 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnnotation Inconsistency and Entity Bias in MultiWOZ
May 29, 2021
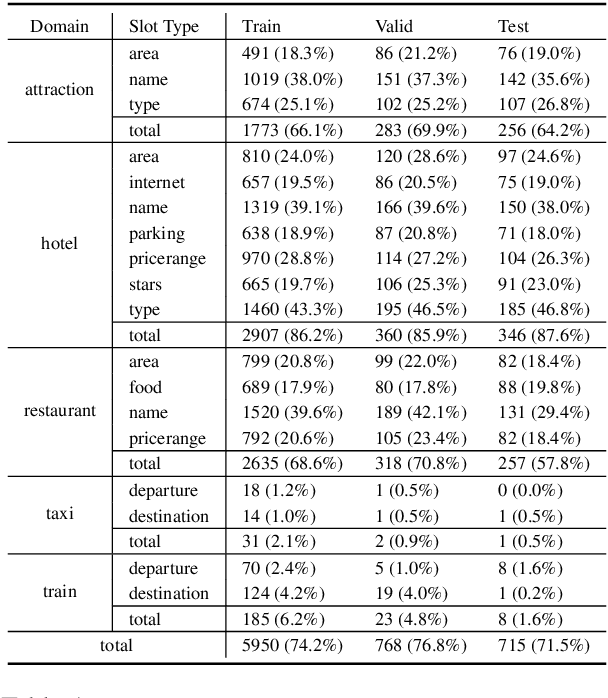
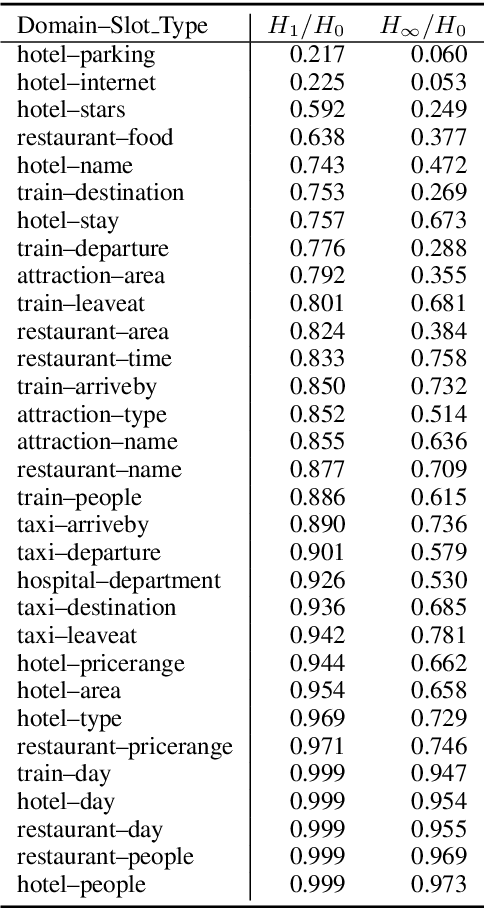

MultiWOZ is one of the most popular multi-domain task-oriented dialog datasets, containing 10K+ annotated dialogs covering eight domains. It has been widely accepted as a benchmark for various dialog tasks, e.g., dialog state tracking (DST), natural language generation (NLG), and end-to-end (E2E) dialog modeling. In this work, we identify an overlooked issue with dialog state annotation inconsistencies in the dataset, where a slot type is tagged inconsistently across similar dialogs leading to confusion for DST modeling. We propose an automated correction for this issue, which is present in a whopping 70% of the dialogs. Additionally, we notice that there is significant entity bias in the dataset (e.g., "cambridge" appears in 50% of the destination cities in the train domain). The entity bias can potentially lead to named entity memorization in generative models, which may go unnoticed as the test set suffers from a similar entity bias as well. We release a new test set with all entities replaced with unseen entities. Finally, we benchmark joint goal accuracy (JGA) of the state-of-the-art DST baselines on these modified versions of the data. Our experiments show that the annotation inconsistency corrections lead to 7-10% improvement in JGA. On the other hand, we observe a 29% drop in JGA when models are evaluated on the new test set with unseen entities.
