 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSegmental Recurrent Neural Networks
Mar 01, 2016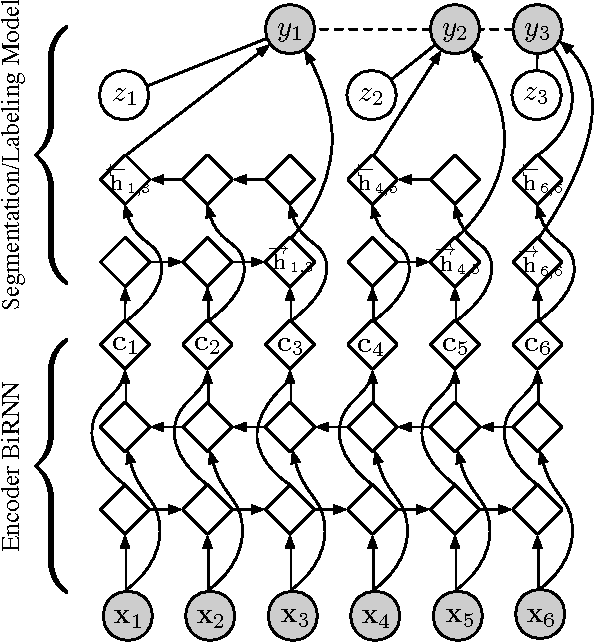
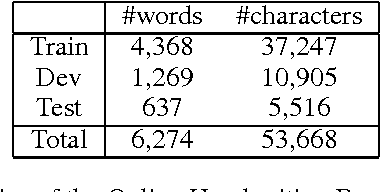

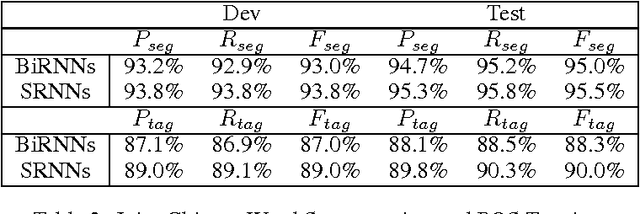
We introduce segmental recurrent neural networks (SRNNs) which define, given an input sequence, a joint probability distribution over segmentations of the input and labelings of the segments. Representations of the input segments (i.e., contiguous subsequences of the input) are computed by encoding their constituent tokens using bidirectional recurrent neural nets, and these "segment embeddings" are used to define compatibility scores with output labels. These local compatibility scores are integrated using a global semi-Markov conditional random field. Both fully supervised training -- in which segment boundaries and labels are observed -- as well as partially supervised training -- in which segment boundaries are latent -- are straightforward. Experiments on handwriting recognition and joint Chinese word segmentation/POS tagging show that, compared to models that do not explicitly represent segments such as BIO tagging schemes and connectionist temporal classification (CTC), SRNNs obtain substantially higher accuracies.
Document Context Language Models
Feb 21, 2016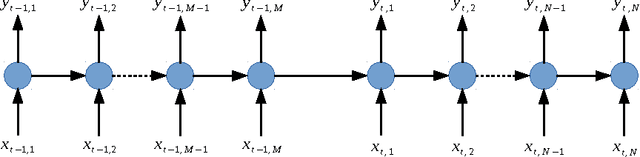
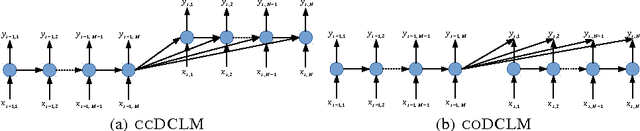
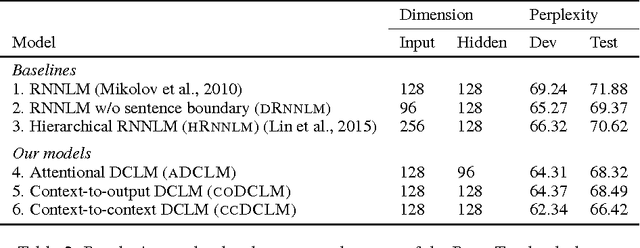
Text documents are structured on multiple levels of detail: individual words are related by syntax, but larger units of text are related by discourse structure. Existing language models generally fail to account for discourse structure, but it is crucial if we are to have language models that reward coherence and generate coherent texts. We present and empirically evaluate a set of multi-level recurrent neural network language models, called Document-Context Language Models (DCLM), which incorporate contextual information both within and beyond the sentence. In comparison with word-level recurrent neural network language models, the DCLM models obtain slightly better predictive likelihoods, and considerably better assessments of document coherence.
