 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRequirements Framework for Engineering Human-centered Artificial Intelligence-Based Software Systems
Mar 06, 2023



[Context] Artificial intelligence (AI) components used in building software solutions have substantially increased in recent years. However, many of these solutions end up focusing on technical aspects and ignore critical human-centered aspects. [Objective] Including human-centered aspects during requirements engineering (RE) when building AI-based software can help achieve more responsible, unbiased, and inclusive AI-based software solutions. [Method] In this paper, we present a new framework developed based on human-centered AI guidelines and a user survey to aid in collecting requirements for human-centered AI-based software. We provide a catalog to elicit these requirements and a conceptual model to present them visually. [Results] The framework is applied to a case study to elicit and model requirements for enhancing the quality of 360 degree~videos intended for virtual reality (VR) users. [Conclusion] We found that our proposed approach helped the project team fully understand the needs of the project to deliver. Furthermore, the framework helped to understand what requirements need to be captured at the initial stages against later stages in the engineering process of AI-based software.
From Forks to Forceps: A New Framework for Instance Segmentation of Surgical Instruments
Nov 26, 2022



Minimally invasive surgeries and related applications demand surgical tool classification and segmentation at the instance level. Surgical tools are similar in appearance and are long, thin, and handled at an angle. The fine-tuning of state-of-the-art (SOTA) instance segmentation models trained on natural images for instrument segmentation has difficulty discriminating instrument classes. Our research demonstrates that while the bounding box and segmentation mask are often accurate, the classification head mis-classifies the class label of the surgical instrument. We present a new neural network framework that adds a classification module as a new stage to existing instance segmentation models. This module specializes in improving the classification of instrument masks generated by the existing model. The module comprises multi-scale mask attention, which attends to the instrument region and masks the distracting background features. We propose training our classifier module using metric learning with arc loss to handle low inter-class variance of surgical instruments. We conduct exhaustive experiments on the benchmark datasets EndoVis2017 and EndoVis2018. We demonstrate that our method outperforms all (more than 18) SOTA methods compared with, and improves the SOTA performance by at least 12 points (20%) on the EndoVis2017 benchmark challenge and generalizes effectively across the datasets.
