 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Modal Learning meets Genetic Programming: Analyzing Alignment in Latent Space Optimization
Apr 09, 2026Symbolic regression (SR) aims to discover mathematical expressions from data, a task traditionally tackled using Genetic Programming (GP) through combinatorial search over symbolic structures. Latent Space Optimization (LSO) methods use neural encoders to map symbolic expressions into continuous spaces, transforming the combinatorial search into continuous optimization. SNIP (Meidani et al., 2024), a contrastive pre-training model inspired by CLIP, advances LSO by introducing a multi-modal approach: aligning symbolic and numeric encoders in a shared latent space to learn the phenotype-genotype mapping, enabling optimization in the numeric space to implicitly guide symbolic search. However, this relies on fine-grained cross-modal alignment, whereas literature on similar models like CLIP reveals that such an alignment is typically coarse-grained. In this paper, we investigate whether SNIP delivers on its promise of effective bi-modal optimization for SR. Our experiments show that: (1) cross-modal alignment does not improve during optimization, even as fitness increases, and (2) the alignment learned by SNIP is too coarse to efficiently conduct principled search in the symbolic space. These findings reveal that while multi-modal LSO holds significant potential for SR, effective alignment-guided optimization remains unrealized in practice, highlighting fine-grained alignment as a critical direction for future work.
Meta Learning Black-Box Population-Based Optimizers
Mar 05, 2021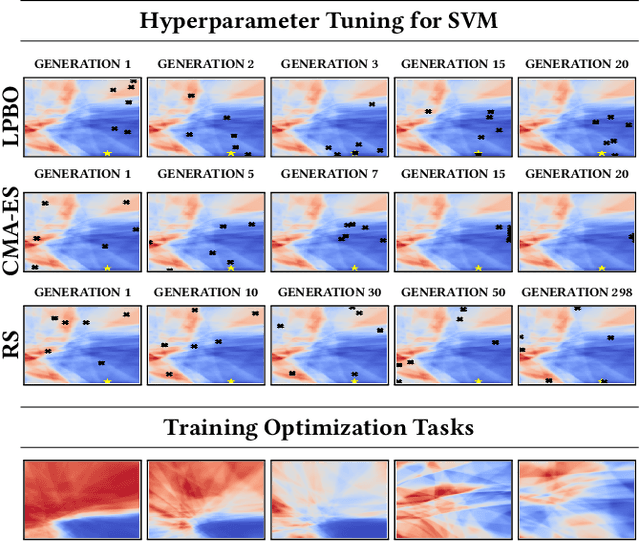
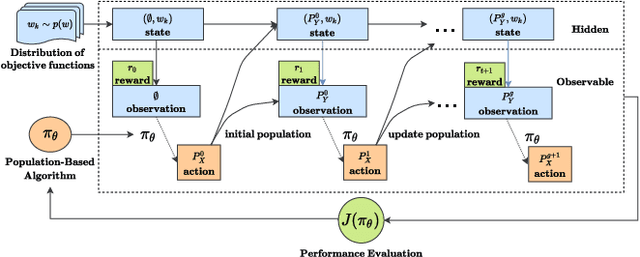
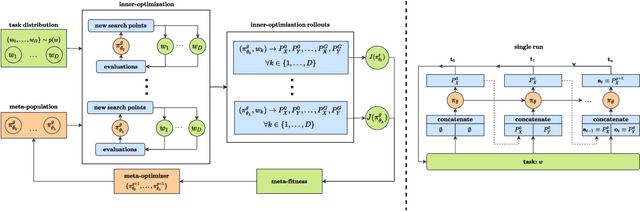
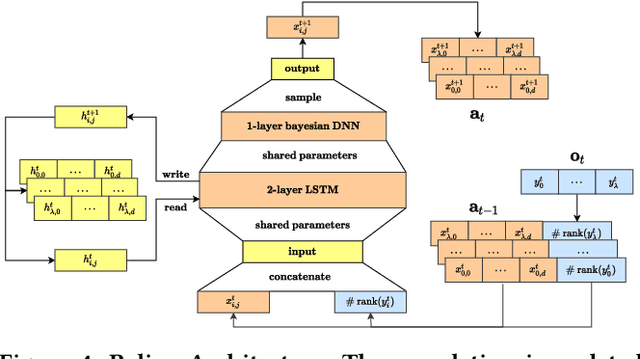
The no free lunch theorem states that no model is better suited to every problem. A question that arises from this is how to design methods that propose optimizers tailored to specific problems achieving state-of-the-art performance. This paper addresses this issue by proposing the use of meta-learning to infer population-based black-box optimizers that can automatically adapt to specific classes of problems. We suggest a general modeling of population-based algorithms that result in Learning-to-Optimize POMDP (LTO-POMDP), a meta-learning framework based on a specific partially observable Markov decision process (POMDP). From that framework's formulation, we propose to parameterize the algorithm using deep recurrent neural networks and use a meta-loss function based on stochastic algorithms' performance to train efficient data-driven optimizers over several related optimization tasks. The learned optimizers' performance based on this implementation is assessed on various black-box optimization tasks and hyperparameter tuning of machine learning models. Our results revealed that the meta-loss function encourages a learned algorithm to alter its search behavior so that it can easily fit into a new context. Thus, it allows better generalization and higher sample efficiency than state-of-the-art generic optimization algorithms, such as the Covariance matrix adaptation evolution strategy (CMA-ES).