 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSA-SDR: A novel loss function for separation of meeting style data
Oct 29, 2021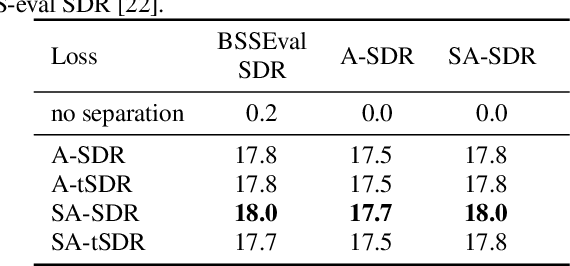
Many state-of-the-art neural network-based source separation systems use the averaged Signal-to-Distortion Ratio (SDR) as a training objective function. The basic SDR is, however, undefined if the network reconstructs the reference signal perfectly or if the reference signal contains silence, e.g., when a two-output separator processes a single-speaker recording. Many modifications to the plain SDR have been proposed that trade-off between making the loss more robust and distorting its value. We propose to switch from a mean over the SDRs of each individual output channel to a global SDR over all output channels at the same time, which we call source-aggregated SDR (SA-SDR). This makes the loss robust against silence and perfect reconstruction as long as at least one reference signal is not silent. We experimentally show that our proposed SA-SDR is more stable and preferable over other well-known modifications when processing meeting-style data that typically contains many silent or single-speaker regions.
Graph-PIT: Generalized permutation invariant training for continuous separation of arbitrary numbers of speakers
Jul 30, 2021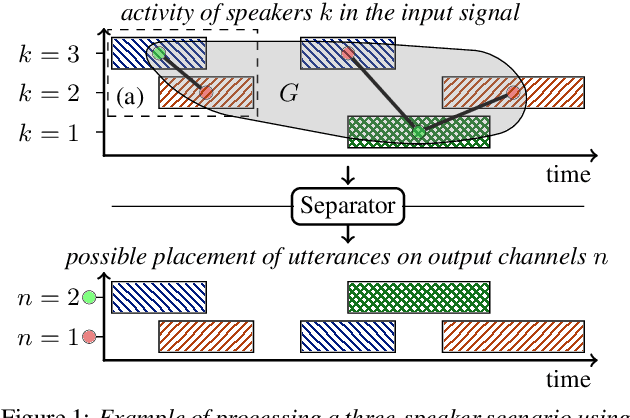
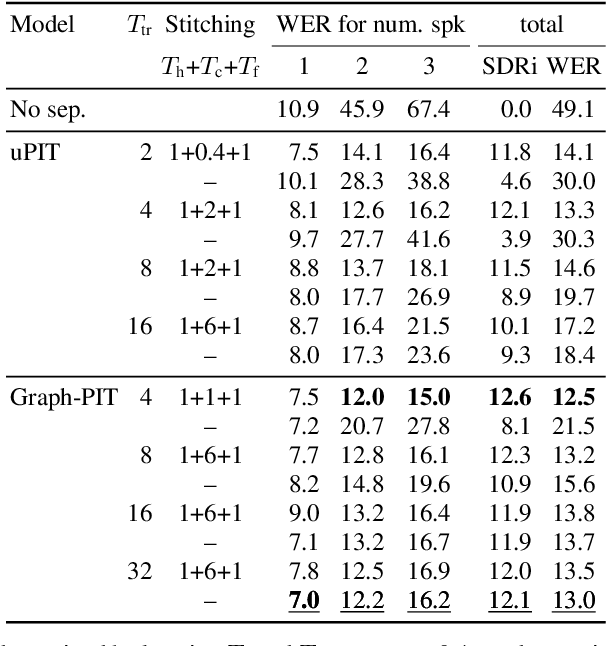
