 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinding Sparse Structure for Domain Specific Neural Machine Translation
Dec 19, 2020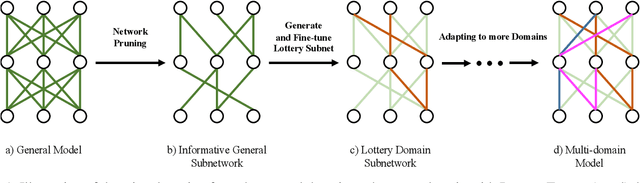
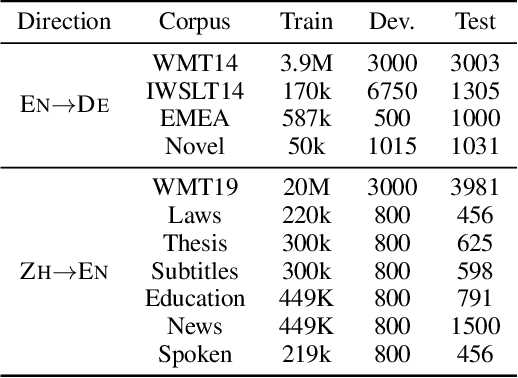
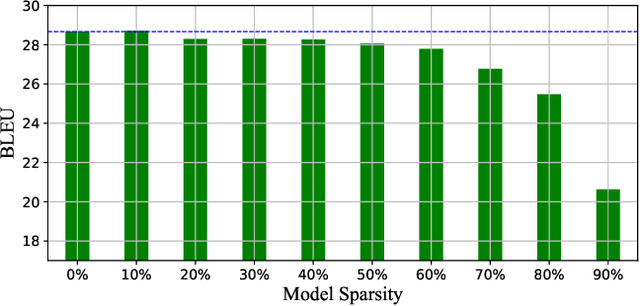
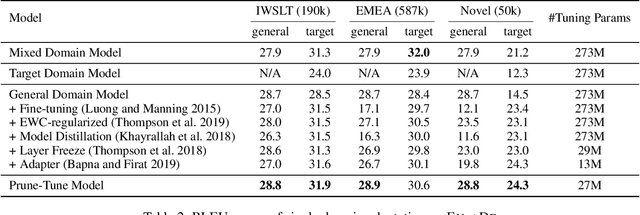
Fine-tuning is a major approach for domain adaptation in Neural Machine Translation (NMT). However, unconstrained fine-tuning requires very careful hyper-parameter tuning otherwise it is easy to fall into over-fitting on the target domain and degradation on the general domain. To mitigate it, we propose PRUNE-TUNE, a novel domain adaptation method via gradual pruning. It learns tiny domain-specific subnetworks for tuning. During adaptation to a new domain, we only tune its corresponding subnetwork. PRUNE-TUNE alleviates the over-fitting and the degradation problem without model modification. Additionally, with no overlapping between domain-specific subnetworks, PRUNE-TUNE is also capable of sequential multi-domain learning. Empirical experiment results show that PRUNE-TUNE outperforms several strong competitors in the target domain test set without the quality degradation of the general domain in both single and multiple domain settings.
NeurST: Neural Speech Translation Toolkit
Dec 18, 2020

