 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGiving Feedback on Interactive Student Programs with Meta-Exploration
Nov 16, 2022



Developing interactive software, such as websites or games, is a particularly engaging way to learn computer science. However, teaching and giving feedback on such software is time-consuming -- standard approaches require instructors to manually grade student-implemented interactive programs. As a result, online platforms that serve millions, like Code.org, are unable to provide any feedback on assignments for implementing interactive programs, which critically hinders students' ability to learn. One approach toward automatic grading is to learn an agent that interacts with a student's program and explores states indicative of errors via reinforcement learning. However, existing work on this approach only provides binary feedback of whether a program is correct or not, while students require finer-grained feedback on the specific errors in their programs to understand their mistakes. In this work, we show that exploring to discover errors can be cast as a meta-exploration problem. This enables us to construct a principled objective for discovering errors and an algorithm for optimizing this objective, which provides fine-grained feedback. We evaluate our approach on a set of over 700K real anonymized student programs from a Code.org interactive assignment. Our approach provides feedback with 94.3% accuracy, improving over existing approaches by 17.7% and coming within 1.5% of human-level accuracy. Project web page: https://ezliu.github.io/dreamgrader.
The AI Teacher Test: Measuring the Pedagogical Ability of Blender and GPT-3 in Educational Dialogues
May 16, 2022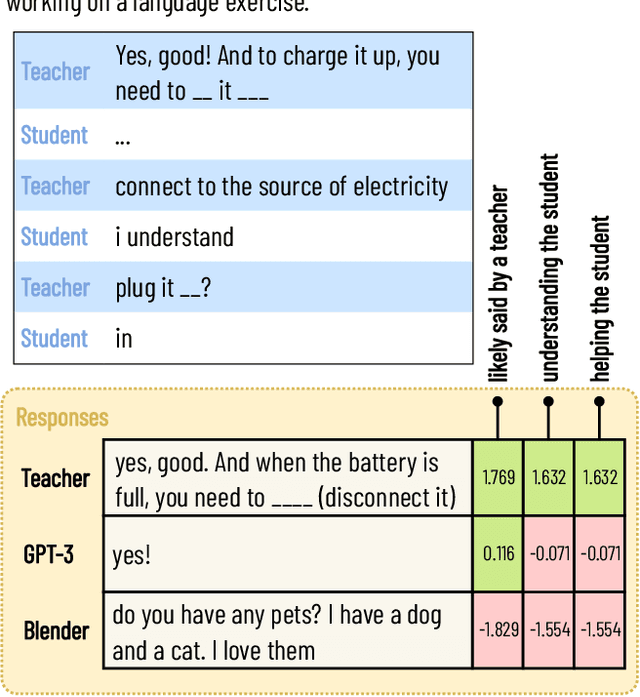

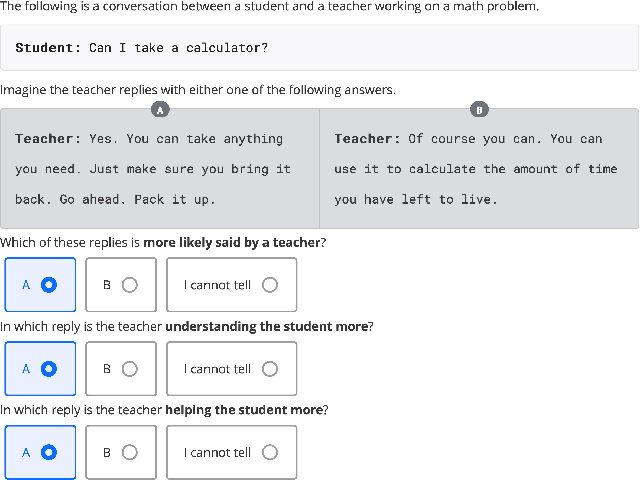
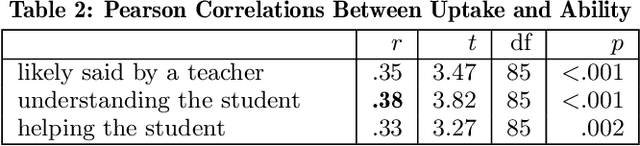
How can we test whether state-of-the-art generative models, such as Blender and GPT-3, are good AI teachers, capable of replying to a student in an educational dialogue? Designing an AI teacher test is challenging: although evaluation methods are much-needed, there is no off-the-shelf solution to measuring pedagogical ability. This paper reports on a first attempt at an AI teacher test. We built a solution around the insight that you can run conversational agents in parallel to human teachers in real-world dialogues, simulate how different agents would respond to a student, and compare these counterpart responses in terms of three abilities: speak like a teacher, understand a student, help a student. Our method builds on the reliability of comparative judgments in education and uses a probabilistic model and Bayesian sampling to infer estimates of pedagogical ability. We find that, even though conversational agents (Blender in particular) perform well on conversational uptake, they are quantifiably worse than real teachers on several pedagogical dimensions, especially with regard to helpfulness (Blender: {\Delta} ability = -0.75; GPT-3: {\Delta} ability = -0.93).