Semantic Scan: Detecting Subtle, Spatially Localized Events in Text Streams
Feb 13, 2016

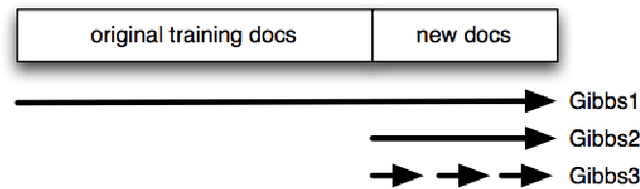
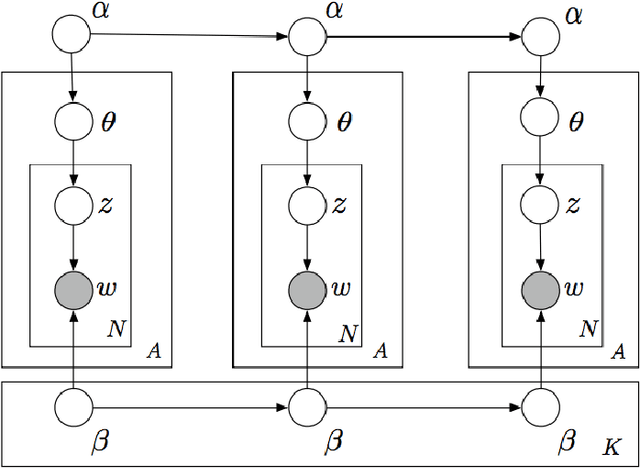
Early detection and precise characterization of emerging topics in text streams can be highly useful in applications such as timely and targeted public health interventions and discovering evolving regional business trends. Many methods have been proposed for detecting emerging events in text streams using topic modeling. However, these methods have numerous shortcomings that make them unsuitable for rapid detection of locally emerging events on massive text streams. In this paper, we describe Semantic Scan (SS) that has been developed specifically to overcome these shortcomings in detecting new spatially compact events in text streams. Semantic Scan integrates novel contrastive topic modeling with online document assignment and principled likelihood ratio-based spatial scanning to identify emerging events with unexpected patterns of keywords hidden in text streams. This enables more timely and accurate detection and characterization of anomalous, spatially localized emerging events. Semantic Scan does not require manual intervention or labeled training data, and is robust to noise in real-world text data since it identifies anomalous text patterns that occur in a cluster of new documents rather than an anomaly in a single new document. We compare Semantic Scan to alternative state-of-the-art methods such as Topics over Time, Online LDA, and Labeled LDA on two real-world tasks: (i) a disease surveillance task monitoring free-text Emergency Department chief complaints in Allegheny County, and (ii) an emerging business trend detection task based on Yelp reviews. On both tasks, we find that Semantic Scan provides significantly better event detection and characterization accuracy than competing approaches, while providing up to an order of magnitude speedup.
