 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical fuzzy neural networks with privacy preservation for heterogeneous big data
Sep 18, 2022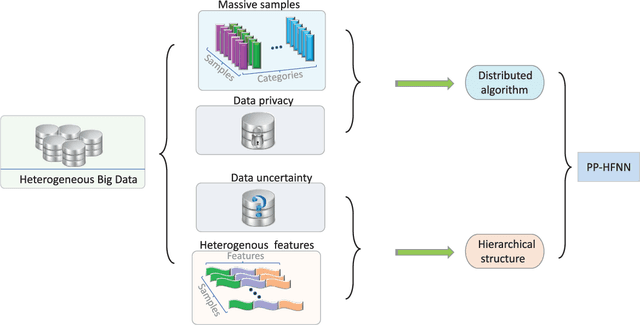
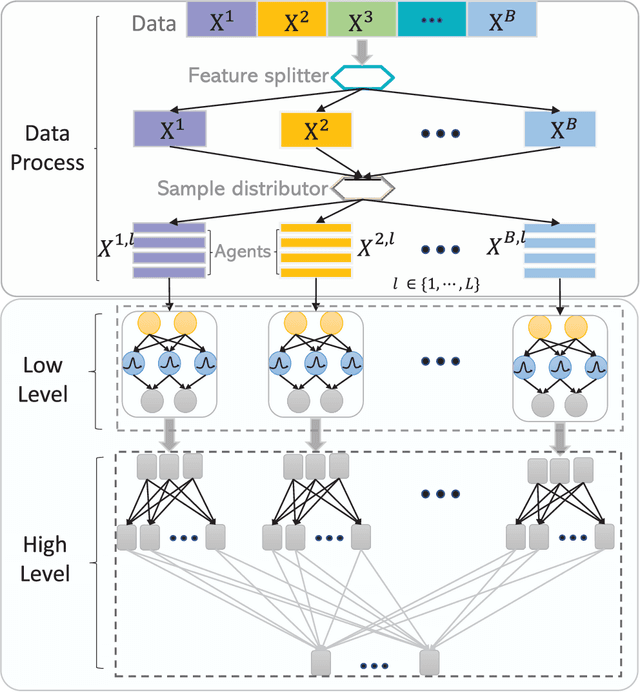
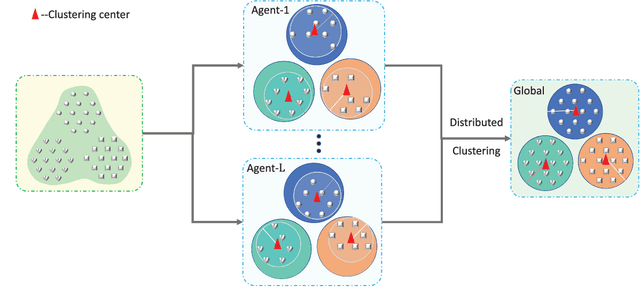
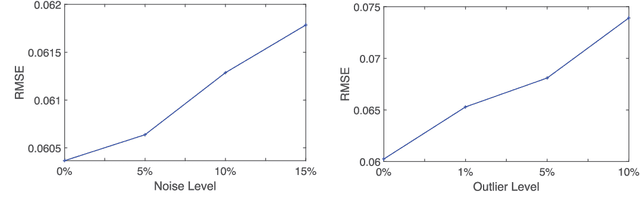
Heterogeneous big data poses many challenges in machine learning. Its enormous scale, high dimensionality, and inherent uncertainty make almost every aspect of machine learning difficult, from providing enough processing power to maintaining model accuracy to protecting privacy. However, perhaps the most imposing problem is that big data is often interspersed with sensitive personal data. Hence, we propose a privacy-preserving hierarchical fuzzy neural network (PP-HFNN) to address these technical challenges while also alleviating privacy concerns. The network is trained with a two-stage optimization algorithm, and the parameters at low levels of the hierarchy are learned with a scheme based on the well-known alternating direction method of multipliers, which does not reveal local data to other agents. Coordination at high levels of the hierarchy is handled by the alternating optimization method, which converges very quickly. The entire training procedure is scalable, fast and does not suffer from gradient vanishing problems like the methods based on back-propagation. Comprehensive simulations conducted on both regression and classification tasks demonstrate the effectiveness of the proposed model.