DVD: A Diagnostic Dataset for Multi-step Reasoning in Video Grounded Dialogue
Jan 01, 2021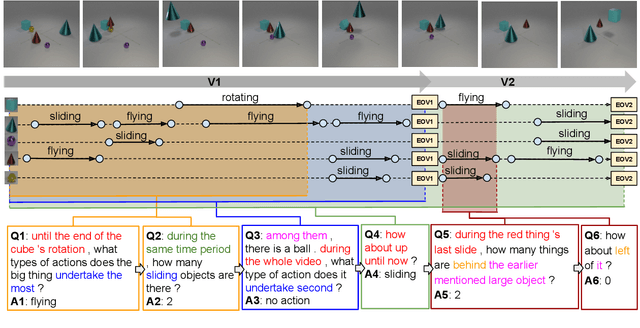
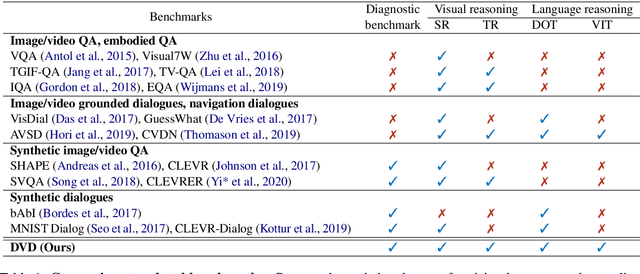
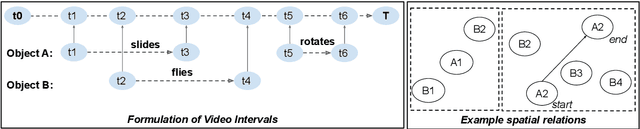
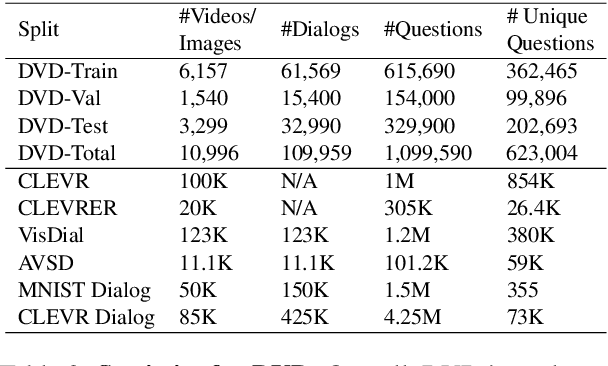
A video-grounded dialogue system is required to understand both dialogue, which contains semantic dependencies from turn to turn, and video, which contains visual cues of spatial and temporal scene variations. Building such dialogue systems is a challenging problem involving complex multimodal and temporal inputs, and studying them independently is hard with existing datasets. Existing benchmarks do not have enough annotations to help analyze dialogue systems and understand their linguistic and visual reasoning capability and limitations in isolation. These benchmarks are also not explicitly designed to minimize biases that models can exploit without actual reasoning. To address these limitations, in this paper, we present a diagnostic dataset that can test a range of reasoning abilities on videos and dialogues. The dataset is designed to contain minimal biases and has detailed annotations for the different types of reasoning each question requires, including cross-turn video interval tracking and dialogue object tracking. We use our dataset to analyze several dialogue system approaches, providing interesting insights into their abilities and limitations. In total, the dataset contains $10$ instances of $10$-round dialogues for each of $\sim11k$ synthetic videos, resulting in more than $100k$ dialogues and $1M$ question-answer pairs. Our code and dataset will be made public.
ProFormer: Towards On-Device LSH Projection Based Transformers
Apr 13, 2020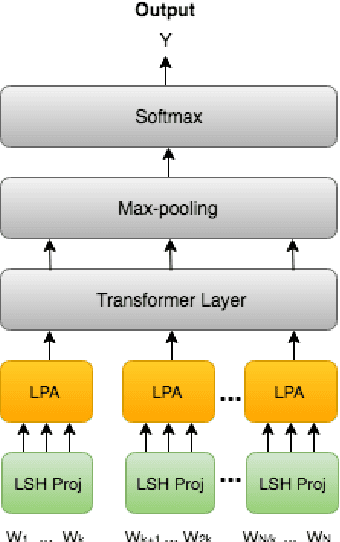

At the heart of text based neural models lay word representations, which are powerful but occupy a lot of memory making it challenging to deploy to devices with memory constraints such as mobile phones, watches and IoT. To surmount these challenges, we introduce ProFormer -- a projection based transformer architecture that is faster and lighter making it suitable to deploy to memory constraint devices and preserve user privacy. We use LSH projection layer to dynamically generate word representations on-the-fly without embedding lookup tables leading to significant memory footprint reduction from O(V.d) to O(T), where V is the vocabulary size, d is the embedding dimension size and T is the dimension of the LSH projection representation. We also propose a local projection attention (LPA) layer, which uses self-attention to transform the input sequence of N LSH word projections into a sequence of N/K representations reducing the computations quadratically by O(K^2). We evaluate ProFormer on multiple text classification tasks and observed improvements over prior state-of-the-art on-device approaches for short text classification and comparable performance for long text classification tasks. In comparison with a 2-layer BERT model, ProFormer reduced the embedding memory footprint from 92.16 MB to 1.3 KB and requires 16 times less computation overhead, which is very impressive making it the fastest and smallest on-device model.
