 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCitation Recommendation based on Argumentative Zoning of User Queries
Jan 30, 2025Citation recommendation aims to locate the important papers for scholars to cite. When writing the citing sentences, the authors usually hold different citing intents, which are referred to citation function in citation analysis. Since argumentative zoning is to identify the argumentative and rhetorical structure in scientific literature, we want to use this information to improve the citation recommendation task. In this paper, a multi-task learning model is built for citation recommendation and argumentative zoning classification. We also generated an annotated corpus of the data from PubMed Central based on a new argumentative zoning schema. The experimental results show that, by considering the argumentative information in the citing sentence, citation recommendation model will get better performance.
A review on the novelty measurements of academic papers
Jan 29, 2025Novelty evaluation is vital for the promotion and management of innovation. With the advancement of information techniques and the open data movement, some progress has been made in novelty measurements. Tracking and reviewing novelty measures provides a data-driven way to assess contributions, progress, and emerging directions in the science field. As academic papers serve as the primary medium for the dissemination, validation, and discussion of scientific knowledge, this review aims to offer a systematic analysis of novelty measurements for scientific papers. We began by comparing the differences between scientific novelty and four similar concepts, including originality, scientific innovation, creativity, and scientific breakthrough. Next, we reviewed the types of scientific novelty. Then, we classified existing novelty measures according to data types and reviewed the measures for each type. Subsequently, we surveyed the approaches employed in validating novelty measures and examined the current tools and datasets associated with these measures. Finally, we proposed several open issues for future studies.
UI Layout Generation with LLMs Guided by UI Grammar
Oct 24, 2023



The recent advances in Large Language Models (LLMs) have stimulated interest among researchers and industry professionals, particularly in their application to tasks concerning mobile user interfaces (UIs). This position paper investigates the use of LLMs for UI layout generation. Central to our exploration is the introduction of UI grammar -- a novel approach we proposed to represent the hierarchical structure inherent in UI screens. The aim of this approach is to guide the generative capacities of LLMs more effectively and improve the explainability and controllability of the process. Initial experiments conducted with GPT-4 showed the promising capability of LLMs to produce high-quality user interfaces via in-context learning. Furthermore, our preliminary comparative study suggested the potential of the grammar-based approach in improving the quality of generative results in specific aspects.
Automatic Recognition and Classification of Future Work Sentences from Academic Articles in a Specific Domain
Dec 28, 2022



Future work sentences (FWS) are the particular sentences in academic papers that contain the author's description of their proposed follow-up research direction. This paper presents methods to automatically extract FWS from academic papers and classify them according to the different future directions embodied in the paper's content. FWS recognition methods will enable subsequent researchers to locate future work sentences more accurately and quickly and reduce the time and cost of acquiring the corpus. The current work on automatic identification of future work sentences is relatively small, and the existing research cannot accurately identify FWS from academic papers, and thus cannot conduct data mining on a large scale. Furthermore, there are many aspects to the content of future work, and the subdivision of the content is conducive to the analysis of specific development directions. In this paper, Nature Language Processing (NLP) is used as a case study, and FWS are extracted from academic papers and classified into different types. We manually build an annotated corpus with six different types of FWS. Then, automatic recognition and classification of FWS are implemented using machine learning models, and the performance of these models is compared based on the evaluation metrics. The results show that the Bernoulli Bayesian model has the best performance in the automatic recognition task, with the Macro F1 reaching 90.73%, and the SCIBERT model has the best performance in the automatic classification task, with the weighted average F1 reaching 72.63%. Finally, we extract keywords from FWS and gain a deep understanding of the key content described in FWS, and we also demonstrate that content determination in FWS will be reflected in the subsequent research work by measuring the similarity between future work sentences and the abstracts.
Exploring the Distribution Regularities of User Attention and Sentiment toward Product Aspects in Online Reviews
Sep 08, 2022



[Purpose] To better understand the online reviews and help potential consumers, businessmen, and product manufacturers effectively obtain users' evaluation on product aspects, this paper explores the distribution regularities of user attention and sentiment toward product aspects from the temporal perspective of online reviews. [Design/methodology/approach] Temporal characteristics of online reviews (purchase time, review time, and time intervals between purchase time and review time), similar attributes clustering, and attribute-level sentiment computing technologies are employed based on more than 340k smartphone reviews of three products from JD.COM (a famous online shopping platform in China) to explore the distribution regularities of user attention and sentiment toward product aspects in this article. [Findings] The empirical results show that a power-law distribution can fit user attention to product aspects, and the reviews posted in short time intervals contain more product aspects. Besides, the results show that the values of user sentiment of product aspects are significantly higher/lower in short time intervals which contribute to judging the advantages and weaknesses of a product. [Research limitations] The paper can't acquire online reviews for more products with temporal characteristics to verify the findings because of the restriction on reviews crawling by the shopping platforms. [Originality/value] This work reveals the distribution regularities of user attention and sentiment toward product aspects, which is of great significance in assisting decision-making, optimizing review presentation, and improving the shopping experience.