RadFormer: Transformers with Global-Local Attention for Interpretable and Accurate Gallbladder Cancer Detection
Nov 09, 2022



We propose a novel deep neural network architecture to learn interpretable representation for medical image analysis. Our architecture generates a global attention for region of interest, and then learns bag of words style deep feature embeddings with local attention. The global, and local feature maps are combined using a contemporary transformer architecture for highly accurate Gallbladder Cancer (GBC) detection from Ultrasound (USG) images. Our experiments indicate that the detection accuracy of our model beats even human radiologists, and advocates its use as the second reader for GBC diagnosis. Bag of words embeddings allow our model to be probed for generating interpretable explanations for GBC detection consistent with the ones reported in medical literature. We show that the proposed model not only helps understand decisions of neural network models but also aids in discovery of new visual features relevant to the diagnosis of GBC. Source-code and model will be available at https://github.com/sbasu276/RadFormer
Attention Attention Everywhere: Monocular Depth Prediction with Skip Attention
Oct 17, 2022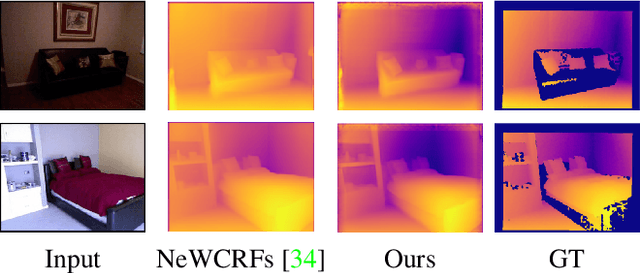
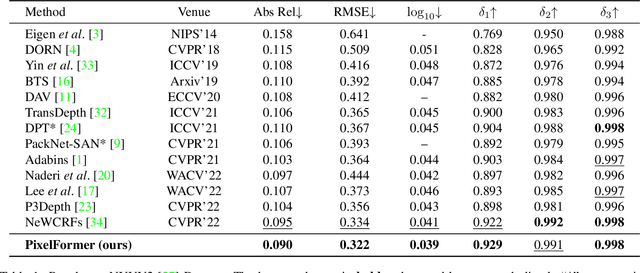
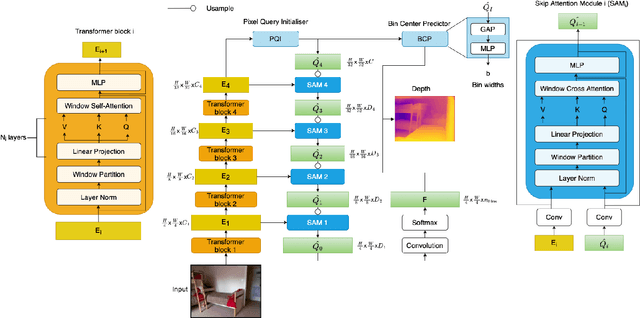
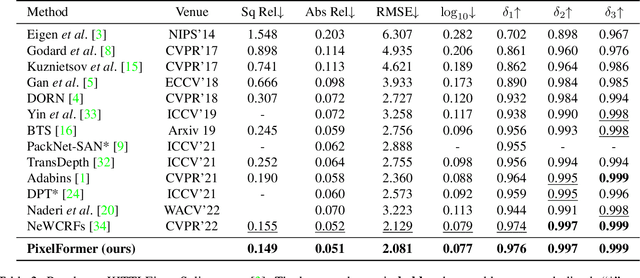
Monocular Depth Estimation (MDE) aims to predict pixel-wise depth given a single RGB image. For both, the convolutional as well as the recent attention-based models, encoder-decoder-based architectures have been found to be useful due to the simultaneous requirement of global context and pixel-level resolution. Typically, a skip connection module is used to fuse the encoder and decoder features, which comprises of feature map concatenation followed by a convolution operation. Inspired by the demonstrated benefits of attention in a multitude of computer vision problems, we propose an attention-based fusion of encoder and decoder features. We pose MDE as a pixel query refinement problem, where coarsest-level encoder features are used to initialize pixel-level queries, which are then refined to higher resolutions by the proposed Skip Attention Module (SAM). We formulate the prediction problem as ordinal regression over the bin centers that discretize the continuous depth range and introduce a Bin Center Predictor (BCP) module that predicts bins at the coarsest level using pixel queries. Apart from the benefit of image adaptive depth binning, the proposed design helps learn improved depth embedding in initial pixel queries via direct supervision from the ground truth. Extensive experiments on the two canonical datasets, NYUV2 and KITTI, show that our architecture outperforms the state-of-the-art by 5.3% and 3.9%, respectively, along with an improved generalization performance by 9.4% on the SUNRGBD dataset. Code is available at https://github.com/ashutosh1807/PixelFormer.git.