Toward multi-target self-organizing pursuit in a partially observable Markov game
Jun 24, 2022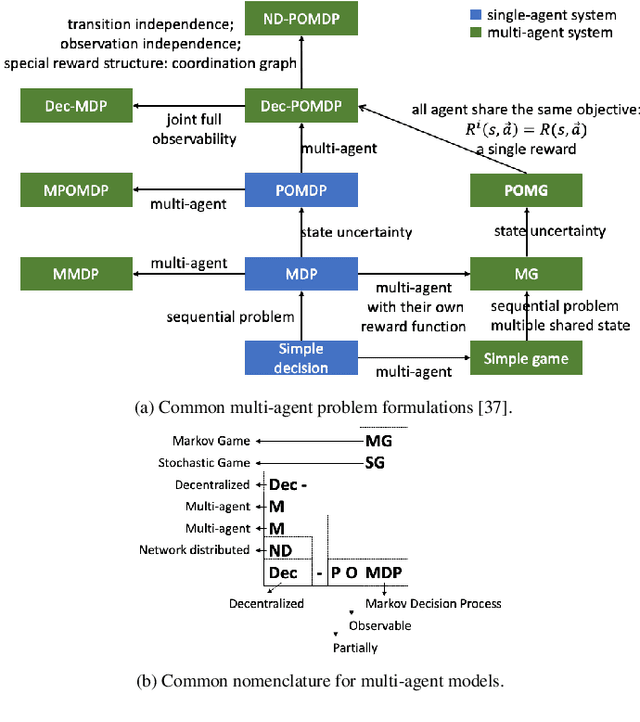

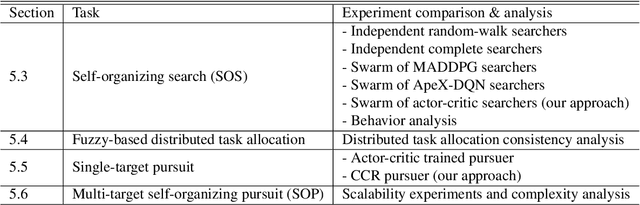
The multiple-target self-organizing pursuit (SOP) problem has wide applications and has been considered a challenging self-organization game for distributed systems, in which intelligent agents cooperatively pursue multiple dynamic targets with partial observations. This work proposes a framework for decentralized multi-agent systems to improve intelligent agents' search and pursuit capabilities. We model a self-organizing system as a partially observable Markov game (POMG) with the features of decentralization, partial observation, and noncommunication. The proposed distributed algorithm: fuzzy self-organizing cooperative coevolution (FSC2) is then leveraged to resolve the three challenges in multi-target SOP: distributed self-organizing search (SOS), distributed task allocation, and distributed single-target pursuit. FSC2 includes a coordinated multi-agent deep reinforcement learning method that enables homogeneous agents to learn natural SOS patterns. Additionally, we propose a fuzzy-based distributed task allocation method, which locally decomposes multi-target SOP into several single-target pursuit problems. The cooperative coevolution principle is employed to coordinate distributed pursuers for each single-target pursuit problem. Therefore, the uncertainties of inherent partial observation and distributed decision-making in the POMG can be alleviated. The experimental results demonstrate that distributed noncommunicating multi-agent coordination with partial observations in all three subtasks are effective, and 2048 FSC2 agents can perform efficient multi-target SOP with an almost 100% capture rate.
Semantic Autoencoder and Its Potential Usage for Adversarial Attack
May 31, 2022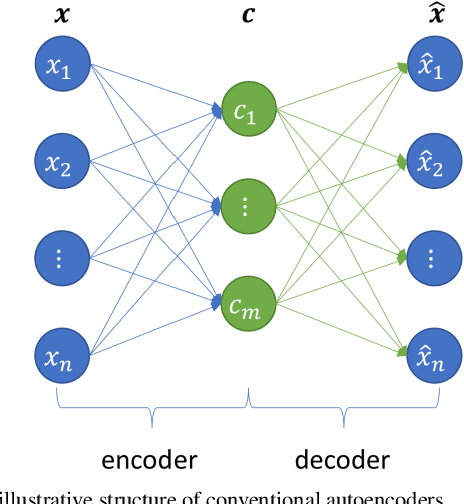
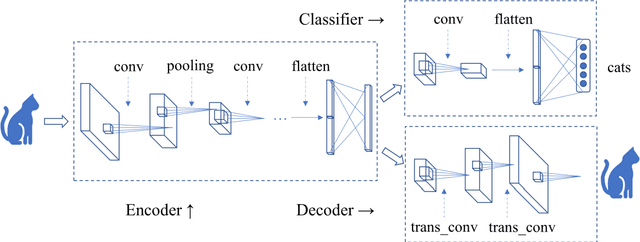
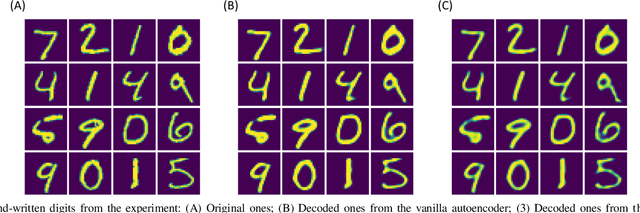
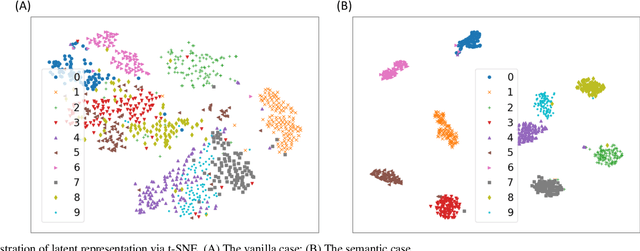
Autoencoder can give rise to an appropriate latent representation of the input data, however, the representation which is solely based on the intrinsic property of the input data, is usually inferior to express some semantic information. A typical case is the potential incapability of forming a clear boundary upon clustering of these representations. By encoding the latent representation that not only depends on the content of the input data, but also the semantic of the input data, such as label information, we propose an enhanced autoencoder architecture named semantic autoencoder. Experiments of representation distribution via t-SNE shows a clear distinction between these two types of encoders and confirm the supremacy of the semantic one, whilst the decoded samples of these two types of autoencoders exhibit faint dissimilarity either objectively or subjectively. Based on this observation, we consider adversarial attacks to learning algorithms that rely on the latent representation obtained via autoencoders. It turns out that latent contents of adversarial samples constructed from semantic encoder with deliberate wrong label information exhibit different distribution compared with that of the original input data, while both of these samples manifest very marginal difference. This new way of attack set up by our work is worthy of attention due to the necessity to secure the widespread deep learning applications.
