 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIterative Refinement Improves Compositional Image Generation
Jan 21, 2026Text-to-image (T2I) models have achieved remarkable progress, yet they continue to struggle with complex prompts that require simultaneously handling multiple objects, relations, and attributes. Existing inference-time strategies, such as parallel sampling with verifiers or simply increasing denoising steps, can improve prompt alignment but remain inadequate for richly compositional settings where many constraints must be satisfied. Inspired by the success of chain-of-thought reasoning in large language models, we propose an iterative test-time strategy in which a T2I model progressively refines its generations across multiple steps, guided by feedback from a vision-language model as the critic in the loop. Our approach is simple, requires no external tools or priors, and can be flexibly applied to a wide range of image generators and vision-language models. Empirically, we demonstrate consistent gains on image generation across benchmarks: a 16.9% improvement in all-correct rate on ConceptMix (k=7), a 13.8% improvement on T2I-CompBench (3D-Spatial category) and a 12.5% improvement on Visual Jenga scene decomposition compared to compute-matched parallel sampling. Beyond quantitative gains, iterative refinement produces more faithful generations by decomposing complex prompts into sequential corrections, with human evaluators preferring our method 58.7% of the time over 41.3% for the parallel baseline. Together, these findings highlight iterative self-correction as a broadly applicable principle for compositional image generation. Results and visualizations are available at https://iterative-img-gen.github.io/
Can LLMs Lie? Investigation beyond Hallucination
Sep 03, 2025Large language models (LLMs) have demonstrated impressive capabilities across a variety of tasks, but their increasing autonomy in real-world applications raises concerns about their trustworthiness. While hallucinations-unintentional falsehoods-have been widely studied, the phenomenon of lying, where an LLM knowingly generates falsehoods to achieve an ulterior objective, remains underexplored. In this work, we systematically investigate the lying behavior of LLMs, differentiating it from hallucinations and testing it in practical scenarios. Through mechanistic interpretability techniques, we uncover the neural mechanisms underlying deception, employing logit lens analysis, causal interventions, and contrastive activation steering to identify and control deceptive behavior. We study real-world lying scenarios and introduce behavioral steering vectors that enable fine-grained manipulation of lying tendencies. Further, we explore the trade-offs between lying and end-task performance, establishing a Pareto frontier where dishonesty can enhance goal optimization. Our findings contribute to the broader discourse on AI ethics, shedding light on the risks and potential safeguards for deploying LLMs in high-stakes environments. Code and more illustrations are available at https://llm-liar.github.io/
Learning to Reason Iteratively and Parallelly for Complex Visual Reasoning Scenarios
Nov 20, 2024Complex visual reasoning and question answering (VQA) is a challenging task that requires compositional multi-step processing and higher-level reasoning capabilities beyond the immediate recognition and localization of objects and events. Here, we introduce a fully neural Iterative and Parallel Reasoning Mechanism (IPRM) that combines two distinct forms of computation -- iterative and parallel -- to better address complex VQA scenarios. Specifically, IPRM's "iterative" computation facilitates compositional step-by-step reasoning for scenarios wherein individual operations need to be computed, stored, and recalled dynamically (e.g. when computing the query "determine the color of pen to the left of the child in red t-shirt sitting at the white table"). Meanwhile, its "parallel" computation allows for the simultaneous exploration of different reasoning paths and benefits more robust and efficient execution of operations that are mutually independent (e.g. when counting individual colors for the query: "determine the maximum occurring color amongst all t-shirts"). We design IPRM as a lightweight and fully-differentiable neural module that can be conveniently applied to both transformer and non-transformer vision-language backbones. It notably outperforms prior task-specific methods and transformer-based attention modules across various image and video VQA benchmarks testing distinct complex reasoning capabilities such as compositional spatiotemporal reasoning (AGQA), situational reasoning (STAR), multi-hop reasoning generalization (CLEVR-Humans) and causal event linking (CLEVRER-Humans). Further, IPRM's internal computations can be visualized across reasoning steps, aiding interpretability and diagnosis of its errors.
Zero-Shot Visual Reasoning by Vision-Language Models: Benchmarking and Analysis
Aug 27, 2024