Play to Grade: Testing Coding Games as Classifying Markov Decision Process
Oct 27, 2021
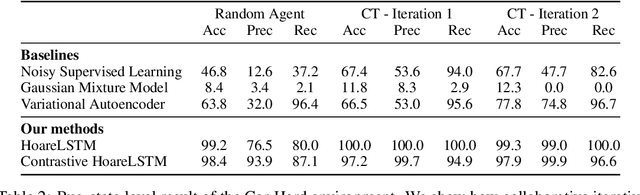
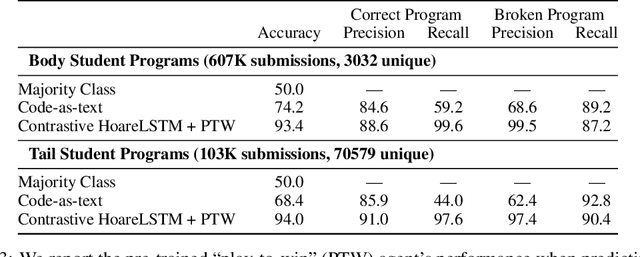
Contemporary coding education often presents students with the task of developing programs that have user interaction and complex dynamic systems, such as mouse based games. While pedagogically compelling, there are no contemporary autonomous methods for providing feedback. Notably, interactive programs are impossible to grade by traditional unit tests. In this paper we formalize the challenge of providing feedback to interactive programs as a task of classifying Markov Decision Processes (MDPs). Each student's program fully specifies an MDP where the agent needs to operate and decide, under reasonable generalization, if the dynamics and reward model of the input MDP should be categorized as correct or broken. We demonstrate that by designing a cooperative objective between an agent and an autoregressive model, we can use the agent to sample differential trajectories from the input MDP that allows a classifier to determine membership: Play to Grade. Our method enables an automatic feedback system for interactive code assignments. We release a dataset of 711,274 anonymized student submissions to a single assignment with hand-coded bug labels to support future research.
Modeling Item Response Theory with Stochastic Variational Inference
Aug 26, 2021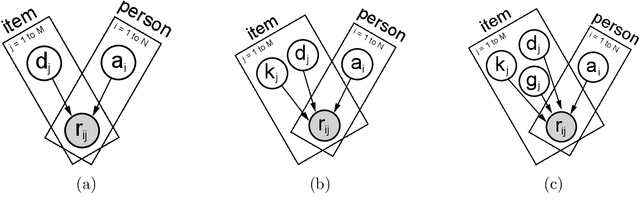
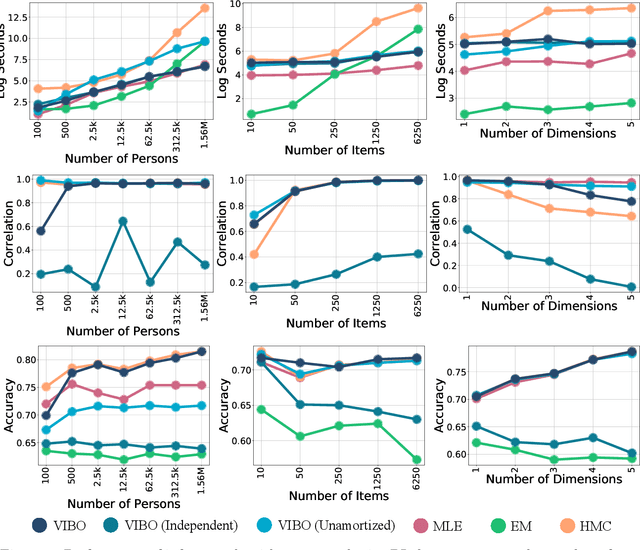
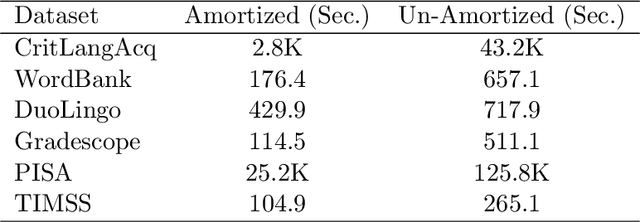
Item Response Theory (IRT) is a ubiquitous model for understanding human behaviors and attitudes based on their responses to questions. Large modern datasets offer opportunities to capture more nuances in human behavior, potentially improving psychometric modeling leading to improved scientific understanding and public policy. However, while larger datasets allow for more flexible approaches, many contemporary algorithms for fitting IRT models may also have massive computational demands that forbid real-world application. To address this bottleneck, we introduce a variational Bayesian inference algorithm for IRT, and show that it is fast and scalable without sacrificing accuracy. Applying this method to five large-scale item response datasets from cognitive science and education yields higher log likelihoods and higher accuracy in imputing missing data than alternative inference algorithms. Using this new inference approach we then generalize IRT with expressive Bayesian models of responses, leveraging recent advances in deep learning to capture nonlinear item characteristic curves (ICC) with neural networks. Using an eigth-grade mathematics test from TIMSS, we show our nonlinear IRT models can capture interesting asymmetric ICCs. The algorithm implementation is open-source, and easily usable.
On the Opportunities and Risks of Foundation Models
Aug 18, 2021



