 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBOP Challenge 2020 on 6D Object Localization
Oct 13, 2020
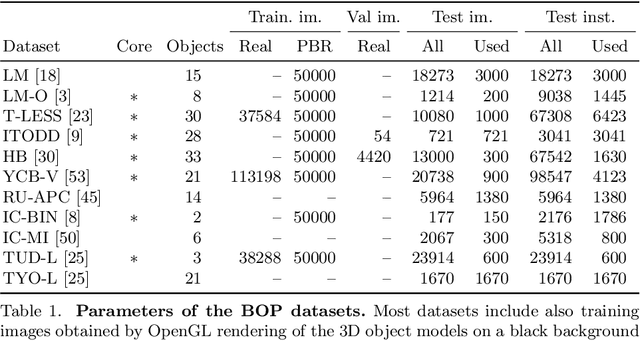

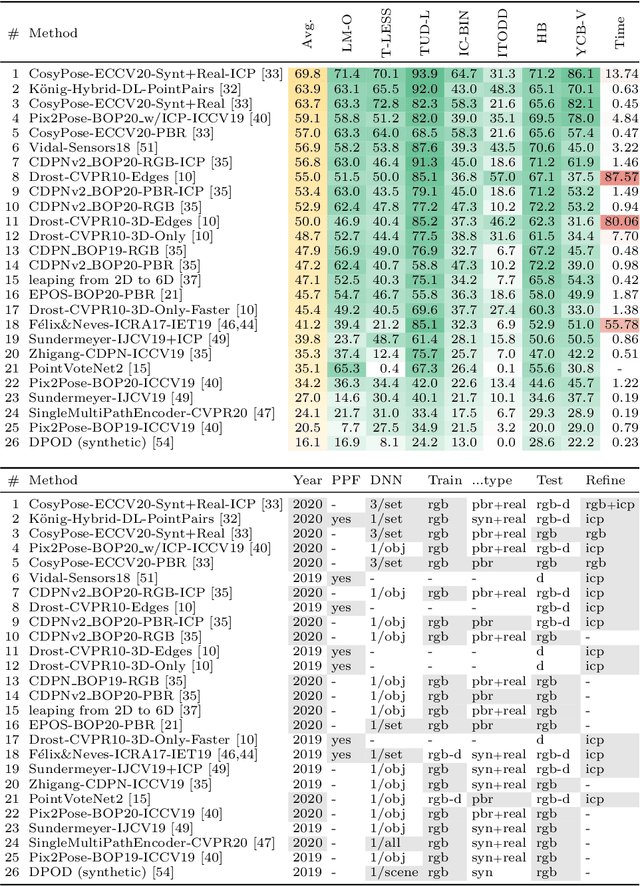
This paper presents the evaluation methodology, datasets, and results of the BOP Challenge 2020, the third in a series of public competitions organized with the goal to capture the status quo in the field of 6D object pose estimation from an RGB-D image. In 2020, to reduce the domain gap between synthetic training and real test RGB images, the participants were provided 350K photorealistic training images generated by BlenderProc4BOP, a new open-source and light-weight physically-based renderer (PBR) and procedural data generator. Methods based on deep neural networks have finally caught up with methods based on point pair features, which were dominating previous editions of the challenge. Although the top-performing methods rely on RGB-D image channels, strong results were achieved when only RGB channels were used at both training and test time - out of the 26 evaluated methods, the third method was trained on RGB channels of PBR and real images, while the fifth on RGB channels of PBR images only. Strong data augmentation was identified as a key component of the top-performing CosyPose method, and the photorealism of PBR images was demonstrated effective despite the augmentation. The online evaluation system stays open and is available on the project website: bop.felk.cvut.cz.
