 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Optimization Landscape of Neural Collapse under MSE Loss: Global Optimality with Unconstrained Features
Mar 12, 2022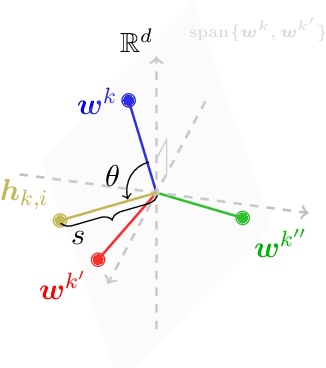
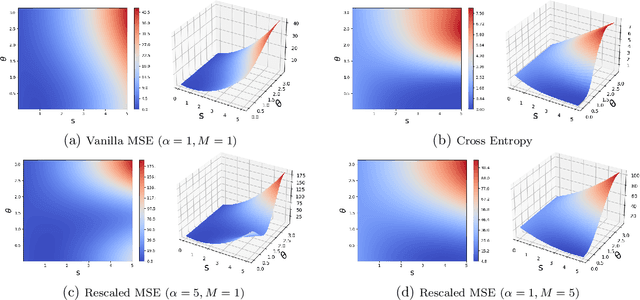
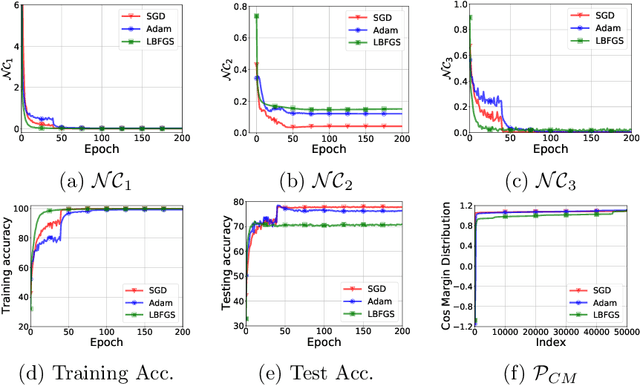

When training deep neural networks for classification tasks, an intriguing empirical phenomenon has been widely observed in the last-layer classifiers and features, where (i) the class means and the last-layer classifiers all collapse to the vertices of a Simplex Equiangular Tight Frame (ETF) up to scaling, and (ii) cross-example within-class variability of last-layer activations collapses to zero. This phenomenon is called Neural Collapse (NC), which seems to take place regardless of the choice of loss functions. In this work, we justify NC under the mean squared error (MSE) loss, where recent empirical evidence shows that it performs comparably or even better than the de-facto cross-entropy loss. Under a simplified unconstrained feature model, we provide the first global landscape analysis for vanilla nonconvex MSE loss and show that the (only!) global minimizers are neural collapse solutions, while all other critical points are strict saddles whose Hessian exhibit negative curvature directions. Furthermore, we justify the usage of rescaled MSE loss by probing the optimization landscape around the NC solutions, showing that the landscape can be improved by tuning the rescaling hyperparameters. Finally, our theoretical findings are experimentally verified on practical network architectures.
