 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDCMT: A Direct Entire-Space Causal Multi-Task Framework for Post-Click Conversion Estimation
Feb 13, 2023



In recommendation scenarios, there are two long-standing challenges, i.e., selection bias and data sparsity, which lead to a significant drop in prediction accuracy for both Click-Through Rate (CTR) and post-click Conversion Rate (CVR) tasks. To cope with these issues, existing works emphasize on leveraging Multi-Task Learning (MTL) frameworks (Category 1) or causal debiasing frameworks (Category 2) to incorporate more auxiliary data in the entire exposure/inference space D or debias the selection bias in the click/training space O. However, these two kinds of solutions cannot effectively address the not-missing-at-random problem and debias the selection bias in O to fit the inference in D. To fill the research gaps, we propose a Direct entire-space Causal Multi-Task framework, namely DCMT, for post-click conversion prediction in this paper. Specifically, inspired by users' decision process of conversion, we propose a new counterfactual mechanism to debias the selection bias in D, which can predict the factual CVR and the counterfactual CVR under the soft constraint of a counterfactual prior knowledge. Extensive experiments demonstrate that our DCMT can improve the state-of-the-art methods by an average of 1.07% in terms of CVR AUC on the five offline datasets and 0.75% in terms of PV-CVR on the online A/B test (the Alipay Search). Such improvements can increase millions of conversions per week in real industrial applications, e.g., the Alipay Search.
INCREASE: Inductive Graph Representation Learning for Spatio-Temporal Kriging
Feb 06, 2023Spatio-temporal kriging is an important problem in web and social applications, such as Web or Internet of Things, where things (e.g., sensors) connected into a web often come with spatial and temporal properties. It aims to infer knowledge for (the things at) unobserved locations using the data from (the things at) observed locations during a given time period of interest. This problem essentially requires \emph{inductive learning}. Once trained, the model should be able to perform kriging for different locations including newly given ones, without retraining. However, it is challenging to perform accurate kriging results because of the heterogeneous spatial relations and diverse temporal patterns. In this paper, we propose a novel inductive graph representation learning model for spatio-temporal kriging. We first encode heterogeneous spatial relations between the unobserved and observed locations by their spatial proximity, functional similarity, and transition probability. Based on each relation, we accurately aggregate the information of most correlated observed locations to produce inductive representations for the unobserved locations, by jointly modeling their similarities and differences. Then, we design relation-aware gated recurrent unit (GRU) networks to adaptively capture the temporal correlations in the generated sequence representations for each relation. Finally, we propose a multi-relation attention mechanism to dynamically fuse the complex spatio-temporal information at different time steps from multiple relations to compute the kriging output. Experimental results on three real-world datasets show that our proposed model outperforms state-of-the-art methods consistently, and the advantage is more significant when there are fewer observed locations. Our code is available at https://github.com/zhengchuanpan/INCREASE.
Heterogeneous Information Crossing on Graphs for Session-based Recommender Systems
Oct 24, 2022



Recommender systems are fundamental information filtering techniques to recommend content or items that meet users' personalities and potential needs. As a crucial solution to address the difficulty of user identification and unavailability of historical information, session-based recommender systems provide recommendation services that only rely on users' behaviors in the current session. However, most existing studies are not well-designed for modeling heterogeneous user behaviors and capturing the relationships between them in practical scenarios. To fill this gap, in this paper, we propose a novel graph-based method, namely Heterogeneous Information Crossing on Graphs (HICG). HICG utilizes multiple types of user behaviors in the sessions to construct heterogeneous graphs, and captures users' current interests with their long-term preferences by effectively crossing the heterogeneous information on the graphs. In addition, we also propose an enhanced version, named HICG-CL, which incorporates contrastive learning (CL) technique to enhance item representation ability. By utilizing the item co-occurrence relationships across different sessions, HICG-CL improves the recommendation performance of HICG. We conduct extensive experiments on three real-world recommendation datasets, and the results verify that (i) HICG achieves the state-of-the-art performance by utilizing multiple types of behaviors on the heterogeneous graph. (ii) HICG-CL further significantly improves the recommendation performance of HICG by the proposed contrastive learning module.