Reducing Annotation Effort by Identifying and Labeling Contextually Diverse Classes for Semantic Segmentation Under Domain Shift
Oct 13, 2022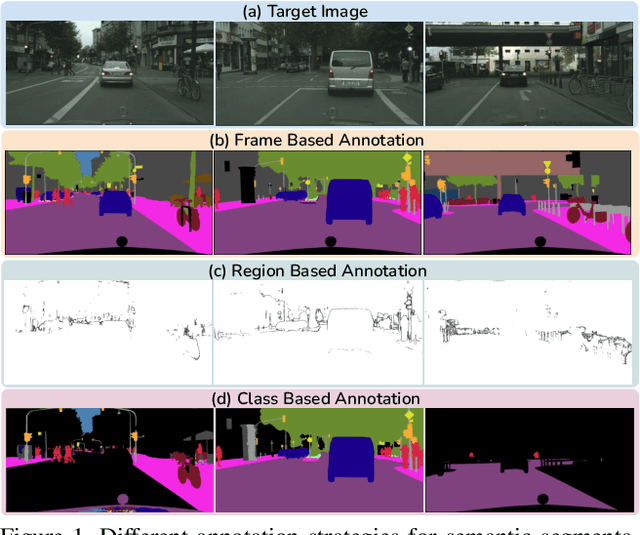
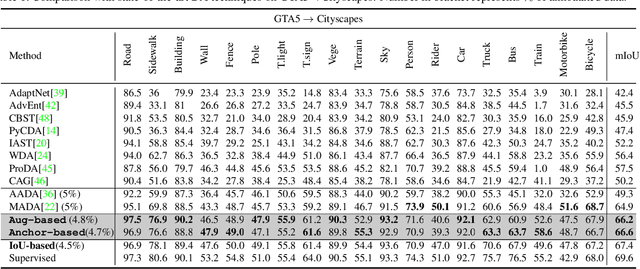
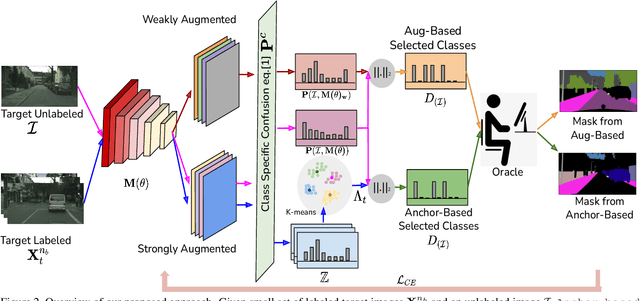
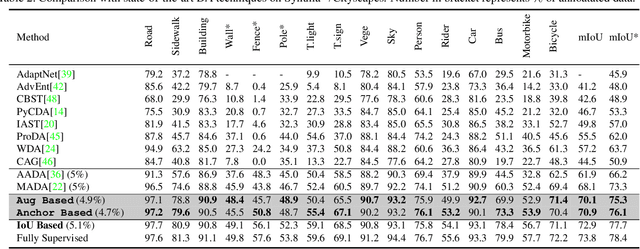
In Active Domain Adaptation (ADA), one uses Active Learning (AL) to select a subset of images from the target domain, which are then annotated and used for supervised domain adaptation (DA). Given the large performance gap between supervised and unsupervised DA techniques, ADA allows for an excellent trade-off between annotation cost and performance. Prior art makes use of measures of uncertainty or disagreement of models to identify `regions' to be annotated by the human oracle. However, these regions frequently comprise of pixels at object boundaries which are hard and tedious to annotate. Hence, even if the fraction of image pixels annotated reduces, the overall annotation time and the resulting cost still remain high. In this work, we propose an ADA strategy, which given a frame, identifies a set of classes that are hardest for the model to predict accurately, thereby recommending semantically meaningful regions to be annotated in a selected frame. We show that these set of `hard' classes are context-dependent and typically vary across frames, and when annotated help the model generalize better. We propose two ADA techniques: the Anchor-based and Augmentation-based approaches to select complementary and diverse regions in the context of the current training set. Our approach achieves 66.6 mIoU on GTA to Cityscapes dataset with an annotation budget of 4.7% in comparison to 64.9 mIoU by MADA using 5% of annotations. Our technique can also be used as a decorator for any existing frame-based AL technique, e.g., we report 1.5% performance improvement for CDAL on Cityscapes using our approach.
A Novel Data Augmentation Technique for Out-of-Distribution Sample Detection using Compounded Corruptions
Jul 28, 2022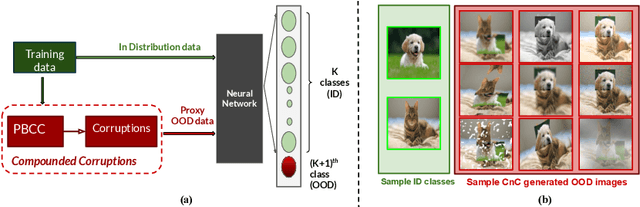
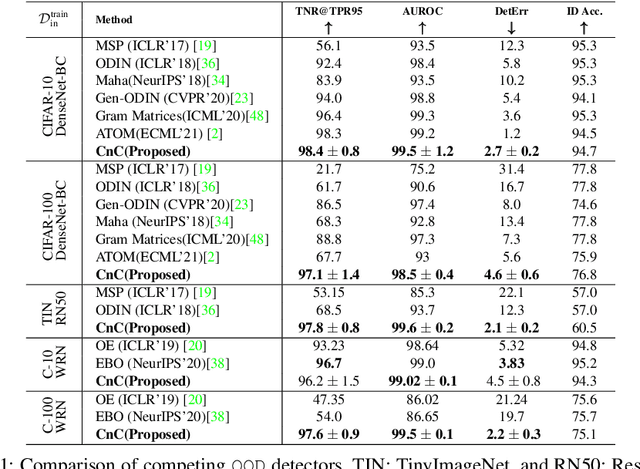
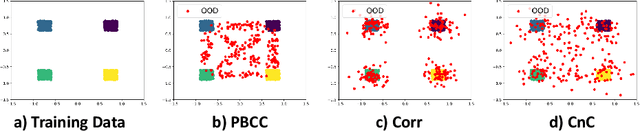
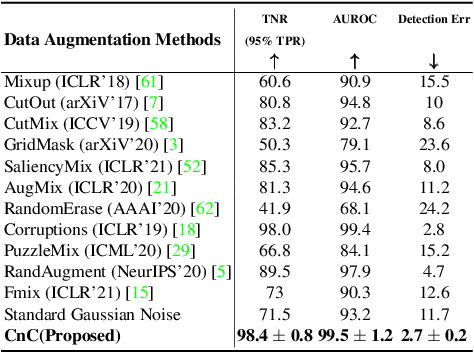
Modern deep neural network models are known to erroneously classify out-of-distribution (OOD) test data into one of the in-distribution (ID) training classes with high confidence. This can have disastrous consequences for safety-critical applications. A popular mitigation strategy is to train a separate classifier that can detect such OOD samples at the test time. In most practical settings OOD examples are not known at the train time, and hence a key question is: how to augment the ID data with synthetic OOD samples for training such an OOD detector? In this paper, we propose a novel Compounded