 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThinKV: Thought-Adaptive KV Cache Compression for Efficient Reasoning Models
Oct 01, 2025The long-output context generation of large reasoning models enables extended chain of thought (CoT) but also drives rapid growth of the key-value (KV) cache, quickly overwhelming GPU memory. To address this challenge, we propose ThinKV, a thought-adaptive KV cache compression framework. ThinKV is based on the observation that attention sparsity reveals distinct thought types with varying importance within the CoT. It applies a hybrid quantization-eviction strategy, assigning token precision by thought importance and progressively evicting tokens from less critical thoughts as reasoning trajectories evolve. Furthermore, to implement ThinKV, we design a kernel that extends PagedAttention to enable efficient reuse of evicted tokens' memory slots, eliminating compaction overheads. Extensive experiments on DeepSeek-R1-Distill, GPT-OSS, and NVIDIA AceReason across mathematics and coding benchmarks show that ThinKV achieves near-lossless accuracy with less than 5% of the original KV cache, while improving performance with up to 5.8x higher inference throughput over state-of-the-art baselines.
FGMP: Fine-Grained Mixed-Precision Weight and Activation Quantization for Hardware-Accelerated LLM Inference
Apr 19, 2025Quantization is a powerful tool to improve large language model (LLM) inference efficiency by utilizing more energy-efficient low-precision datapaths and reducing memory footprint. However, accurately quantizing LLM weights and activations to low precision is challenging without degrading model accuracy. We propose fine-grained mixed precision (FGMP) quantization, a post-training mixed-precision quantization hardware-software co-design methodology that maintains accuracy while quantizing the majority of weights and activations to reduced precision. Our work makes the following contributions: 1) We develop a policy that uses the perturbation in each value, weighted by the Fisher information, to select which weight and activation blocks to keep in higher precision. This approach preserves accuracy by identifying which weight and activation blocks need to be retained in higher precision to minimize the perturbation in the model loss. 2) We also propose a sensitivity-weighted clipping approach for fine-grained quantization which helps retain accuracy for blocks that are quantized to low precision. 3) We then propose hardware augmentations to leverage the efficiency benefits of FGMP quantization. Our hardware implementation encompasses i) datapath support for FGMP at block granularity, and ii) a mixed-precision activation quantization unit to assign activation blocks to high or low precision on the fly with minimal runtime and energy overhead. Our design, prototyped using NVFP4 (an FP4 format with microscaling) as the low-precision datatype and FP8 as the high-precision datatype, facilitates efficient FGMP quantization, attaining <1% perplexity degradation on Wikitext-103 for the Llama-2-7B model relative to an all-FP8 baseline design while consuming 14% less energy during inference and requiring 30% less weight memory.
BCQ: Block Clustered Quantization for 4-bit (W4A4) LLM Inference
Feb 07, 2025Post-training quantization (PTQ) is a promising approach to reducing the storage and computational requirements of large language models (LLMs) without additional training cost. Recent PTQ studies have primarily focused on quantizing only weights to sub-8-bits while maintaining activations at 8-bits or higher. Accurate sub-8-bit quantization for both weights and activations without relying on quantization-aware training remains a significant challenge. We propose a novel quantization method called block clustered quantization (BCQ) wherein each operand tensor is decomposed into blocks (a block is a group of contiguous scalars), blocks are clustered based on their statistics, and a dedicated optimal quantization codebook is designed for each cluster. As a specific embodiment of this approach, we propose a PTQ algorithm called Locally-Optimal BCQ (LO-BCQ) that iterates between the steps of block clustering and codebook design to greedily minimize the quantization mean squared error. When weight and activation scalars are encoded to W4A4 format (with 0.5-bits of overhead for storing scaling factors and codebook selectors), we advance the current state-of-the-art by demonstrating <1% loss in inference accuracy across several LLMs and downstream tasks.