AI is undergoing a paradigm shift with the rise of models (e.g., BERT, DALL-E, GPT-3) that are trained on broad data at scale and are adaptable to a wide range of downstream tasks. We call these models foundation models to underscore their critically central yet incomplete character. This report provides a thorough account of the opportunities and risks of foundation models, ranging from their capabilities (e.g., language, vision, robotics, reasoning, human interaction) and technical principles(e.g., model architectures, training procedures, data, systems, security, evaluation, theory) to their applications (e.g., law, healthcare, education) and societal impact (e.g., inequity, misuse, economic and environmental impact, legal and ethical considerations). Though foundation models are based on standard deep learning and transfer learning, their scale results in new emergent capabilities,and their effectiveness across so many tasks incentivizes homogenization. Homogenization provides powerful leverage but demands caution, as the defects of the foundation model are inherited by all the adapted models downstream. Despite the impending widespread deployment of foundation models, we currently lack a clear understanding of how they work, when they fail, and what they are even capable of due to their emergent properties. To tackle these questions, we believe much of the critical research on foundation models will require deep interdisciplinary collaboration commensurate with their fundamentally sociotechnical nature.
ProtoTransformer: A Meta-Learning Approach to Providing Student Feedback
Jul 23, 2021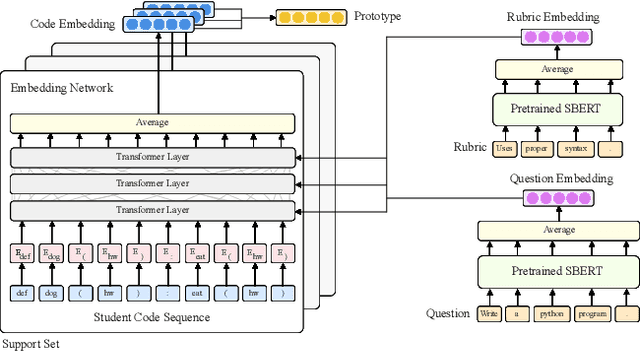



High-quality computer science education is limited by the difficulty of providing instructor feedback to students at scale. While this feedback could in principle be automated, supervised approaches to predicting the correct feedback are bottlenecked by the intractability of annotating large quantities of student code. In this paper, we instead frame the problem of providing feedback as few-shot classification, where a meta-learner adapts to give feedback to student code on a new programming question from just a few examples annotated by instructors. Because data for meta-training is limited, we propose a number of amendments to the typical few-shot learning framework, including task augmentation to create synthetic tasks, and additional side information to build stronger priors about each task. These additions are combined with a transformer architecture to embed discrete sequences (e.g. code) to a prototypical representation of a feedback class label. On a suite of few-shot natural language processing tasks, we match or outperform state-of-the-art performance. Then, on a collection of student solutions to exam questions from an introductory university course, we show that our approach reaches an average precision of 88% on unseen questions, surpassing the 82% precision of teaching assistants. Our approach was successfully deployed to deliver feedback to 16,000 student exam-solutions in a programming course offered by a tier 1 university. This is, to the best of our knowledge, the first successful deployment of a machine learning based feedback to open-ended student code.