Corruption technique for the OOD data augmentation termed CnC. One of the major advantages of CnC is that it does not require any hold-out data apart from the training set. Further, unlike current state-of-the-art (SOTA) techniques, CnC does not require backpropagation or ensembling at the test time, making our method much faster at inference. Our extensive comparison with 20 methods from the major conferences in last 4 years show that a model trained using CnC based data augmentation, significantly outperforms SOTA, both in terms of OOD detection accuracy as well as inference time. We include a detailed post-hoc analysis to investigate the reasons for the success of our method and identify higher relative entropy and diversity of CnC samples as probable causes. We also provide theoretical insights via a piece-wise decomposition analysis on a two-dimensional dataset to reveal (visually and quantitatively) that our approach leads to a tighter boundary around ID classes, leading to better detection of OOD samples. Source code link: https://github.com/cnc-ood
Unsupervised Contrastive Learning of Image Representations from Ultrasound Videos with Hard Negative Mining
Jul 26, 2022
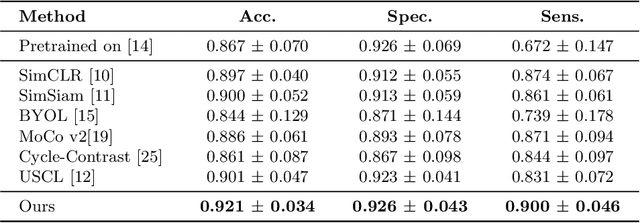
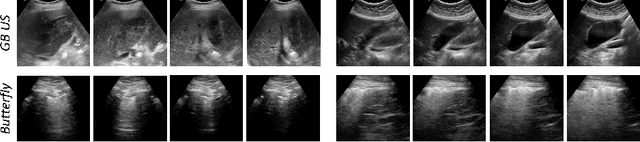
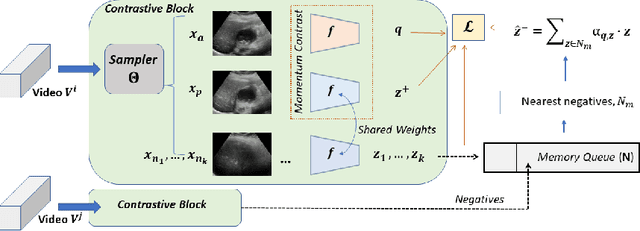
Rich temporal information and variations in viewpoints make video data an attractive choice for learning image representations using unsupervised contrastive learning (UCL) techniques. State-of-the-art (SOTA) contrastive learning techniques consider frames within a video as positives in the embedding space, whereas the frames from other videos are considered negatives. We observe that unlike multiple views of an object in natural scene videos, an Ultrasound (US) video captures different 2D slices of an organ. Hence, there is almost no similarity between the temporally distant frames of even the same US video. In this paper we propose to instead utilize such frames as hard negatives. We advocate mining both intra-video and cross-video negatives in a hardness-sensitive negative mining curriculum in a UCL framework to learn rich image representations. We deploy our framework to learn the representations of Gallbladder (GB) malignancy from US videos. We also construct the first large-scale US video dataset containing 64 videos and 15,800 frames for learning GB representations. We show that the standard ResNet50 backbone trained with our framework improves the accuracy of models pretrained with SOTA UCL techniques as well as supervised pretrained models on ImageNet for the GB malignancy detection task by 2-6%. We further validate the generalizability of our method on a publicly available lung US image dataset of COVID-19 pathologies and show an improvement of 1.5% compared to SOTA. Source code, dataset, and models are available at https://gbc-iitd.github.io/usucl.