Robust Training under Label Noise by Over-parameterization
Feb 28, 2022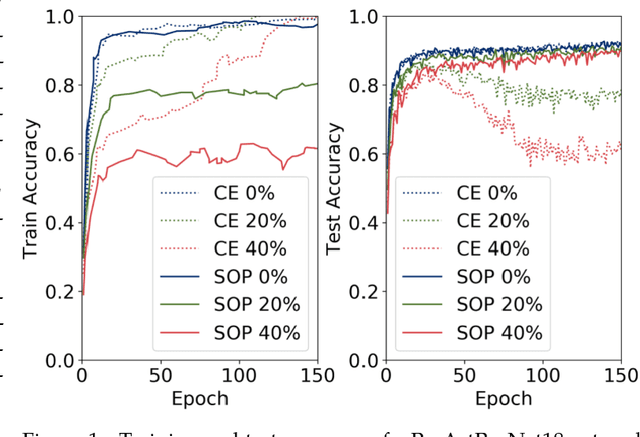
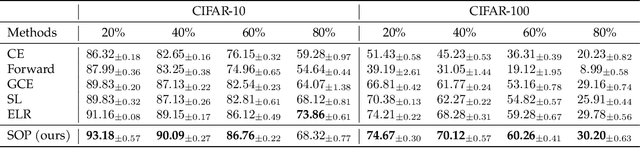
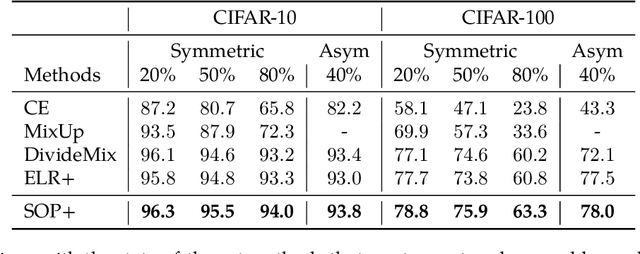
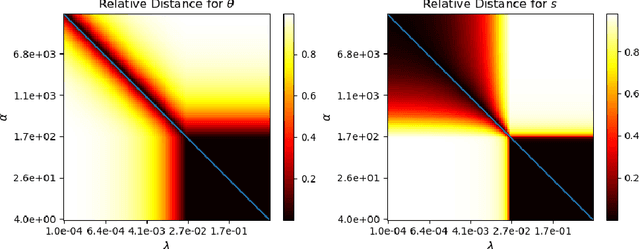
Recently, over-parameterized deep networks, with increasingly more network parameters than training samples, have dominated the performances of modern machine learning. However, when the training data is corrupted, it has been well-known that over-parameterized networks tend to overfit and do not generalize. In this work, we propose a principled approach for robust training of over-parameterized deep networks in classification tasks where a proportion of training labels are corrupted. The main idea is yet very simple: label noise is sparse and incoherent with the network learned from clean data, so we model the noise and learn to separate it from the data. Specifically, we model the label noise via another sparse over-parameterization term, and exploit implicit algorithmic regularizations to recover and separate the underlying corruptions. Remarkably, when trained using such a simple method in practice, we demonstrate state-of-the-art test accuracy against label noise on a variety of real datasets. Furthermore, our experimental results are corroborated by theory on simplified linear models, showing that exact separation between sparse noise and low-rank data can be achieved under incoherent conditions. The work opens many interesting directions for improving over-parameterized models by using sparse over-parameterization and implicit regularization.
Learning a Self-Expressive Network for Subspace Clustering
Oct 08, 2021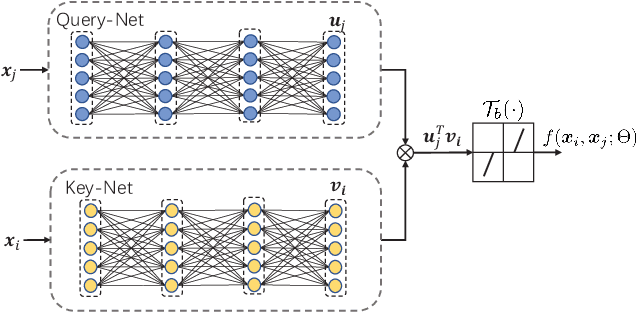
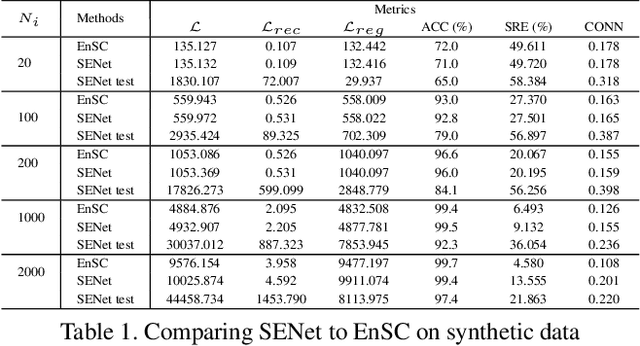
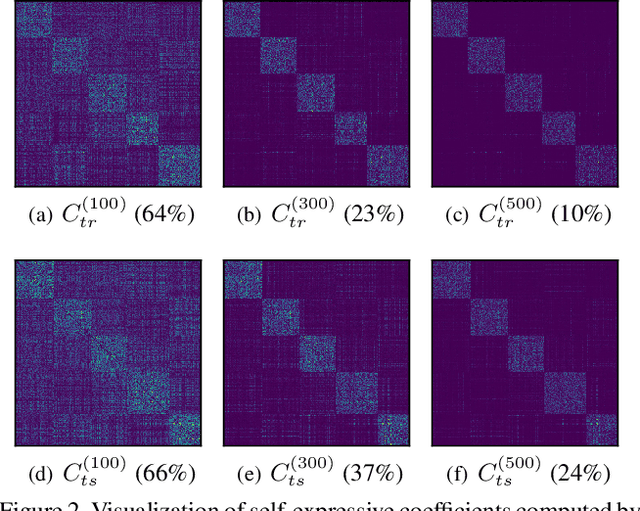
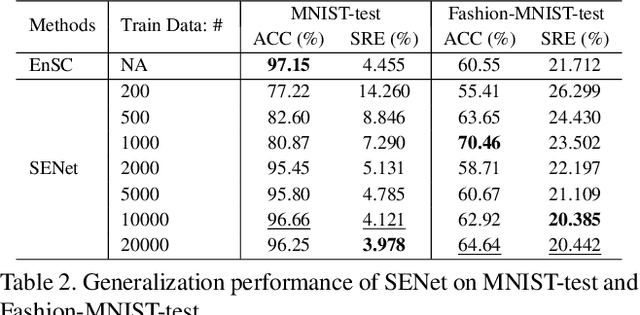
State-of-the-art subspace clustering methods are based on self-expressive model, which represents each data point as a linear combination of other data points. However, such methods are designed for a finite sample dataset and lack the ability to generalize to out-of-sample data. Moreover, since the number of self-expressive coefficients grows quadratically with the number of data points, their ability to handle large-scale datasets is often limited. In this