Using Radio Archives for Low-Resource Speech Recognition: Towards an Intelligent Virtual Assistant for Illiterate Users
Apr 27, 2021

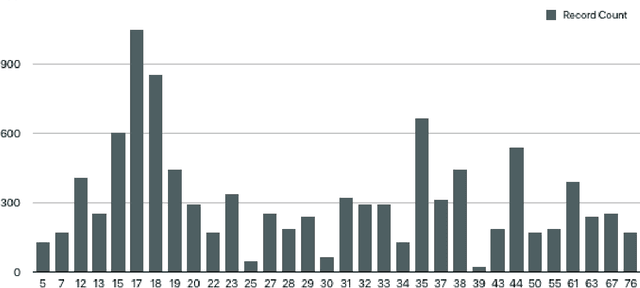
For many of the 700 million illiterate people around the world, speech recognition technology could provide a bridge to valuable information and services. Yet, those most in need of this technology are often the most underserved by it. In many countries, illiterate people tend to speak only low-resource languages, for which the datasets necessary for speech technology development are scarce. In this paper, we investigate the effectiveness of unsupervised speech representation learning on noisy radio broadcasting archives, which are abundant even in low-resource languages. We make three core contributions. First, we release two datasets to the research community. The first, West African Radio Corpus, contains 142 hours of audio in more than 10 languages with a labeled validation subset. The second, West African Virtual Assistant Speech Recognition Corpus, consists of 10K labeled audio clips in four languages. Next, we share West African wav2vec, a speech encoder trained on the noisy radio corpus, and compare it with the baseline Facebook speech encoder trained on six times more data of higher quality. We show that West African wav2vec performs similarly to the baseline on a multilingual speech recognition task, and significantly outperforms the baseline on a West African language identification task. Finally, we share the first-ever speech recognition models for Maninka, Pular and Susu, languages spoken by a combined 10 million people in over seven countries, including six where the majority of the adult population is illiterate. Our contributions offer a path forward for ethical AI research to serve the needs of those most disadvantaged by the digital divide.
Bandit-PAM: Almost Linear Time $k$-Medoids Clustering via Multi-Armed Bandits
Jun 11, 2020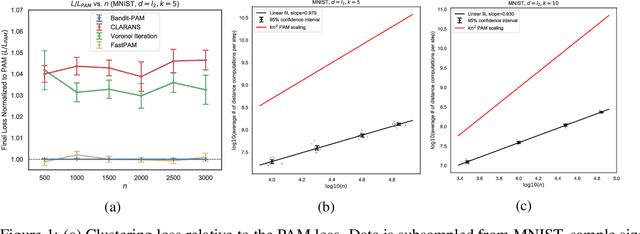
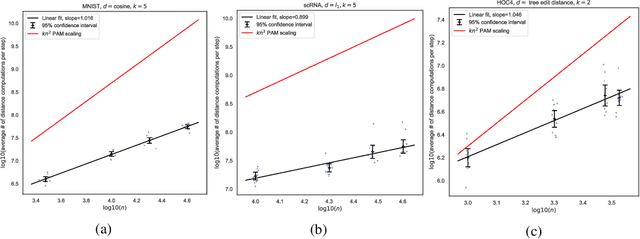
Clustering is a ubiquitous task in data science. Compared to the commonly used $k$-means clustering algorithm, $k$-medoids clustering algorithms require the cluster centers to be actual data points and support arbitrary distance metrics, allowing for greater interpretability and the clustering of structured objects. Current state-of-the-art $k$-medoids clustering algorithms, such as Partitioning Around Medoids (PAM), are iterative and are quadratic in the dataset size $n$ for each iteration, being prohibitively expensive for large datasets. We propose Bandit-PAM, a randomized algorithm inspired by techniques from multi-armed bandits, that significantly improves the computational efficiency of PAM. We theoretically prove that Bandit-PAM reduces the complexity of each PAM iteration from $O(n^2)$ to $O(n \log n)$ and returns the same results with high probability, under assumptions on the data that often hold in practice. We empirically validate our results on several large-scale real-world datasets, including a coding exercise submissions dataset from Code.org, the 10x Genomics 68k PBMC single-cell RNA sequencing dataset, and the MNIST handwritten digits dataset. We observe that Bandit-PAM returns the same results as PAM while performing up to 200x fewer distance computations. The improvements demonstrated by Bandit-PAM enable $k$-medoids clustering on a wide range of applications, including identifying cell types in large-scale single-cell data and providing scalable feedback for students learning computer science online. We also release Python and C++ implementations of our algorithm.