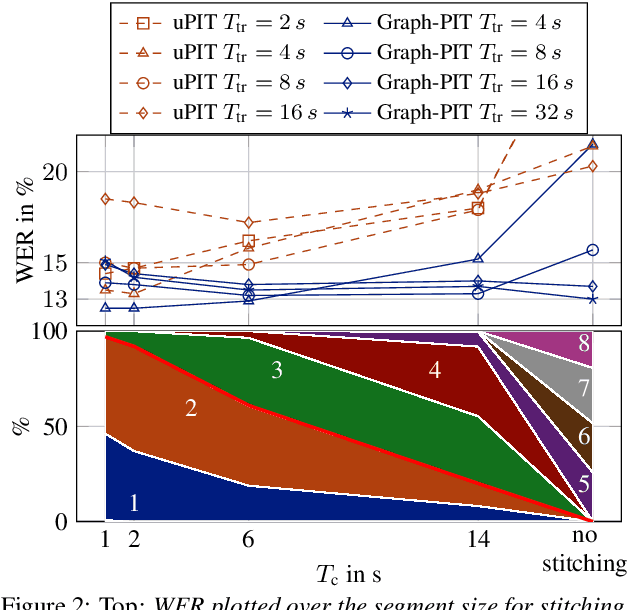
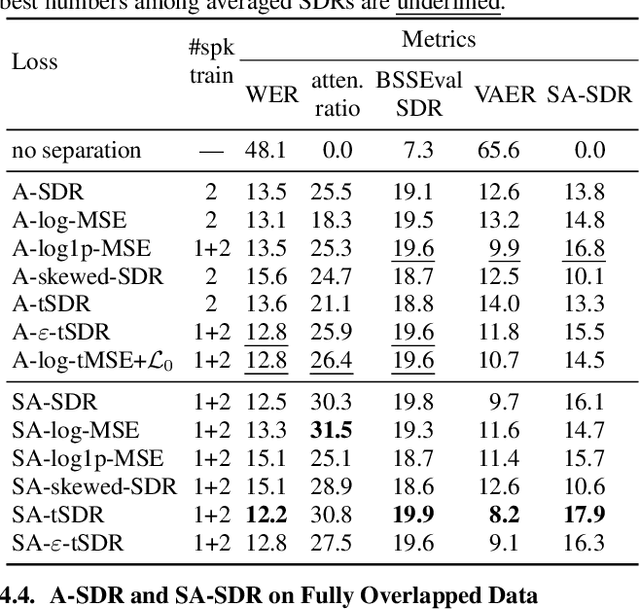
Automatic transcription of meetings requires handling of overlapped speech, which calls for continuous speech separation (CSS) systems. The uPIT criterion was proposed for utterance-level separation with neural networks and introduces the constraint that the total number of speakers must not exceed the number of output channels. When processing meeting-like data in a segment-wise manner, i.e., by separating overlapping segments independently and stitching adjacent segments to continuous output streams, this constraint has to be fulfilled for any segment. In this contribution, we show that this constraint can be significantly relaxed. We propose a novel graph-based PIT criterion, which casts the assignment of utterances to output channels in a graph coloring problem. It only requires that the number of concurrently active speakers must not exceed the number of output channels. As a consequence, the system can process an arbitrary number of speakers and arbitrarily long segments and thus can handle more diverse scenarios. Further, the stitching algorithm for obtaining a consistent output order in neighboring segments is of less importance and can even be eliminated completely, not the least reducing the computational effort. Experiments on meeting-style WSJ data show improvements in recognition performance over using the uPIT criterion.