A Review on Method Entities in the Academic Literature: Extraction, Evaluation, and Application
Sep 08, 2022In scientific research, the method is an indispensable means to solve scientific problems and a critical research object. With the advancement of sciences, many scientific methods are being proposed, modified, and used in academic literature. The authors describe details of the method in the abstract and body text, and key entities in academic literature reflecting names of the method are called method entities. Exploring diverse method entities in a tremendous amount of academic literature helps scholars understand existing methods, select the appropriate method for research tasks, and propose new methods. Furthermore, the evolution of method entities can reveal the development of a discipline and facilitate knowledge discovery. Therefore, this article offers a systematic review of methodological and empirical works focusing on extracting method entities from full-text academic literature and efforts to build knowledge services using these extracted method entities. Definitions of key concepts involved in this review were first proposed. Based on these definitions, we systematically reviewed the approaches and indicators to extract and evaluate method entities, with a strong focus on the pros and cons of each approach. We also surveyed how extracted method entities are used to build new applications. Finally, limitations in existing works as well as potential next steps were discussed.
Does Attention Mechanism Possess the Feature of Human Reading? A Perspective of Sentiment Classification Task
Sep 08, 2022
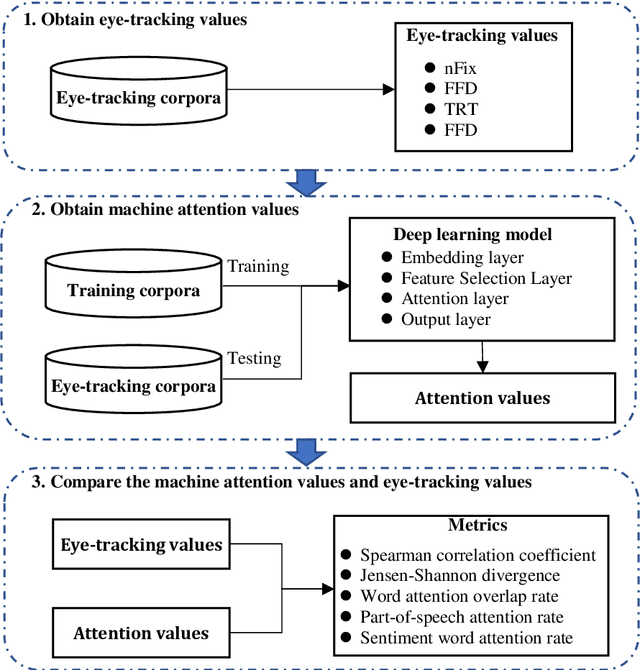
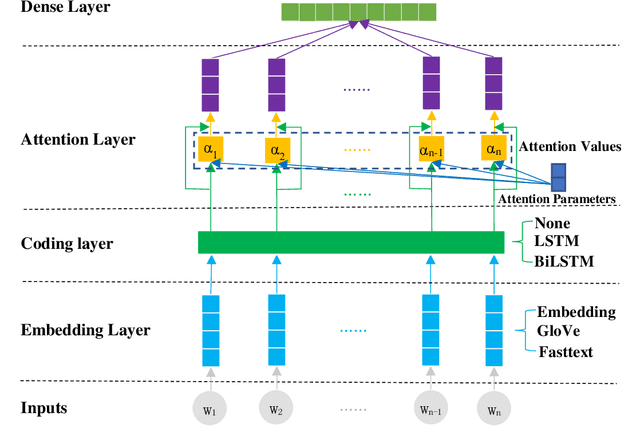
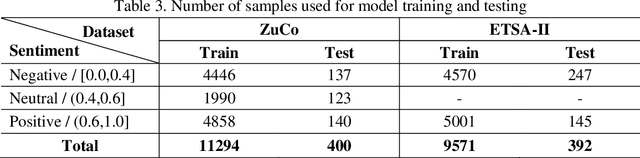
[Purpose] To understand the meaning of a sentence, humans can focus on important words in the sentence, which reflects our eyes staying on each word in different gaze time or times. Thus, some studies utilize eye-tracking values to optimize the attention mechanism in deep learning models. But these studies lack to explain the rationality of this approach. Whether the attention mechanism possesses this feature of human reading needs to be explored. [Design/methodology/approach] We conducted experiments on a sentiment classification task. Firstly, we obtained eye-tracking values from two open-source eye-tracking corpora to describe the feature of human reading. Then, the machine attention values of each sentence were learned from a sentiment classification model. Finally, a comparison was conducted to analyze machine attention values and eye-tracking values. [Findings] Through experiments, we found the attention mechanism can focus on important words, such as adjectives, adverbs, and sentiment words, which are valuable for judging the sentiment of sentences on the sentiment classification task. It possesses the feature of human reading, focusing on important words in sentences when reading. Due to the insufficient learning of the attention mechanism, some words are wrongly focused. The eye-tracking values can help the attention mechanism correct this error and improve the model performance. [Originality/value] Our research not only provides a reasonable explanation for the study of using eye-tracking values to optimize the attention mechanism, but also provides new inspiration for the interpretability of attention mechanism.
