 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain Agnostic Image-to-image Translation using Low-Resolution Conditioning
May 11, 2023Generally, image-to-image translation (i2i) methods aim at learning mappings across domains with the assumption that the images used for translation share content (e.g., pose) but have their own domain-specific information (a.k.a. style). Conditioned on a target image, such methods extract the target style and combine it with the source image content, keeping coherence between the domains. In our proposal, we depart from this traditional view and instead consider the scenario where the target domain is represented by a very low-resolution (LR) image, proposing a domain-agnostic i2i method for fine-grained problems, where the domains are related. More specifically, our domain-agnostic approach aims at generating an image that combines visual features from the source image with low-frequency information (e.g. pose, color) of the LR target image. To do so, we present a novel approach that relies on training the generative model to produce images that both share distinctive information of the associated source image and correctly match the LR target image when downscaled. We validate our method on the CelebA-HQ and AFHQ datasets by demonstrating improvements in terms of visual quality. Qualitative and quantitative results show that when dealing with intra-domain image translation, our method generates realistic samples compared to state-of-the-art methods such as StarGAN v2. Ablation studies also reveal that our method is robust to changes in color, it can be applied to out-of-distribution images, and it allows for manual control over the final results.
Improved Robustness Against Adaptive Attacks With Ensembles and Error-Correcting Output Codes
Mar 04, 2023Neural network ensembles have been studied extensively in the context of adversarial robustness and most ensemble-based approaches remain vulnerable to adaptive attacks. In this paper, we investigate the robustness of Error-Correcting Output Codes (ECOC) ensembles through architectural improvements and ensemble diversity promotion. We perform a comprehensive robustness assessment against adaptive attacks and investigate the relationship between ensemble diversity and robustness. Our results demonstrate the benefits of ECOC ensembles for adversarial robustness compared to regular ensembles of convolutional neural networks (CNNs) and show why the robustness of previous implementations is limited. We also propose an adversarial training method specific to ECOC ensembles that allows to further improve robustness to adaptive attacks.
On Learning Fairness and Accuracy on Multiple Subgroups
Oct 19, 2022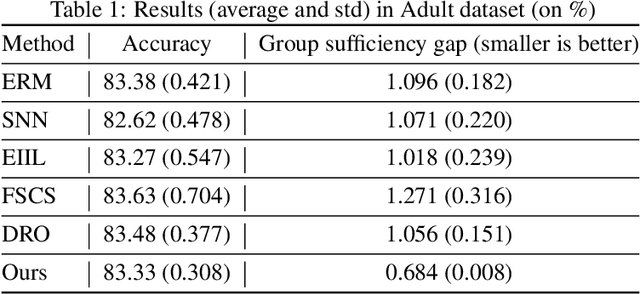
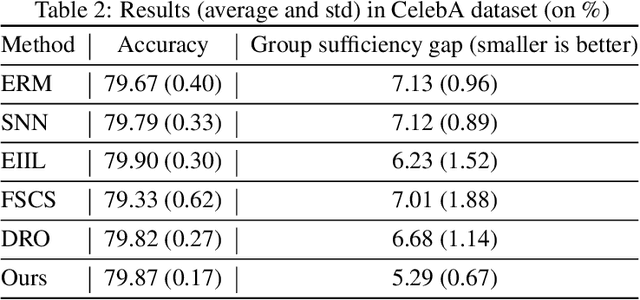
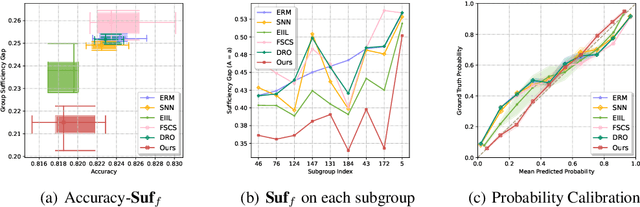
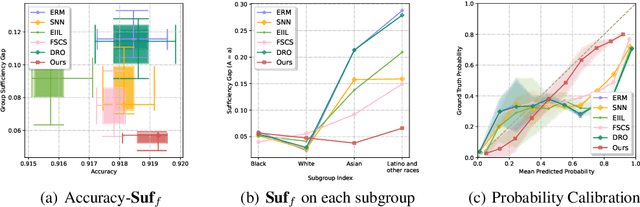
We propose an analysis in fair learning that preserves the utility of the data while reducing prediction disparities under the criteria of group sufficiency. We focus on the scenario where the data contains multiple or even many subgroups, each with limited number of samples. As a result, we present a principled method for learning a fair predictor for all subgroups via formulating it as a bilevel objective. Specifically, the subgroup specific predictors are learned in the lower-level through a small amount of data and the fair predictor. In the upper-level, the fair predictor is updated to be close to all subgroup specific predictors. We further prove that such a bilevel objective can effectively control the group sufficiency and generalization error. We evaluate the proposed framework on real-world datasets. Empirical evidence suggests the consistently improved fair predictions, as well as the comparable accuracy to the baselines.
