 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring the Limitations of Graph Reasoning in Large Language Models
Feb 02, 2024



Pretrained Large Language Models have demonstrated various types of reasoning capabilities through language-based prompts alone. However, in this paper, we test the depth of graph reasoning for 5 different LLMs (GPT-4, GPT-3.5, Claude-2, Llama-2 and Palm-2) through the problems of graph reasoning. In particular, we design 10 distinct problems of graph traversal, each representing increasing levels of complexity. Further, we analyze the performance of models across various settings such as varying sizes of graphs as well as different forms of k-shot prompting. We highlight various limitations, biases, and properties of LLMs through this benchmarking process, such as an inverse relation to the average degrees of freedom of traversal per node in graphs, the overall negative impact of k-shot prompting on graph reasoning tasks, and a positive response bias which prevents LLMs from identifying the absence of a valid solution. Finally, we propose a new prompting technique specially designed for graph traversal tasks, known as PathCompare, which shows a notable increase in the performance of LLMs in comparison to standard prompting and CoT.
Advancing Perception in Artificial Intelligence through Principles of Cognitive Science
Oct 13, 2023Although artificial intelligence (AI) has achieved many feats at a rapid pace, there still exist open problems and fundamental shortcomings related to performance and resource efficiency. Since AI researchers benchmark a significant proportion of performance standards through human intelligence, cognitive sciences-inspired AI is a promising domain of research. Studying cognitive science can provide a fresh perspective to building fundamental blocks in AI research, which can lead to improved performance and efficiency. In this review paper, we focus on the cognitive functions of perception, which is the process of taking signals from one's surroundings as input, and processing them to understand the environment. Particularly, we study and compare its various processes through the lens of both cognitive sciences and AI. Through this study, we review all current major theories from various sub-disciplines of cognitive science (specifically neuroscience, psychology and linguistics), and draw parallels with theories and techniques from current practices in AI. We, hence, present a detailed collection of methods in AI for researchers to build AI systems inspired by cognitive science. Further, through the process of reviewing the state of cognitive-inspired AI, we point out many gaps in the current state of AI (with respect to the performance of the human brain), and hence present potential directions for researchers to develop better perception systems in AI.
STUPD: A Synthetic Dataset for Spatial and Temporal Relation Reasoning
Sep 13, 2023Understanding relations between objects is crucial for understanding the semantics of a visual scene. It is also an essential step in order to bridge visual and language models. However, current state-of-the-art computer vision models still lack the ability to perform spatial reasoning well. Existing datasets mostly cover a relatively small number of spatial relations, all of which are static relations that do not intrinsically involve motion. In this paper, we propose the Spatial and Temporal Understanding of Prepositions Dataset (STUPD) -- a large-scale video dataset for understanding static and dynamic spatial relationships derived from prepositions of the English language. The dataset contains 150K visual depictions (videos and images), consisting of 30 distinct spatial prepositional senses, in the form of object interaction simulations generated synthetically using Unity3D. In addition to spatial relations, we also propose 50K visual depictions across 10 temporal relations, consisting of videos depicting event/time-point interactions. To our knowledge, no dataset exists that represents temporal relations through visual settings. In this dataset, we also provide 3D information about object interactions such as frame-wise coordinates, and descriptions of the objects used. The goal of this synthetic dataset is to help models perform better in visual relationship detection in real-world settings. We demonstrate an increase in the performance of various models over 2 real-world datasets (ImageNet-VidVRD and Spatial Senses) when pretrained on the STUPD dataset, in comparison to other pretraining datasets.
Compositional Learning of Visually-Grounded Concepts Using Reinforcement
Sep 08, 2023



Deep reinforcement learning agents need to be trained over millions of episodes to decently solve navigation tasks grounded to instructions. Furthermore, their ability to generalize to novel combinations of instructions is unclear. Interestingly however, children can decompose language-based instructions and navigate to the referred object, even if they have not seen the combination of queries prior. Hence, we created three 3D environments to investigate how deep RL agents learn and compose color-shape based combinatorial instructions to solve novel combinations in a spatial navigation task. First, we explore if agents can perform compositional learning, and whether they can leverage on frozen text encoders (e.g. CLIP, BERT) to learn word combinations in fewer episodes. Next, we demonstrate that when agents are pretrained on the shape or color concepts separately, they show a 20 times decrease in training episodes needed to solve unseen combinations of instructions. Lastly, we show that agents pretrained on concept and compositional learning achieve significantly higher reward when evaluated zero-shot on novel color-shape1-shape2 visual object combinations. Overall, our results highlight the foundations needed to increase an agent's proficiency in composing word groups through reinforcement learning and its ability for zero-shot generalization to new combinations.
DetermiNet: A Large-Scale Diagnostic Dataset for Complex Visually-Grounded Referencing using Determiners
Sep 07, 2023