Making Split Learning Resilient to Label Leakage by Potential Energy Loss
Oct 18, 2022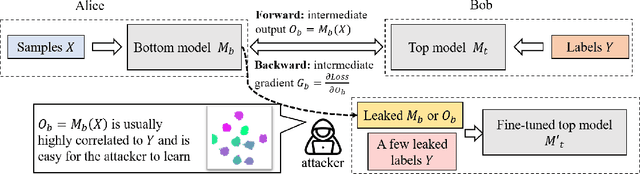
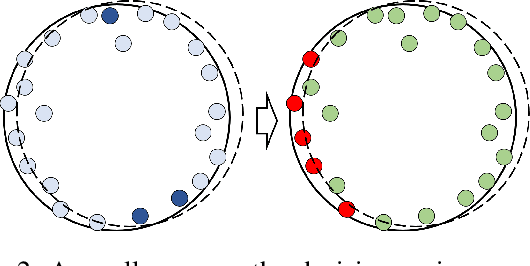
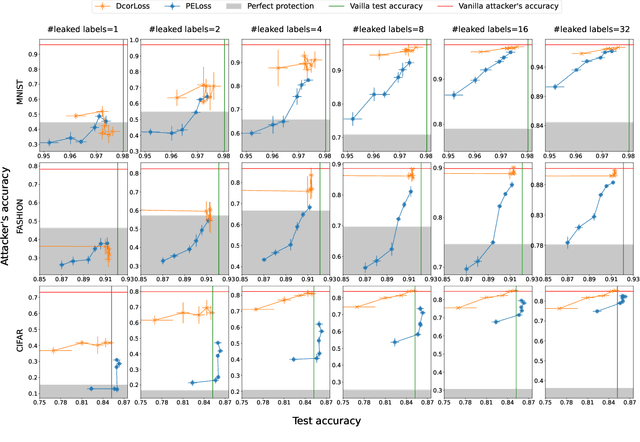
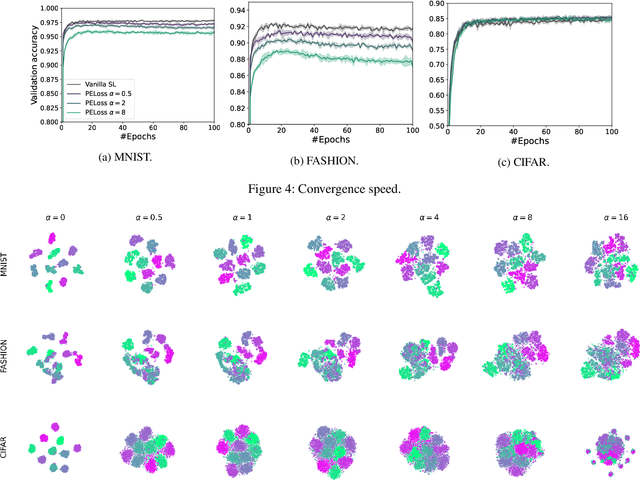
As a practical privacy-preserving learning method, split learning has drawn much attention in academia and industry. However, its security is constantly being questioned since the intermediate results are shared during training and inference. In this paper, we focus on the privacy leakage problem caused by the trained split model, i.e., the attacker can use a few labeled samples to fine-tune the bottom model, and gets quite good performance. To prevent such kind of privacy leakage, we propose the potential energy loss to make the output of the bottom model become a more `complicated' distribution, by pushing outputs of the same class towards the decision boundary. Therefore, the adversary suffers a large generalization error when fine-tuning the bottom model with only a few leaked labeled samples. Experiment results show that our method significantly lowers the attacker's fine-tuning accuracy, making the split model more resilient to label leakage.