Evolving Domain Generalization
Jun 07, 2022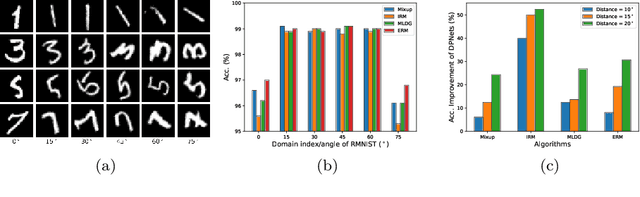
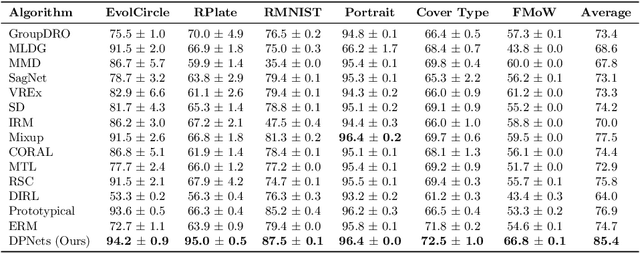


Domain generalization aims to learn a predictive model from multiple different but related source tasks that can generalize well to a target task without the need of accessing any target data. Existing domain generalization methods ignore the relationship between tasks, implicitly assuming that all the tasks are sampled from a stationary environment. Therefore, they can fail when deployed in an evolving environment. To this end, we formulate and study the \emph{evolving domain generalization} (EDG) scenario, which exploits not only the source data but also their evolving pattern to generate a model for the unseen task. Our theoretical result reveals the benefits of modeling the relation between two consecutive tasks by learning a globally consistent directional mapping function. In practice, our analysis also suggests solving the DDG problem in a meta-learning manner, which leads to \emph{directional prototypical network}, the first method for the DDG problem. Empirical evaluation of both synthetic and real-world data sets validates the effectiveness of our approach.