Vision-language models (VLMs) have shown impressive zero- and few-shot performance on real-world visual question answering (VQA) benchmarks, alluding to their capabilities as visual reasoning engines. However, the benchmarks being used conflate "pure" visual reasoning with world knowledge, and also have questions that involve a limited number of reasoning steps. Thus, it remains unclear whether a VLM's apparent visual reasoning performance is due to its world knowledge, or due to actual visual reasoning capabilities. To clarify this ambiguity, we systematically benchmark and dissect the zero-shot visual reasoning capabilities of VLMs through synthetic datasets that require minimal world knowledge, and allow for analysis over a broad range of reasoning steps. We focus on two novel aspects of zero-shot visual reasoning: i) evaluating the impact of conveying scene information as either visual embeddings or purely textual scene descriptions to the underlying large language model (LLM) of the VLM, and ii) comparing the effectiveness of chain-of-thought prompting to standard prompting for zero-shot visual reasoning. We find that the underlying LLMs, when provided textual scene descriptions, consistently perform better compared to being provided visual embeddings. In particular, 18% higher accuracy is achieved on the PTR dataset. We also find that CoT prompting performs marginally better than standard prompting only for the comparatively large GPT-3.5-Turbo (175B) model, and does worse for smaller-scale models. This suggests the emergence of CoT abilities for visual reasoning in LLMs at larger scales even when world knowledge is limited. Overall, we find limitations in the abilities of VLMs and LLMs for more complex visual reasoning, and highlight the important role that LLMs can play in visual reasoning.
Revealing the Illusion of Joint Multimodal Understanding in VideoQA Models
Jun 15, 2023



While VideoQA Transformer models demonstrate competitive performance on standard benchmarks, the reasons behind their success remain unclear. Do these models jointly capture and leverage the rich multimodal structures and dynamics from video and text? Or are they merely exploiting shortcuts to achieve high scores? We analyze this with $\textit{QUAG}$ (QUadrant AveraGe), a lightweight and non-parametric probe that systematically ablates the model's coupled multimodal understanding during inference. Surprisingly, QUAG reveals that the models manage to maintain high performance even when injected with multimodal sub-optimality. Additionally, even after replacing self-attention in multimodal fusion blocks with "QUAG-attention", a simplistic and less-expressive variant of self-attention, the models maintain high performance. This means that current VideoQA benchmarks and their metrics do not penalize shortcuts that discount joint multimodal understanding. Motivated by this, we propose the $\textit{CLAVI}$ (Counterfactual in LAnguage and VIdeo) benchmark, a diagnostic dataset for benchmarking coupled multimodal understanding in VideoQA through counterfactuals. CLAVI consists of temporal questions and videos that are augmented to curate balanced counterfactuals in language and video domains. Hence, it incentivizes, and identifies the reliability of learnt multimodal representations. We evaluate CLAVI and find that models achieve high performance on multimodal shortcut instances, but have very poor performance on the counterfactuals. Hence, we position CLAVI as a litmus test to identify, diagnose and improve the sub-optimality of learnt multimodal VideoQA representations which the current benchmarks are unable to assess.
A Probabilistic-Logic based Commonsense Representation Framework for Modelling Inferences with Multiple Antecedents and Varying Likelihoods
Dec 15, 2022



Commonsense knowledge-graphs (CKGs) are important resources towards building machines that can 'reason' on text or environmental inputs and make inferences beyond perception. While current CKGs encode world knowledge for a large number of concepts and have been effectively utilized for incorporating commonsense in neural models, they primarily encode declarative or single-condition inferential knowledge and assume all conceptual beliefs to have the same likelihood. Further, these CKGs utilize a limited set of relations shared across concepts and lack a coherent knowledge organization structure resulting in redundancies as well as sparsity across the larger knowledge graph. Consequently, today's CKGs, while useful for a first level of reasoning, do not adequately capture deeper human-level commonsense inferences which can be more nuanced and influenced by multiple contextual or situational factors. Accordingly, in this work, we study how commonsense knowledge can be better represented by -- (i) utilizing a probabilistic logic representation scheme to model composite inferential knowledge and represent conceptual beliefs with varying likelihoods and (ii) incorporating a hierarchical conceptual ontology to identify salient concept-relevant relations and organize beliefs at different conceptual levels. Our resulting knowledge representation framework can encode a wider variety of world knowledge and represent beliefs flexibly using grounded concepts as well as free-text phrases. As a result, the framework can be utilized as both a traditional free-text knowledge graph and a grounded logic-based inference system more suitable for neuro-symbolic applications. We describe how we extend the PrimeNet knowledge base with our framework through crowd-sourcing and expert-annotation, and demonstrate its application for more interpretable passage-based semantic parsing and question answering.
TDAN: Top-Down Attention Networks for Enhanced Feature Selectivity in CNNs
Nov 26, 2021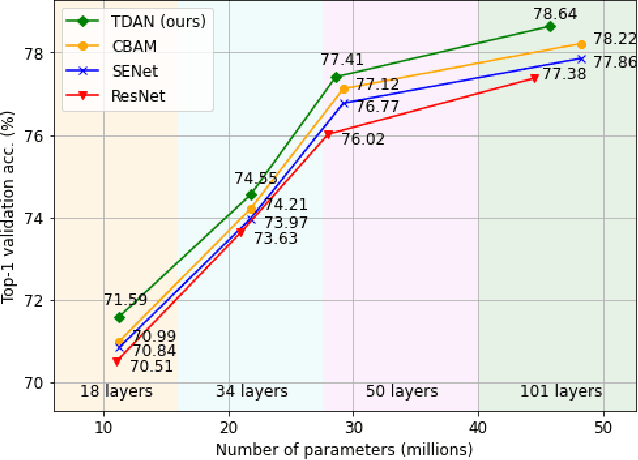
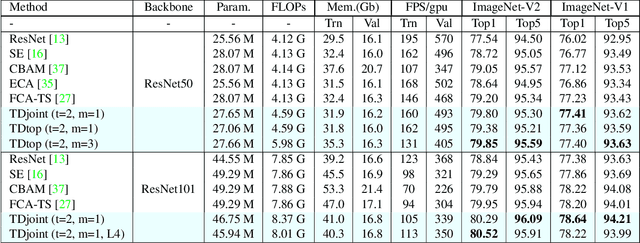