Incorporating Structural Alignment Biases into an Attentional Neural Translation Model
Jan 06, 2016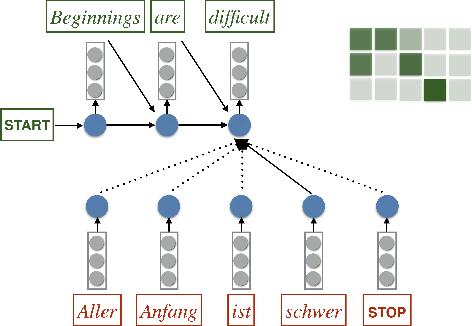
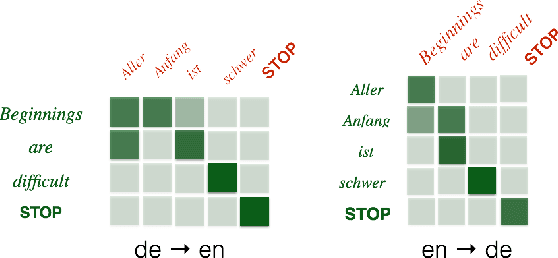
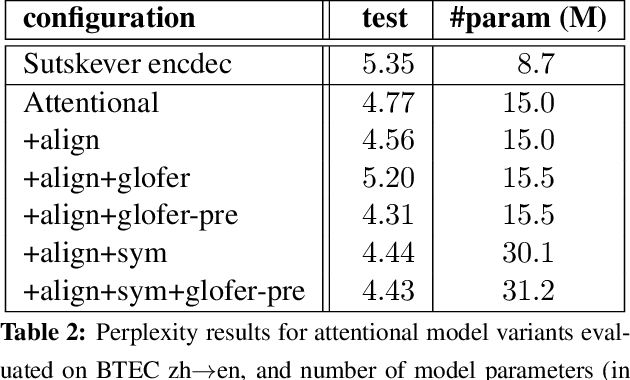
Neural encoder-decoder models of machine translation have achieved impressive results, rivalling traditional translation models. However their modelling formulation is overly simplistic, and omits several key inductive biases built into traditional models. In this paper we extend the attentional neural translation model to include structural biases from word based alignment models, including positional bias, Markov conditioning, fertility and agreement over translation directions. We show improvements over a baseline attentional model and standard phrase-based model over several language pairs, evaluating on difficult languages in a low resource setting.
Modeling Dynamic Relationships Between Characters in Literary Novels
Nov 30, 2015
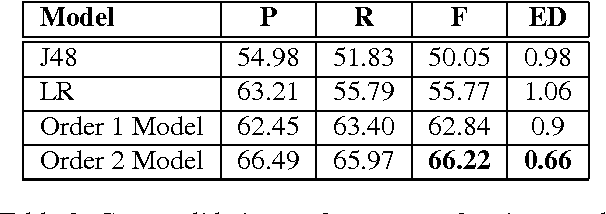
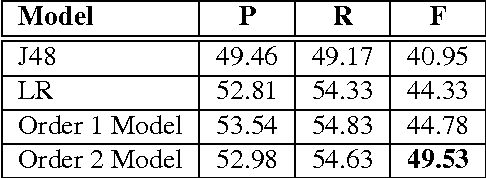
Studying characters plays a vital role in computationally representing and interpreting narratives. Unlike previous work, which has focused on inferring character roles, we focus on the problem of modeling their relationships. Rather than assuming a fixed relationship for a character pair, we hypothesize that relationships are dynamic and temporally evolve with the progress of the narrative, and formulate the problem of relationship modeling as a structured prediction problem. We propose a semi-supervised framework to learn relationship sequences from fully as well as partially labeled data. We present a Markovian model capable of accumulating historical beliefs about the relationship and status changes. We use a set of rich linguistic and semantically motivated features that incorporate world knowledge to investigate the textual content of narrative. We empirically demonstrate that such a framework outperforms competitive baselines.
Learning to Represent Words in Context with Multilingual Supervision
Nov 19, 2015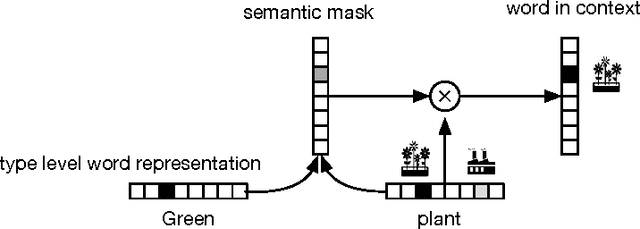
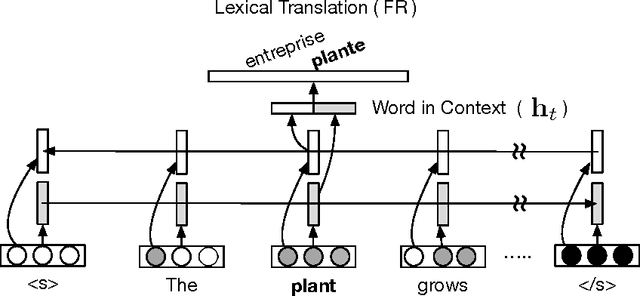
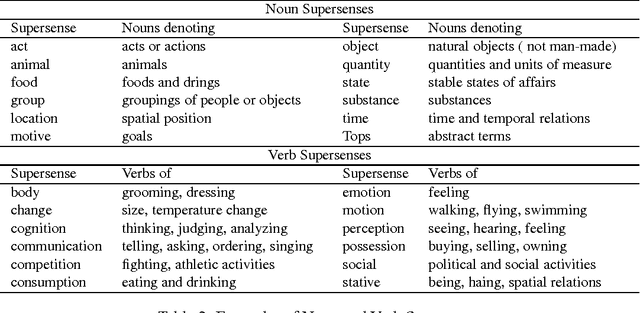
We present a neural network architecture based on bidirectional LSTMs to compute representations of words in the sentential contexts. These context-sensitive word representations are suitable for, e.g., distinguishing different word senses and other context-modulated variations in meaning. To learn the parameters of our model, we use cross-lingual supervision, hypothesizing that a good representation of a word in context will be one that is sufficient for selecting the correct translation into a second language. We evaluate the quality of our representations as features in three downstream tasks: prediction of semantic supersenses (which assign nouns and verbs into a few dozen semantic classes), low resource machine translation, and a lexical substitution task, and obtain state-of-the-art results on all of these.