Fair Representation Learning through Implicit Path Alignment
May 26, 2022
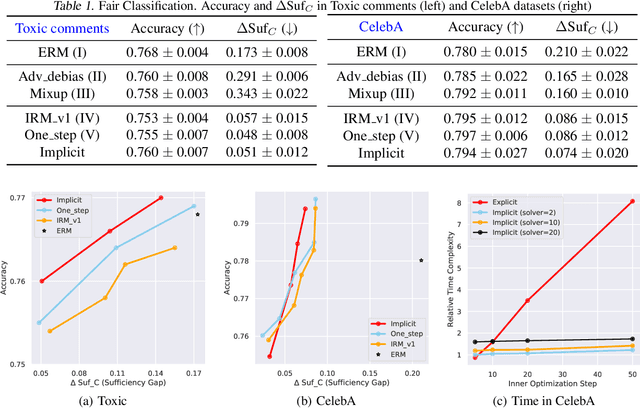
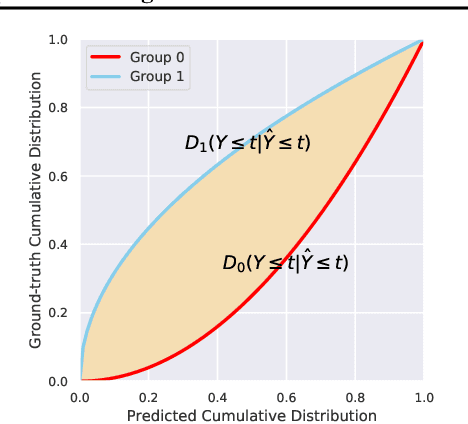
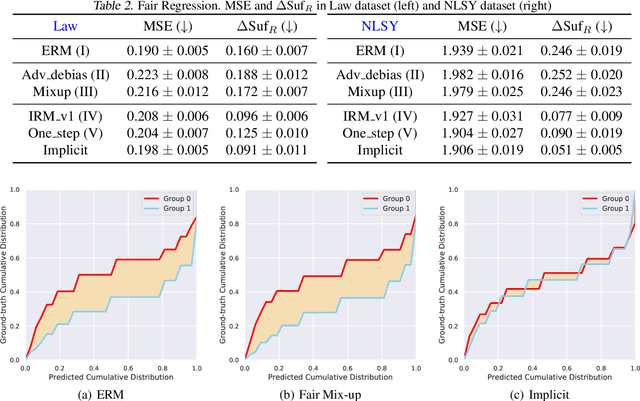
We consider a fair representation learning perspective, where optimal predictors, on top of the data representation, are ensured to be invariant with respect to different sub-groups. Specifically, we formulate this intuition as a bi-level optimization, where the representation is learned in the outer-loop, and invariant optimal group predictors are updated in the inner-loop. Moreover, the proposed bi-level objective is demonstrated to fulfill the sufficiency rule, which is desirable in various practical scenarios but was not commonly studied in the fair learning. Besides, to avoid the high computational and memory cost of differentiating in the inner-loop of bi-level objective, we propose an implicit path alignment algorithm, which only relies on the solution of inner optimization and the implicit differentiation rather than the exact optimization path. We further analyze the error gap of the implicit approach and empirically validate the proposed method in both classification and regression settings. Experimental results show the consistently better trade-off in prediction performance and fairness measurement.
Matching Feature Sets for Few-Shot Image Classification
Apr 02, 2022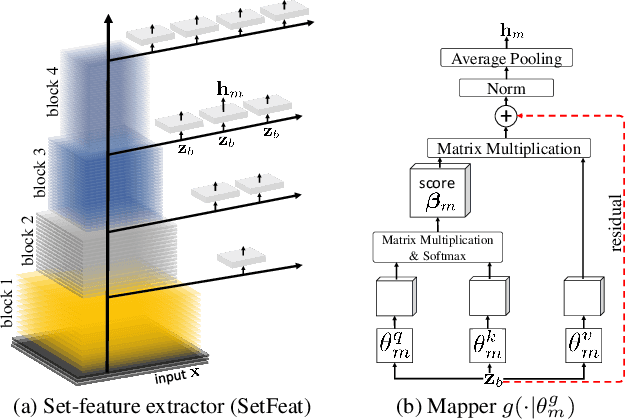
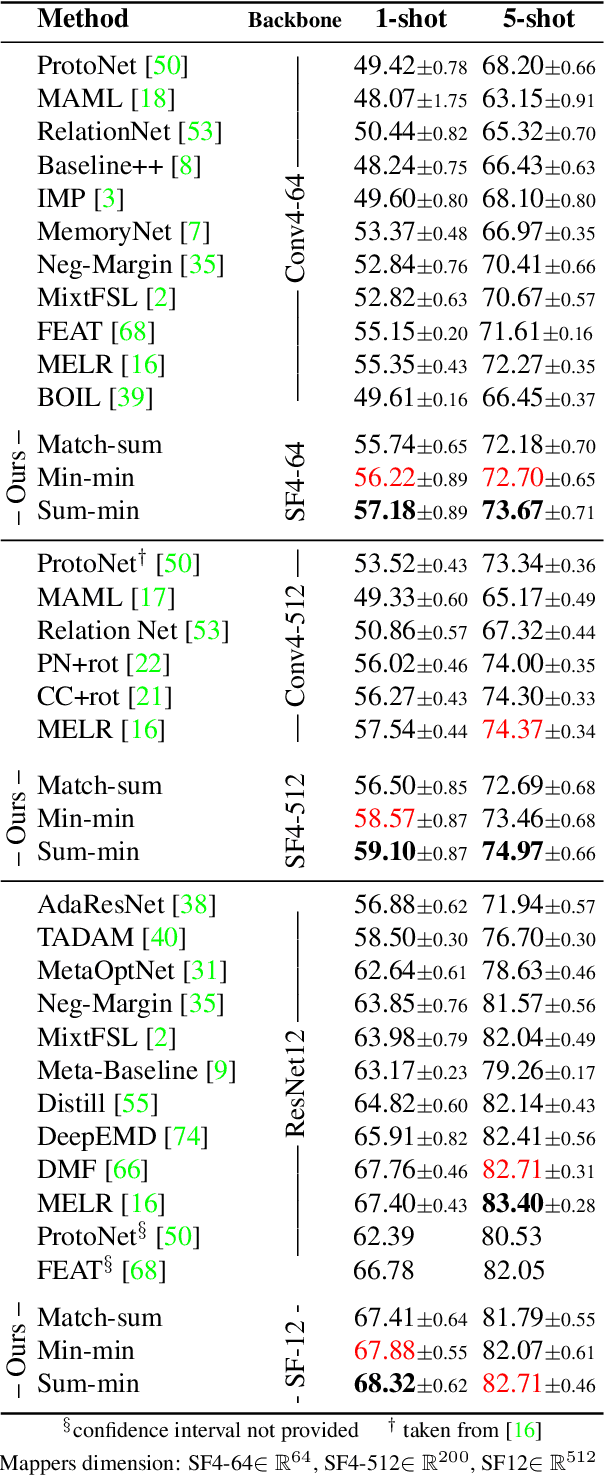