paper, we propose a novel framework for subspace clustering, termed Self-Expressive Network (SENet), which employs a properly designed neural network to learn a self-expressive representation of the data. We show that our SENet can not only learn the self-expressive coefficients with desired properties on the training data, but also handle out-of-sample data. Besides, we show that SENet can also be leveraged to perform subspace clustering on large-scale datasets. Extensive experiments conducted on synthetic data and real world benchmark data validate the effectiveness of the proposed method. In particular, SENet yields highly competitive performance on MNIST, Fashion MNIST and Extended MNIST and state-of-the-art performance on CIFAR-10. The code is available at https://github.com/zhangsz1998/Self-Expressive-Network.
ReduNet: A White-box Deep Network from the Principle of Maximizing Rate Reduction
Jun 10, 2021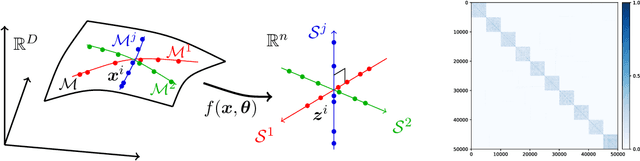
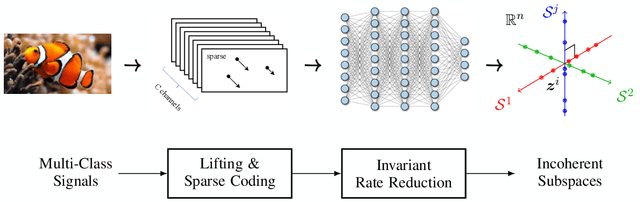

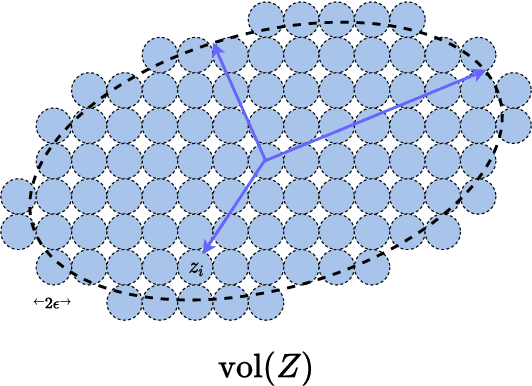
This work attempts to provide a plausible theoretical framework that aims to interpret modern deep (convolutional) networks from the principles of data compression and discriminative representation. We argue that for high-dimensional multi-class data, the optimal linear discriminative representation maximizes the coding rate difference between the whole dataset and the average of all the subsets. We show that the basic iterative gradient ascent scheme for optimizing the rate reduction objective naturally leads to a multi-layer deep network, named ReduNet, which shares common characteristics of modern deep networks. The deep layered architectures, linear and nonlinear operators, and even parameters of the network are all explicitly constructed layer-by-layer via forward propagation, although they are amenable to fine-tuning via back propagation. All components of so-obtained ``white-box'' network have precise optimization, statistical, and geometric interpretation. Moreover, all linear operators of the so-derived network naturally become multi-channel convolutions when we enforce classification to be rigorously shift-invariant. The derivation in the invariant setting suggests a trade-off between sparsity and invariance, and also indicates that such a deep convolution network is significantly more efficient to construct and learn in the spectral domain. Our preliminary simulations and experiments clearly verify the effectiveness of both the rate reduction objective and the associated ReduNet. All code and data are available at https://github.com/Ma-Lab-Berkeley.