Increasing the Robustness of Semantic Segmentation Models with Painting-by-Numbers
Oct 12, 2020
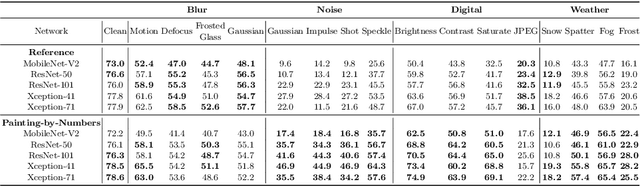

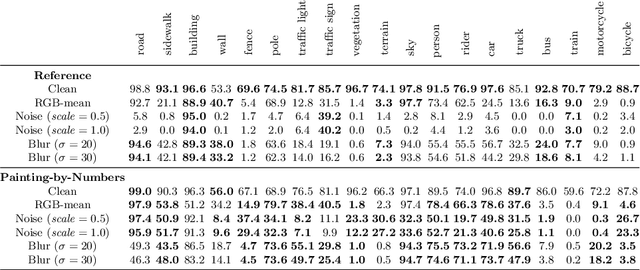
For safety-critical applications such as autonomous driving, CNNs have to be robust with respect to unavoidable image corruptions, such as image noise. While previous works addressed the task of robust prediction in the context of full-image classification, we consider it for dense semantic segmentation. We build upon an insight from image classification that output robustness can be improved by increasing the network-bias towards object shapes. We present a new training schema that increases this shape bias. Our basic idea is to alpha-blend a portion of the RGB training images with faked images, where each class-label is given a fixed, randomly chosen color that is not likely to appear in real imagery. This forces the network to rely more strongly on shape cues. We call this data augmentation technique ``Painting-by-Numbers''. We demonstrate the effectiveness of our training schema for DeepLabv3+ with various network backbones, MobileNet-V2, ResNets, and Xception, and evaluate it on the Cityscapes dataset. With respect to our 16 different types of image corruptions and 5 different network backbones, we are in 74% better than training with clean data. For cases where we are worse than a model trained without our training schema, it is mostly only marginally worse. However, for some image corruptions such as images with noise, we see a considerable performance gain of up to 25%.
Generative Classifiers as a Basis for Trustworthy Computer Vision