Speeding Up Permutation Invariant Training for Source Separation
Jul 30, 2021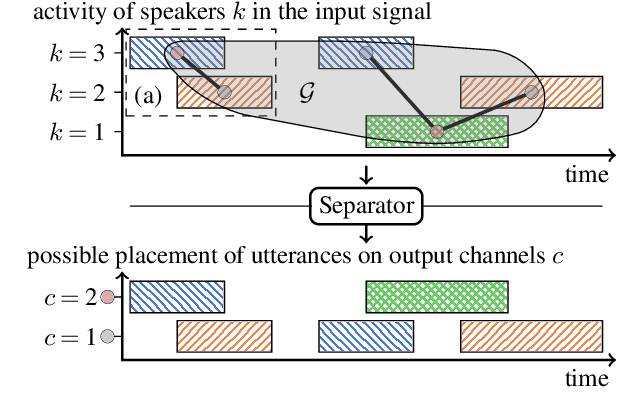
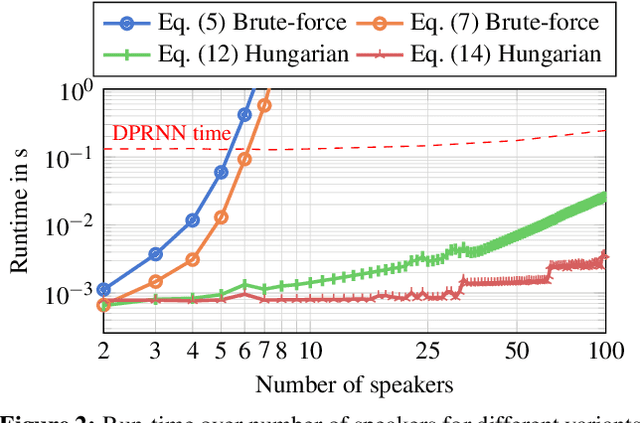
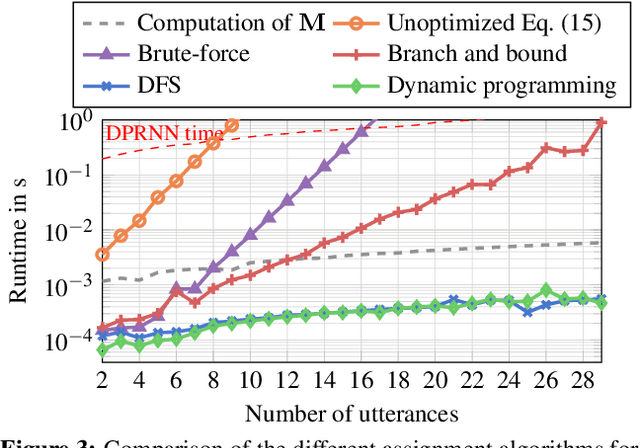
Permutation invariant training (PIT) is a widely used training criterion for neural network-based source separation, used for both utterance-level separation with utterance-level PIT (uPIT) and separation of long recordings with the recently proposed Graph-PIT. When implemented naively, both suffer from an exponential complexity in the number of utterances to separate, rendering them unusable for large numbers of speakers or long realistic recordings. We present a decomposition of the PIT criterion into the computation of a matrix and a strictly monotonously increasing function so that the permutation or assignment problem can be solved efficiently with several search algorithms. The Hungarian algorithm can be used for uPIT and we introduce various algorithms for the Graph-PIT assignment problem to reduce the complexity to be polynomial in the number of utterances.