On the utility of power spectral techniques with feature selection techniques for effective mental task classification in noninvasive BCI
Nov 16, 2021
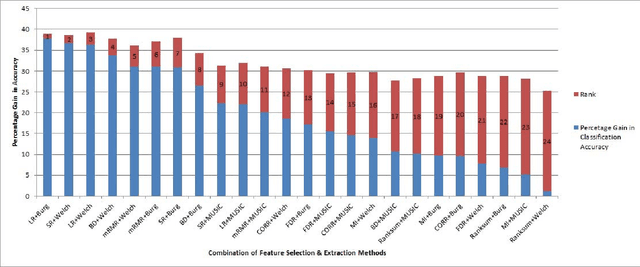
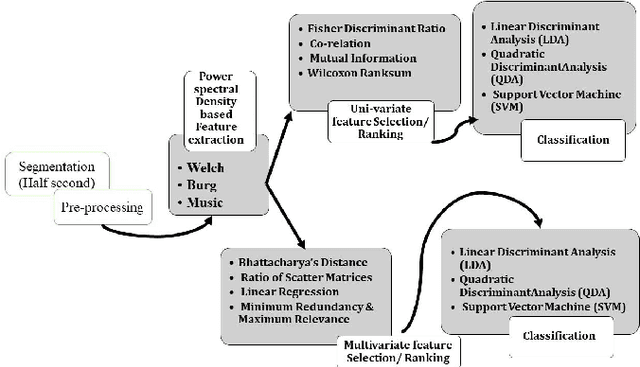
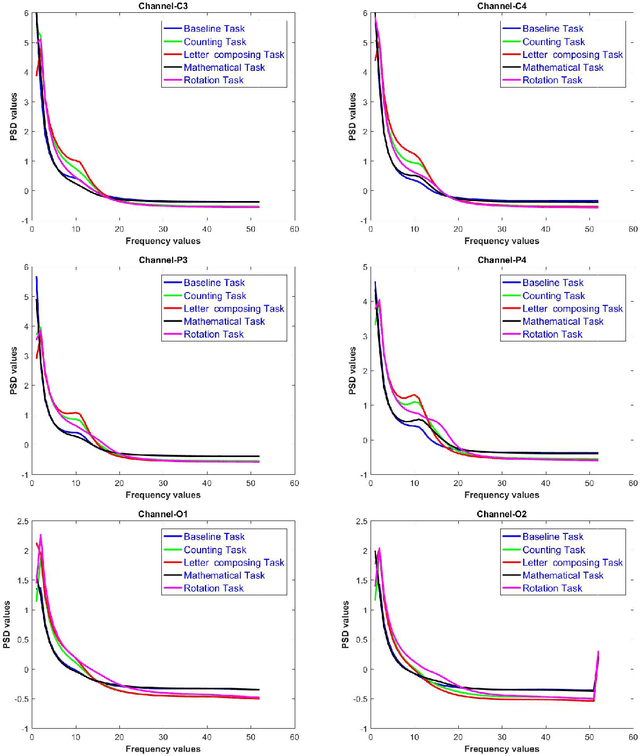
In this paper classification of mental task-root Brain-Computer Interfaces (BCI) is being investigated, as those are a dominant area of investigations in BCI and are of utmost interest as these systems can be augmented life of people having severe disabilities. The BCI model's performance is primarily dependent on the size of the feature vector, which is obtained through multiple channels. In the case of mental task classification, the availability of training samples to features are minimal. Very often, feature selection is used to increase the ratio for the mental task classification by getting rid of irrelevant and superfluous features. This paper proposes an approach to select relevant and non-redundant spectral features for the mental task classification. This can be done by using four very known multivariate feature selection methods viz, Bhattacharya's Distance, Ratio of Scatter Matrices, Linear Regression and Minimum Redundancy & Maximum Relevance. This work also deals with a comparative analysis of multivariate and univariate feature selection for mental task classification. After applying the above-stated method, the findings demonstrate substantial improvements in the performance of the learning model for mental task classification. Moreover, the efficacy of the proposed approach is endorsed by carrying out a robust ranking algorithm and Friedman's statistical test for finding the best combinations and comparing different combinations of power spectral density and feature selection methods.