State-of-the-art visual grounding models can achieve high detection accuracy, but they are not designed to distinguish between all objects versus only certain objects of interest. In natural language, in order to specify a particular object or set of objects of interest, humans use determiners such as "my", "either" and "those". Determiners, as an important word class, are a type of schema in natural language about the reference or quantity of the noun. Existing grounded referencing datasets place much less emphasis on determiners, compared to other word classes such as nouns, verbs and adjectives. This makes it difficult to develop models that understand the full variety and complexity of object referencing. Thus, we have developed and released the DetermiNet dataset , which comprises 250,000 synthetically generated images and captions based on 25 determiners. The task is to predict bounding boxes to identify objects of interest, constrained by the semantics of the given determiner. We find that current state-of-the-art visual grounding models do not perform well on the dataset, highlighting the limitations of existing models on reference and quantification tasks.
Revealing the Illusion of Joint Multimodal Understanding in VideoQA Models
Jun 15, 2023



While VideoQA Transformer models demonstrate competitive performance on standard benchmarks, the reasons behind their success remain unclear. Do these models jointly capture and leverage the rich multimodal structures and dynamics from video and text? Or are they merely exploiting shortcuts to achieve high scores? We analyze this with $\textit{QUAG}$ (QUadrant AveraGe), a lightweight and non-parametric probe that systematically ablates the model's coupled multimodal understanding during inference. Surprisingly, QUAG reveals that the models manage to maintain high performance even when injected with multimodal sub-optimality. Additionally, even after replacing self-attention in multimodal fusion blocks with "QUAG-attention", a simplistic and less-expressive variant of self-attention, the models maintain high performance. This means that current VideoQA benchmarks and their metrics do not penalize shortcuts that discount joint multimodal understanding. Motivated by this, we propose the $\textit{CLAVI}$ (Counterfactual in LAnguage and VIdeo) benchmark, a diagnostic dataset for benchmarking coupled multimodal understanding in VideoQA through counterfactuals. CLAVI consists of temporal questions and videos that are augmented to curate balanced counterfactuals in language and video domains. Hence, it incentivizes, and identifies the reliability of learnt multimodal representations. We evaluate CLAVI and find that models achieve high performance on multimodal shortcut instances, but have very poor performance on the counterfactuals. Hence, we position CLAVI as a litmus test to identify, diagnose and improve the sub-optimality of learnt multimodal VideoQA representations which the current benchmarks are unable to assess.
FedHQL: Federated Heterogeneous Q-Learning
Jan 26, 2023Federated Reinforcement Learning (FedRL) encourages distributed agents to learn collectively from each other's experience to improve their performance without exchanging their raw trajectories. The existing work on FedRL assumes that all participating agents are homogeneous, which requires all agents to share the same policy parameterization (e.g., network architectures and training configurations). However, in real-world applications, agents are often in disagreement about the architecture and the parameters, possibly also because of disparate computational budgets. Because homogeneity is not given in practice, we introduce the problem setting of Federated Reinforcement Learning with Heterogeneous And bLack-box agEnts (FedRL-HALE). We present the unique challenges this new setting poses and propose the Federated Heterogeneous Q-Learning (FedHQL) algorithm that principally addresses these challenges. We empirically demonstrate the efficacy of FedHQL in boosting the sample efficiency of heterogeneous agents with distinct policy parameterization using standard RL tasks.
Abductive Action Inference
Oct 24, 2022



Abductive reasoning aims to make the most likely inference for a given set of incomplete observations. In this work, given a situation or a scenario, we aim to answer the question 'what is the set of actions that were executed by the human in order to come to this current state?', which we coin as abductive action inference. We provide a solution based on the human-object relations and their states in the given scene. Specifically, we first detect objects and humans in the scene, and then generate representations for each human-centric relation. Using these human-centric relations, we derive the most likely set of actions the human may have executed to arrive in this state. To generate human-centric relational representations, we investigate several models such as Transformers, a novel graph neural network-based encoder-decoder, and a new relational bilinear pooling method. We obtain promising results using these new models on this challenging task on the Action Genome dataset.
BOSS: A Benchmark for Human Belief Prediction in Object-context Scenarios
Jun 21, 2022