Character-based Neural Machine Translation
Nov 14, 2015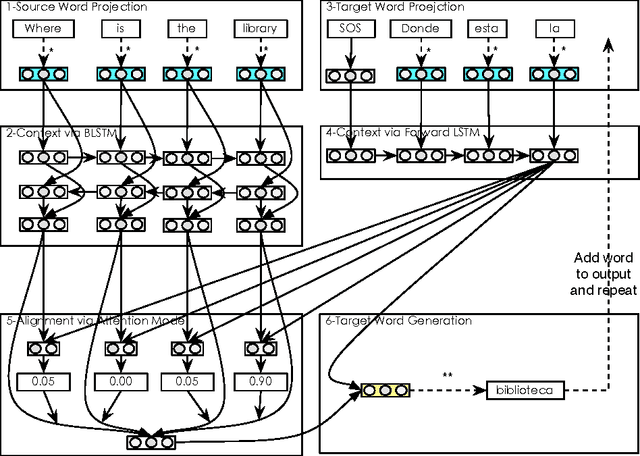
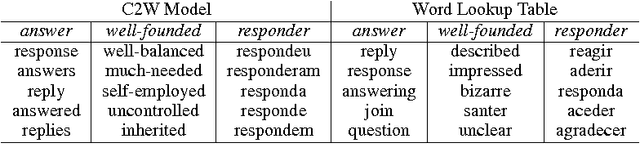
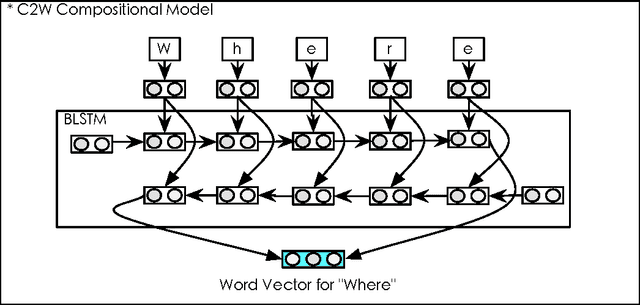

We introduce a neural machine translation model that views the input and output sentences as sequences of characters rather than words. Since word-level information provides a crucial source of bias, our input model composes representations of character sequences into representations of words (as determined by whitespace boundaries), and then these are translated using a joint attention/translation model. In the target language, the translation is modeled as a sequence of word vectors, but each word is generated one character at a time, conditional on the previous character generations in each word. As the representation and generation of words is performed at the character level, our model is capable of interpreting and generating unseen word forms. A secondary benefit of this approach is that it alleviates much of the challenges associated with preprocessing/tokenization of the source and target languages. We show that our model can achieve translation results that are on par with conventional word-based models.
