 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeM3TR: Generalist HD Map Construction with Variable Map Priors
Nov 15, 2024Autonomous vehicles require road information for their operation, usually in form of HD maps. Since offline maps eventually become outdated or may only be partially available, online HD map construction methods have been proposed to infer map information from live sensor data. A key issue remains how to exploit such partial or outdated map information as a prior. We introduce M3TR (Multi-Masking Map Transformer), a generalist approach for HD map construction both with and without map priors. We address shortcomings in ground truth generation for Argoverse 2 and nuScenes and propose the first realistic scenarios with semantically diverse map priors. Examining various query designs, we use an improved method for integrating prior map elements into a HD map construction model, increasing performance by +4.3 mAP. Finally, we show that training across all prior scenarios yields a single Generalist model, whose performance is on par with previous Expert models that can handle only one specific type of map prior. M3TR thus is the first model capable of leveraging variable map priors, making it suitable for real-world deployment. Code is available at https://github.com/immel-f/m3tr
SceneMotion: From Agent-Centric Embeddings to Scene-Wide Forecasts
Aug 02, 2024



Self-driving vehicles rely on multimodal motion forecasts to effectively interact with their environment and plan safe maneuvers. We introduce SceneMotion, an attention-based model for forecasting scene-wide motion modes of multiple traffic agents. Our model transforms local agent-centric embeddings into scene-wide forecasts using a novel latent context module. This module learns a scene-wide latent space from multiple agent-centric embeddings, enabling joint forecasting and interaction modeling. The competitive performance in the Waymo Open Interaction Prediction Challenge demonstrates the effectiveness of our approach. Moreover, we cluster future waypoints in time and space to quantify the interaction between agents. We merge all modes and analyze each mode independently to determine which clusters are resolved through interaction or result in conflict. Our implementation is available at: https://github.com/kit-mrt/future-motion
Generation of Training Data from HD Maps in the Lanelet2 Framework
Jul 24, 2024Using HD maps directly as training data for machine learning tasks has seen a massive surge in popularity and shown promising results, e.g. in the field of map perception. Despite that, a standardized HD map framework supporting all parts of map-based automated driving and training label generation from map data does not exist. Furthermore, feeding map perception models with map data as part of the input during real-time inference is not addressed by the research community. In order to fill this gap, we presentlanelet2_ml_converter, an integrated extension to the HD map framework Lanelet2, widely used in automated driving systems by academia and industry. With this addition Lanelet2 unifies map based automated driving, machine learning inference and training, all from a single source of map data and format. Requirements for a unified framework are analyzed and the implementation of these requirements is described. The usability of labels in state of the art machine learning is demonstrated with application examples from the field of map perception. The source code is available embedded in the Lanelet2 framework under https://github.com/fzi-forschungszentrum-informatik/Lanelet2/tree/feature_ml_converter
MAP-Former: Multi-Agent-Pair Gaussian Joint Prediction
Apr 30, 2024



There is a gap in risk assessment of trajectories between the trajectory information coming from a traffic motion prediction module and what is actually needed. Closing this gap necessitates advancements in prediction beyond current practices. Existing prediction models yield joint predictions of agents' future trajectories with uncertainty weights or marginal Gaussian probability density functions (PDFs) for single agents. Although, these methods achieve high accurate trajectory predictions, they only provide little or no information about the dependencies of interacting agents. Since traffic is a process of highly interdependent agents, whose actions directly influence their mutual behavior, the existing methods are not sufficient to reliably assess the risk of future trajectories. This paper addresses that gap by introducing a novel approach to motion prediction, focusing on predicting agent-pair covariance matrices in a ``scene-centric'' manner, which can then be used to model Gaussian joint PDFs for all agent-pairs in a scene. We propose a model capable of predicting those agent-pair covariance matrices, leveraging an enhanced awareness of interactions. Utilizing the prediction results of our model, this work forms the foundation for comprehensive risk assessment with statistically based methods for analyzing agents' relations by their joint PDFs.