A Geometric Analysis of Neural Collapse with Unconstrained Features
May 06, 2021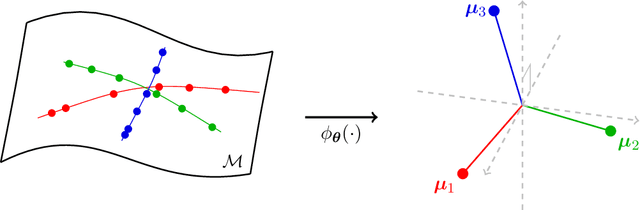

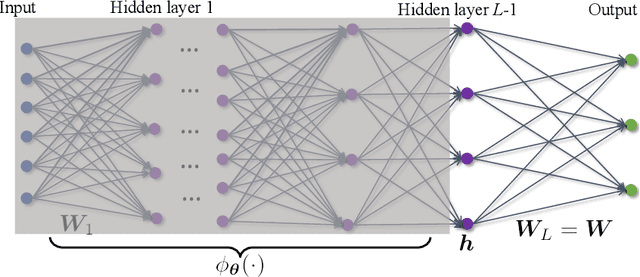
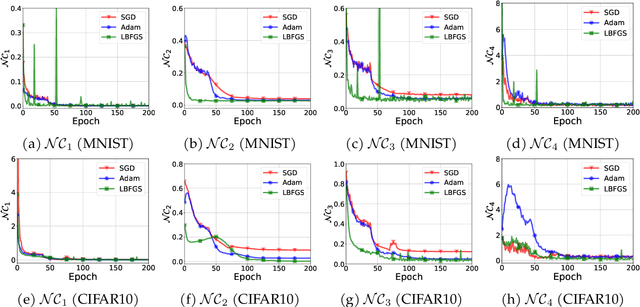
We provide the first global optimization landscape analysis of $Neural\;Collapse$ -- an intriguing empirical phenomenon that arises in the last-layer classifiers and features of neural networks during the terminal phase of training. As recently reported by Papyan et al., this phenomenon implies that ($i$) the class means and the last-layer classifiers all collapse to the vertices of a Simplex Equiangular Tight Frame (ETF) up to scaling, and ($ii$) cross-example within-class variability of last-layer activations collapses to zero. We study the problem based on a simplified $unconstrained\;feature\;model$, which isolates the topmost layers from the classifier of the neural network. In this context, we show that the classical cross-entropy loss with weight decay has a benign global landscape, in the sense that the only global minimizers are the Simplex ETFs while all other critical points are strict saddles whose Hessian exhibit negative curvature directions. In contrast to existing landscape analysis for deep neural networks which is often disconnected from practice, our analysis of the simplified model not only does it explain what kind of features are learned in the last layer, but it also shows why they can be efficiently optimized in the simplified settings, matching the empirical observations in practical deep network architectures. These findings could have profound implications for optimization, generalization, and robustness of broad interests. For example, our experiments demonstrate that one may set the feature dimension equal to the number of classes and fix the last-layer classifier to be a Simplex ETF for network training, which reduces memory cost by over $20\%$ on ResNet18 without sacrificing the generalization performance.