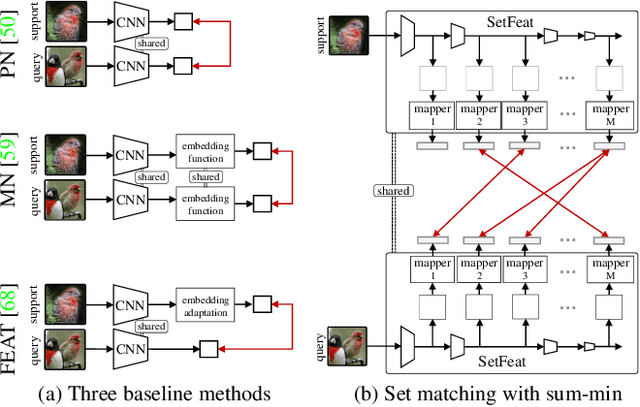
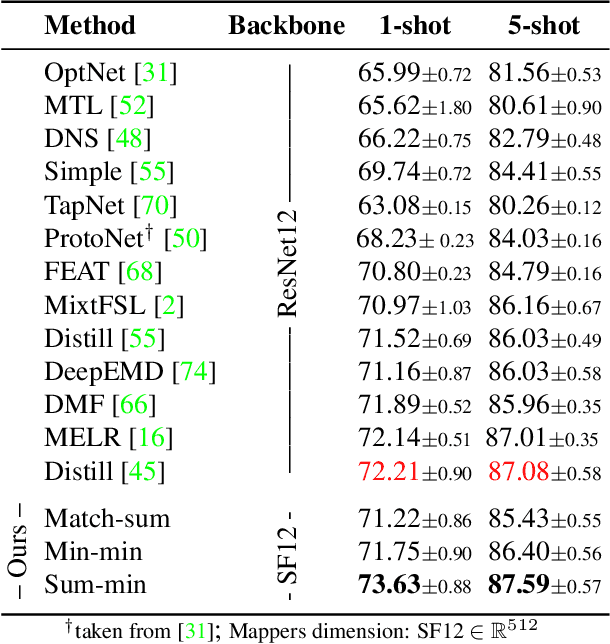
In image classification, it is common practice to train deep networks to extract a single feature vector per input image. Few-shot classification methods also mostly follow this trend. In this work, we depart from this established direction and instead propose to extract sets of feature vectors for each image. We argue that a set-based representation intrinsically builds a richer representation of images from the base classes, which can subsequently better transfer to the few-shot classes. To do so, we propose to adapt existing feature extractors to instead produce sets of feature vectors from images. Our approach, dubbed SetFeat, embeds shallow self-attention mechanisms inside existing encoder architectures. The attention modules are lightweight, and as such our method results in encoders that have approximately the same number of parameters as their original versions. During training and inference, a set-to-set matching metric is used to perform image classification. The effectiveness of our proposed architecture and metrics is demonstrated via thorough experiments on standard few-shot datasets -- namely miniImageNet, tieredImageNet, and CUB -- in both the 1- and 5-shot scenarios. In all cases but one, our method outperforms the state-of-the-art.
Gap Minimization for Knowledge Sharing and Transfer
Jan 26, 2022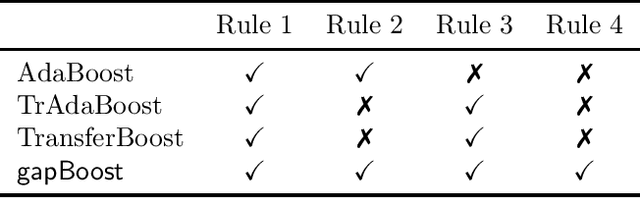