Deep hierarchical reinforcement agents for automated penetration testing
Sep 14, 2021
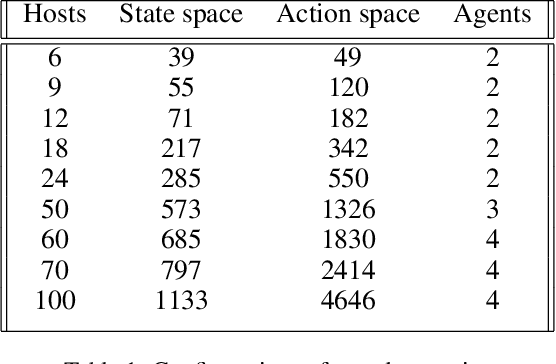
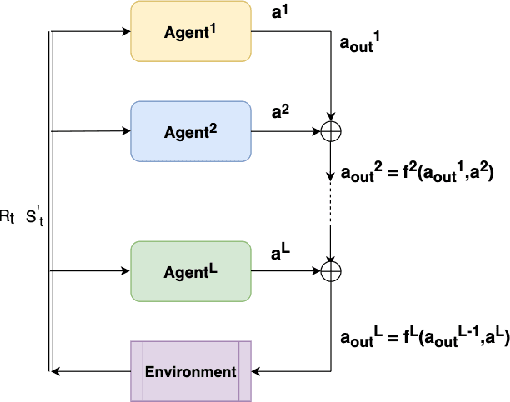
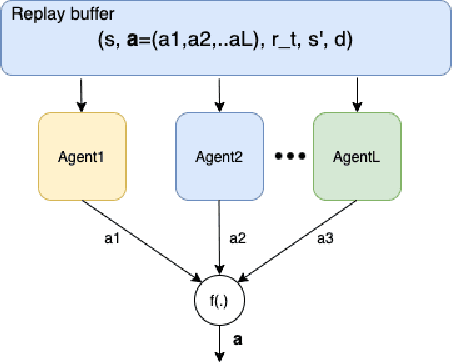
Penetration testing the organised attack of a computer system in order to test existing defences has been used extensively to evaluate network security. This is a time consuming process and requires in-depth knowledge for the establishment of a strategy that resembles a real cyber-attack. This paper presents a novel deep reinforcement learning architecture with hierarchically structured agents called HA-DRL, which employs an algebraic action decomposition strategy to address the large discrete action space of an autonomous penetration testing simulator where the number of actions is exponentially increased with the complexity of the designed cybersecurity network. The proposed architecture is shown to find the optimal attacking policy faster and more stably than a conventional deep Q-learning agent which is commonly used as a method to apply artificial intelligence in automatic penetration testing.
Identification of EEG Dynamics During Freezing of Gait and Voluntary Stopping in Patients with Parkinson's Disease
Feb 06, 2021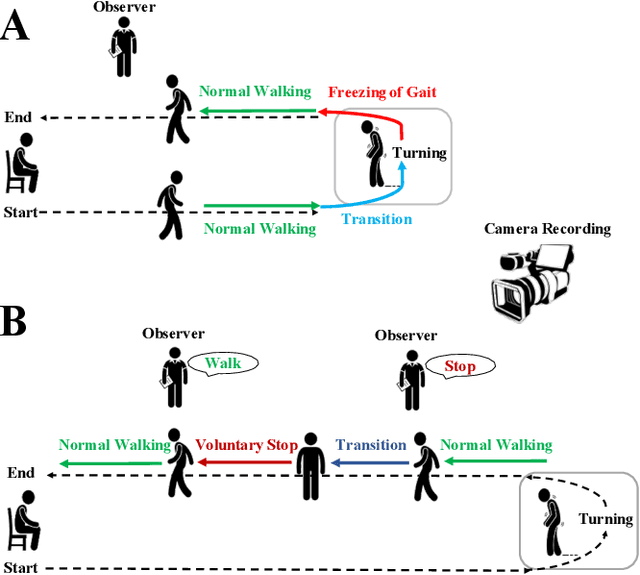
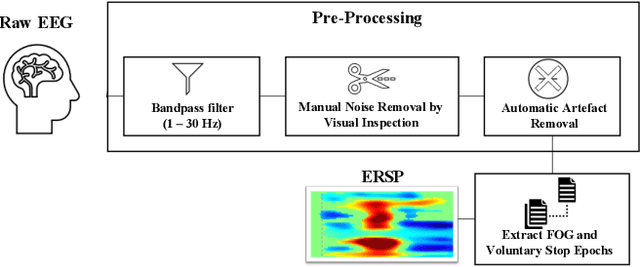
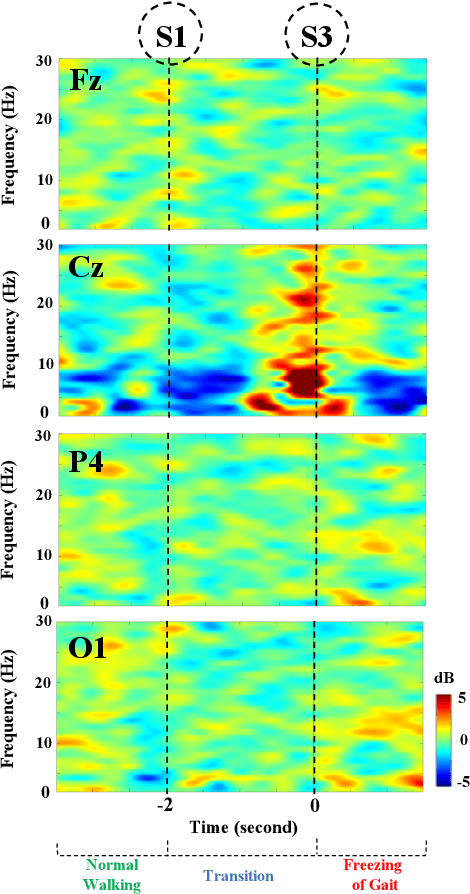
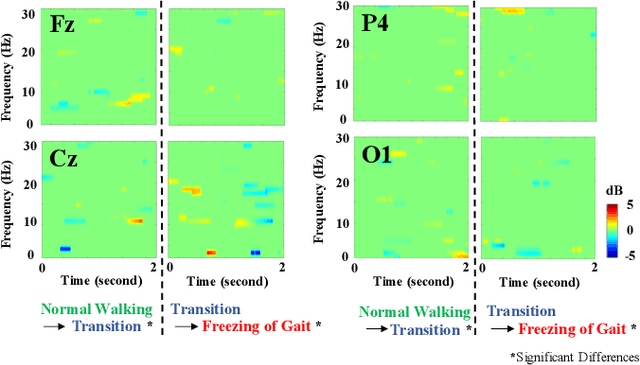
