 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProMist-5K: A Comprehensive Dataset for Digital Emulation of Cinematic Pro-Mist Filter Effects
Jan 27, 2026Pro-Mist filters are widely used in cinematography for their ability to create soft halation, lower contrast, and produce a distinctive, atmospheric style. These effects are difficult to reproduce digitally due to the complex behavior of light diffusion. We present ProMist-5K, a dataset designed to support cinematic style emulation. It is built using a physically inspired pipeline in a scene-referred linear space and includes 20,000 high-resolution image pairs across four configurations, covering two filter densities (1/2 and 1/8) and two focal lengths (20mm and 50mm). Unlike general style datasets, ProMist-5K focuses on realistic glow and highlight diffusion effects. Multiple blur layers and carefully tuned weighting are used to model the varying intensity and spread of optical diffusion. The dataset provides a consistent and controllable target domain that supports various image translation models and learning paradigms. Experiments show that the dataset works well across different training settings and helps capture both subtle and strong cinematic appearances. ProMist-5K offers a practical and physically grounded resource for film-inspired image transformation, bridging the gap between digital flexibility and traditional lens aesthetics. The dataset is available at https://www.kaggle.com/datasets/yingtielei/promist5k.
OTI: A Model-free and Visually Interpretable Measure of Image Attackability
Jan 24, 2026Despite the tremendous success of neural networks, benign images can be corrupted by adversarial perturbations to deceive these models. Intriguingly, images differ in their attackability. Specifically, given an attack configuration, some images are easily corrupted, whereas others are more resistant. Evaluating image attackability has important applications in active learning, adversarial training, and attack enhancement. This prompts a growing interest in developing attackability measures. However, existing methods are scarce and suffer from two major limitations: (1) They rely on a model proxy to provide prior knowledge (e.g., gradients or minimal perturbation) to extract model-dependent image features. Unfortunately, in practice, many task-specific models are not readily accessible. (2) Extracted features characterizing image attackability lack visual interpretability, obscuring their direct relationship with the images. To address these, we propose a novel Object Texture Intensity (OTI), a model-free and visually interpretable measure of image attackability, which measures image attackability as the texture intensity of the image's semantic object. Theoretically, we describe the principles of OTI from the perspectives of decision boundaries as well as the mid- and high-frequency characteristics of adversarial perturbations. Comprehensive experiments demonstrate that OTI is effective and computationally efficient. In addition, our OTI provides the adversarial machine learning community with a visual understanding of attackability.
IO-RAE: Information-Obfuscation Reversible Adversarial Example for Audio Privacy Protection
Jan 03, 2026The rapid advancements in artificial intelligence have significantly accelerated the adoption of speech recognition technology, leading to its widespread integration across various applications. However, this surge in usage also highlights a critical issue: audio data is highly vulnerable to unauthorized exposure and analysis, posing significant privacy risks for businesses and individuals. This paper introduces an Information-Obfuscation Reversible Adversarial Example (IO-RAE) framework, the pioneering method designed to safeguard audio privacy using reversible adversarial examples. IO-RAE leverages large language models to generate misleading yet contextually coherent content, effectively preventing unauthorized eavesdropping by humans and Automatic Speech Recognition (ASR) systems. Additionally, we propose the Cumulative Signal Attack technique, which mitigates high-frequency noise and enhances attack efficacy by targeting low-frequency signals. Our approach ensures the protection of audio data without degrading its quality or our ability. Experimental evaluations demonstrate the superiority of our method, achieving a targeted misguidance rate of 96.5% and a remarkable 100% untargeted misguidance rate in obfuscating target keywords across multiple ASR models, including a commercial black-box system from Google. Furthermore, the quality of the recovered audio, measured by the Perceptual Evaluation of Speech Quality score, reached 4.45, comparable to high-quality original recordings. Notably, the recovered audio processed by ASR systems exhibited an error rate of 0%, indicating nearly lossless recovery. These results highlight the practical applicability and effectiveness of our IO-RAE framework in protecting sensitive audio privacy.
PersonaLive! Expressive Portrait Image Animation for Live Streaming
Dec 12, 2025



Current diffusion-based portrait animation models predominantly focus on enhancing visual quality and expression realism, while overlooking generation latency and real-time performance, which restricts their application range in the live streaming scenario. We propose PersonaLive, a novel diffusion-based framework towards streaming real-time portrait animation with multi-stage training recipes. Specifically, we first adopt hybrid implicit signals, namely implicit facial representations and 3D implicit keypoints, to achieve expressive image-level motion control. Then, a fewer-step appearance distillation strategy is proposed to eliminate appearance redundancy in the denoising process, greatly improving inference efficiency. Finally, we introduce an autoregressive micro-chunk streaming generation paradigm equipped with a sliding training strategy and a historical keyframe mechanism to enable low-latency and stable long-term video generation. Extensive experiments demonstrate that PersonaLive achieves state-of-the-art performance with up to 7-22x speedup over prior diffusion-based portrait animation models.
