 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeGRe: Dense-supervised Generative Reranking for Recommendation
May 25, 2026In multi-stage recommender systems, reranking optimizes overall utility by capturing intra-list contextual dependencies, yet its central challenge lies in exploring optimal sequences within an exponentially large permutation space. Recent studies have shifted towards end-to-end generative frameworks, which typically leverage list-wise rewards or preference alignment to guide generator training. However, these methods still face two critical issues. First is the heuristic label bias. Existing methods often construct training targets based on simple rules, such as promoting clicked items to the top, while ignoring causal dependencies within the list context. Second is the credit assignment problem. Sparse list-level posterior rewards fail to directly guide intermediate steps in sequence generation, leading to ambiguous optimization directions. To address these issues, we propose DeGRe (Dense-supervised Generative Reranking), a generative reranking framework that bridges the gap between offline exploration and online efficiency through dense supervision. The core of DeGRe lies in its offline-online decoupled design. During the offline phase, we introduce a Lookahead Evaluator based on cumulative regression, which leverages beam search to actively mine high-value lookahead sequences in the unexposed space. During training, we transform the step-wise value estimations from the evaluator into dense supervision signals and distill them into a lightweight Online Generator. This mechanism enables the generator to internalize lookahead planning capabilities, requiring only a single efficient greedy decoding pass during online inference to approximate the global optimum. Experiments demonstrate that DeGRe outperforms baseline models on public benchmarks and industrial datasets. We have successfully deployed DeGRe on Taobao Flash Shopping, significantly improving online recommendations.
A Hierarchical Error-Corrective Graph Framework for Autonomous Agents with LLM-Based Action Generation
Mar 09, 2026We propose a Hierarchical Error-Corrective Graph FrameworkforAutonomousAgentswithLLM-BasedActionGeneration(HECG),whichincorporates three core innovations: (1) Multi-Dimensional Transferable Strategy (MDTS): by integrating task quality metrics (Q), confidence/cost metrics (C), reward metrics (R), and LLM-based semantic reasoning scores (LLM-Score), MDTS achieves multi-dimensional alignment between quantitative performance and semantic context, enabling more precise selection of high-quality candidate strate gies and effectively reducing the risk of negative transfer. (2) Error Matrix Classification (EMC): unlike simple confusion matrices or overall performance metrics, EMC provides structured attribution of task failures by categorizing errors into ten types, such as Strategy Errors (Strategy Whe) and Script Parsing Errors (Script-Parsing-Error), and decomposing them according to severity, typical actions, error descriptions, and recoverability. This allows precise analysis of the root causes of task failures, offering clear guidance for subsequent error correction and strategy optimization rather than relying solely on overall success rates or single performance metrics. (3) Causal-Context Graph Retrieval (CCGR): to enhance agent retrieval capabilities in dynamic task environments, we construct graphs from historical states, actions, and event sequences, where nodes store executed actions, next-step actions, execution states, transferable strategies, and other relevant information, and edges represent causal dependencies such as preconditions for transitions between nodes. CCGR identifies subgraphs most relevant to the current task context, effectively capturing structural relationships beyond vector similarity, allowing agents to fully leverage contextual information, accelerate strategy adaptation, and improve execution reliability in complex, multi-step tasks.
A Solution-based LLM API-using Methodology for Academic Information Seeking
May 24, 2024Applying large language models (LLMs) for academic API usage shows promise in reducing researchers' academic information seeking efforts. However, current LLM API-using methods struggle with complex API coupling commonly encountered in academic queries. To address this, we introduce SoAy, a solution-based LLM API-using methodology for academic information seeking. It uses code with a solution as the reasoning method, where a solution is a pre-constructed API calling sequence. The addition of the solution reduces the difficulty for the model to understand the complex relationships between APIs. Code improves the efficiency of reasoning. To evaluate SoAy, we introduce SoAyBench, an evaluation benchmark accompanied by SoAyEval, built upon a cloned environment of APIs from AMiner. Experimental results demonstrate a 34.58-75.99\% performance improvement compared to state-of-the-art LLM API-based baselines. All datasets, codes, tuned models, and deployed online services are publicly accessible at https://github.com/RUCKBReasoning/SoAy.