My View is the Best View: Procedure Learning from Egocentric Videos
Jul 22, 2022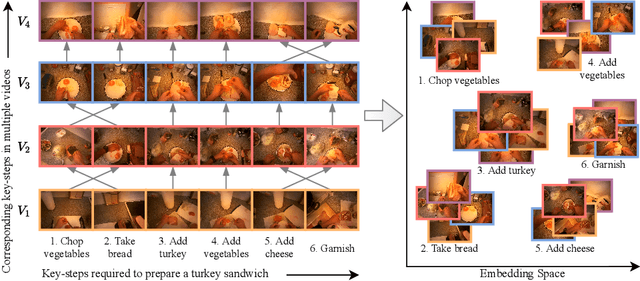


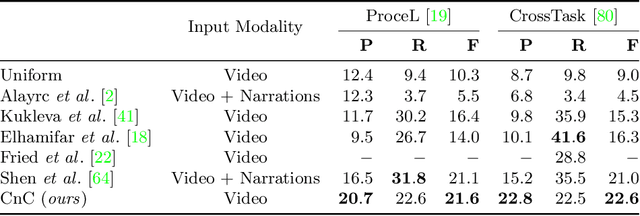
Procedure learning involves identifying the key-steps and determining their logical order to perform a task. Existing approaches commonly use third-person videos for learning the procedure, making the manipulated object small in appearance and often occluded by the actor, leading to significant errors. In contrast, we observe that videos obtained from first-person (egocentric) wearable cameras provide an unobstructed and clear view of the action. However, procedure learning from egocentric videos is challenging because (a) the camera view undergoes extreme changes due to the wearer's head motion, and (b) the presence of unrelated frames due to the unconstrained nature of the videos. Due to this, current state-of-the-art methods' assumptions that the actions occur at approximately the same time and are of the same duration, do not hold. Instead, we propose to use the signal provided by the temporal correspondences between key-steps across videos. To this end, we present a novel self-supervised Correspond and Cut (CnC) framework for procedure learning. CnC identifies and utilizes the temporal correspondences between the key-steps across multiple videos to learn the procedure. Our experiments show that CnC outperforms the state-of-the-art on the benchmark ProceL and CrossTask datasets by 5.2% and 6.3%, respectively. Furthermore, for procedure learning using egocentric videos, we propose the EgoProceL dataset consisting of 62 hours of videos captured by 130 subjects performing 16 tasks. The source code and the dataset are available on the project page https://sid2697.github.io/egoprocel/.
Depthformer : Multiscale Vision Transformer For Monocular Depth Estimation With Local Global Information Fusion
Jul 12, 2022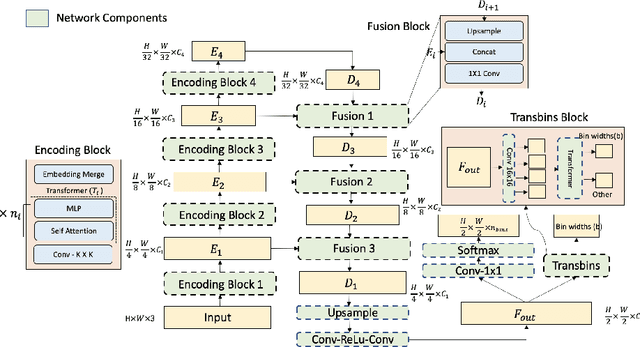
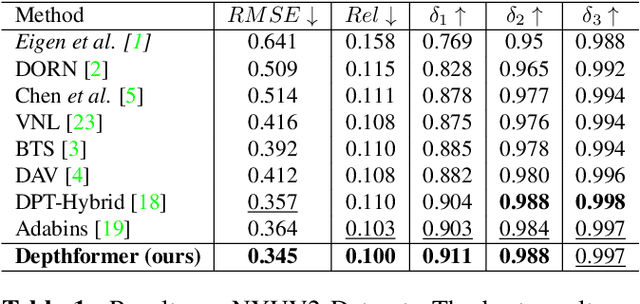

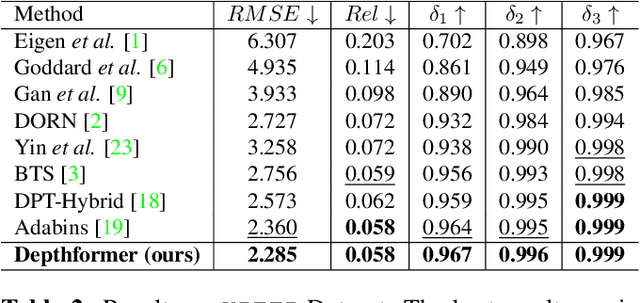