EoRA: Training-free Compensation for Compressed LLM with Eigenspace Low-Rank Approximation
Oct 28, 2024In this work, we re-formulate the model compression problem into the customized compensation problem: Given a compressed model, we aim to introduce residual low-rank paths to compensate for compression errors under customized requirements from users (e.g., tasks, compression ratios), resulting in greater flexibility in adjusting overall capacity without being constrained by specific compression formats. However, naively applying SVD to derive residual paths causes suboptimal utilization of the low-rank representation capacity. Instead, we propose Training-free Eigenspace Low-Rank Approximation (EoRA), a method that directly minimizes compression-induced errors without requiring gradient-based training, achieving fast optimization in minutes using a small amount of calibration data. EoRA projects compression errors into the eigenspace of input activations, leveraging eigenvalues to effectively prioritize the reconstruction of high-importance error components. Moreover, EoRA can be seamlessly integrated with fine-tuning and quantization to further improve effectiveness and efficiency. EoRA consistently outperforms previous methods in compensating errors for compressed LLaMA2/3 models on various tasks, such as language generation, commonsense reasoning, and math reasoning tasks (e.g., 31.31%/12.88% and 9.69% improvements on ARC-Easy/ARC-Challenge and MathQA when compensating LLaMA3-8B that is quantized to 4-bit and pruned to 2:4 sparsity). EoRA offers a scalable, training-free solution to compensate for compression errors, making it a powerful tool to deploy LLMs in various capacity and efficiency requirements.
ESPACE: Dimensionality Reduction of Activations for Model Compression
Oct 07, 2024We propose ESPACE, an LLM compression technique based on dimensionality reduction of activations. Unlike prior works on weight-centric tensor decomposition, ESPACE projects activations onto a pre-calibrated set of principal components. The activation-centrality of the approach enables retraining LLMs with no loss of expressivity; while at inference, weight decomposition is obtained as a byproduct of matrix multiplication associativity. Theoretical results on the construction of projection matrices with optimal computational accuracy are provided. Experimentally, we find ESPACE enables 50% compression of GPT3, Llama2, and Nemotron4 models with small accuracy degradation, as low as a 0.18 perplexity increase on GPT3-22B. At lower compression rates of 20% to 40%, ESPACE drives GPT3 models to outperforming their baseline, by up to a 0.38 decrease in perplexity for GPT3-8B. ESPACE also reduces GEMM execution time and prefill inference latency on existing hardware. Comparison with related works on compressing Llama2-7B via matrix factorization shows that ESPACE is a first step in advancing the state-of-the-art in tensor decomposition compression of LLMs.
VaPr: Variable-Precision Tensors to Accelerate Robot Motion Planning
Oct 11, 2023



High-dimensional motion generation requires numerical precision for smooth, collision-free solutions. Typically, double-precision or single-precision floating-point (FP) formats are utilized. Using these for big tensors imposes a strain on the memory bandwidth provided by the devices and alters the memory footprint, hence limiting their applicability to low-power edge devices needed for mobile robots. The uniform application of reduced precision can be advantageous but severely degrades solutions. Using decreased precision data types for important tensors, we propose to accelerate motion generation by removing memory bottlenecks. We propose variable-precision (VaPr) search optimization to determine the appropriate precision for large tensors from a vast search space of approximately 4 million unique combinations for FP data types across the tensors. To obtain the efficiency gains, we exploit existing platform support for an out-of-the-box GPU speedup and evaluate prospective precision converter units for GPU types that are not currently supported. Our experimental results on 800 planning problems for the Franka Panda robot on the MotionBenchmaker dataset across 8 environments show that a 4-bit FP format is sufficient for the largest set of tensors in the motion generation stack. With the software-only solution, VaPr achieves 6.3% and 6.3% speedups on average for a significant portion of motion generation over the SOTA solution (CuRobo) on Jetson Orin and RTX2080 Ti GPU, respectively, and 9.9%, 17.7% speedups with the FP converter.