A Comparison and Combination of Unsupervised Blind Source Separation Techniques
Jun 10, 2021
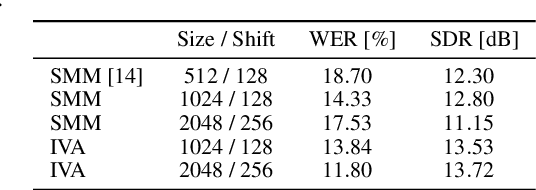
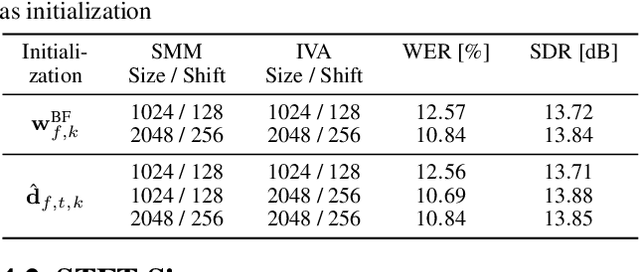
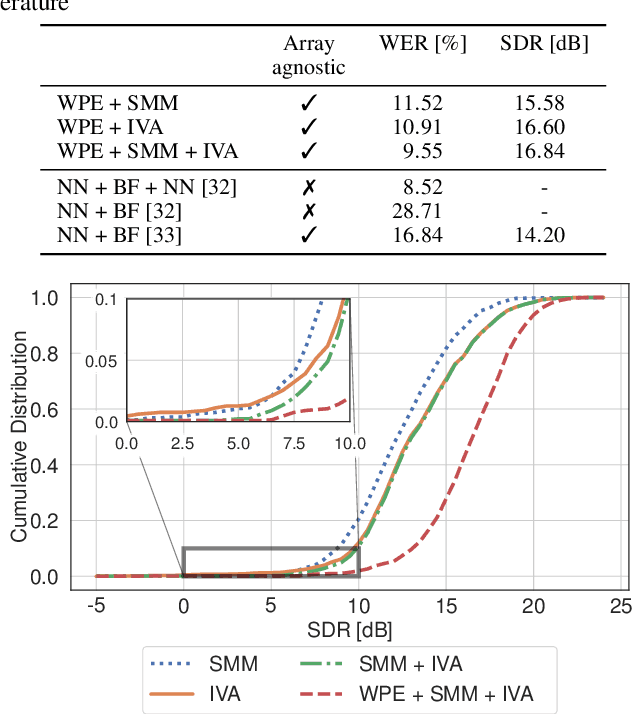
Unsupervised blind source separation methods do not require a training phase and thus cannot suffer from a train-test mismatch, which is a common concern in neural network based source separation. The unsupervised techniques can be categorized in two classes, those building upon the sparsity of speech in the Short-Time Fourier transform domain and those exploiting non-Gaussianity or non-stationarity of the source signals. In this contribution, spatial mixture models which fall in the first category and independent vector analysis (IVA) as a representative of the second category are compared w.r.t. their separation performance and the performance of a downstream speech recognizer on a reverberant dataset of reasonable size. Furthermore, we introduce a serial concatenation of the two, where the result of the mixture model serves as initialization of IVA, which achieves significantly better WER performance than each algorithm individually and even approaches the performance of a much more complex neural network based technique.
End-to-End Dereverberation, Beamforming, and Speech Recognition with Improved Numerical Stability and Advanced Frontend
Feb 23, 2021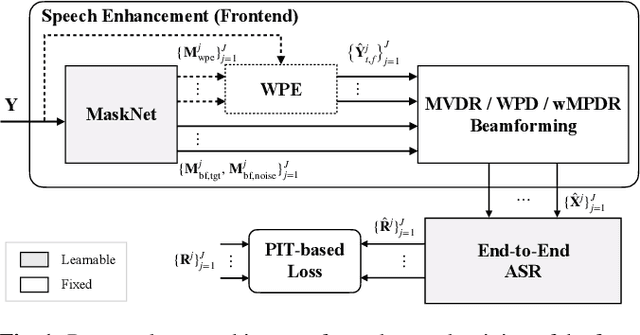
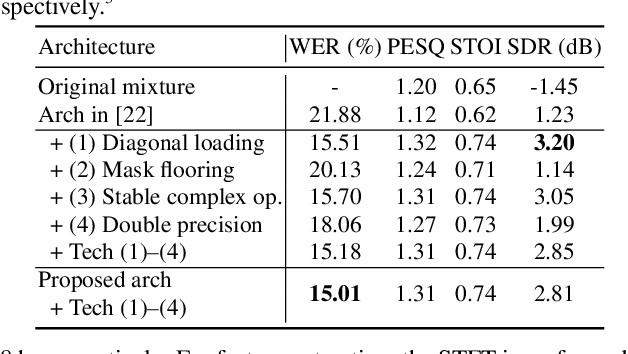
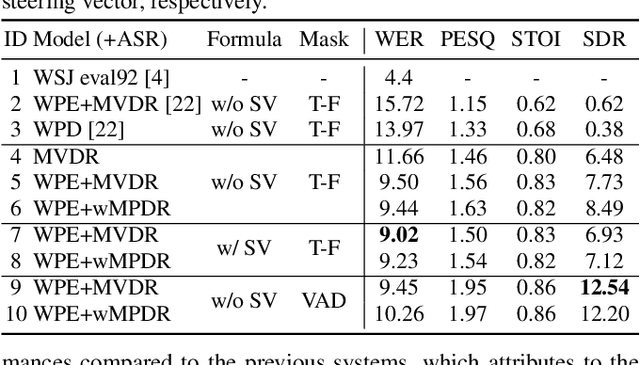