PITA: Physics-Informed Trajectory Autoencoder
Mar 18, 2024Validating robotic systems in safety-critical appli-cations requires testing in many scenarios including rare edgecases that are unlikely to occur, requiring to complement real-world testing with testing in simulation. Generative models canbe used to augment real-world datasets with generated data toproduce edge case scenarios by sampling in a learned latentspace. Autoencoders can learn said latent representation for aspecific domain by learning to reconstruct the input data froma lower-dimensional intermediate representation. However, theresulting trajectories are not necessarily physically plausible, butinstead typically contain noise that is not present in the inputtrajectory. To resolve this issue, we propose the novel Physics-Informed Trajectory Autoencoder (PITA) architecture, whichincorporates a physical dynamics model into the loss functionof the autoencoder. This results in smooth trajectories that notonly reconstruct the input trajectory but also adhere to thephysical model. We evaluate PITA on a real-world dataset ofvehicle trajectories and compare its performance to a normalautoencoder and a state-of-the-art action-space autoencoder.
YOLinO++: Single-Shot Estimation of Generic Polylines for Mapless Automated Diving
Feb 01, 2024In automated driving, highly accurate maps are commonly used to support and complement perception. These maps are costly to create and quickly become outdated as the traffic world is permanently changing. In order to support or replace the map of an automated system with detections from sensor data, a perception module must be able to detect the map features. We propose a neural network that follows the one shot philosophy of YOLO but is designed for detection of 1D structures in images, such as lane boundaries. We extend previous ideas by a midpoint based line representation and anchor definitions. This representation can be used to describe lane borders, markings, but also implicit features such as centerlines of lanes. The broad applicability of the approach is shown with the detection performance on lane centerlines, lane borders as well as the markings both on highways and in urban areas. Versatile lane boundaries are detected and can be inherently classified as dashed or solid lines, curb, road boundaries, or implicit delimitation.
Decision-theoretic MPC: Motion Planning with Weighted Maneuver Preferences Under Uncertainty
Oct 27, 2023



Continuous optimization based motion planners require deciding on a maneuver homotopy before optimizing the trajectory. Under uncertainty, maneuver intentions of other participants can be unclear, and the vehicle might not be able to decide on the most suitable maneuver. This work introduces a method that incorporates multiple maneuver preferences in planning. It optimizes the trajectory by considering weighted maneuver preferences together with uncertainties ranging from perception to prediction while ensuring the feasibility of a chance-constrained fallback option. Evaluations in both driving experiments and simulation studies show enhanced interaction capabilities and comfort levels compared to conventional planners, which consider only a single maneuver.
HD Map Generation from Noisy Multi-Route Vehicle Fleet Data on Highways with Expectation Maximization
May 03, 2023High Definition (HD) maps are necessary for many applications of automated driving (AD), but their manual creation and maintenance is very costly. Vehicle fleet data from series production vehicles can be used to automatically generate HD maps, but the data is often incomplete and noisy. We propose a system for the generation of HD maps from vehicle fleet data, which is tolerant to missing or misclassified detections and can handle drives with multiple routes, generating a single complete map, model-free and without prior reference lines. Using randomly selected drives as pivot drives, a step-wise lateral sampling of detections is performed. These sampled points are then clustered and aligned using Expectation Maximization (EM), estimating a lateral offset for each drive to compensate localization errors. The clustered points are replaced with the maxima of their probability density function (PDF) and connected to form polylines using a modified rectangular linear assignment algorithm. The data from vehicles on varying routes is then fused into a hierarchical singular map graph. The proposed approach achieves an average accuracy below 0.5 meters compared to a hand annotated ground truth map, as well as correctly resolving lane splits and merges, proving the feasibility of the use of vehicle fleet data for the generation of highway HD maps.