Convolutional Normalization: Improving Deep Convolutional Network Robustness and Training
Mar 01, 2021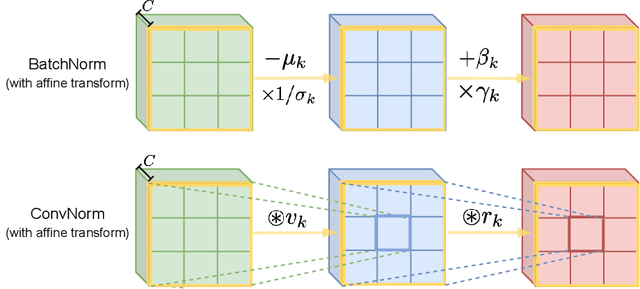
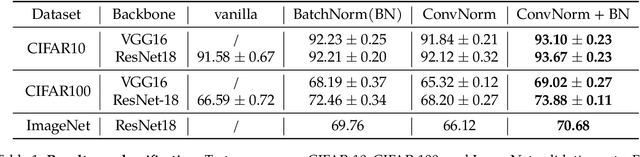
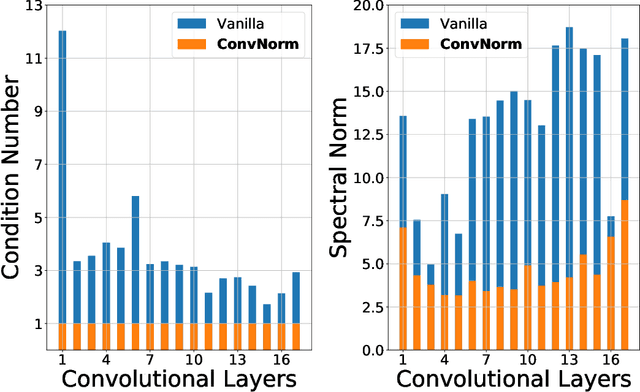
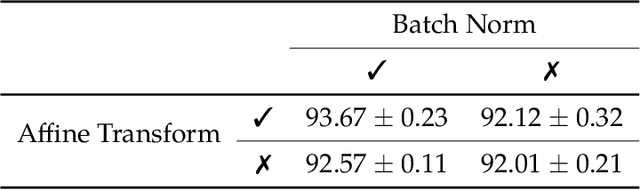
Normalization techniques have become a basic component in modern convolutional neural networks (ConvNets). In particular, many recent works demonstrate that promoting the orthogonality of the weights helps train deep models and improve robustness. For ConvNets, most existing methods are based on penalizing or normalizing weight matrices derived from concatenating or flattening the convolutional kernels. These methods often destroy or ignore the benign convolutional structure of the kernels; therefore, they are often expensive or impractical for deep ConvNets. In contrast, we introduce a simple and efficient ``convolutional normalization'' method that can fully exploit the convolutional structure in the Fourier domain and serve as a simple plug-and-play module to be conveniently incorporated into any ConvNets. Our method is inspired by recent work on preconditioning methods for convolutional sparse coding and can effectively promote each layer's channel-wise isometry. Furthermore, we show that convolutional normalization can reduce the layerwise spectral norm of the weight matrices and hence improve the Lipschitzness of the network, leading to easier training and improved robustness for deep ConvNets. Applied to classification under noise corruptions and generative adversarial network (GAN), we show that convolutional normalization improves the robustness of common ConvNets such as ResNet and the performance of GAN. We verify our findings via extensive numerical experiments on CIFAR-10, CIFAR-100, and ImageNet.