Optimal Clipping and Magnitude-aware Differentiation for Improved Quantization-aware Training
Jun 13, 2022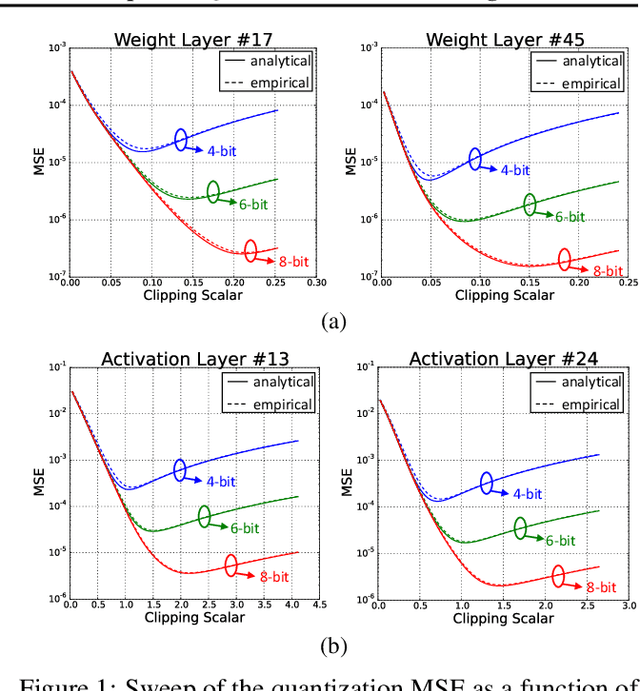

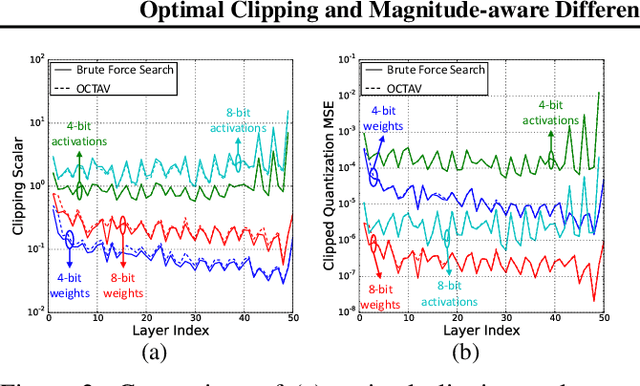
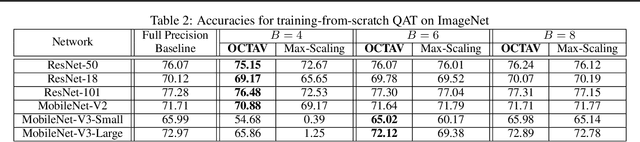
Data clipping is crucial in reducing noise in quantization operations and improving the achievable accuracy of quantization-aware training (QAT). Current practices rely on heuristics to set clipping threshold scalars and cannot be shown to be optimal. We propose Optimally Clipped Tensors And Vectors (OCTAV), a recursive algorithm to determine MSE-optimal clipping scalars. Derived from the fast Newton-Raphson method, OCTAV finds optimal clipping scalars on the fly, for every tensor, at every iteration of the QAT routine. Thus, the QAT algorithm is formulated with provably minimum quantization noise at each step. In addition, we reveal limitations in common gradient estimation techniques in QAT and propose magnitude-aware differentiation as a remedy to further improve accuracy. Experimentally, OCTAV-enabled QAT achieves state-of-the-art accuracy on multiple tasks. These include training-from-scratch and retraining ResNets and MobileNets on ImageNet, and Squad fine-tuning using BERT models, where OCTAV-enabled QAT consistently preserves accuracy at low precision (4-to-6-bits). Our results require no modifications to the baseline training recipe, except for the insertion of quantization operations where appropriate.