DDGHM: Dual Dynamic Graph with Hybrid Metric Training for Cross-Domain Sequential Recommendation
Sep 21, 2022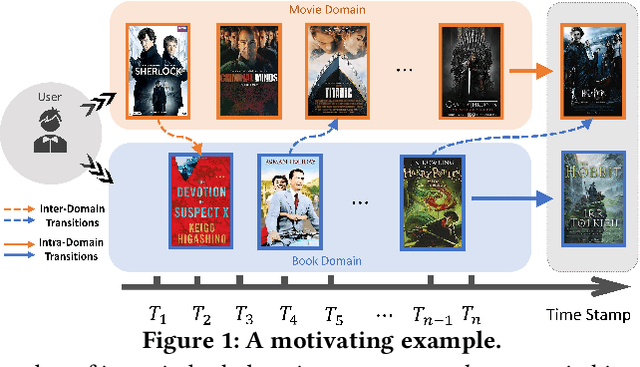
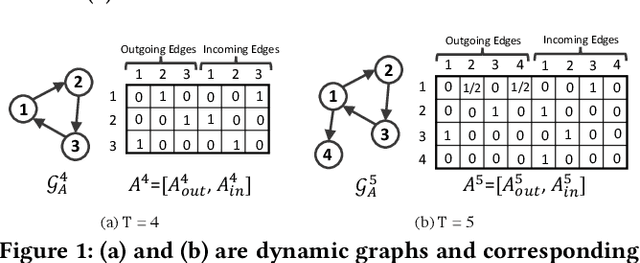
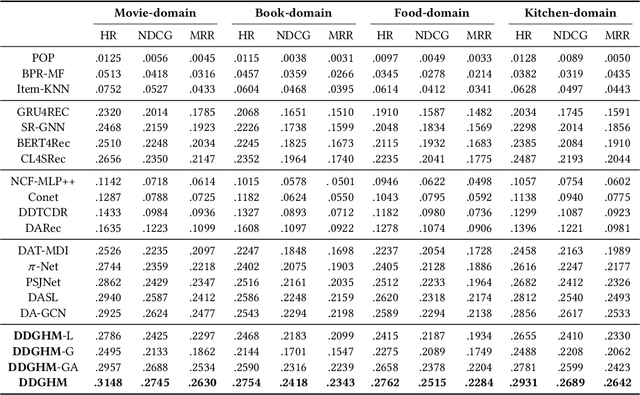
Sequential Recommendation (SR) characterizes evolving patterns of user behaviors by modeling how users transit among items. However, the short interaction sequences limit the performance of existing SR. To solve this problem, we focus on Cross-Domain Sequential Recommendation (CDSR) in this paper, which aims to leverage information from other domains to improve the sequential recommendation performance of a single domain. Solving CDSR is challenging. On the one hand, how to retain single domain preferences as well as integrate cross-domain influence remains an essential problem. On the other hand, the data sparsity problem cannot be totally solved by simply utilizing knowledge from other domains, due to the limited length of the merged sequences. To address the challenges, we propose DDGHM, a novel framework for the CDSR problem, which includes two main modules, i.e., dual dynamic graph modeling and hybrid metric training. The former captures intra-domain and inter-domain sequential transitions through dynamically constructing two-level graphs, i.e., the local graphs and the global graph, and incorporating them with a fuse attentive gating mechanism. The latter enhances user and item representations by employing hybrid metric learning, including collaborative metric for achieving alignment and contrastive metric for preserving uniformity, to further alleviate data sparsity issue and improve prediction accuracy. We conduct experiments on two benchmark datasets and the results demonstrate the effectiveness of DDHMG.
Cross-Network Social User Embedding with Hybrid Differential Privacy Guarantees
Sep 04, 2022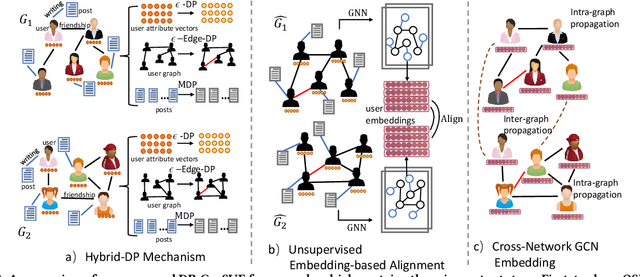

Integrating multiple online social networks (OSNs) has important implications for many downstream social mining tasks, such as user preference modelling, recommendation, and link prediction. However, it is unfortunately accompanied by growing privacy concerns about leaking sensitive user information. How to fully utilize the data from different online social networks while preserving user privacy remains largely unsolved. To this end, we propose a Cross-network Social User Embedding framework, namely DP-CroSUE, to learn the comprehensive representations of users in a privacy-preserving way. We jointly consider information from partially aligned social networks with differential privacy guarantees. In particular, for each heterogeneous social network, we first introduce a hybrid differential privacy notion to capture the variation of privacy expectations for heterogeneous data types. Next, to find user linkages across social networks, we make unsupervised user embedding-based alignment in which the user embeddings are achieved by the heterogeneous network embedding technology. To further enhance user embeddings, a novel cross-network GCN embedding model is designed to transfer knowledge across networks through those aligned users. Extensive experiments on three real-world datasets demonstrate that our approach makes a significant improvement on user interest prediction tasks as well as defending user attribute inference attacks from embedding.