Neural Assistant: Joint Action Prediction, Response Generation, and Latent Knowledge Reasoning
Oct 31, 2019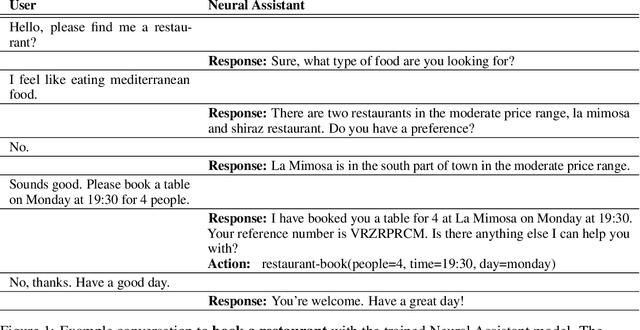
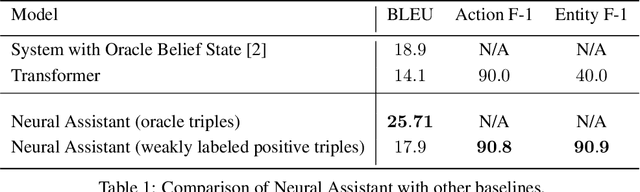
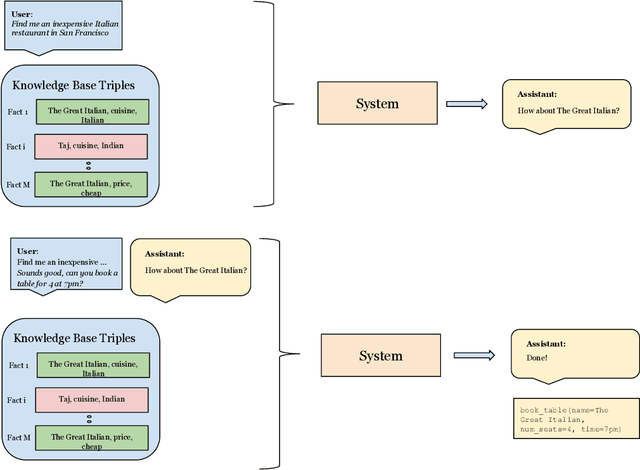
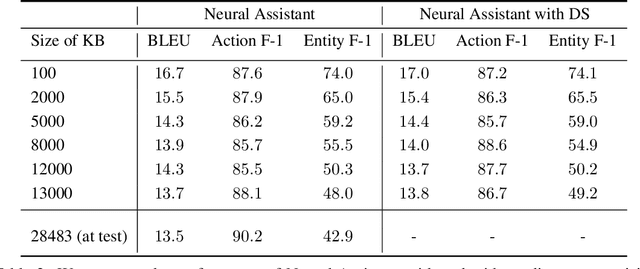
Task-oriented dialog presents a difficult challenge encompassing multiple problems including multi-turn language understanding and generation, knowledge retrieval and reasoning, and action prediction. Modern dialog systems typically begin by converting conversation history to a symbolic object referred to as belief state by using supervised learning. The belief state is then used to reason on an external knowledge source whose result along with the conversation history is used in action prediction and response generation tasks independently. Such a pipeline of individually optimized components not only makes the development process cumbersome but also makes it non-trivial to leverage session-level user reinforcement signals. In this paper, we develop Neural Assistant: a single neural network model that takes conversation history and an external knowledge source as input and jointly produces both text response and action to be taken by the system as output. The model learns to reason on the provided knowledge source with weak supervision signal coming from the text generation and the action prediction tasks, hence removing the need for belief state annotations. In the MultiWOZ dataset, we study the effect of distant supervision, and the size of knowledge base on model performance. We find that the Neural Assistant without belief states is able to incorporate external knowledge information achieving higher factual accuracy scores compared to Transformer. In settings comparable to reported baseline systems, Neural Assistant when provided with oracle belief state significantly improves language generation performance.