Mobility is severely impacted in patients with Parkinson's disease (PD), especially when they experience involuntary stopping from the freezing of gait (FOG). Understanding the neurophysiological difference between "voluntary stopping" and "involuntary stopping" caused by FOG is vital for the detection and potential intervention of FOG in the daily lives of patients. This study characterised the electroencephalographic (EEG) signature associated with FOG in contrast to voluntary stopping. The protocol consisted of a timed up-and-go (TUG) task and an additional TUG task with a voluntary stopping component, where participants reacted to verbal "stop" and "walk" instructions by voluntarily stopping or walking. Event-related spectral perturbation (ERSP) analysis was used to study the dynamics of the EEG spectra induced by different walking phases, which included normal walking, voluntary stopping and episodes of involuntary stopping (FOG), as well as the transition windows between normal walking and voluntary stopping or FOG. These results demonstrate for the first time that the EEG signal during the transition from walking to voluntary stopping is distinguishable from that of the transition to involuntary stopping caused by FOG. The EEG signature of voluntary stopping exhibits a significantly decreased power spectrum compared to that of FOG episodes, with distinctly different patterns in the delta and low-beta power in the central area. These findings suggest the possibility of a practical EEG-based treatment strategy that can accurately predict FOG episodes, excluding the potential confound of voluntary stopping.