Scalable and Sparsity-Aware Privacy-Preserving K-means Clustering with Application to Fraud Detection
Aug 12, 2022
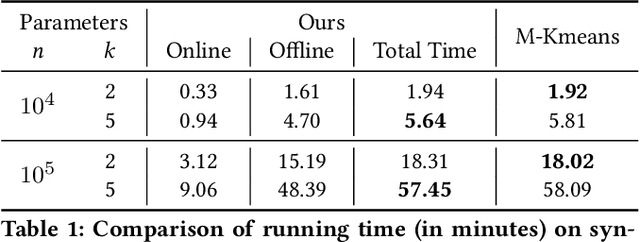
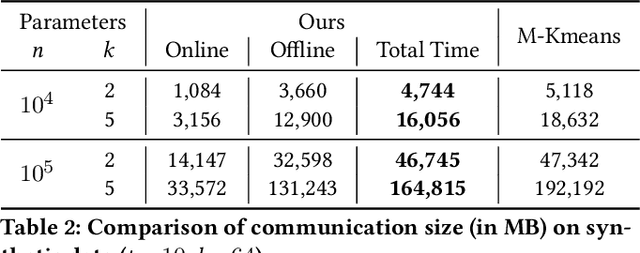
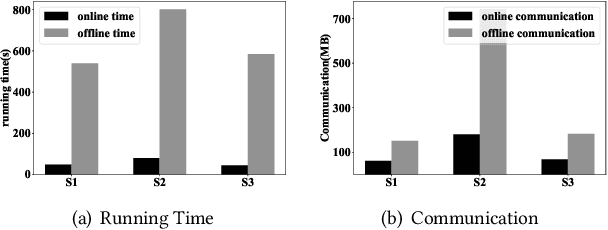
K-means is one of the most widely used clustering models in practice. Due to the problem of data isolation and the requirement for high model performance, how to jointly build practical and secure K-means for multiple parties has become an important topic for many applications in the industry. Existing work on this is mainly of two types. The first type has efficiency advantages, but information leakage raises potential privacy risks. The second type is provable secure but is inefficient and even helpless for the large-scale data sparsity scenario. In this paper, we propose a new framework for efficient sparsity-aware K-means with three characteristics. First, our framework is divided into a data-independent offline phase and a much faster online phase, and the offline phase allows to pre-compute almost all cryptographic operations. Second, we take advantage of the vectorization techniques in both online and offline phases. Third, we adopt a sparse matrix multiplication for the data sparsity scenario to improve efficiency further. We conduct comprehensive experiments on three synthetic datasets and deploy our model in a real-world fraud detection task. Our experimental results show that, compared with the state-of-the-art solution, our model achieves competitive performance in terms of both running time and communication size, especially on sparse datasets.