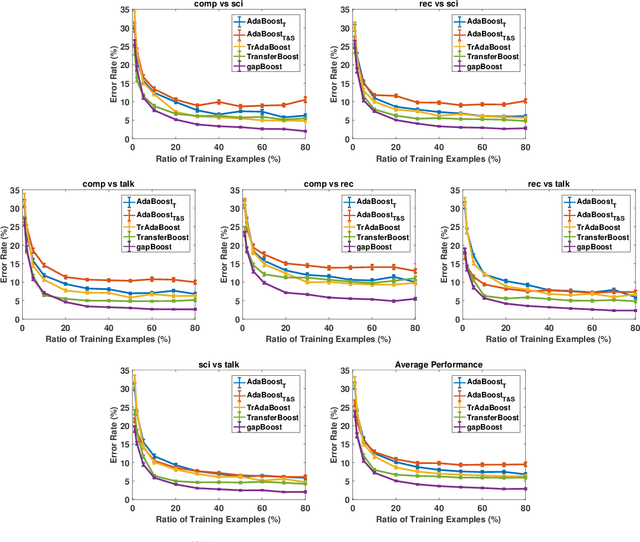
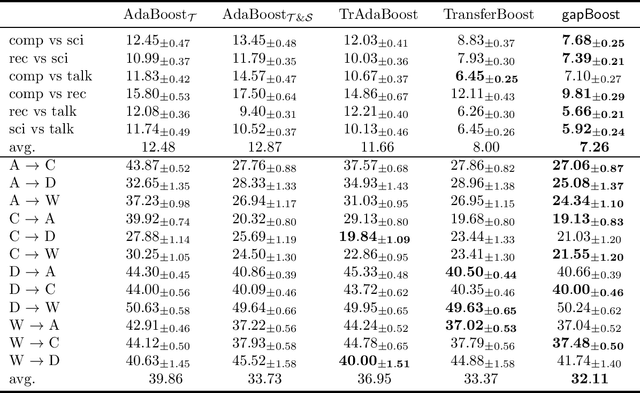
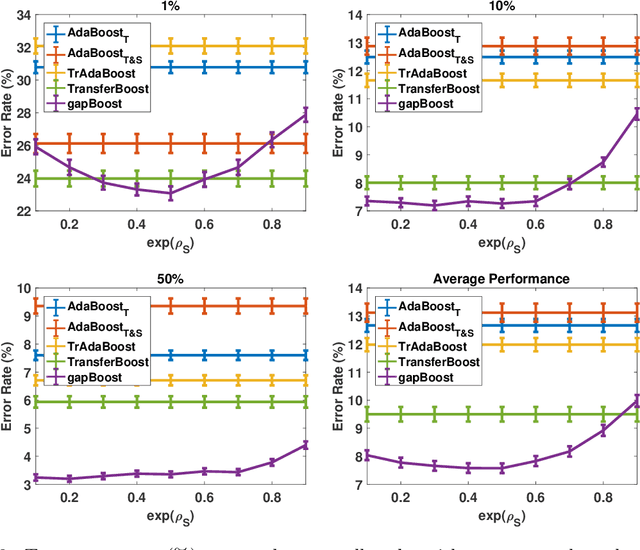
Learning from multiple related tasks by knowledge sharing and transfer has become increasingly relevant over the last two decades. In order to successfully transfer information from one task to another, it is critical to understand the similarities and differences between the domains. In this paper, we introduce the notion of \emph{performance gap}, an intuitive and novel measure of the distance between learning tasks. Unlike existing measures which are used as tools to bound the difference of expected risks between tasks (e.g., $\mathcal{H}$-divergence or discrepancy distance), we theoretically show that the performance gap can be viewed as a data- and algorithm-dependent regularizer, which controls the model complexity and leads to finer guarantees. More importantly, it also provides new insights and motivates a novel principle for designing strategies for knowledge sharing and transfer: gap minimization. We instantiate this principle with two algorithms: 1. {gapBoost}, a novel and principled boosting algorithm that explicitly minimizes the performance gap between source and target domains for transfer learning; and 2. {gapMTNN}, a representation learning algorithm that reformulates gap minimization as semantic conditional matching for multitask learning. Our extensive evaluation on both transfer learning and multitask learning benchmark data sets shows that our methods outperform existing baselines.