Motor-Imagery-Based Brain Computer Interface using Signal Derivation and Aggregation Functions
Jan 18, 2021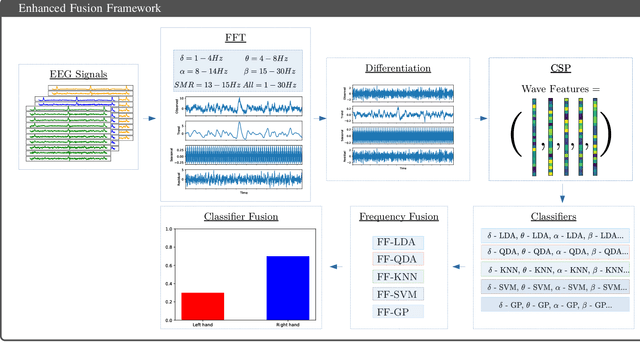
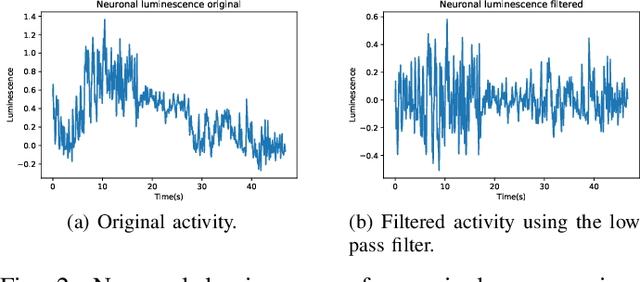
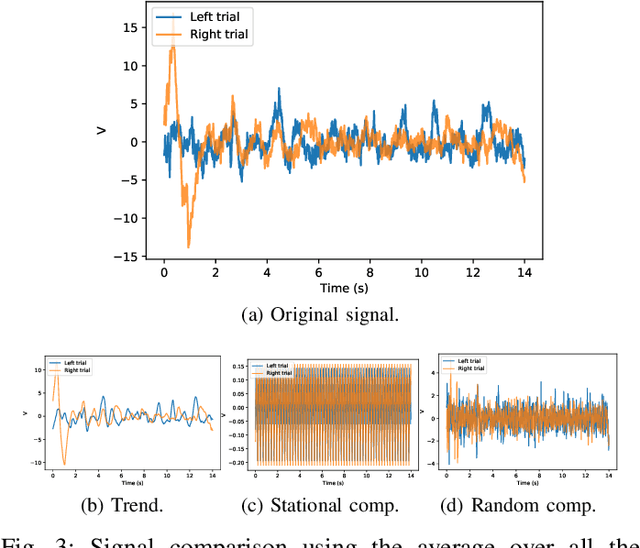
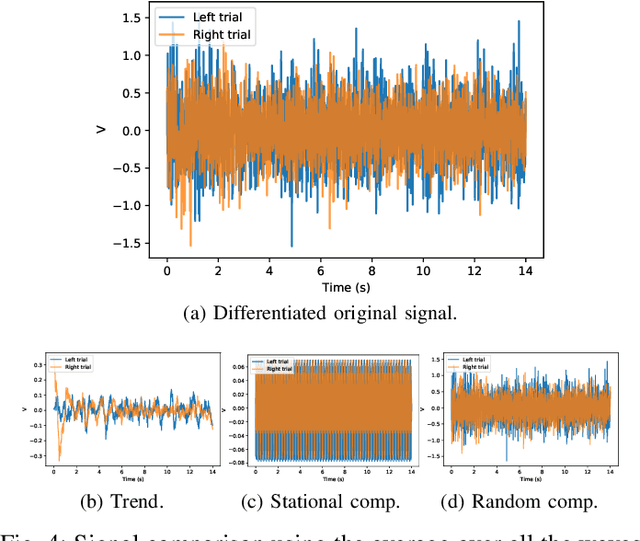
Brain Computer Interface technologies are popular methods of communication between the human brain and external devices. One of the most popular approaches to BCI is Motor Imagery. In BCI applications, the ElectroEncephaloGraphy is a very popular measurement for brain dynamics because of its non-invasive nature. Although there is a high interest in the BCI topic, the performance of existing systems is still far from ideal, due to the difficulty of performing pattern recognition tasks in EEG signals. BCI systems are composed of a wide range of components that perform signal pre-processing, feature extraction and decision making. In this paper, we define a BCI Framework, named Enhanced Fusion Framework, where we propose three different ideas to improve the existing MI-based BCI frameworks. Firstly, we include aan additional pre-processing step of the signal: a differentiation of the EEG signal that makes it time-invariant. Secondly, we add an additional frequency band as feature for the system and we show its effect on the performance of the system. Finally, we make a profound study of how to make the final decision in the system. We propose the usage of both up to six types of different classifiers and a wide range of aggregation functions (including classical aggregations, Choquet and Sugeno integrals and their extensions and overlap functions) to fuse the information given by the considered classifiers. We have tested this new system on a dataset of 20 volunteers performing motor imagery-based brain-computer interface experiments. On this dataset, the new system achieved a 88.80% of accuracy. We also propose an optimized version of our system that is able to obtain up to 90,76%. Furthermore, we find that the pair Choquet/Sugeno integrals and overlap functions are the ones providing the best results.