Taskmaster-1: Toward a Realistic and Diverse Dialog Dataset
Sep 01, 2019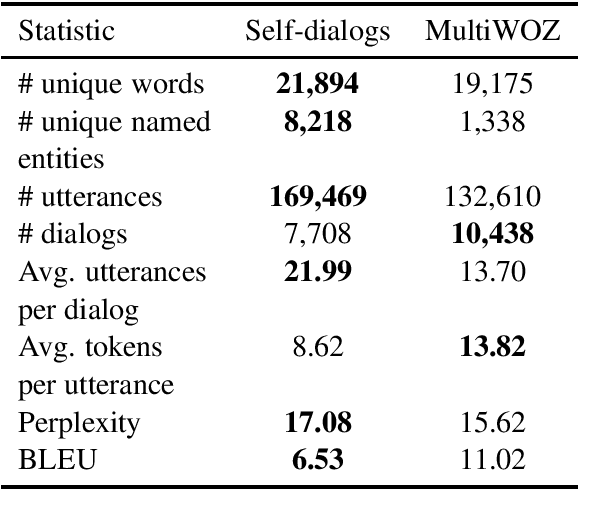

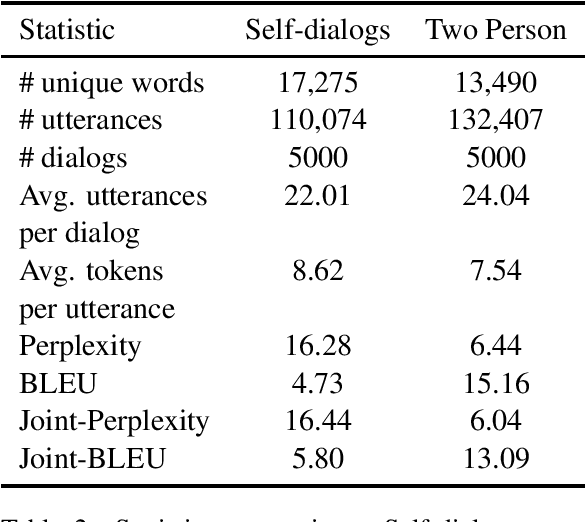
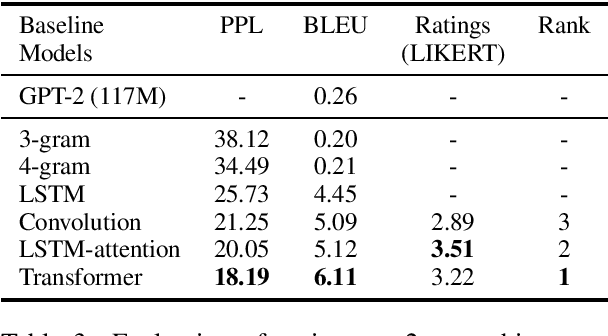
A significant barrier to progress in data-driven approaches to building dialog systems is the lack of high quality, goal-oriented conversational data. To help satisfy this elementary requirement, we introduce the initial release of the Taskmaster-1 dataset which includes 13,215 task-based dialogs comprising six domains. Two procedures were used to create this collection, each with unique advantages. The first involves a two-person, spoken "Wizard of Oz" (WOz) approach in which trained agents and crowdsourced workers interact to complete the task while the second is "self-dialog" in which crowdsourced workers write the entire dialog themselves. We do not restrict the workers to detailed scripts or to a small knowledge base and hence we observe that our dataset contains more realistic and diverse conversations in comparison to existing datasets. We offer several baseline models including state of the art neural seq2seq architectures with benchmark performance as well as qualitative human evaluations. Dialogs are labeled with API calls and arguments, a simple and cost effective approach which avoids the requirement of complex annotation schema. The layer of abstraction between the dialog model and the service provider API allows for a given model to interact with multiple services that provide similar functionally. Finally, the dataset will evoke interest in written vs. spoken language, discourse patterns, error handling and other linguistic phenomena related to dialog system research, development and design.