Self-supervised Pseudo-colorizing of Masked Cells
Feb 12, 2023Self-supervised learning, which is strikingly referred to as the dark matter of intelligence, is gaining more attention in biomedical applications of deep learning. In this work, we introduce a novel self-supervision objective for the analysis of cells in biomedical microscopy images. We propose training deep learning models to pseudo-colorize masked cells. We use a physics-informed pseudo-spectral colormap that is well suited for colorizing cell topology. Our experiments reveal that approximating semantic segmentation by pseudo-colorization is beneficial for subsequent fine-tuning on cell detection. Inspired by the recent success of masked image modeling, we additionally mask out cell parts and train to reconstruct these parts to further enrich the learned representations. We compare our pre-training method with self-supervised frameworks including contrastive learning (SimCLR), masked autoencoders (MAEs), and edge-based self-supervision. We build upon our previous work and train hybrid models for cell detection, which contain both convolutional and vision transformer modules. Our pre-training method can outperform SimCLR, MAE-like masked image modeling, and edge-based self-supervision when pre-training on a diverse set of six fluorescence microscopy datasets. Code is available at: https://github.com/roydenwa/cell-centroid-former
Space, Time, and Interaction: A Taxonomy of Corner Cases in Trajectory Datasets for Automated Driving
Oct 17, 2022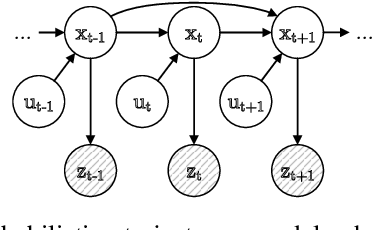
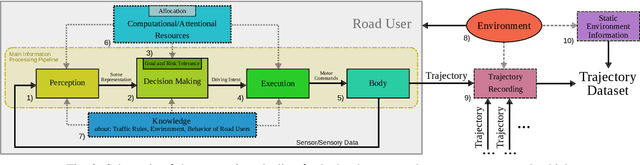
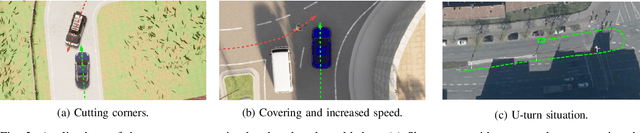
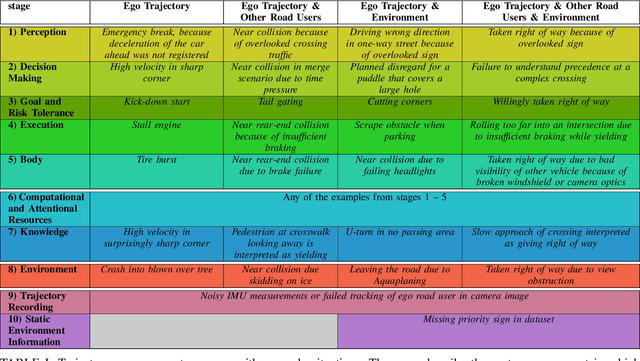
Trajectory data analysis is an essential component for highly automated driving. Complex models developed with these data predict other road users' movement and behavior patterns. Based on these predictions - and additional contextual information such as the course of the road, (traffic) rules, and interaction with other road users - the highly automated vehicle (HAV) must be able to reliably and safely perform the task assigned to it, e.g., moving from point A to B. Ideally, the HAV moves safely through its environment, just as we would expect a human driver to do. However, if unusual trajectories occur, so-called trajectory corner cases, a human driver can usually cope well, but an HAV can quickly get into trouble. In the definition of trajectory corner cases, which we provide in this work, we will consider the relevance of unusual trajectories with respect to the task at hand. Based on this, we will also present a taxonomy of different trajectory corner cases. The categorization of corner cases into the taxonomy will be shown with examples and is done by cause and required data sources. To illustrate the complexity between the machine learning (ML) model and the corner case cause, we present a general processing chain underlying the taxonomy.