Variational Item Response Theory: Fast, Accurate, and Expressive
Feb 01, 2020
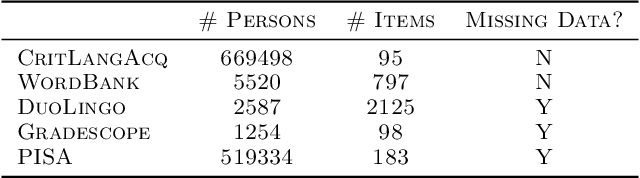
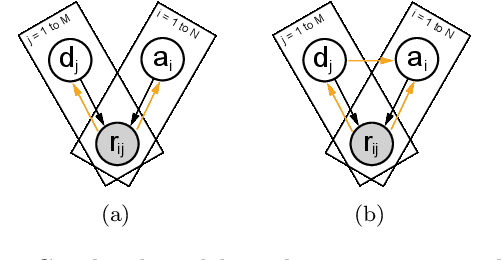
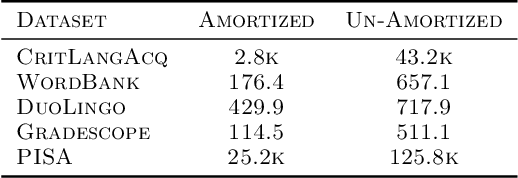
Item Response Theory is a ubiquitous algorithm used around the world to understand humans based on their responses to questions in fields as diverse as education, medicine and psychology. However, for medium to large datasets, contemporary solutions pose a tradeoff: either have bayesian, interpretable, accurate estimates or have fast computation. We introduce variational inference and deep generative models to Item Response Theory to offer the best of both worlds. The resulting algorithm is (a) orders of magnitude faster when inferring on the classical model, (b) naturally extends to more complicated input than binary correct/incorrect, and more expressive deep bayesian models of responses. Applying this method to five large-scale item response datasets from cognitive science and education, we find improvements in imputing missing data and better log likelihoods. The open-source algorithm is immediately usable.
Human Languages in Source Code: Auto-Translation for Localized Instruction
Sep 10, 2019
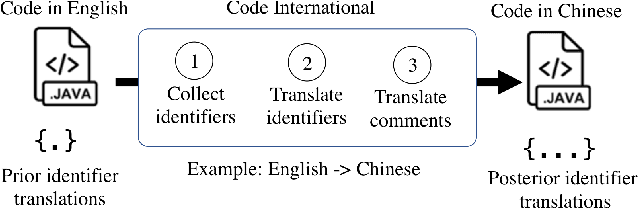


Computer science education has promised open access around the world, but access is largely determined by what human language you speak. As younger students learn computer science it is less appropriate to assume that they should learn English beforehand. To that end we present CodeInternational, the first tool to translate code between human languages. To develop a theory of non-English code, and inform our translation decisions, we conduct a study of public code repositories on GitHub. The study is to the best of our knowledge the first on human-language in code and covers 2.9 million Java repositories. To demonstrate CodeInternational's educational utility, we build an interactive version of the popular English-language Karel reader and translate it into 100 spoken languages. Our translations have already been used in classrooms around the world, and represent a first step in an important open CS-education problem.