Incremental Learning via Rate Reduction
Nov 30, 2020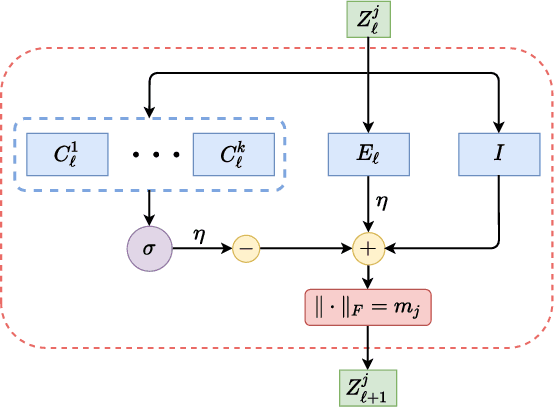
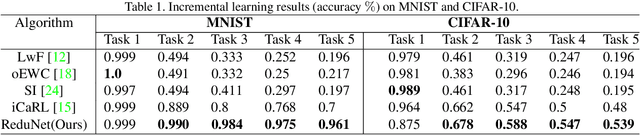
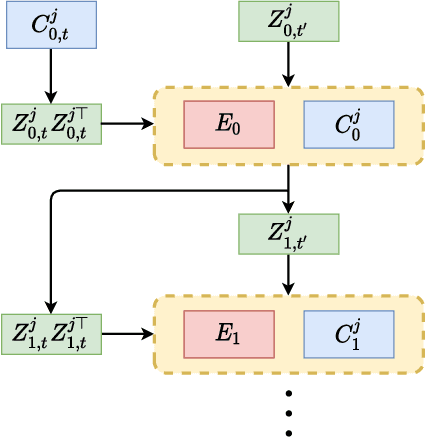
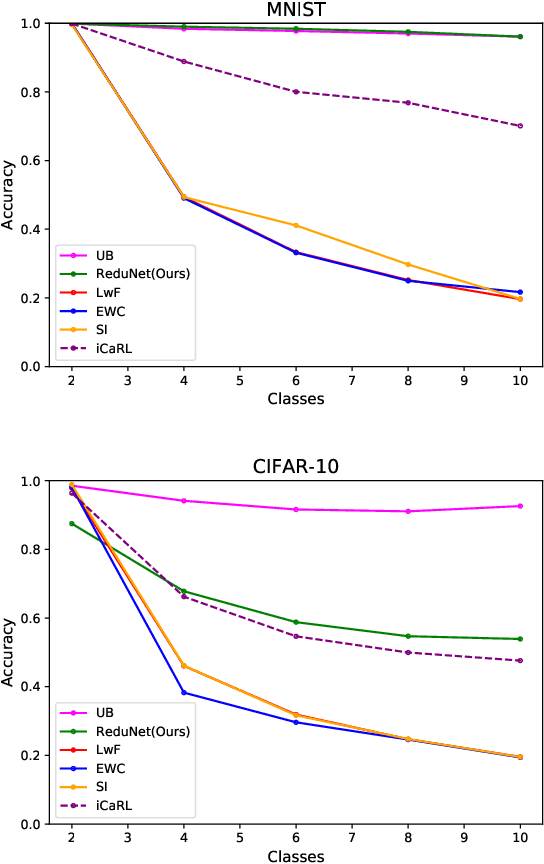
Current deep learning architectures suffer from catastrophic forgetting, a failure to retain knowledge of previously learned classes when incrementally trained on new classes. The fundamental roadblock faced by deep learning methods is that deep learning models are optimized as "black boxes," making it difficult to properly adjust the model parameters to preserve knowledge about previously seen data. To overcome the problem of catastrophic forgetting, we propose utilizing an alternative "white box" architecture derived from the principle of rate reduction, where each layer of the network is explicitly computed without back propagation. Under this paradigm, we demonstrate that, given a pre-trained network and new data classes, our approach can provably construct a new network that emulates joint training with all past and new classes. Finally, our experiments show that our proposed learning algorithm observes significantly less decay in classification performance, outperforming state of the art methods on MNIST and CIFAR-10 by a large margin and justifying the use of "white box" algorithms for incremental learning even for sufficiently complex image data.