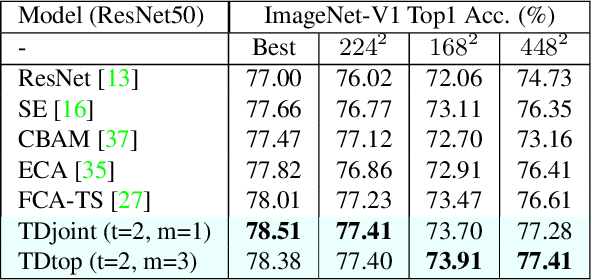
Attention modules for Convolutional Neural Networks (CNNs) are an effective method to enhance performance of networks on multiple computer-vision tasks. While many works focus on building more effective modules through appropriate modelling of channel-, spatial- and self-attention, they primarily operate in a feedfoward manner. Consequently, the attention mechanism strongly depends on the representational capacity of a single input feature activation, and can benefit from incorporation of semantically richer higher-level activations that can specify "what and where to look" through top-down information flow. Such feedback connections are also prevalent in the primate visual cortex and recognized by neuroscientists as a key component in primate visual attention. Accordingly, in this work, we propose a lightweight top-down (TD) attention module that iteratively generates a "visual searchlight" to perform top-down channel and spatial modulation of its inputs and consequently outputs more selective feature activations at each computation step. Our experiments indicate that integrating TD in CNNs enhances their performance on ImageNet-1k classification and outperforms prominent attention modules while being more parameter and memory efficient. Further, our models are more robust to changes in input resolution during inference and learn to "shift attention" by localizing individual objects or features at each computation step without any explicit supervision. This capability results in 5% improvement for ResNet50 on weakly-supervised object localization besides improvements in fine-grained and multi-label classification.
graph2vec: Learning Distributed Representations of Graphs
Jul 17, 2017
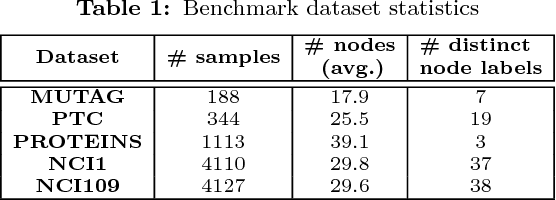
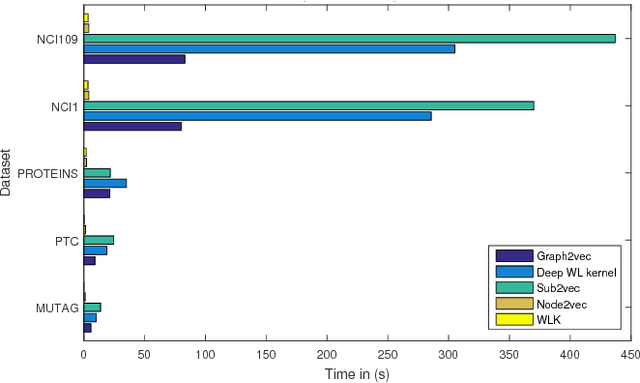

Recent works on representation learning for graph structured data predominantly focus on learning distributed representations of graph substructures such as nodes and subgraphs. However, many graph analytics tasks such as graph classification and clustering require representing entire graphs as fixed length feature vectors. While the aforementioned approaches are naturally unequipped to learn such representations, graph kernels remain as the most effective way of obtaining them. However, these graph kernels use handcrafted features (e.g., shortest paths, graphlets, etc.) and hence are hampered by problems such as poor generalization. To address this limitation, in this work, we propose a neural embedding framework named graph2vec to learn data-driven distributed representations of arbitrary sized graphs. graph2vec's embeddings are learnt in an unsupervised manner and are task agnostic. Hence, they could be used for any downstream task such as graph classification, clustering and even seeding supervised representation learning approaches. Our experiments on several benchmark and large real-world datasets show that graph2vec achieves significant improvements in classification and clustering accuracies over substructure representation learning approaches and are competitive with state-of-the-art graph kernels.