Jul 29, 2020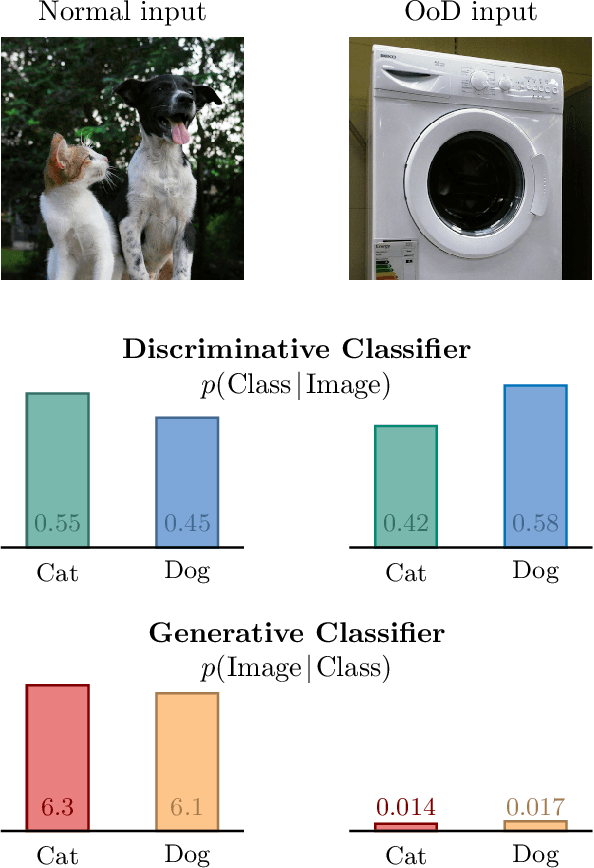
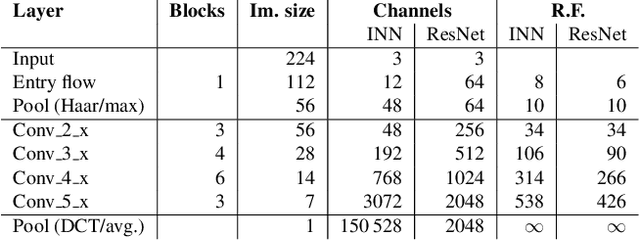
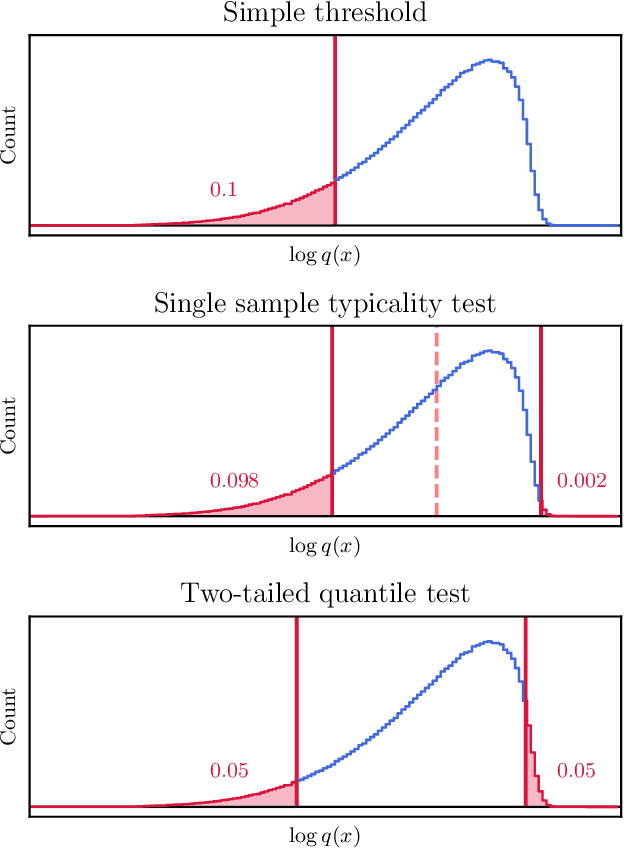
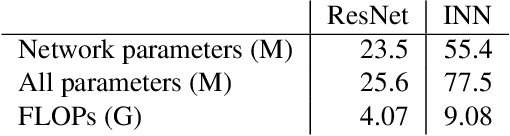
With the maturing of deep learning systems, trustworthiness is becoming increasingly important for model assessment. We understand trustworthiness as the combination of explainability and robustness. Generative classifiers (GCs) are a promising class of models that are said to naturally accomplish these qualities. However, this has mostly been demonstrated on simple datasets such as MNIST, SVHN and CIFAR in the past. In this work, we firstly develop an architecture and training scheme that allows for GCs to be trained on the ImageNet classification task, a more relevant level of complexity for practical computer vision. The resulting models use an invertible neural network architecture and achieve a competetive ImageNet top-1 accuracy of up to 76.2%. Secondly, we show the large potential of GCs for trustworthiness. Explainability and some aspects of robustness are vastly improved compared to standard feed-forward models, even when the GCs are just applied naively. While not all trustworthiness problems are solved completely, we argue from our observations that GCs are an extremely promising basis for further algorithms and modifications, as have been developed in the past for feedforward models to increase their trustworthiness. We release our trained model for download in the hope that it serves as a starting point for various other generative classification tasks in much the same way as pretrained ResNet models do for discriminative classification.