Recently, the end-to-end approach has been successfully applied to multi-speaker speech separation and recognition in both single-channel and multichannel conditions. However, severe performance degradation is still observed in the reverberant and noisy scenarios, and there is still a large performance gap between anechoic and reverberant conditions. In this work, we focus on the multichannel multi-speaker reverberant condition, and propose to extend our previous framework for end-to-end dereverberation, beamforming, and speech recognition with improved numerical stability and advanced frontend subnetworks including voice activity detection like masks. The techniques significantly stabilize the end-to-end training process. The experiments on the spatialized wsj1-2mix corpus show that the proposed system achieves about 35% WER relative reduction compared to our conventional multi-channel E2E ASR system, and also obtains decent speech dereverberation and separation performance (SDR=12.5 dB) in the reverberant multi-speaker condition while trained only with the ASR criterion.
Multi-talker ASR for an unknown number of sources: Joint training of source counting, separation and ASR
Jun 04, 2020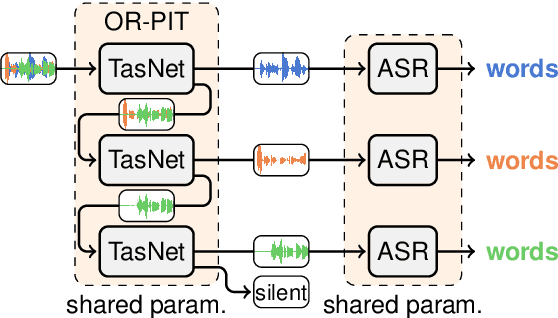
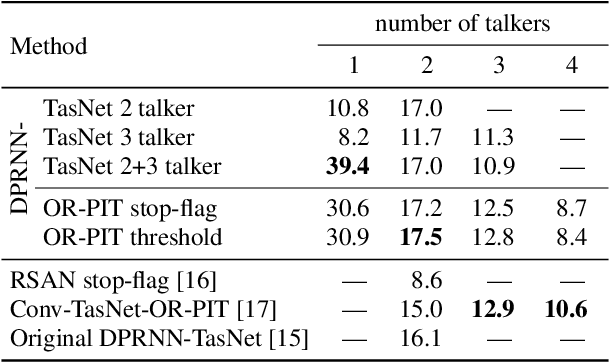
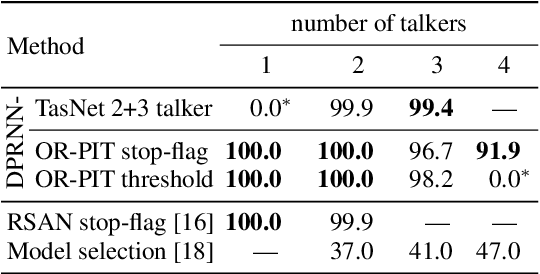
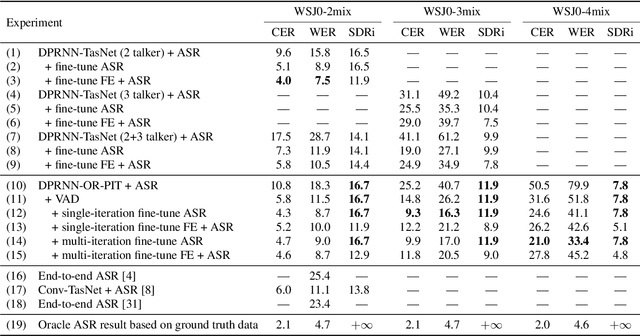
Most approaches to multi-talker overlapped speech separation and recognition assume that the number of simultaneously active speakers is given, but in realistic situations, it is typically unknown. To cope with this, we extend an iterative speech extraction system with mechanisms to count the number of sources and combine it with a single-talker speech recognizer to form the first end-to-end multi-talker automatic speech recognition system for an unknown number of active