Depth-Gated LSTM
Aug 25, 2015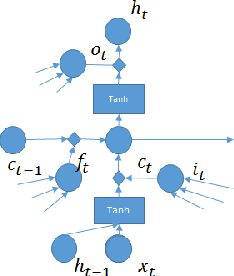
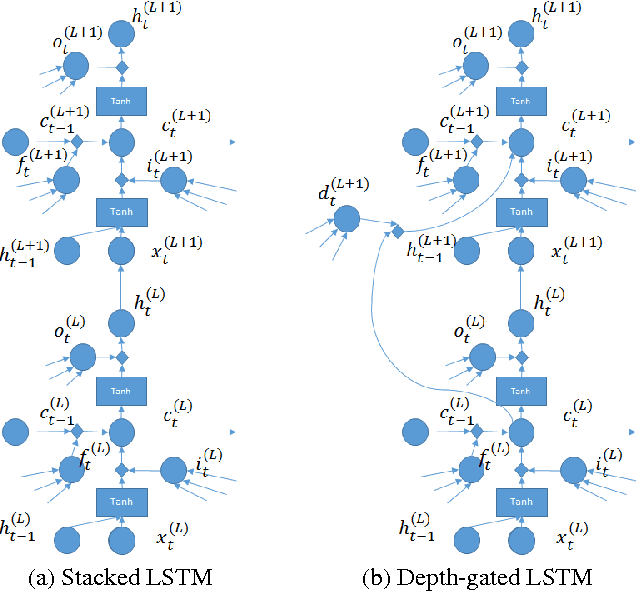


In this short note, we present an extension of long short-term memory (LSTM) neural networks to using a depth gate to connect memory cells of adjacent layers. Doing so introduces a linear dependence between lower and upper layer recurrent units. Importantly, the linear dependence is gated through a gating function, which we call depth gate. This gate is a function of the lower layer memory cell, the input to and the past memory cell of this layer. We conducted experiments and verified that this new architecture of LSTMs was able to improve machine translation and language modeling performances.
Improved Transition-Based Parsing by Modeling Characters instead of Words with LSTMs
Aug 11, 2015
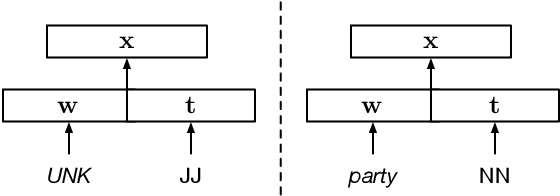
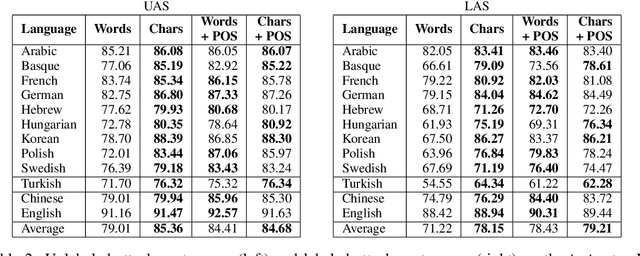
We present extensions to a continuous-state dependency parsing method that makes it applicable to morphologically rich languages. Starting with a high-performance transition-based parser that uses long short-term memory (LSTM) recurrent neural networks to learn representations of the parser state, we replace lookup-based word representations with representations constructed from the orthographic representations of the words, also using LSTMs. This allows statistical sharing across word forms that are similar on the surface. Experiments for morphologically rich languages show that the parsing model benefits from incorporating the character-based encodings of words.
Non-distributional Word Vector Representations
Jun 17, 2015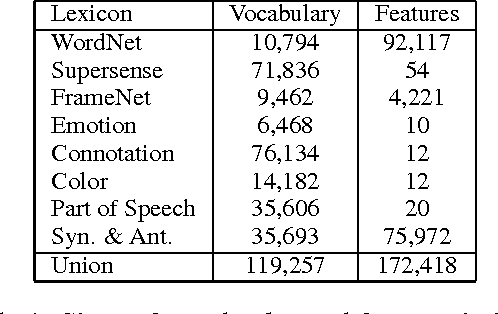


Data-driven representation learning for words is a technique of central importance in NLP. While indisputably useful as a source of features in downstream tasks, such vectors tend to consist of uninterpretable components whose relationship to the categories of traditional lexical semantic theories is tenuous at best. We present a method for constructing interpretable word vectors from hand-crafted linguistic resources like WordNet, FrameNet etc. These vectors are binary (i.e, contain only 0 and 1) and are 99.9% sparse. We analyze their performance on state-of-the-art evaluation methods for distributional models of word vectors and find they are competitive to standard distributional approaches.