Intrinsic Autoencoders for Joint Neural Rendering and Intrinsic Image Decomposition
Jul 01, 2020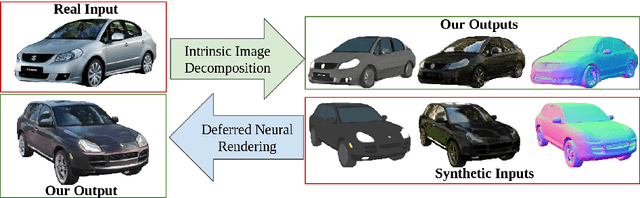

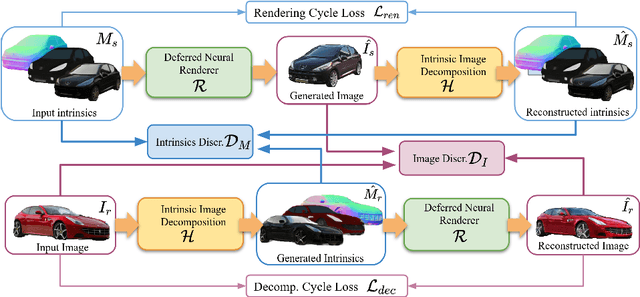
Neural rendering techniques promise efficient photo-realistic image synthesis while at the same time providing rich control over scene parameters by learning the physical image formation process. While several supervised methods have been proposed for this task, acquiring a dataset of images with accurately aligned 3D models is very difficult. The main contribution of this work is to lift this restriction by training a neural rendering algorithm from unpaired data. More specifically, we propose an autoencoder for joint generation of realistic images from synthetic 3D models while simultaneously decomposing real images into their intrinsic shape and appearance properties. In contrast to a traditional graphics pipeline, our approach does not require to specify all scene properties, such as material parameters and lighting by hand. Instead, we learn photo-realistic deferred rendering from a small set of 3D models and a larger set of unaligned real images, both of which are easy to acquire in practice. Simultaneously, we obtain accurate intrinsic decompositions of real images while not requiring paired ground truth. Our experiments confirm that a joint treatment of rendering and decomposition is indeed beneficial and that our approach outperforms state-of-the-art image-to-image translation baselines both qualitatively and quantitatively.
Split-Merge Pooling
Jun 13, 2020



There are a variety of approaches to obtain a vast receptive field with convolutional neural networks (CNNs), such as pooling or striding convolutions. Most of these approaches were initially designed for image classification and later adapted to dense prediction tasks, such as semantic segmentation. However, the major drawback of this adaptation is the loss of spatial information. Even the popular dilated convolution approach, which in theory is able to operate with full spatial resolution, needs to subsample features for large image sizes in order to make the training and inference tractable. In this work, we introduce Split-Merge pooling to fully preserve the spatial information without any subsampling. By applying Split-Merge pooling to deep networks, we achieve, at the same time, a very large receptive field. We evaluate our approach for dense semantic segmentation of large image sizes taken from the Cityscapes and GTA-5 datasets. We demonstrate that by replacing max-pooling and striding convolutions with our split-merge pooling, we are able to improve the accuracy of different variations of ResNet significantly.
