality edge-aware output. We achieve compelling results on multiple benchmarks, showing how the proposed method offers extreme flexibility at an acceptable computational budget.
ActiveStereoNet: End-to-End Self-Supervised Learning for Active Stereo Systems
Jul 16, 2018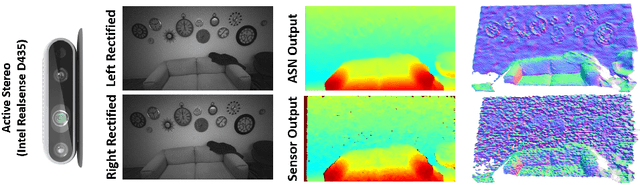
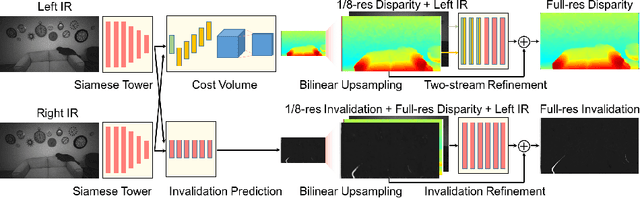

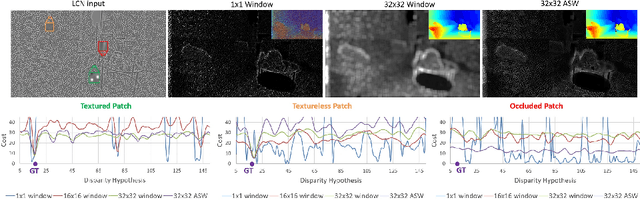
In this paper we present ActiveStereoNet, the first deep learning solution for active stereo systems. Due to the lack of ground truth, our method is fully self-supervised, yet it produces precise depth with a subpixel precision of $1/30th$ of a pixel; it does not suffer from the common over-smoothing issues; it preserves the edges; and it explicitly handles occlusions. We introduce a novel reconstruction loss that is more robust to noise and texture-less patches, and is invariant to illumination changes. The proposed loss is optimized using a window-based cost aggregation with an adaptive support weight scheme. This cost aggregation is edge-preserving and smooths the loss function, which is key to allow the network to reach compelling results. Finally we show how the task of predicting invalid regions, such as occlusions, can be trained end-to-end without ground-truth. This component is crucial to reduce blur and particularly improves predictions along depth discontinuities. Extensive quantitatively and qualitatively evaluations on real and synthetic data demonstrate state of the art results in many challenging scenes.
A Light Transport Model for Mitigating Multipath Interference in TOF Sensors
Jan 30, 2015Continuous-wave Time-of-flight (TOF) range imaging has become a commercially viable technology with many applications in computer vision and graphics. However, the depth images obtained from TOF cameras contain scene dependent errors due to multipath interference (MPI). Specifically, MPI occurs when multiple optical reflections return to a single spatial location on the imaging sensor. Many prior approaches to rectifying MPI rely on sparsity in optical reflections, which is an extreme simplification. In this paper, we correct MPI by combining the standard measurements from a TOF camera with information from direct and global light transport. We report results on both simulated experiments and physical experiments (using the Kinect sensor). Our results, evaluated against ground truth, demonstrate a quantitative improvement in depth accuracy.