Deep Networks from the Principle of Rate Reduction
Oct 27, 2020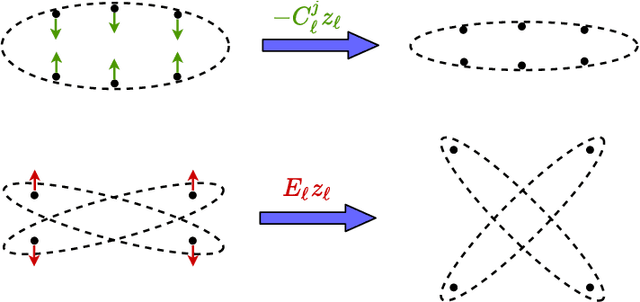
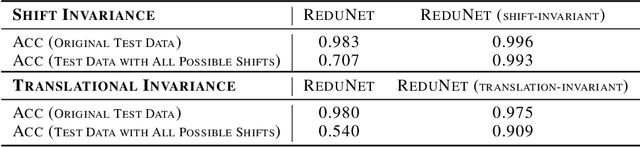
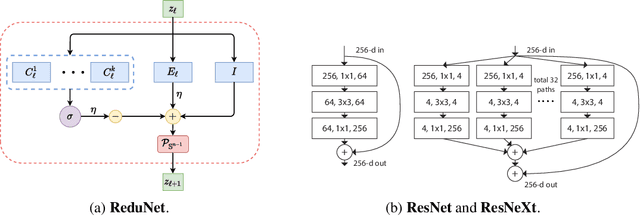

This work attempts to interpret modern deep (convolutional) networks from the principles of rate reduction and (shift) invariant classification. We show that the basic iterative gradient ascent scheme for optimizing the rate reduction of learned features naturally leads to a multi-layer deep network, one iteration per layer. The layered architectures, linear and nonlinear operators, and even parameters of the network are all explicitly constructed layer-by-layer in a forward propagation fashion by emulating the gradient scheme. All components of this "white box" network have precise optimization, statistical, and geometric interpretation. This principled framework also reveals and justifies the role of multi-channel lifting and sparse coding in early stage of deep networks. Moreover, all linear operators of the so-derived network naturally become multi-channel convolutions when we enforce classification to be rigorously shift-invariant. The derivation also indicates that such a convolutional network is significantly more efficient to construct and learn in the spectral domain. Our preliminary simulations and experiments indicate that so constructed deep network can already learn a good discriminative representation even without any back propagation training.
A Critique of Self-Expressive Deep Subspace Clustering
Oct 08, 2020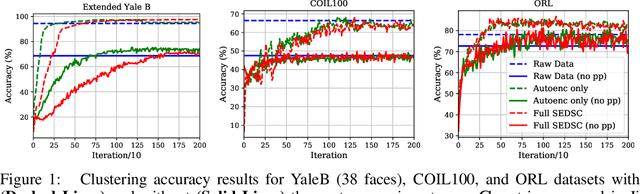

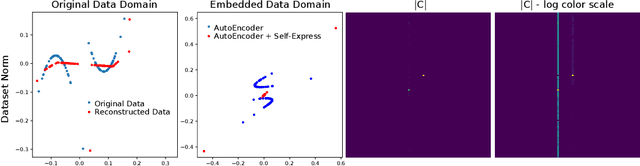
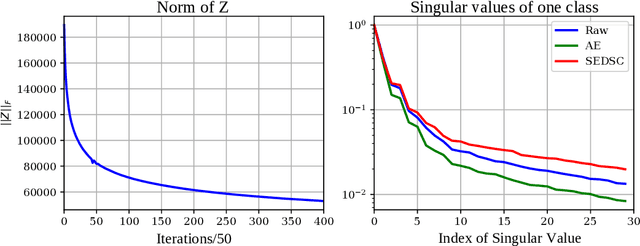
Subspace clustering is an unsupervised clustering technique designed to cluster data that is supported on a union of linear subspaces, with each subspace defining a cluster with dimension lower than the ambient space. Many existing formulations for this problem are based on exploiting the self-expressive property of linear subspaces, where any point within a subspace can be represented as linear combination of other points within the subspace. To extend this approach to data supported on a union of non-linear manifolds, numerous studies have proposed learning an appropriate kernel embedding of the original data using a neural network, which is regularized by a self-expressive loss function on the data in the embedded space to encourage a union of linear subspaces prior on the data in the embedded space. Here we show that there are a number of potential flaws with this approach which have not been adequately addressed in prior work. In particular, we show the model formulation is often ill-posed in multiple ways, which can lead to a degenerate embedding of the data, which need not correspond to a union of subspaces at all. We validate our theoretical results experimentally and additionally repeat prior experiments reported in the literature, where we conclude that a significant portion of the previously claimed performance benefits can be attributed to an ad-hoc post processing step rather than the clustering model.
