 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLiteraryTaste: A Preference Dataset for Creative Writing Personalization
Nov 12, 2025People have different creative writing preferences, and large language models (LLMs) for these tasks can benefit from adapting to each user's preferences. However, these models are often trained over a dataset that considers varying personal tastes as a monolith. To facilitate developing personalized creative writing LLMs, we introduce LiteraryTaste, a dataset of reading preferences from 60 people, where each person: 1) self-reported their reading habits and tastes (stated preference), and 2) annotated their preferences over 100 pairs of short creative writing texts (revealed preference). With our dataset, we found that: 1) people diverge on creative writing preferences, 2) finetuning a transformer encoder could achieve 75.8% and 67.7% accuracy when modeling personal and collective revealed preferences, and 3) stated preferences had limited utility in modeling revealed preferences. With an LLM-driven interpretability pipeline, we analyzed how people's preferences vary. We hope our work serves as a cornerstone for personalizing creative writing technologies.
UI Layout Generation with LLMs Guided by UI Grammar
Oct 24, 2023



The recent advances in Large Language Models (LLMs) have stimulated interest among researchers and industry professionals, particularly in their application to tasks concerning mobile user interfaces (UIs). This position paper investigates the use of LLMs for UI layout generation. Central to our exploration is the introduction of UI grammar -- a novel approach we proposed to represent the hierarchical structure inherent in UI screens. The aim of this approach is to guide the generative capacities of LLMs more effectively and improve the explainability and controllability of the process. Initial experiments conducted with GPT-4 showed the promising capability of LLMs to produce high-quality user interfaces via in-context learning. Furthermore, our preliminary comparative study suggested the potential of the grammar-based approach in improving the quality of generative results in specific aspects.
A Bottom-Up End-User Intelligent Assistant Approach to Empower Gig Workers against AI Inequality
Apr 29, 2022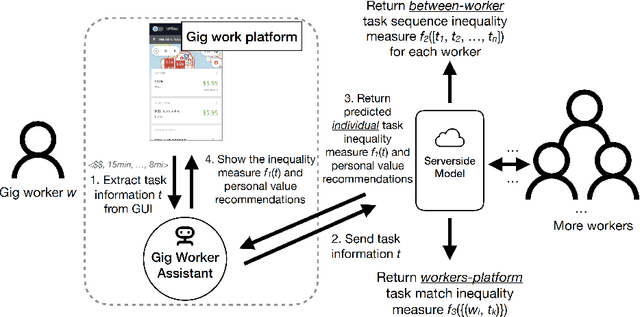
The growing inequality in gig work between workers and platforms has become a critical social issue as gig work plays an increasingly prominent role in the future of work. The AI inequality is caused by (1) the technology divide in who has access to AI technologies in gig work; and (2) the data divide in who owns the data in gig work leads to unfair working conditions, growing pay gap, neglect of workers' diverse preferences, and workers' lack of trust in the platforms. In this position paper, we argue that a bottom-up approach that empowers individual workers to access AI-enabled work planning support and share data among a group of workers through a network of end-user-programmable intelligent assistants is a practical way to bridge AI inequality in gig work under the current paradigm of privately owned platforms. This position paper articulates a set of research challenges, potential approaches, and community engagement opportunities, seeking to start a dialogue on this important research topic in the interdisciplinary CHIWORK community.