Fundamental Limits on Energy-Delay-Accuracy of In-memory Architectures in Inference Applications
Dec 25, 2020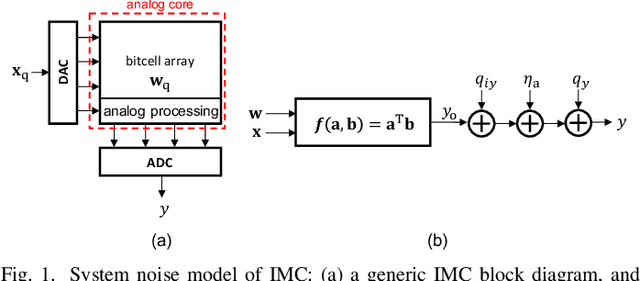
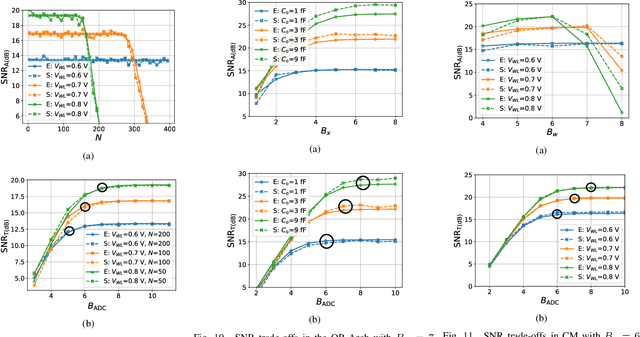
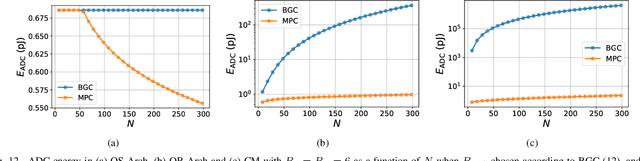
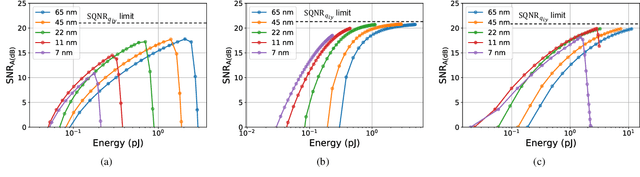
This paper obtains fundamental limits on the computational precision of in-memory computing architectures (IMCs). An IMC noise model and associated SNR metrics are defined and their interrelationships analyzed to show that the accuracy of IMCs is fundamentally limited by the compute SNR ($\text{SNR}_{\text{a}}$) of its analog core, and that activation, weight and output precision needs to be assigned appropriately for the final output SNR $\text{SNR}_{\text{T}} \rightarrow \text{SNR}_{\text{a}}$. The minimum precision criterion (MPC) is proposed to minimize the ADC precision. Three in-memory compute models - charge summing (QS), current summing (IS) and charge redistribution (QR) - are shown to underlie most known IMCs. Noise, energy and delay expressions for the compute models are developed and employed to derive expressions for the SNR, ADC precision, energy, and latency of IMCs. The compute SNR expressions are validated via Monte Carlo simulations in a 65 nm CMOS process. For a 512 row SRAM array, it is shown that: 1) IMCs have an upper bound on their maximum achievable $\text{SNR}_{\text{a}}$ due to constraints on energy, area and voltage swing, and this upper bound reduces with technology scaling for QS-based architectures; 2) MPC enables $\text{SNR}_{\text{T}} \rightarrow \text{SNR}_{\text{a}}$ to be realized with minimal ADC precision; 3) QS-based (QR-based) architectures are preferred for low (high) compute SNR scenarios.
HarDNN: Feature Map Vulnerability Evaluation in CNNs
Feb 25, 2020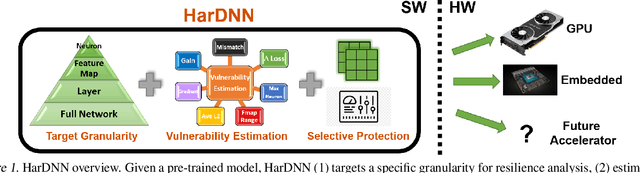
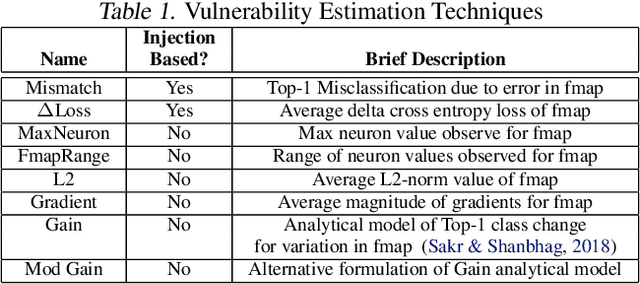
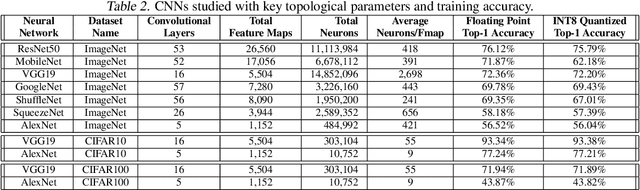
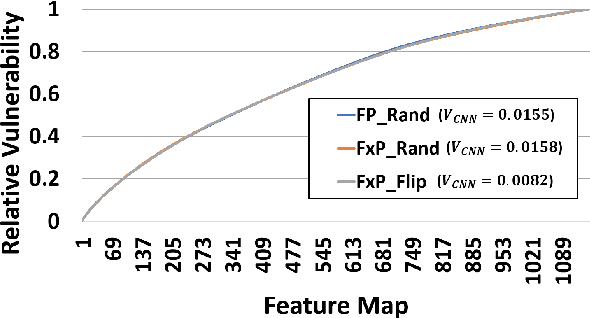
As Convolutional Neural Networks (CNNs) are increasingly being employed in safety-critical applications, it is important that they behave reliably in the face of hardware errors. Transient hardware errors may percolate undesirable state during execution, resulting in software-manifested errors which can adversely affect high-level decision making. This paper presents HarDNN, a software-directed approach to identify vulnerable computations during a CNN inference and selectively protect