 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeGRe: Dense-supervised Generative Reranking for Recommendation
May 25, 2026In multi-stage recommender systems, reranking optimizes overall utility by capturing intra-list contextual dependencies, yet its central challenge lies in exploring optimal sequences within an exponentially large permutation space. Recent studies have shifted towards end-to-end generative frameworks, which typically leverage list-wise rewards or preference alignment to guide generator training. However, these methods still face two critical issues. First is the heuristic label bias. Existing methods often construct training targets based on simple rules, such as promoting clicked items to the top, while ignoring causal dependencies within the list context. Second is the credit assignment problem. Sparse list-level posterior rewards fail to directly guide intermediate steps in sequence generation, leading to ambiguous optimization directions. To address these issues, we propose DeGRe (Dense-supervised Generative Reranking), a generative reranking framework that bridges the gap between offline exploration and online efficiency through dense supervision. The core of DeGRe lies in its offline-online decoupled design. During the offline phase, we introduce a Lookahead Evaluator based on cumulative regression, which leverages beam search to actively mine high-value lookahead sequences in the unexposed space. During training, we transform the step-wise value estimations from the evaluator into dense supervision signals and distill them into a lightweight Online Generator. This mechanism enables the generator to internalize lookahead planning capabilities, requiring only a single efficient greedy decoding pass during online inference to approximate the global optimum. Experiments demonstrate that DeGRe outperforms baseline models on public benchmarks and industrial datasets. We have successfully deployed DeGRe on Taobao Flash Shopping, significantly improving online recommendations.
Pre-train and Fine-tune: Recommenders as Large Models
Jan 24, 2025



In reality, users have different interests in different periods, regions, scenes, etc. Such changes in interest are so drastic that they are difficult to be captured by recommenders. Existing multi-domain learning can alleviate this problem. However, the structure of the industrial recommendation system is complex, the amount of data is huge, and the training cost is extremely high, so it is difficult to modify the structure of the industrial recommender and re-train it. To fill this gap, we consider recommenders as large pre-trained models and fine-tune them. We first propose the theory of the information bottleneck for fine-tuning and present an explanation for the fine-tuning technique in recommenders. To tailor for recommendation, we design an information-aware adaptive kernel (IAK) technique to fine-tune the pre-trained recommender. Specifically, we define fine-tuning as two phases: knowledge compression and knowledge matching and let the training stage of IAK explicitly approximate these two phases. Our proposed approach designed from the essence of fine-tuning is well interpretable. Extensive online and offline experiments show the superiority of our proposed method. Besides, we also share unique and important lessons we learned when deploying the method in a large-scale online platform. We also present the potential issues of fine-tuning techniques in recommendation systems and the corresponding solutions. The recommender with IAK technique has been deployed on the homepage of a billion-scale online food platform for several months and has yielded considerable profits in our business.
Robust Representation Learning with Feedback for Single Image Deraining
Feb 03, 2021

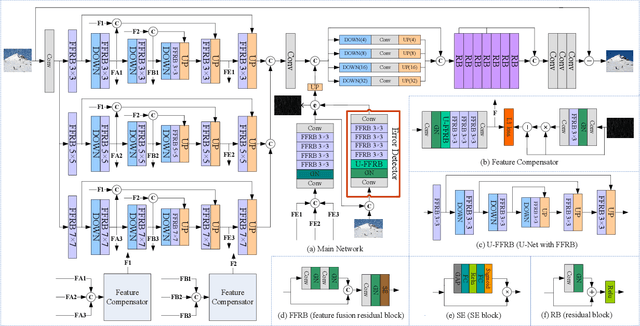
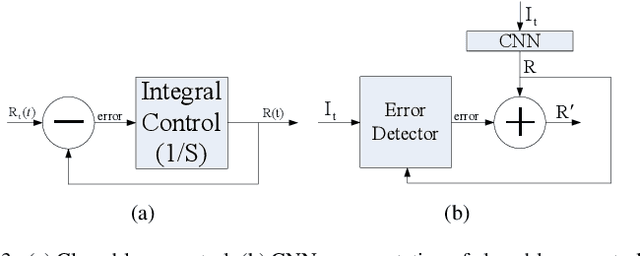
A deraining network may be interpreted as a condition generator. Image degradation generated by the deraining network can be attributed to defective embedding features that serve as conditions. Existing image deraining methods usually ignore uncertainty-caused model errors that lower embedding quality and embed low-quality features into the model directly. In contrast, we replace low-quality features by latent high-quality features. The spirit of closed-loop feedback in the automatic control field is borrowed to obtain latent high-quality features. A new method for error detection and feature compensation is proposed to address model errors. Extensive experiments on benchmark datasets as well as specific real datasets demonstrate the advantage of the proposed method over recent state-of-the-art methods.