speakers. Our experiments show very promising performance in counting accuracy, source separation and speech recognition on simulated clean mixtures from WSJ0-2mix and WSJ0-3mix. Among others, we set a new state-of-the-art word error rate on the WSJ0-2mix database. Furthermore, our system generalizes well to a larger number of speakers than it ever saw during training, as shown in experiments with the WSJ0-4mix database.
CHiME-6 Challenge:Tackling Multispeaker Speech Recognition for Unsegmented Recordings
May 02, 2020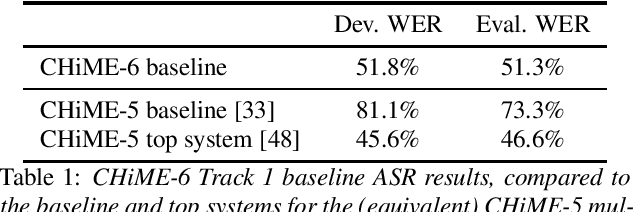

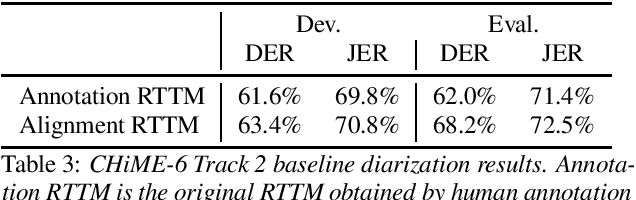

Following the success of the 1st, 2nd, 3rd, 4th and 5th CHiME challenges we organize the 6th CHiME Speech Separation and Recognition Challenge (CHiME-6). The new challenge revisits the previous CHiME-5 challenge and further considers the problem of distant multi-microphone conversational speech diarization and recognition in everyday home environments. Speech material is the same as the previous CHiME-5 recordings except for accurate array synchronization. The material was elicited using a dinner party scenario with efforts taken to capture data that is representative of natural conversational speech. This paper provides a baseline description of the CHiME-6 challenge for both segmented multispeaker speech recognition (Track 1) and unsegmented multispeaker speech recognition (Track 2). Of note, Track 2 is the first challenge activity in the community to tackle an unsegmented multispeaker speech recognition scenario with a complete set of reproducible open source baselines providing speech enhancement, speaker diarization, and speech recognition modules.