Dynamic Parameter Optimization for Highly Transferable Transformation-Based Attacks
Nov 15, 2025



Despite their wide application, the vulnerabilities of deep neural networks raise societal concerns. Among them, transformation-based attacks have demonstrated notable success in transfer attacks. However, existing attacks suffer from blind spots in parameter optimization, limiting their full potential. Specifically, (1) prior work generally considers low-iteration settings, yet attacks perform quite differently at higher iterations, so characterizing overall performance based only on low-iteration results is misleading. (2) Existing attacks use uniform parameters for different surrogate models, iterations, and tasks, which greatly impairs transferability. (3) Traditional transformation parameter optimization relies on grid search. For n parameters with m steps each, the complexity is O(mn). Large computational overhead limits further optimization of parameters. To address these limitations, we conduct an empirical study with various transformations as baselines, revealing three dynamic patterns of transferability with respect to parameter strength. We further propose a novel Concentric Decay Model (CDM) to effectively explain these patterns. Building on these insights, we propose an efficient Dynamic Parameter Optimization (DPO) based on the rise-then-fall pattern, reducing the complexity to O(nlogm). Comprehensive experiments on existing transformation-based attacks across different surrogate models, iterations, and tasks demonstrate that our DPO can significantly improve transferability.
Effective Gaussian Management for High-fidelity Object Reconstruction
Sep 16, 2025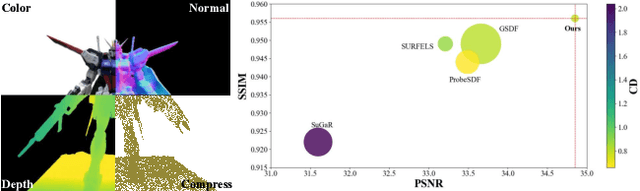
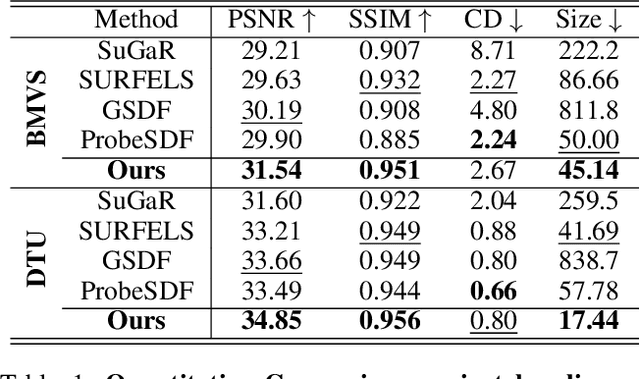
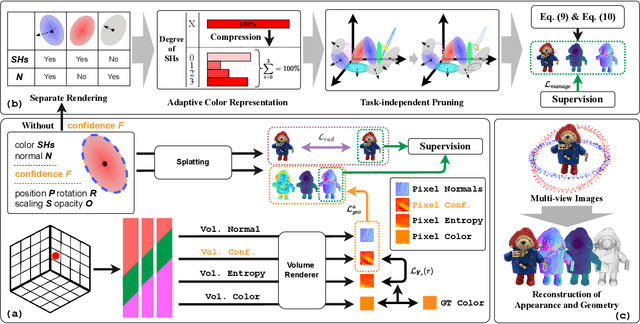
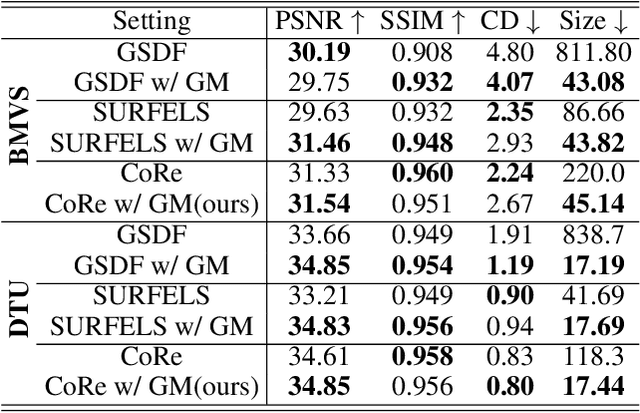
This paper proposes an effective Gaussian management approach for high-fidelity object reconstruction. Departing from recent Gaussian Splatting (GS) methods that employ indiscriminate attribute assignment, our approach introduces a novel densification strategy that dynamically activates spherical harmonics (SHs) or normals under the supervision of a surface reconstruction module, which effectively mitigates the gradient conflicts caused by dual supervision and achieves superior reconstruction results. To further improve representation efficiency, we develop a lightweight Gaussian representation that adaptively adjusts the SH orders of each Gaussian based on gradient magnitudes and performs task-decoupled pruning to remove Gaussian with minimal impact on a reconstruction task without sacrificing others, which balances the representational capacity with parameter quantity. Notably, our management approach is model-agnostic and can be seamlessly integrated into other frameworks, enhancing performance while reducing model size. Extensive experiments demonstrate that our approach consistently outperforms state-of-the-art approaches in both reconstruction quality and efficiency, achieving superior performance with significantly fewer parameters.