them based on their propensity towards corrupting the inference output in the presence of a hardware error. We show that HarDNN can accurately estimate relative vulnerability of a feature map (fmap) in CNNs using a statistical error injection campaign, and explore heuristics for fast vulnerability assessment. Based on these results, we analyze the tradeoff between error coverage and computational overhead that the system designers can use to employ selective protection. Results show that the improvement in resilience for the added computation is superlinear with HarDNN. For example, HarDNN improves SqueezeNet's resilience by 10x with just 30% additional computations.
Accumulation Bit-Width Scaling For Ultra-Low Precision Training Of Deep Networks
Jan 19, 2019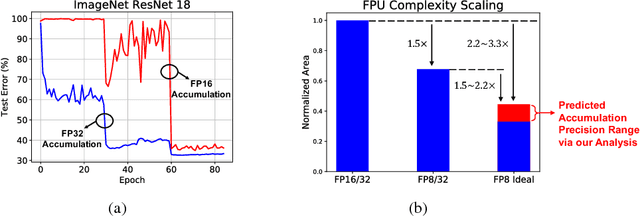
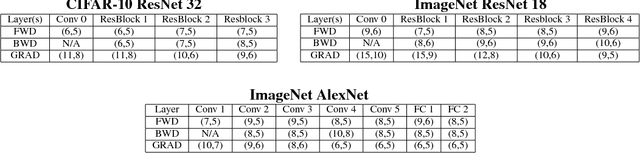
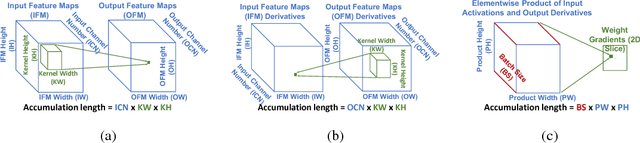
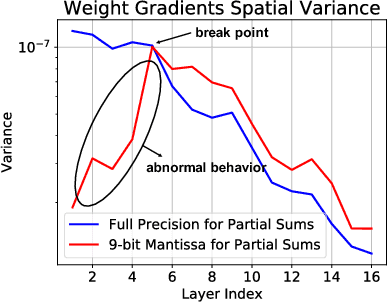
Efforts to reduce the numerical precision of computations in deep learning training have yielded systems that aggressively quantize weights and activations, yet employ wide high-precision accumulators for partial sums in inner-product operations to preserve the quality of convergence. The absence of any framework to analyze the precision requirements of partial sum accumulations results in conservative design choices. This imposes an upper-bound on the reduction of complexity of multiply-accumulate units. We present a statistical approach to analyze the impact of reduced accumulation precision on deep learning training. Observing that a bad choice for accumulation precision results in loss of information that manifests itself as a reduction in variance in an ensemble of partial sums, we derive a set of equations that relate this variance to the length of accumulation and the minimum number of bits needed for accumulation. We apply our analysis to three benchmark networks: CIFAR-10 ResNet 32, ImageNet ResNet 18 and ImageNet AlexNet. In each case, with accumulation precision set in accordance with our proposed equations, the networks successfully converge to the single precision floating-point baseline. We also show that reducing accumulation precision further degrades the quality of the trained network, proving that our equations produce tight bounds. Overall this analysis enables precise tailoring of computation hardware to the application, yielding area- and power-optimal systems.