On the Robustness of Projection Neural Networks For Efficient Text Representation: An Empirical Study
Aug 14, 2019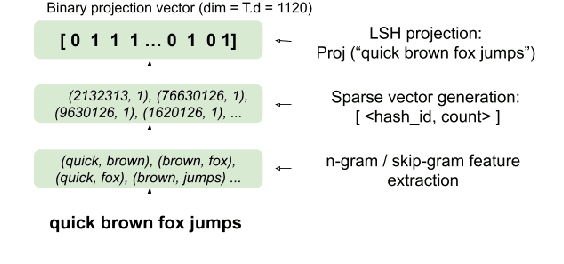
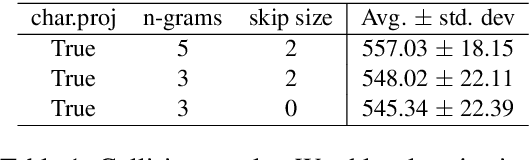
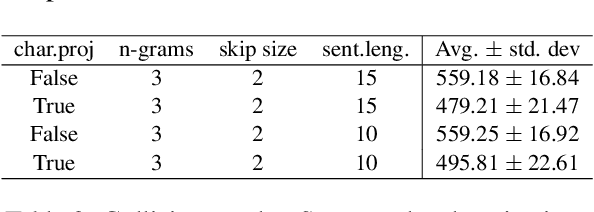
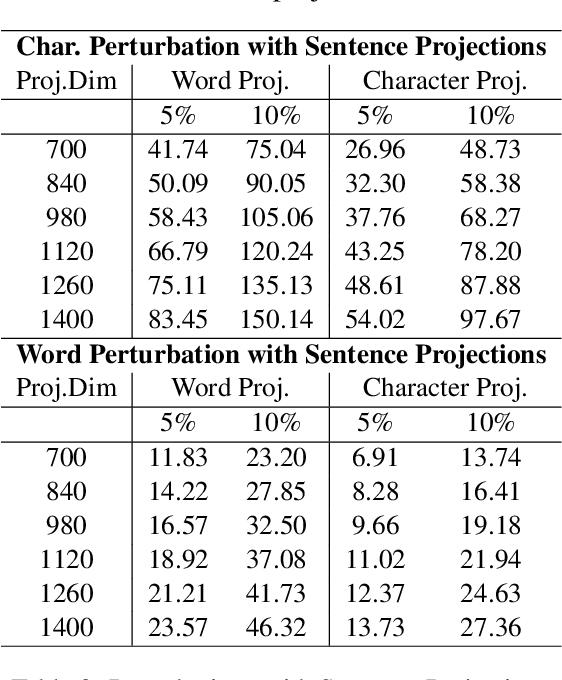
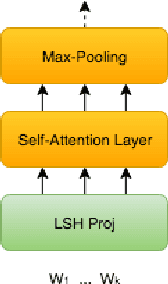
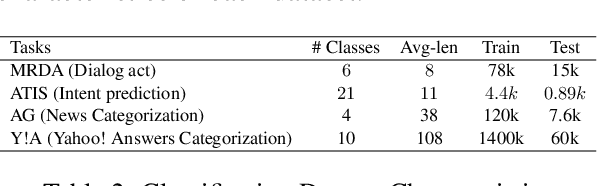
Recently, there has been strong interest in developing natural language applications that live on personal devices such as mobile phones, watches and IoT with the objective to preserve user privacy and have low memory. Advances in Locality-Sensitive Hashing (LSH)-based projection networks have demonstrated state-of-the-art performance without any embedding lookup tables and instead computing on-the-fly text representations. However, previous works have not investigated "What makes projection neural networks effective at capturing compact representations for text classification?" and "Are these projection models resistant to perturbations and misspellings in input text?". In this paper, we analyze and answer these questions through perturbation analyses and by running experiments on multiple dialog act prediction tasks. Our results show that the projections are resistant to perturbations and misspellings compared to widely-used recurrent architectures that use word embeddings. On ATIS intent prediction task, when evaluated with perturbed input data, we observe that the performance of recurrent models that use word embeddings drops significantly by more than 30% compared to just 5% with projection networks, showing that LSH-based projection representations are robust and consistently lead to high quality performance.