EEG-Based Brain-Computer Interfaces Are Vulnerable to Backdoor Attacks
Oct 30, 2020
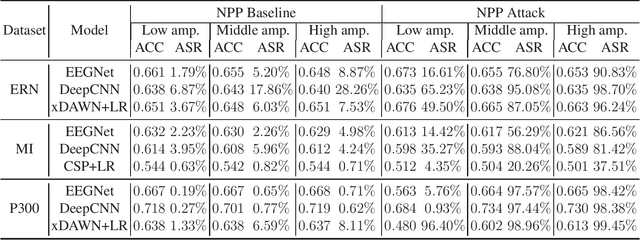
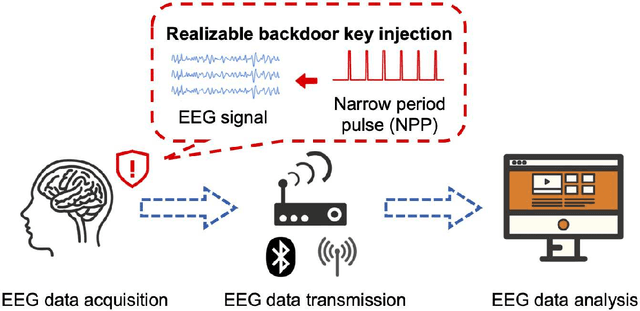
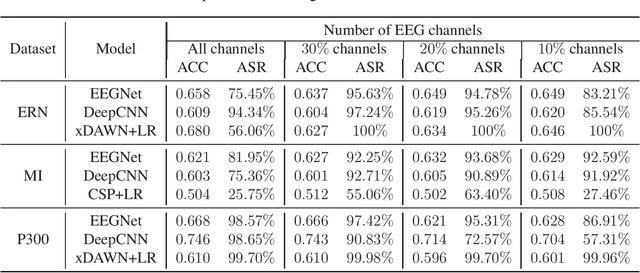
Research and development of electroencephalogram (EEG) based brain-computer interfaces (BCIs) have advanced rapidly, partly due to the wide adoption of sophisticated machine learning approaches for decoding the EEG signals. However, recent studies have shown that machine learning algorithms are vulnerable to adversarial attacks, e.g., the attacker can add tiny adversarial perturbations to a test sample to fool the model, or poison the training data to insert a secret backdoor. Previous research has shown that adversarial attacks are also possible for EEG-based BCIs. However, only adversarial perturbations have been considered, and the approaches are theoretically sound but very difficult to implement in practice. This article proposes to use narrow period pulse for poisoning attack of EEG-based BCIs, which is more feasible in practice and has never been considered before. One can create dangerous backdoors in the machine learning model by injecting poisoning samples into the training set. Test samples with the backdoor key will then be classified into the target class specified by the attacker. What most distinguishes our approach from previous ones is that the backdoor key does not need to be synchronized with the EEG trials, making it very easy to implement. The effectiveness and robustness of the backdoor attack approach is demonstrated, highlighting a critical security concern for EEG-based BCIs.
Human Preference Scaling with Demonstrations For Deep Reinforcement Learning
Jul 25, 2020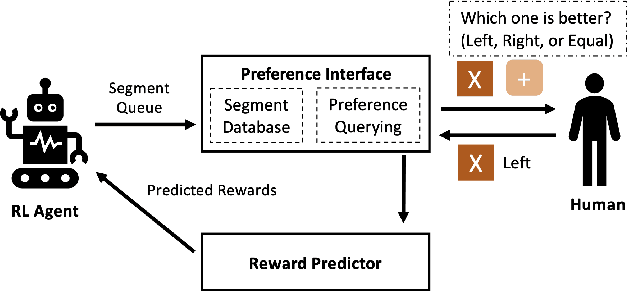
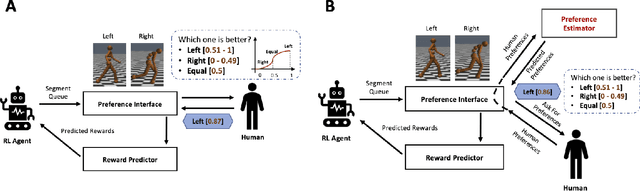
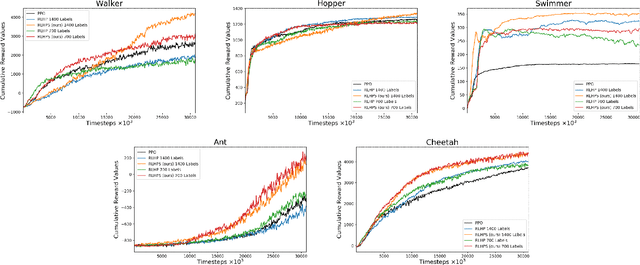
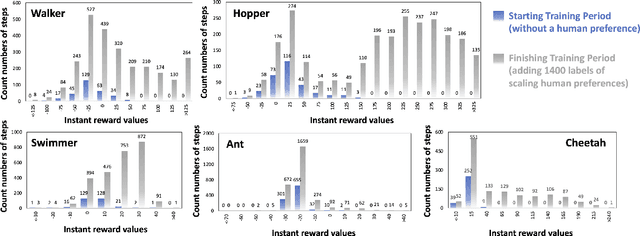
The current reward learning from human preferences could be used for resolving complex reinforcement learning (RL) tasks without access to the reward function by defining a single fixed preference between pairs of trajectory segments. However, the judgement of preferences between trajectories is not dynamic and still requires human inputs over 1,000 times. In this study, we propose a human preference scaling model that naturally reflects the human perception of the degree of choice between trajectories and then develop a human-demonstration preference model via supervised learning to reduce the number of human inputs. The proposed human preference scaling model with demonstrations can effectively solve complex RL tasks and achieve higher cumulative rewards in simulated robot locomotion - MuJoCo games - relative to the single fixed human preferences. Furthermore, our developed human-demonstration preference model only needs human feedback for less than 0.01\% of the agent's interactions with the environment and significantly reduces up to 30\% of the cost of human inputs compared to the existing approaches. To present the flexibility of our approach, we released a video (https://youtu.be/jQPe1OILT0M) showing comparisons of behaviours of agents trained with different types of human inputs. We believe that our naturally inspired human preference scaling with demonstrations is beneficial for precise reward learning and can potentially be applied to state-of-the-art RL systems, such as autonomy-level driving systems.