SFormer: SNR-guided Transformer for Underwater Image Enhancement from the Frequency Domain
Aug 26, 2025



Recent learning-based underwater image enhancement (UIE) methods have advanced by incorporating physical priors into deep neural networks, particularly using the signal-to-noise ratio (SNR) prior to reduce wavelength-dependent attenuation. However, spatial domain SNR priors have two limitations: (i) they cannot effectively separate cross-channel interference, and (ii) they provide limited help in amplifying informative structures while suppressing noise. To overcome these, we propose using the SNR prior in the frequency domain, decomposing features into amplitude and phase spectra for better channel modulation. We introduce the Fourier Attention SNR-prior Transformer (FAST), combining spectral interactions with SNR cues to highlight key spectral components. Additionally, the Frequency Adaptive Transformer (FAT) bottleneck merges low- and high-frequency branches using a gated attention mechanism to enhance perceptual quality. Embedded in a unified U-shaped architecture, these modules integrate a conventional RGB stream with an SNR-guided branch, forming SFormer. Trained on 4,800 paired images from UIEB, EUVP, and LSUI, SFormer surpasses recent methods with a 3.1 dB gain in PSNR and 0.08 in SSIM, successfully restoring colors, textures, and contrast in underwater scenes.
CMAMRNet: A Contextual Mask-Aware Network Enhancing Mural Restoration Through Comprehensive Mask Guidance
Aug 10, 2025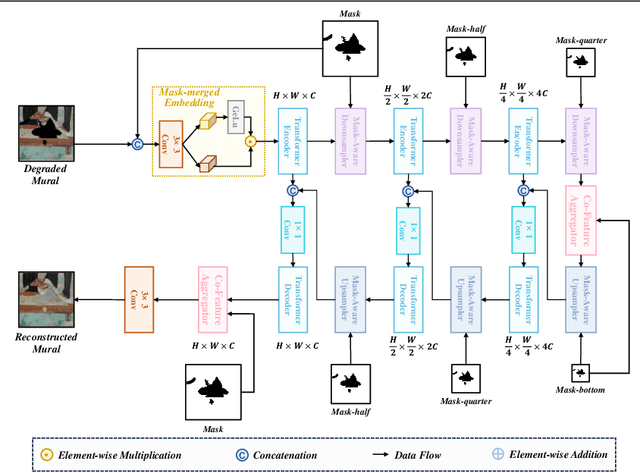
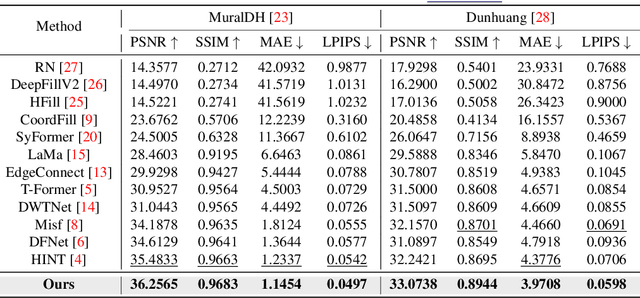
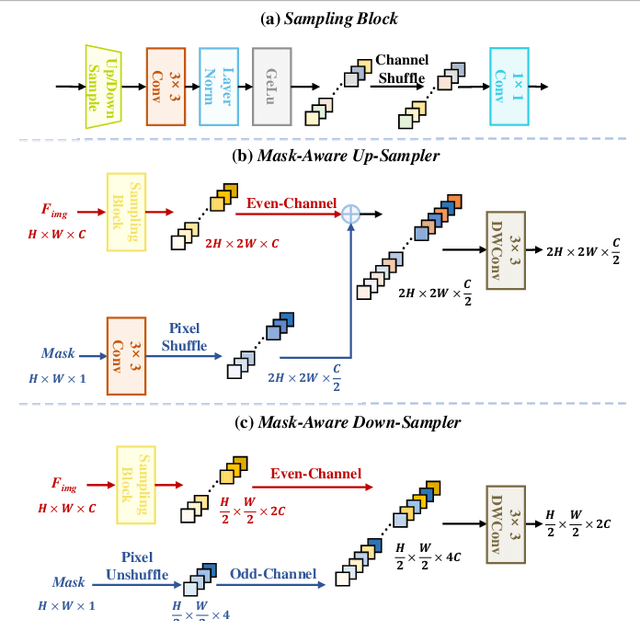
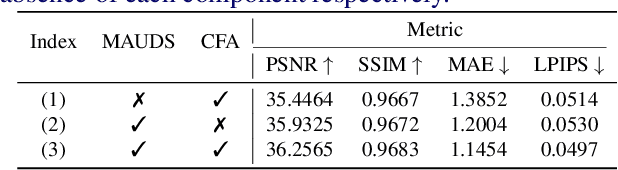
Murals, as invaluable cultural artifacts, face continuous deterioration from environmental factors and human activities. Digital restoration of murals faces unique challenges due to their complex degradation patterns and the critical need to preserve artistic authenticity. Existing learning-based methods struggle with maintaining consistent mask guidance throughout their networks, leading to insufficient focus on damaged regions and compromised restoration quality. We propose CMAMRNet, a Contextual Mask-Aware Mural Restoration Network that addresses these limitations through comprehensive mask guidance and multi-scale feature extraction. Our framework introduces two key components: (1) the Mask-Aware Up/Down-Sampler (MAUDS), which ensures consistent mask sensitivity across resolution scales through dedicated channel-wise feature selection and mask-guided feature fusion; and (2) the Co-Feature Aggregator (CFA), operating at both the highest and lowest resolutions to extract complementary features for capturing fine textures and global structures in degraded regions. Experimental results on benchmark datasets demonstrate that CMAMRNet outperforms state-of-the-art methods, effectively preserving both structural integrity and artistic details in restored murals. The code is available at~\href{https://github.com/CXH-Research/CMAMRNet}{https://github.com/CXH-Research/CMAMRNet}.