Deep Reinforcement Learning For Modeling Chit-Chat Dialog With Discrete Attributes
Jul 05, 2019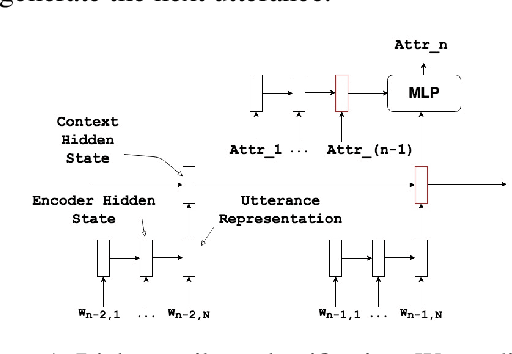

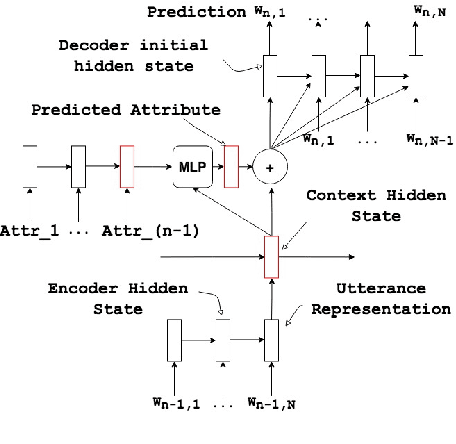
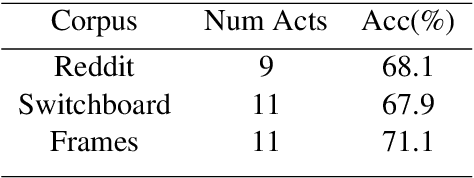
Open domain dialog systems face the challenge of being repetitive and producing generic responses. In this paper, we demonstrate that by conditioning the response generation on interpretable discrete dialog attributes and composed attributes, it helps improve the model perplexity and results in diverse and interesting non-redundant responses. We propose to formulate the dialog attribute prediction as a reinforcement learning (RL) problem and use policy gradients methods to optimize utterance generation using long-term rewards. Unlike existing RL approaches which formulate the token prediction as a policy, our method reduces the complexity of the policy optimization by limiting the action space to dialog attributes, thereby making the policy optimization more practical and sample efficient. We demonstrate this with experimental and human evaluations.
Transferable Neural Projection Representations
Jun 04, 2019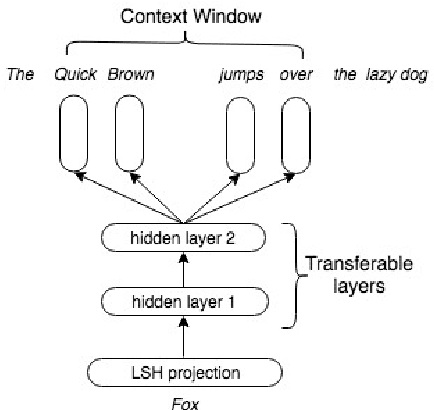
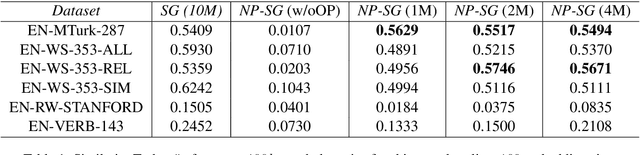

Neural word representations are at the core of many state-of-the-art natural language processing models. A widely used approach is to pre-train, store and look up word or character embedding matrices. While useful, such representations occupy huge memory making it hard to deploy on-device and often do not generalize to unknown words due to vocabulary pruning. In this paper, we propose a skip-gram based architecture coupled with Locality-Sensitive Hashing (LSH) projections to learn efficient dynamically computable representations. Our model does not need to store lookup tables as representations are computed on-the-fly and require low memory footprint. The representations can be trained in an unsupervised fashion and can be easily transferred to other NLP tasks. For qualitative evaluation, we analyze the nearest neighbors of the word representations and discover semantically similar words even with misspellings. For quantitative evaluation, we plug our transferable projections into a simple LSTM and run it on multiple NLP tasks and show how our transferable projections achieve better performance compared to prior work.