Deep Isometric Learning for Visual Recognition
Jun 30, 2020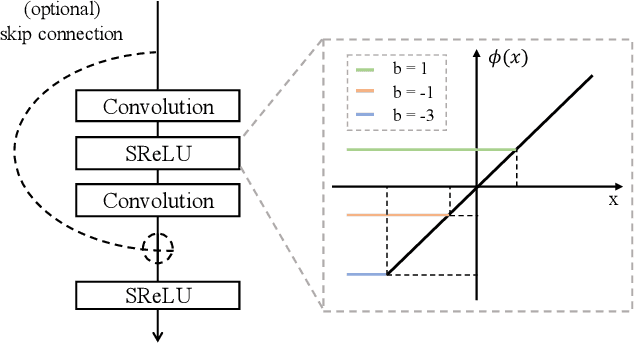
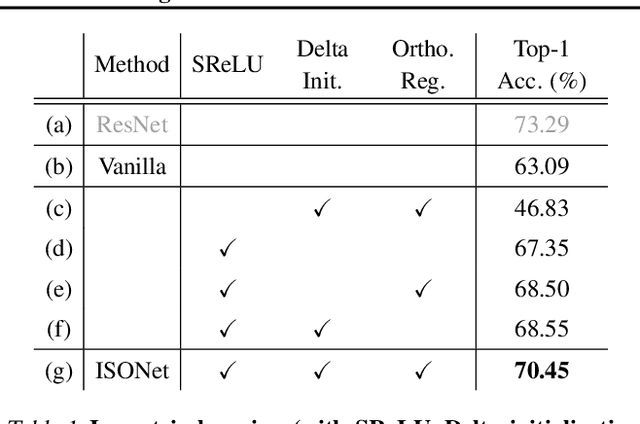
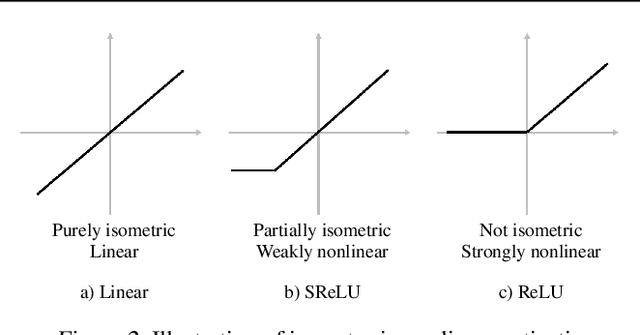
Initialization, normalization, and skip connections are believed to be three indispensable techniques for training very deep convolutional neural networks and obtaining state-of-the-art performance. This paper shows that deep vanilla ConvNets without normalization nor skip connections can also be trained to achieve surprisingly good performance on standard image recognition benchmarks. This is achieved by enforcing the convolution kernels to be near isometric during initialization and training, as well as by using a variant of ReLU that is shifted towards being isometric. Further experiments show that if combined with skip connections, such near isometric networks can achieve performances on par with (for ImageNet) and better than (for COCO) the standard ResNet, even without normalization at all. Our code is available at https://github.com/HaozhiQi/ISONet.