Less is More: Data-Efficient Complex Question Answering over Knowledge Bases
Oct 29, 2020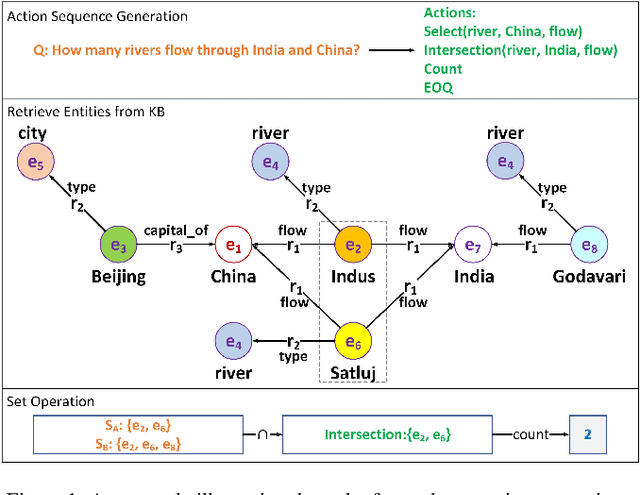
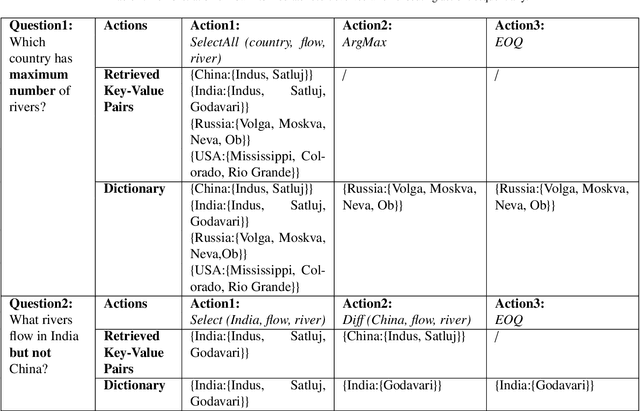
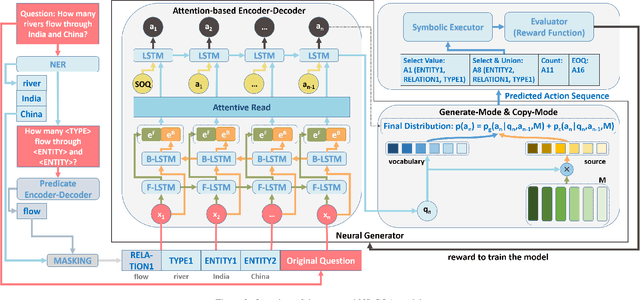
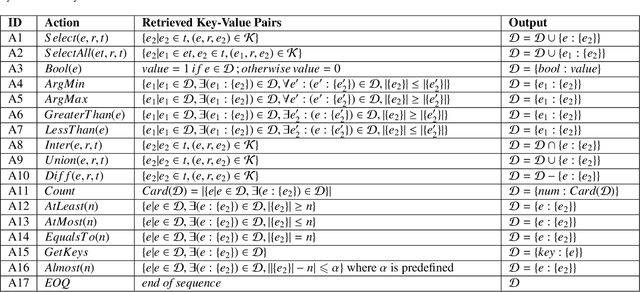
Question answering is an effective method for obtaining information from knowledge bases (KB). In this paper, we propose the Neural-Symbolic Complex Question Answering (NS-CQA) model, a data-efficient reinforcement learning framework for complex question answering by using only a modest number of training samples. Our framework consists of a neural generator and a symbolic executor that, respectively, transforms a natural-language question into a sequence of primitive actions, and executes them over the knowledge base to compute the answer. We carefully formulate a set of primitive symbolic actions that allows us to not only simplify our neural network design but also accelerate model convergence. To reduce search space, we employ the copy and masking mechanisms in our encoder-decoder architecture to drastically reduce the decoder output vocabulary and improve model generalizability. We equip our model with a memory buffer that stores high-reward promising programs. Besides, we propose an adaptive reward function. By comparing the generated trial with the trials stored in the memory buffer, we derive the curriculum-guided reward bonus, i.e., the proximity and the novelty. To mitigate the sparse reward problem, we combine the adaptive reward and the reward bonus, reshaping the sparse reward into dense feedback. Also, we encourage the model to generate new trials to avoid imitating the spurious trials while making the model remember the past high-reward trials to improve data efficiency. Our NS-CQA model is evaluated on two datasets: CQA, a recent large-scale complex question answering dataset, and WebQuestionsSP, a multi-hop question answering dataset. On both datasets, our model outperforms the state-of-the-art models. Notably, on CQA, NS-CQA performs well on questions with higher complexity, while only using approximately 1% of the total training samples.