Do Neural Dialog Systems Use the Conversation History Effectively? An Empirical Study
Jun 04, 2019
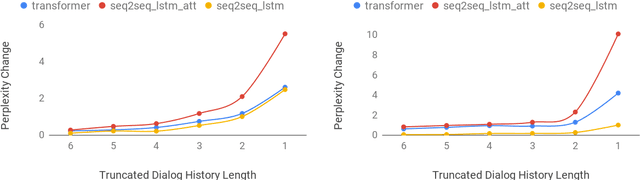
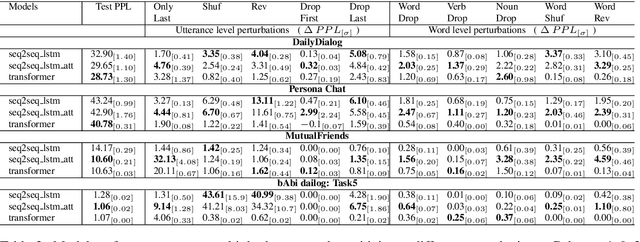
Neural generative models have been become increasingly popular when building conversational agents. They offer flexibility, can be easily adapted to new domains, and require minimal domain engineering. A common criticism of these systems is that they seldom understand or use the available dialog history effectively. In this paper, we take an empirical approach to understanding how these models use the available dialog history by studying the sensitivity of the models to artificially introduced unnatural changes or perturbations to their context at test time. We experiment with 10 different types of perturbations on 4 multi-turn dialog datasets and find that commonly used neural dialog architectures like recurrent and transformer-based seq2seq models are rarely sensitive to most perturbations such as missing or reordering utterances, shuffling words, etc. Also, by open-sourcing our code, we believe that it will serve as a useful diagnostic tool for evaluating dialog systems in the future.
The Bottleneck Simulator: A Model-based Deep Reinforcement Learning Approach
Jul 12, 2018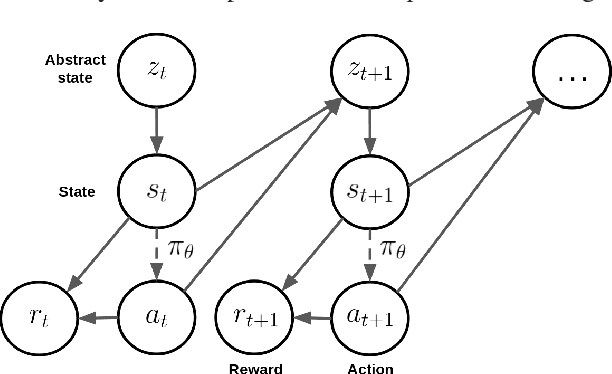

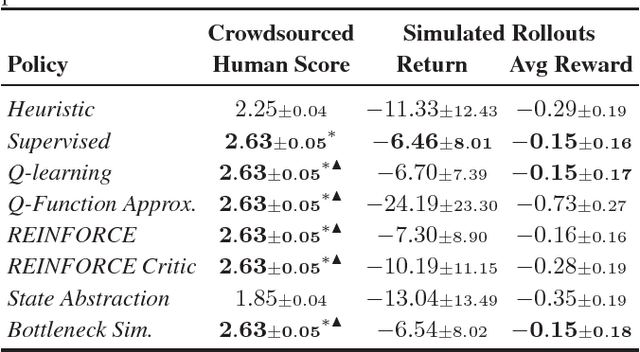
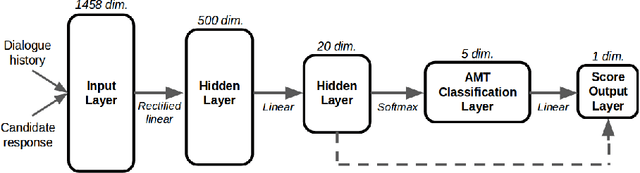
Deep reinforcement learning has recently shown many impressive successes. However, one major obstacle towards applying such methods to real-world problems is their lack of data-efficiency. To this end, we propose the Bottleneck Simulator: a model-based reinforcement learning method which combines a learned, factorized transition model of the environment with rollout simulations to learn an effective policy from few examples. The learned transition model employs an abstract, discrete (bottleneck) state, which increases sample efficiency by reducing the number of model parameters and by exploiting structural properties of the environment. We provide a mathematical analysis of the Bottleneck Simulator in terms of fixed points of the learned policy, which reveals how performance is affected by four distinct sources of error: an error related to the abstract space structure, an error related to the transition model estimation variance, an error related to the transition model estimation bias, and an error related to the transition model class bias. Finally, we evaluate the Bottleneck Simulator on two natural language processing tasks: a text adventure game and a real-world, complex dialogue response selection task. On both tasks, the Bottleneck Simulator yields excellent performance beating competing approaches.