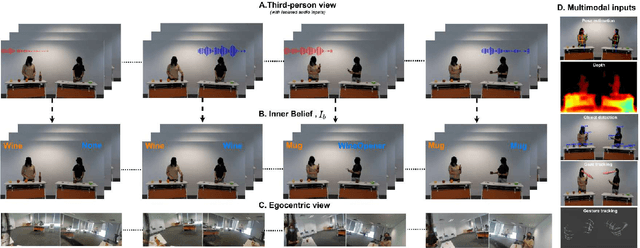

Humans with an average level of social cognition can infer the beliefs of others based solely on the nonverbal communication signals (e.g. gaze, gesture, pose and contextual information) exhibited during social interactions. This social cognitive ability to predict human beliefs and intentions is more important than ever for ensuring safe human-robot interaction and collaboration. This paper uses the combined knowledge of Theory of Mind (ToM) and Object-Context Relations to investigate methods for enhancing collaboration between humans and autonomous systems in environments where verbal communication is prohibited. We propose a novel and challenging multimodal video dataset for assessing the capability of artificial intelligence (AI) systems in predicting human belief states in an object-context scenario. The proposed dataset consists of precise labelling of human belief state ground-truth and multimodal inputs replicating all nonverbal communication inputs captured by human perception. We further evaluate our dataset with existing deep learning models and provide new insights into the effects of the various input modalities and object-context relations on the performance of the baseline models.
Good Time to Ask: A Learning Framework for Asking for Help in Embodied Visual Navigation
Jun 20, 2022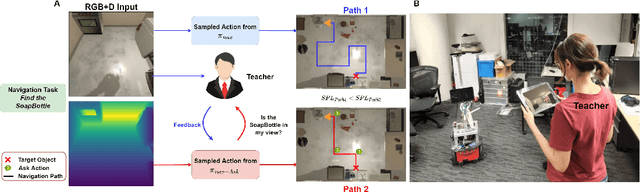
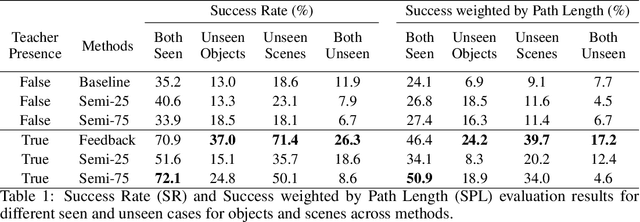
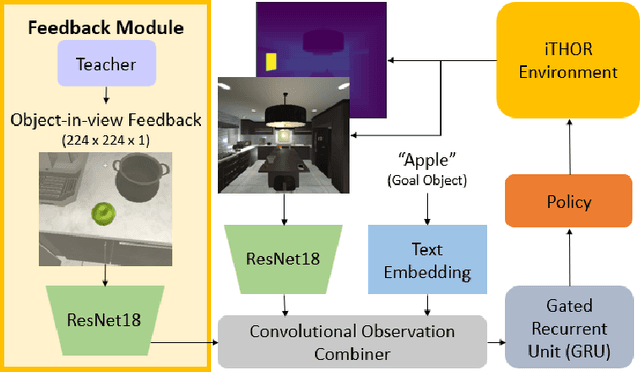
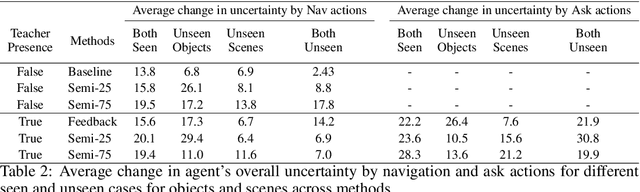
In reality, it is often more efficient to ask for help than to search the entire space to find an object with an unknown location. We present a learning framework that enables an agent to actively ask for help in such embodied visual navigation tasks, where the feedback informs the agent of where the goal is in its view. To emulate the real-world scenario that a teacher may not always be present, we propose a training curriculum where feedback is not always available. We formulate an uncertainty measure of where the goal is and use empirical results to show that through this approach, the agent learns to ask for help effectively while remaining robust when feedback is not available.