MPLP++: Fast, Parallel Dual Block-Coordinate Ascent for Dense Graphical Models
Apr 16, 2020
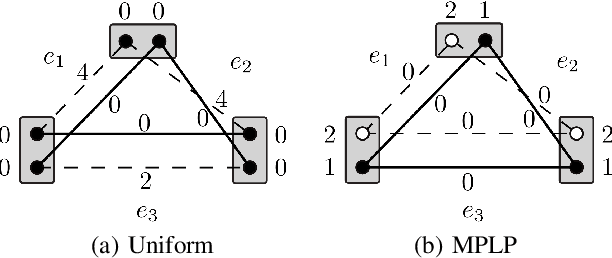
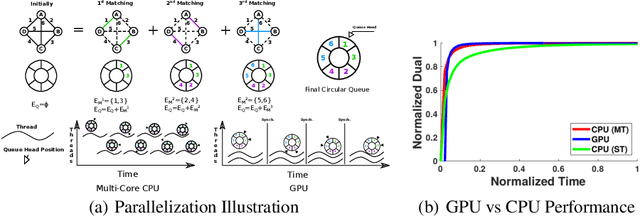
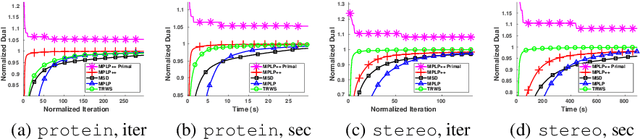
Dense, discrete Graphical Models with pairwise potentials are a powerful class of models which are employed in state-of-the-art computer vision and bio-imaging applications. This work introduces a new MAP-solver, based on the popular Dual Block-Coordinate Ascent principle. Surprisingly, by making a small change to the low-performing solver, the Max Product Linear Programming (MPLP) algorithm, we derive the new solver MPLP++ that significantly outperforms all existing solvers by a large margin, including the state-of-the-art solver Tree-Reweighted Sequential (TRWS) message-passing algorithm. Additionally, our solver is highly parallel, in contrast to TRWS, which gives a further boost in performance with the proposed GPU and multi-thread CPU implementations. We verify the superiority of our algorithm on dense problems from publicly available benchmarks, as well, as a new benchmark for 6D Object Pose estimation. We also provide an ablation study with respect to graph density.
Taxonomy of Dual Block-Coordinate Ascent Methods for Discrete Energy Minimization
Apr 16, 2020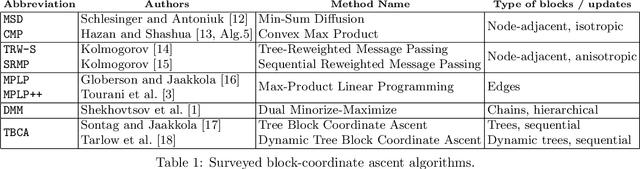
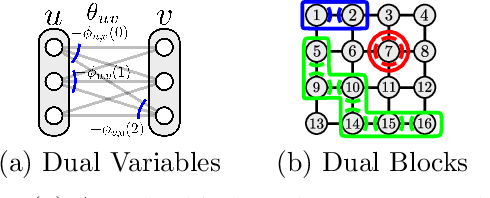
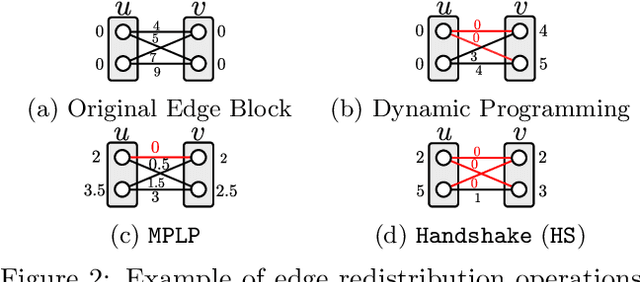
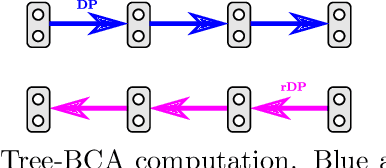
We consider the maximum-a-posteriori inference problem in discrete graphical models and study solvers based on the dual block-coordinate ascent rule. We map all existing solvers in a single framework, allowing for a better understanding of their design principles. We theoretically show that some block-optimizing updates are sub-optimal and how to strictly improve them. On a wide range of problem instances of varying graph connectivity, we study the performance of existing solvers as well as new variants that can be obtained within the framework. As a result of this exploration we build a new state-of-the art solver, performing uniformly better on the whole range of test instances.