Which structure of academic articles do referees pay more attention to?: perspective of peer review and full-text of academic articles
Sep 05, 2022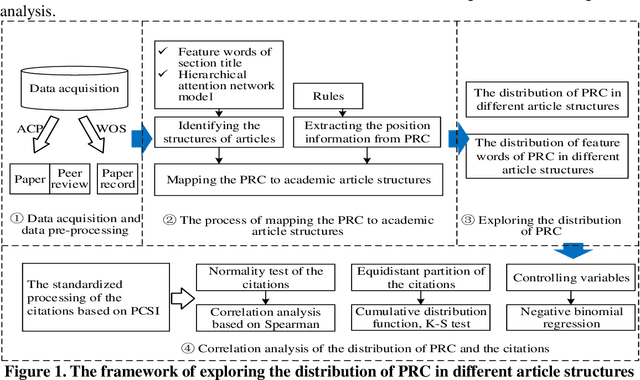
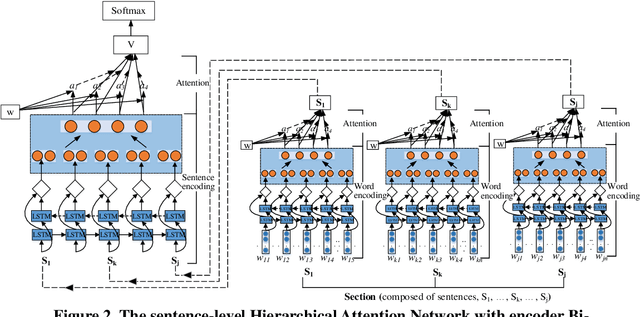
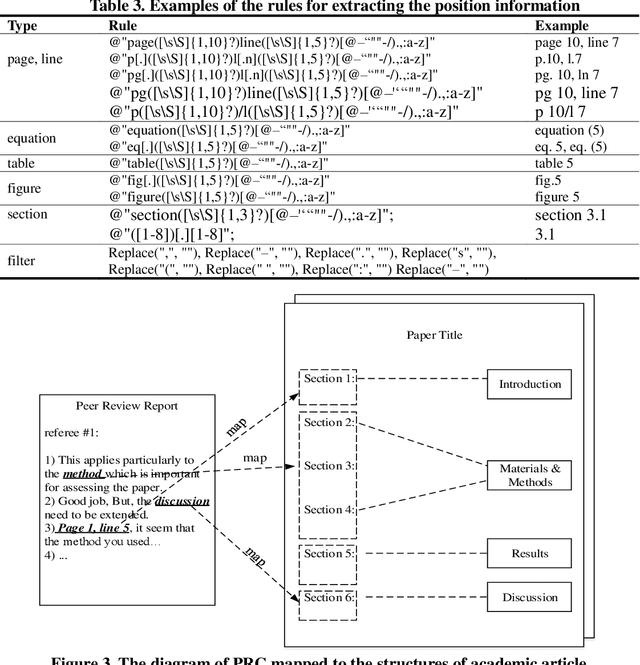
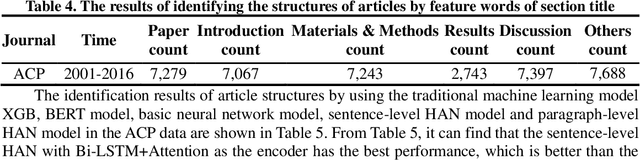
Purpose The purpose of this paper is to explore which structures of academic articles referees would pay more attention to, what specific content referees focus on, and whether the distribution of PRC is related to the citations. Design/methodology/approach Firstly, utilizing the feature words of section title and hierarchical attention network model (HAN) to identify the academic article structures. Secondly, analyzing the distribution of PRC in different structures according to the position information extracted by rules in PRC. Thirdly, analyzing the distribution of feature words of PRC extracted by the Chi-square test and TF-IDF in different structures. Finally, four correlation analysis methods are used to analyze whether the distribution of PRC in different structures is correlated to the citations. Findings The count of PRC distributed in Materials and Methods and Results section is significantly more than that in the structure of Introduction and Discussion, indicating that referees pay more attention to the Material and Methods and Results. The distribution of feature words of PRC in different structures is obviously different, which can reflect the content of referees' concern. There is no correlation between the distribution of PRC in different structures and the citations. Research limitations/implications Due to the differences in the way referees write peer review reports, the rules used to extract position information cannot cover all PRC. Originality/value The paper finds a pattern in the distribution of PRC in different academic article structures proving the long-term empirical understanding. It also provides insight into academic article writing: researchers should ensure the scientificity of methods and the reliability of results when writing academic article to obtain a high degree of recognition from referees.