On the benefits of representation regularization in invariance based domain generalization
May 30, 2021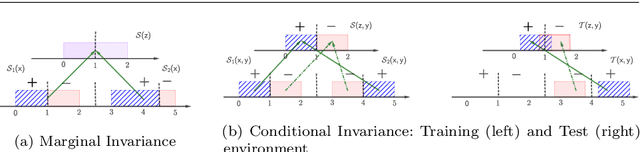
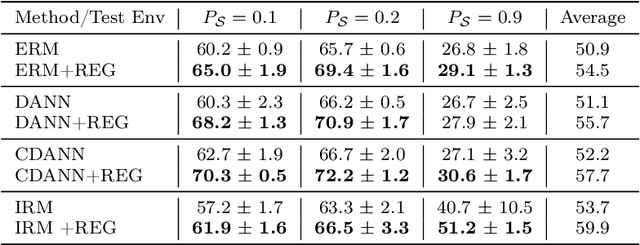
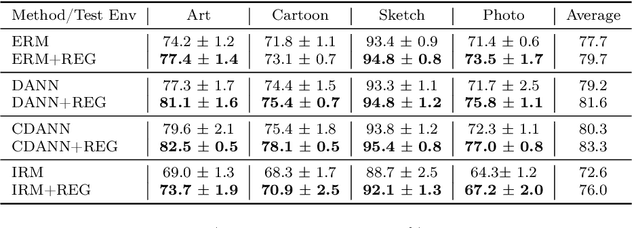
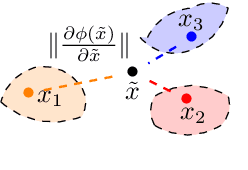
A crucial aspect in reliable machine learning is to design a deployable system in generalizing new related but unobserved environments. Domain generalization aims to alleviate such a prediction gap between the observed and unseen environments. Previous approaches commonly incorporated learning invariant representation for achieving good empirical performance. In this paper, we reveal that merely learning invariant representation is vulnerable to the unseen environment. To this end, we derive novel theoretical analysis to control the unseen test environment error in the representation learning, which highlights the importance of controlling the smoothness of representation. In practice, our analysis further inspires an efficient regularization method to improve the robustness in domain generalization. Our regularization is orthogonal to and can be straightforwardly adopted in existing domain generalization algorithms for invariant representation learning. Empirical results show that our algorithm outperforms the base versions in various dataset and invariance criteria.