Multi-Subspace Neural Network for Image Recognition
Jun 17, 2020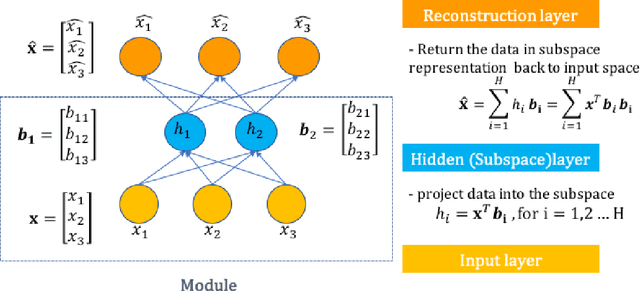
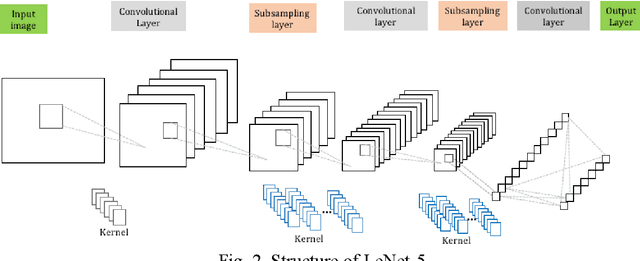
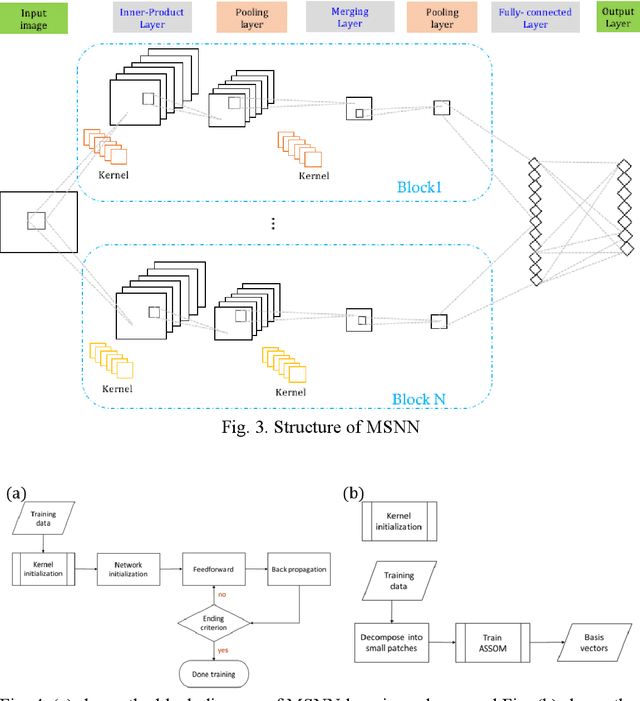
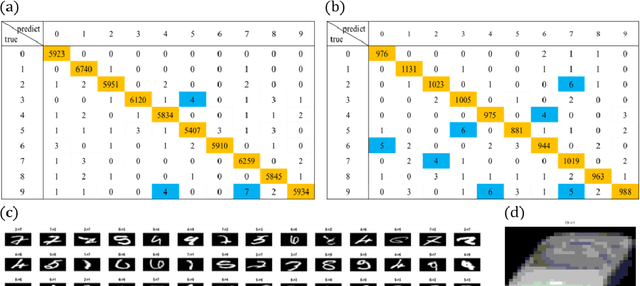
In image classification task, feature extraction is always a big issue. Intra-class variability increases the difficulty in designing the extractors. Furthermore, hand-crafted feature extractor cannot simply adapt new situation. Recently, deep learning has drawn lots of attention on automatically learning features from data. In this study, we proposed multi-subspace neural network (MSNN) which integrates key components of the convolutional neural network (CNN), receptive field, with subspace concept. Associating subspace with the deep network is a novel designing, providing various viewpoints of data. Basis vectors, trained by adaptive subspace self-organization map (ASSOM) span the subspace, serve as a transfer function to access axial components and define the receptive field to extract basic patterns of data without distorting the topology in the visual task. Moreover, the multiple-subspace strategy is implemented as parallel blocks to adapt real-world data and contribute various interpretations of data hoping to be more robust dealing with intra-class variability issues. To this end, handwritten digit and object image datasets (i.e., MNIST and COIL-20) for classification are employed to validate the proposed MSNN architecture. Experimental results show MSNN is competitive to other state-of-the-art approaches.