Using Hashtags to Analyze Purpose and Technology Application of Open-Source Project Related to COVID-19
Jul 03, 2022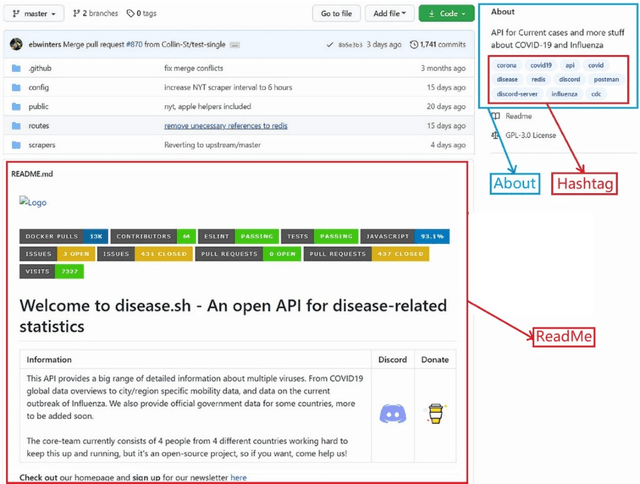
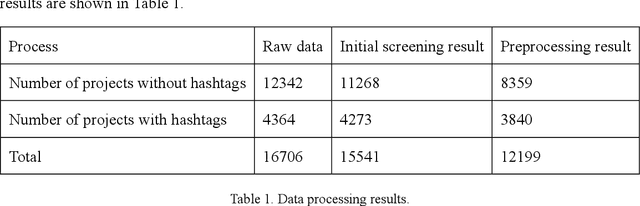
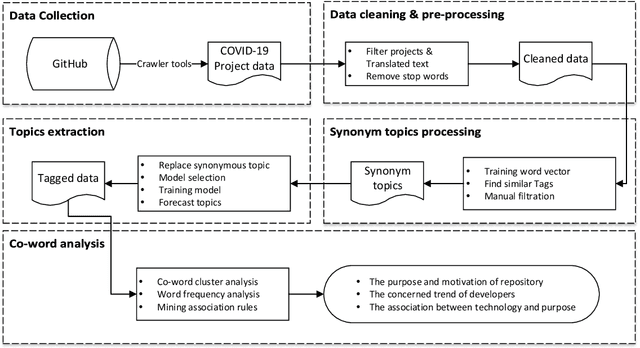
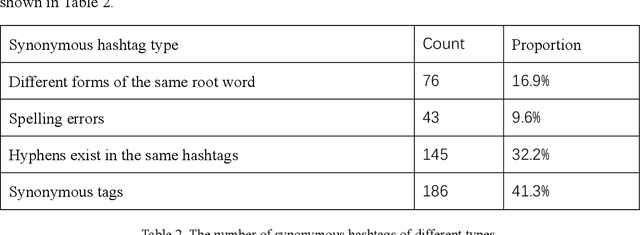
COVID-19 has had a profound impact on the lives of all human beings. Emerging technologies have made significant contributions to the fight against the pandemic. An extensive review of the application of technology will help facilitate future research and technology development to provide better solutions for future pandemics. In contrast to the extensive surveys of academic communities that have already been conducted, this study explores the IT community of practice. Using GitHub as the study target, we analyzed the main functionalities of the projects submitted during the pandemic. This study examines trends in projects with different functionalities and the relationship between functionalities and technologies. The study results show an imbalance in the number of projects with varying functionalities in the GitHub community, i.e., applications account for more than half of the projects. In contrast, other data analysis and AI projects account for a smaller share. This differs significantly from the survey of the academic community, where the findings focus more on cutting-edge technologies while projects in the community of practice use more mature technologies. The spontaneous behavior of developers may lack organization and make it challenging to target needs.