End-to-end training of time domain audio separation and recognition
Dec 25, 2019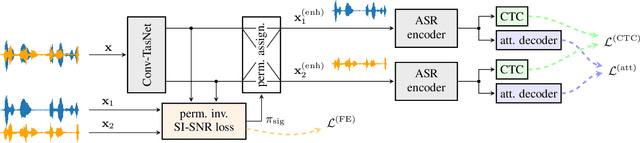


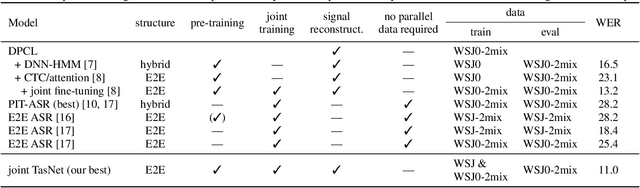
The rising interest in single-channel multi-speaker speech separation sparked development of End-to-End (E2E) approaches to multi-speaker speech recognition. However, up until now, state-of-the-art neural network-based time domain source separation has not yet been combined with E2E speech recognition. We here demonstrate how to combine a separation module based on a Convolutional Time domain Audio Separation Network (Conv-TasNet) with an E2E speech recognizer and how to train such a model jointly by distributing it over multiple GPUs or by approximating truncated back-propagation for the convolutional front-end. To put this work into perspective and illustrate the complexity of the design space, we provide a compact overview of single-channel multi-speaker recognition systems. Our experiments show a word error rate of 11.0% on WSJ0-2mix and indicate that our joint time domain model can yield substantial improvements over cascade DNN-HMM and monolithic E2E frequency domain systems proposed so far.
Demystifying TasNet: A Dissecting Approach
Nov 20, 2019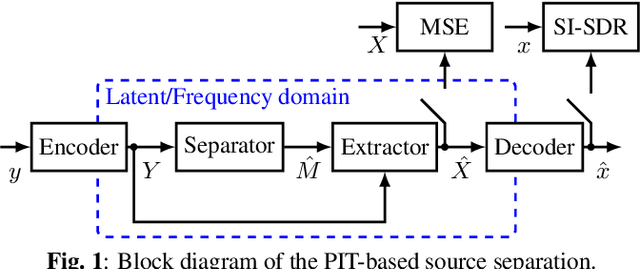
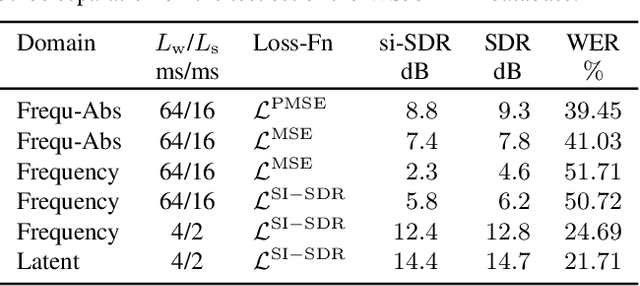
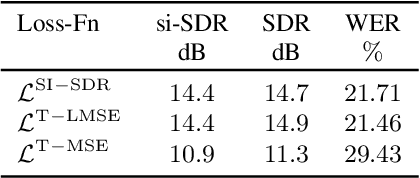
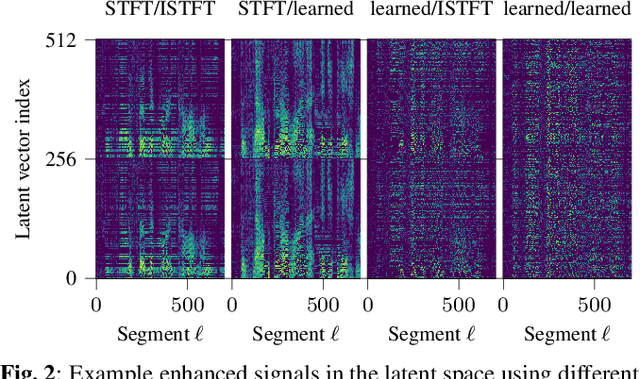
In recent years time domain speech separation has excelled over frequency domain separation in single channel scenarios and noise-free environments. In this paper we dissect the gains of the time-domain audio separation network (TasNet) approach by gradually replacing components of an utterance-level permutation invariant training (u-PIT) based separation system in the frequency domain until the TasNet system is reached, thus blending components of frequency domain approaches with those of time domain approaches. Some of the intermediate variants achieve comparable signal-to-distortion ratio (SDR) gains to TasNet, but retain the advantage of frequency domain processing: compatibility with classic signal processing tools such as frequency-domain beamforming and the human interpretability of the masks. Furthermore, we show that the scale invariant signal-to-distortion ratio (si-SDR) criterion used as loss function in TasNet is related to a logarithmic mean square error criterion and that it is this criterion which contributes most reliable to the performance advantage of TasNet. Finally, we critically assess which gains in a noise-free single channel environment generalize to more realistic reverberant conditions.