HCFRec: Hash Collaborative Filtering via Normalized Flow with Structural Consensus for Efficient Recommendation
May 24, 2022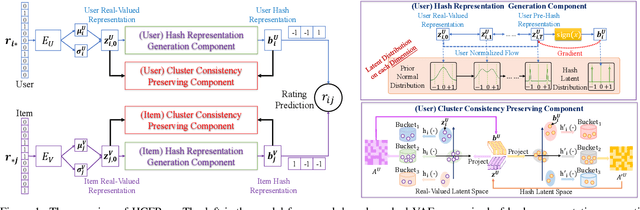
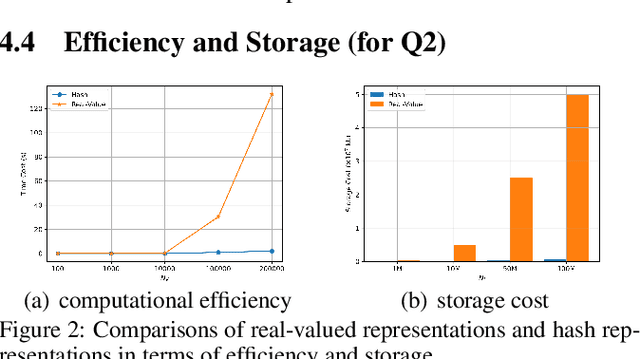
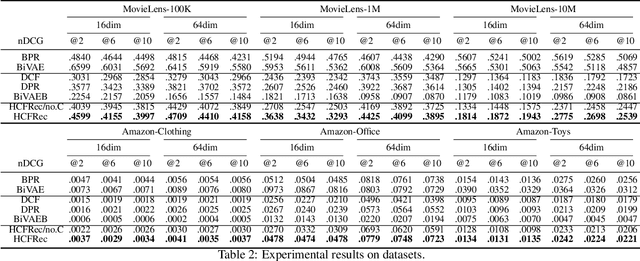
The ever-increasing data scale of user-item interactions makes it challenging for an effective and efficient recommender system. Recently, hash-based collaborative filtering (Hash-CF) approaches employ efficient Hamming distance of learned binary representations of users and items to accelerate recommendations. However, Hash-CF often faces two challenging problems, i.e., optimization on discrete representations and preserving semantic information in learned representations. To address the above two challenges, we propose HCFRec, a novel Hash-CF approach for effective and efficient recommendations. Specifically, HCFRec not only innovatively introduces normalized flow to learn the optimal hash code by efficiently fit a proposed approximate mixture multivariate normal distribution, a continuous but approximately discrete distribution, but also deploys a cluster consistency preserving mechanism to preserve the semantic structure in representations for more accurate recommendations. Extensive experiments conducted on six real-world datasets demonstrate the superiority of our HCFRec compared to the state-of-art methods in terms of effectiveness and efficiency.
Exploiting Variational Domain-Invariant User Embedding for Partially Overlapped Cross Domain Recommendation
May 13, 2022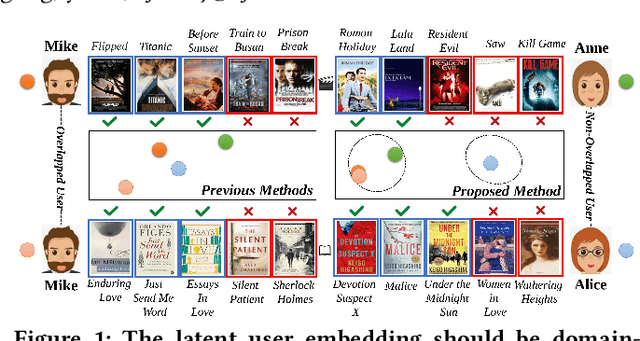
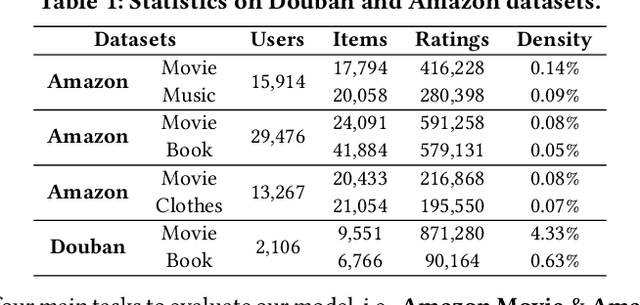
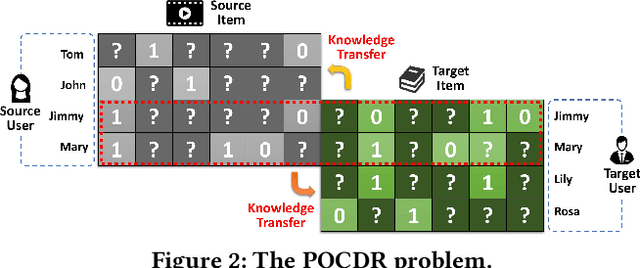
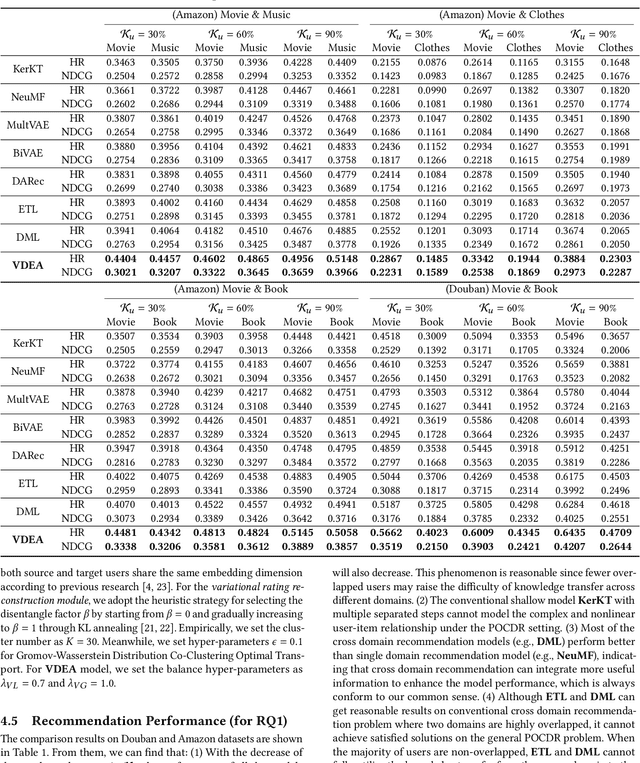
Cross-Domain Recommendation (CDR) has been popularly studied to utilize different domain knowledge to solve the cold-start problem in recommender systems. Most of the existing CDR models assume that both the source and target domains share the same overlapped user set for knowledge transfer. However, only few proportion of users simultaneously activate on both the source and target domains in practical CDR tasks. In this paper, we focus on the Partially Overlapped Cross-Domain Recommendation (POCDR) problem, that is, how to leverage the information of both the overlapped and non-overlapped users