Cross-domain Federated Object Detection
Jun 30, 2022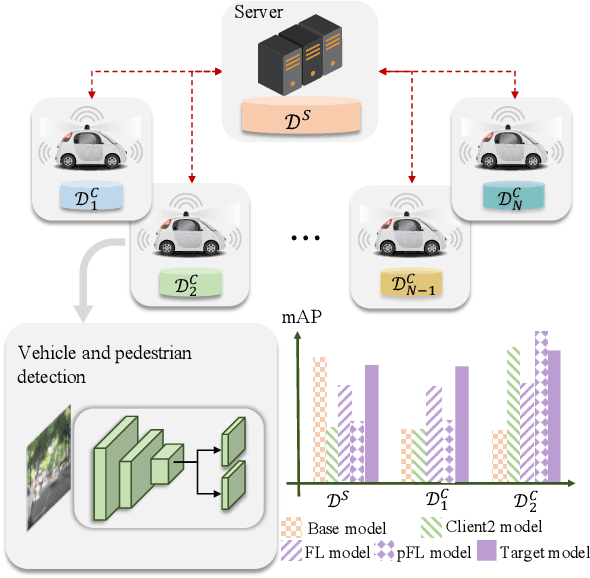
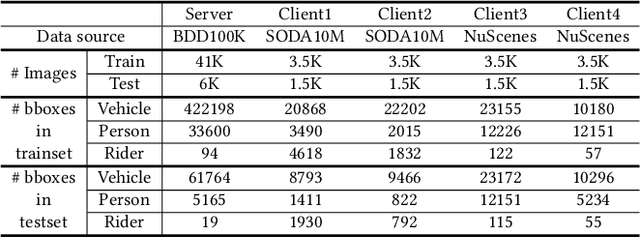
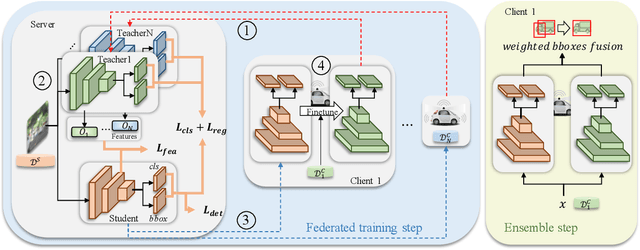
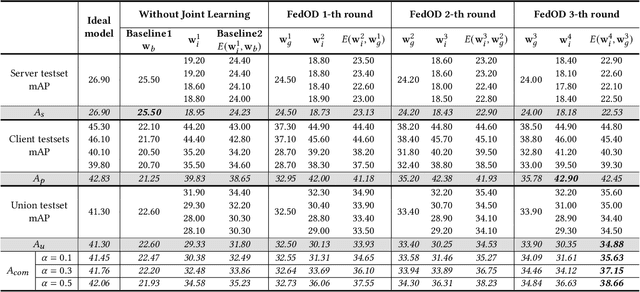
Detection models trained by one party (server) may face severe performance degradation when distributed to other users (clients). For example, in autonomous driving scenarios, different driving environments may bring obvious domain shifts, which lead to biases in model predictions. Federated learning that has emerged in recent years can enable multi-party collaborative training without leaking client data. In this paper, we focus on a special cross-domain scenario where the server contains large-scale data and multiple clients only contain a small amount of data; meanwhile, there exist differences in data distributions among the clients. In this case, traditional federated learning techniques cannot take into account the learning of both the global knowledge of all participants and the personalized knowledge of a specific client. To make up for this limitation, we propose a cross-domain federated object detection framework, named FedOD. In order to learn both the global knowledge and the personalized knowledge in different domains, the proposed framework first performs the federated training to obtain a public global aggregated model through multi-teacher distillation, and sends the aggregated model back to each client for finetuning its personalized local model. After very few rounds of communication, on each client we can perform weighted ensemble inference on the public global model and the personalized local model. With the ensemble, the generalization performance of the client-side model can outperform a single model with the same parameter scale. We establish a federated object detection dataset which has significant background differences and instance differences based on multiple public autonomous driving datasets, and then conduct extensive experiments on the dataset. The experimental results validate the effectiveness of the proposed method.