Efficient Prototype Consistency Learning in Medical Image Segmentation via Joint Uncertainty and Data Augmentation
May 22, 2025Recently, prototype learning has emerged in semi-supervised medical image segmentation and achieved remarkable performance. However, the scarcity of labeled data limits the expressiveness of prototypes in previous methods, potentially hindering the complete representation of prototypes for class embedding. To overcome this issue, we propose an efficient prototype consistency learning via joint uncertainty quantification and data augmentation (EPCL-JUDA) to enhance the semantic expression of prototypes based on the framework of Mean-Teacher. The concatenation of original and augmented labeled data is fed into student network to generate expressive prototypes. Then, a joint uncertainty quantification method is devised to optimize pseudo-labels and generate reliable prototypes for original and augmented unlabeled data separately. High-quality global prototypes for each class are formed by fusing labeled and unlabeled prototypes, which are utilized to generate prototype-to-features to conduct consistency learning. Notably, a prototype network is proposed to reduce high memory requirements brought by the introduction of augmented data. Extensive experiments on Left Atrium, Pancreas-NIH, Type B Aortic Dissection datasets demonstrate EPCL-JUDA's superiority over previous state-of-the-art approaches, confirming the effectiveness of our framework. The code will be released soon.
Mutual Evidential Deep Learning for Medical Image Segmentation
May 18, 2025Existing semi-supervised medical segmentation co-learning frameworks have realized that model performance can be diminished by the biases in model recognition caused by low-quality pseudo-labels. Due to the averaging nature of their pseudo-label integration strategy, they fail to explore the reliability of pseudo-labels from different sources. In this paper, we propose a mutual evidential deep learning (MEDL) framework that offers a potentially viable solution for pseudo-label generation in semi-supervised learning from two perspectives. First, we introduce networks with different architectures to generate complementary evidence for unlabeled samples and adopt an improved class-aware evidential fusion to guide the confident synthesis of evidential predictions sourced from diverse architectural networks. Second, utilizing the uncertainty in the fused evidence, we design an asymptotic Fisher information-based evidential learning strategy. This strategy enables the model to initially focus on unlabeled samples with more reliable pseudo-labels, gradually shifting attention to samples with lower-quality pseudo-labels while avoiding over-penalization of mislabeled classes in high data uncertainty samples. Additionally, for labeled data, we continue to adopt an uncertainty-driven asymptotic learning strategy, gradually guiding the model to focus on challenging voxels. Extensive experiments on five mainstream datasets have demonstrated that MEDL achieves state-of-the-art performance.