Aggregating From Multiple Target-Shifted Sources
May 09, 2021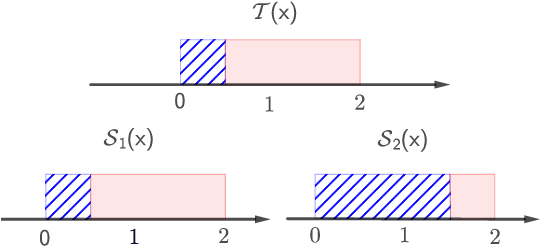
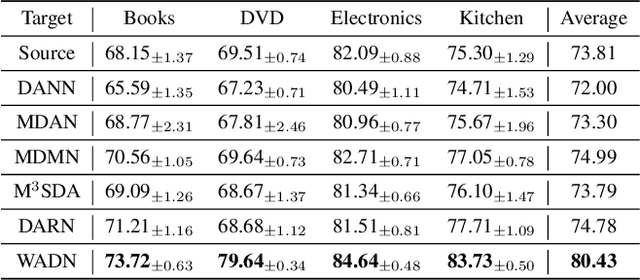
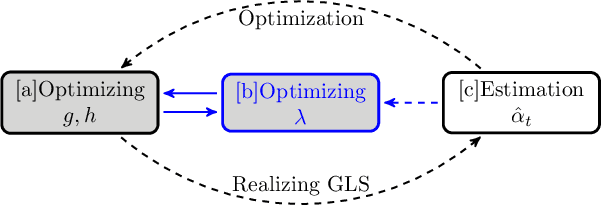
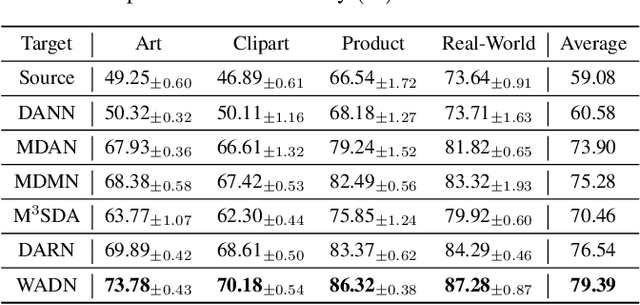
Multi-source domain adaptation aims at leveraging the knowledge from multiple tasks for predicting a related target domain. Hence, a crucial aspect is to properly combine different sources based on their relations. In this paper, we analyzed the problem for aggregating source domains with different label distributions, where most recent source selection approaches fail. Our proposed algorithm differs from previous approaches in two key ways: the model aggregates multiple sources mainly through the similarity of semantic conditional distribution rather than marginal distribution; the model proposes a \emph{unified} framework to select relevant sources for three popular scenarios, i.e., domain adaptation with limited label on target domain, unsupervised domain adaptation and label partial unsupervised domain adaption. We evaluate the proposed method through extensive experiments. The empirical results significantly outperform the baselines.