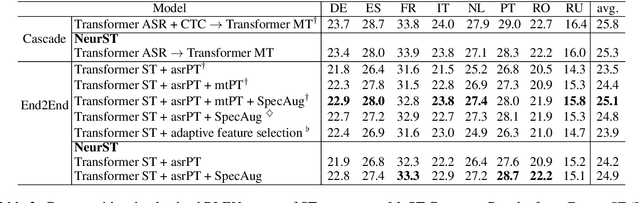
NeurST is an open-source toolkit for neural speech translation developed by ByteDance AI Lab. The toolkit mainly focuses on end-to-end speech translation, which is easy to use, modify, and extend to advanced speech translation research and products. NeurST aims at facilitating the speech translation research for NLP researchers and provides a complete setup for speech translation benchmarks, including feature extraction, data preprocessing, distributed training, and evaluation. Moreover, The toolkit implements several major architectures for end-to-end speech translation. It shows experimental results for different benchmark datasets, which can be regarded as reliable baselines for future research. The toolkit is publicly available at https://github.com/bytedance/neurst.
Capturing Longer Context for Document-level Neural Machine Translation: A Multi-resolutional Approach
Oct 18, 2020
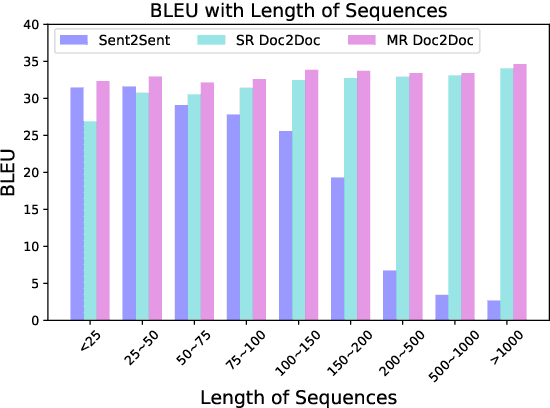
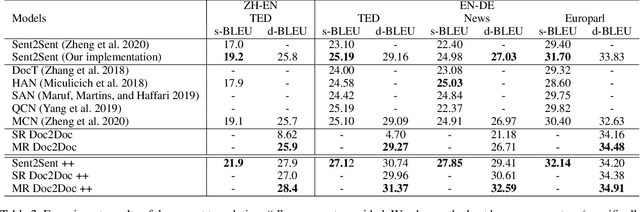
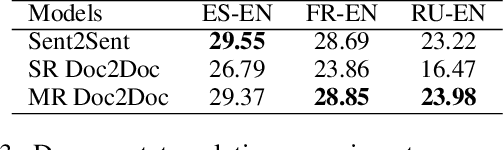
Discourse context has been proven useful when translating documents. It is quite a challenge to incorporate long document context in the prevailing neural machine translation models such as Transformer. In this paper, we propose multi-resolutional (MR) Doc2Doc, a method to train a neural sequence-to-sequence model for document-level translation. Our trained model can simultaneously translate sentence by sentence as well as a document as a whole. We evaluate our method and several recent approaches on nine document-level datasets and two sentence-level datasets across six languages. Experiments show that MR Doc2Doc outperforms sentence-level models and previous methods in a comprehensive set of metrics, including BLEU, four lexical indices, three newly proposed assistant linguistic indicators, and human evaluation.
Kernelized Bayesian Softmax for Text Generation
Nov 01, 2019
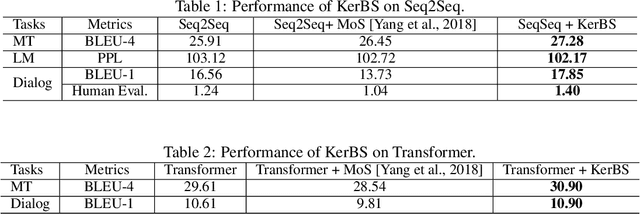
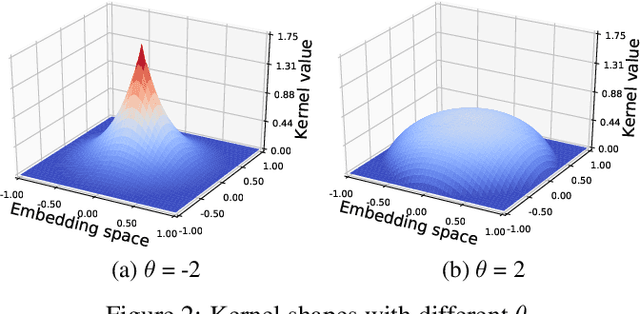

Neural models for text generation require a softmax layer with proper token embeddings during the decoding phase. Most existing approaches adopt single point embedding for each token. However, a word may have multiple senses according to different context, some of which might be distinct. In this paper, we propose KerBS, a novel approach for learning better embeddings for text generation. KerBS embodies two advantages: (a) it employs a Bayesian composition of embeddings for words with multiple senses; (b) it is adaptive to semantic variances of words and robust to rare sentence context by imposing learned kernels to capture the closeness of words (senses) in the embedding space. Empirical studies show that KerBS significantly boosts the performance of several text generation tasks.
Towards Making the Most of BERT in Neural Machine Translation
Aug 30, 2019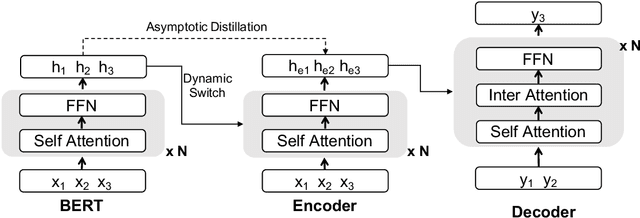

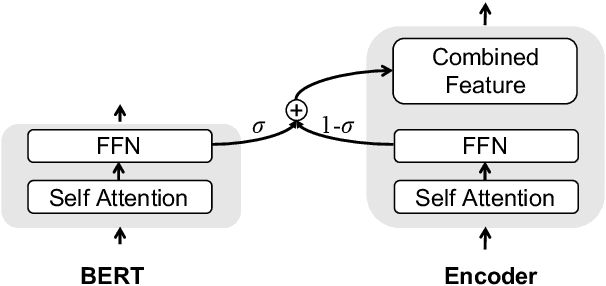
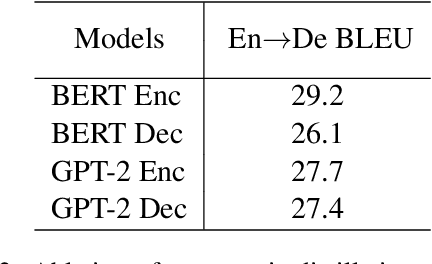
GPT-2 and BERT demonstrate the effectiveness of using pre-trained language models (LMs) on various natural language processing tasks. However, LM fine-tuning often suffers from catastrophic forgetting when applied to resource-rich tasks. In this work, we introduce a concerted training framework (\method) that is the key to integrate the pre-trained LMs to neural machine translation (NMT). Our proposed Cnmt consists of three techniques: a) asymptotic distillation to ensure that the NMT model can retain the previous pre-trained knowledge; \item a dynamic switching gate to avoid catastrophic forgetting of pre-trained knowledge; and b)a strategy to adjust the learning paces according to a scheduled policy. Our experiments in machine translation show \method gains of up to 3 BLEU score on the WMT14 English-German language pair which even surpasses the previous state-of-the-art pre-training aided NMT by 1.4 BLEU score. While for the large WMT14 English-French task with 40 millions of sentence-pairs, our base model still significantly improves upon the state-of-the-art Transformer big model by more than 1 BLEU score.