SMS-WSJ: Database, performance measures, and baseline recipe for multi-channel source separation and recognition
Oct 30, 2019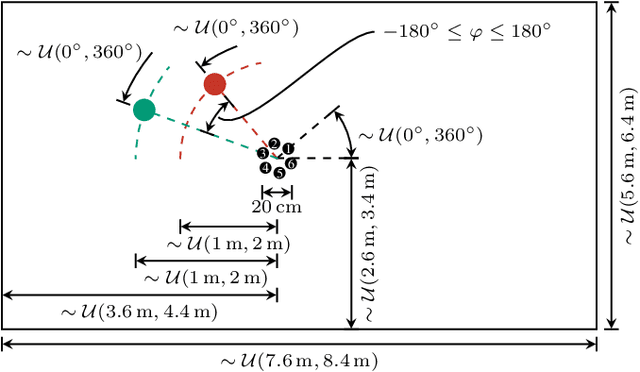
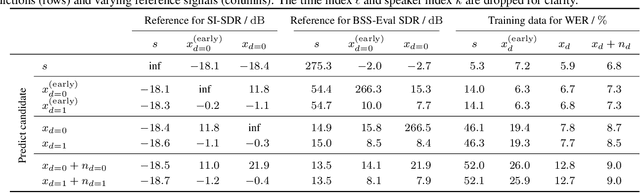
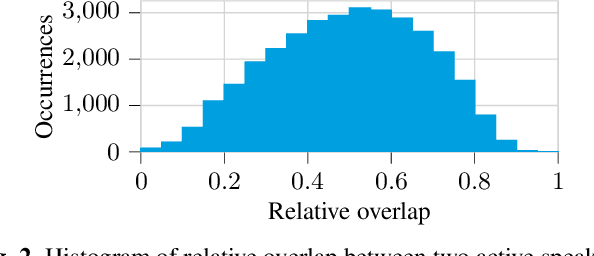
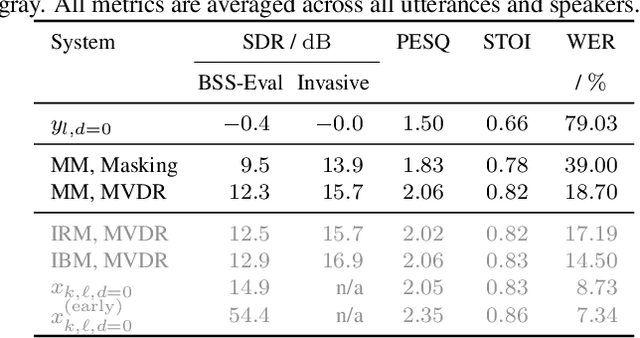
We present a multi-channel database of overlapping speech for training, evaluation, and detailed analysis of source separation and extraction algorithms: SMS-WSJ -- Spatialized Multi-Speaker Wall Street Journal. It consists of artificially mixed speech taken from the WSJ database, but unlike earlier databases we consider all WSJ0+1 utterances and take care of strictly separating the speaker sets present in the training, validation and test sets. When spatializing the data we ensure a high degree of randomness w.r.t. room size, array center and rotation, as well as speaker position. Furthermore, this paper offers a critical assessment of recently proposed measures of source separation performance. Alongside the code to generate the database we provide a source separation baseline and a Kaldi recipe with competitive word error rates to provide common ground for evaluation.