Meta Learning Black-Box Population-Based Optimizers
Mar 05, 2021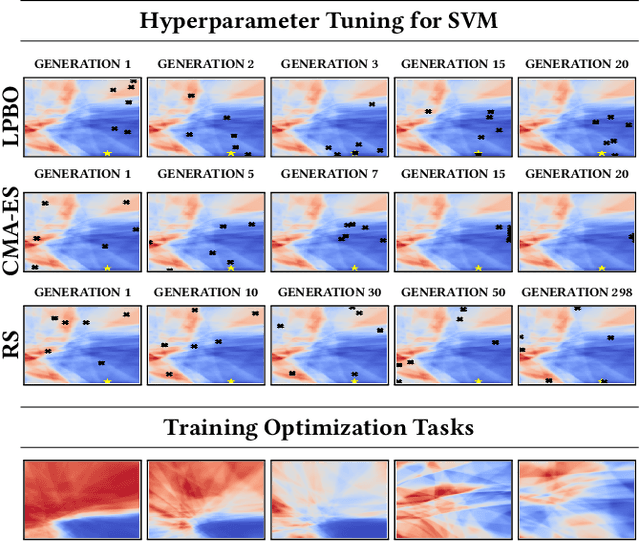
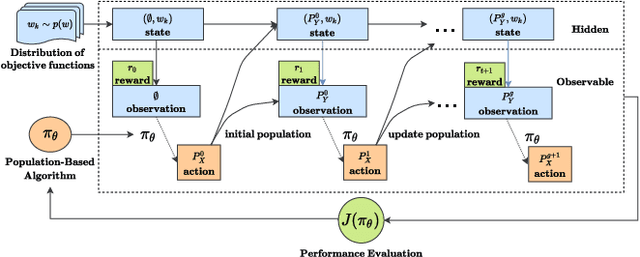
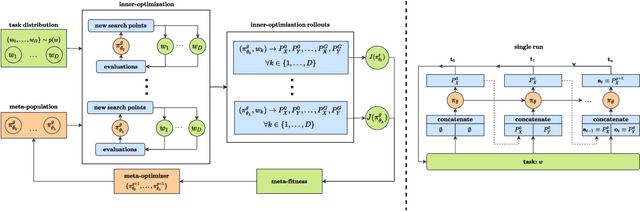
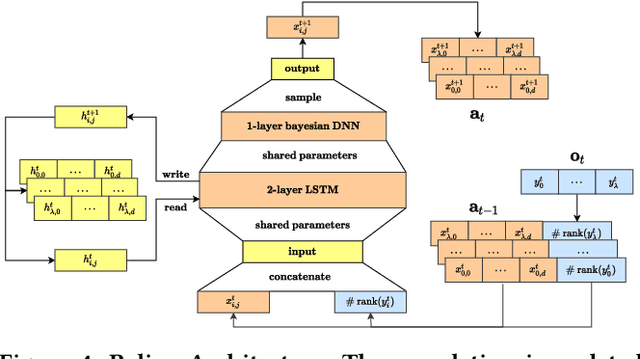
The no free lunch theorem states that no model is better suited to every problem. A question that arises from this is how to design methods that propose optimizers tailored to specific problems achieving state-of-the-art performance. This paper addresses this issue by proposing the use of meta-learning to infer population-based black-box optimizers that can automatically adapt to specific classes of problems. We suggest a general modeling of population-based algorithms that result in Learning-to-Optimize POMDP (LTO-POMDP), a meta-learning framework based on a specific partially observable Markov decision process (POMDP). From that framework's formulation, we propose to parameterize the algorithm using deep recurrent neural networks and use a meta-loss function based on stochastic algorithms' performance to train efficient data-driven optimizers over several related optimization tasks. The learned optimizers' performance based on this implementation is assessed on various black-box optimization tasks and hyperparameter tuning of machine learning models. Our results revealed that the meta-loss function encourages a learned algorithm to alter its search behavior so that it can easily fit into a new context. Thus, it allows better generalization and higher sample efficiency than state-of-the-art generic optimization algorithms, such as the Covariance matrix adaptation evolution strategy (CMA-ES).