Attention-based models such as transformers have shown outstanding performance on dense prediction tasks, such as semantic segmentation, owing to their capability of capturing long-range dependency in an image. However, the benefit of transformers for monocular depth prediction has seldom been explored so far. This paper benchmarks various transformer-based models for the depth estimation task on an indoor NYUV2 dataset and an outdoor KITTI dataset. We propose a novel attention-based architecture, Depthformer for monocular depth estimation that uses multi-head self-attention to produce the multiscale feature maps, which are effectively combined by our proposed decoder network. We also propose a Transbins module that divides the depth range into bins whose center value is estimated adaptively per image. The final depth estimated is a linear combination of bin centers for each pixel. Transbins module takes advantage of the global receptive field using the transformer module in the encoding stage. Experimental results on NYUV2 and KITTI depth estimation benchmark demonstrate that our proposed method improves the state-of-the-art by 3.3%, and 3.3% respectively in terms of Root Mean Squared Error (RMSE). Code is available at https://github.com/ashutosh1807/Depthformer.git.
TAPHSIR: Towards AnaPHoric Ambiguity Detection and ReSolution In Requirements
Jun 21, 2022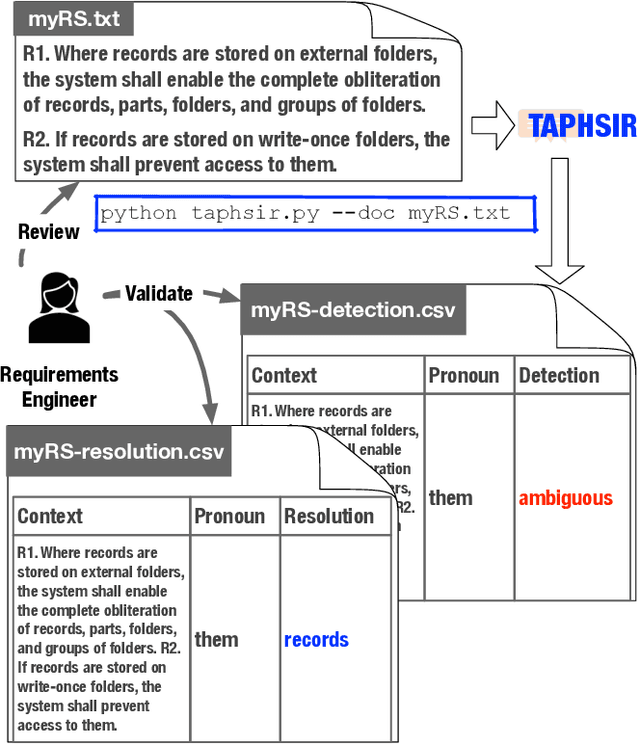
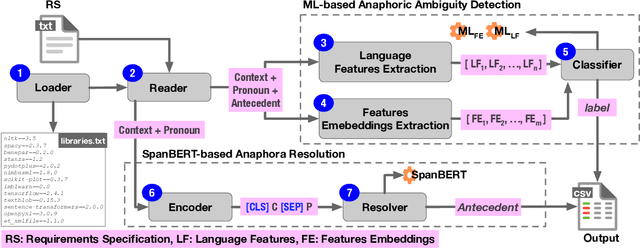
We introduce TAPHSIR, a tool for anaphoric ambiguity detection and anaphora resolution in requirements. TAPHSIR facilities reviewing the use of pronouns in a requirements specification and revising those pronouns that can lead to misunderstandings during the development process. To this end, TAPHSIR detects the requirements which have potential anaphoric ambiguity and further attempts interpreting anaphora occurrences automatically. TAPHSIR employs a hybrid solution composed of an ambiguity detection solution based on machine learning and an anaphora resolution solution based on a variant of the BERT language model. Given a requirements specification, TAPHSIR decides for each pronoun occurrence in the specification whether the pronoun is ambiguous or unambiguous, and further provides an automatic interpretation for the pronoun. The output generated by TAPHSIR can be easily reviewed and validated by requirements engineers. TAPHSIR is publicly available on Zenodo (DOI: 10.5281/zenodo.5902117).