to improve recommendation performance. Existing approaches cannot fully utilize the useful knowledge behind the non-overlapped users across domains, which limits the model performance when the majority of users turn out to be non-overlapped. To address this issue, we propose an end-to-end dual-autoencoder with Variational Domain-invariant Embedding Alignment (VDEA) model, a cross-domain recommendation framework for the POCDR problem, which utilizes dual variational autoencoders with both local and global embedding alignment for exploiting domain-invariant user embedding. VDEA first adopts variational inference to capture collaborative user preferences, and then utilizes Gromov-Wasserstein distribution co-clustering optimal transport to cluster the users with similar rating interaction behaviors. Our empirical studies on Douban and Amazon datasets demonstrate that VDEA significantly outperforms the state-of-the-art models, especially under the POCDR setting.
Making Recommender Systems Forget: Learning and Unlearning for Erasable Recommendation
Mar 22, 2022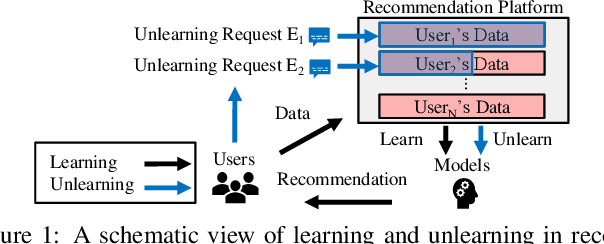

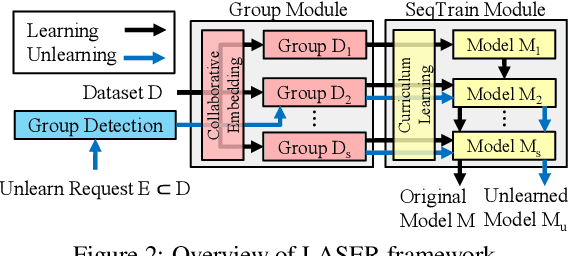
Privacy laws and regulations enforce data-driven systems, e.g., recommender systems, to erase the data that concern individuals. As machine learning models potentially memorize the training data, data erasure should also unlearn the data lineage in models, which raises increasing interest in the problem of Machine Unlearning (MU). However, existing MU methods cannot be directly applied into recommendation. The basic idea of most recommender systems is collaborative filtering, but existing MU methods ignore the collaborative information across users and items. In this paper, we propose a general erasable recommendation framework, namely LASER, which consists of Group module and SeqTrain module. Firstly, Group module partitions users into balanced groups based on their similarity of collaborative embedding learned via hypergraph. Then SeqTrain module trains the model sequentially on all groups with curriculum learning. Both theoretical analysis and experiments on two real-world datasets demonstrate that LASER can not only achieve efficient unlearning, but also outperform the state-of-the-art unlearning framework in terms of model utility.