A Primal-Dual Solver for Large-Scale Tracking-by-Assignment
Apr 14, 2020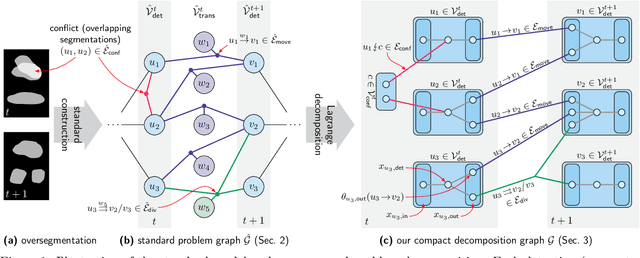
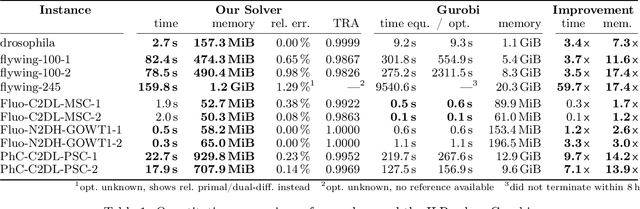
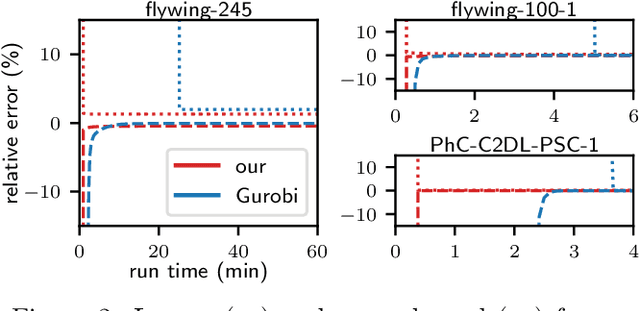
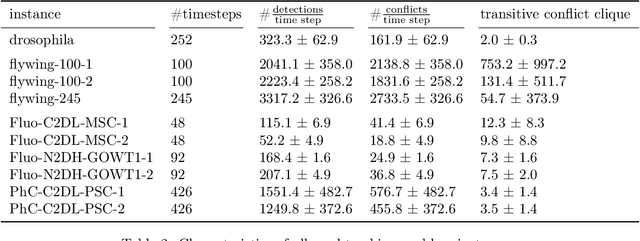
We propose a fast approximate solver for the combinatorial problem known as tracking-by-assignment, which we apply to cell tracking. The latter plays a key role in discovery in many life sciences, especially in cell and developmental biology. So far, in the most general setting this problem was addressed by off-the-shelf solvers like Gurobi, whose run time and memory requirements rapidly grow with the size of the input. In contrast, for our method this growth is nearly linear. Our contribution consists of a new (1) decomposable compact representation of the problem; (2) dual block-coordinate ascent method for optimizing the decomposition-based dual; and (3) primal heuristics that reconstructs a feasible integer solution based on the dual information. Compared to solving the problem with Gurobi, we observe an up to~60~times speed-up, while reducing the memory footprint significantly. We demonstrate the efficacy of our method on real-world tracking problems.
Self-Supervised Viewpoint Learning From Image Collections
Apr 03, 2020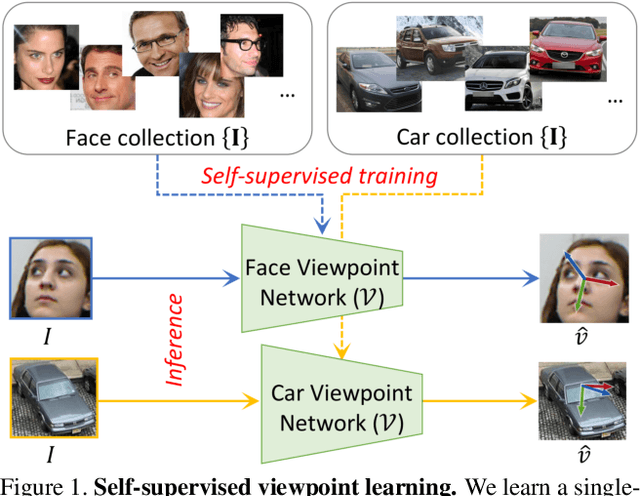
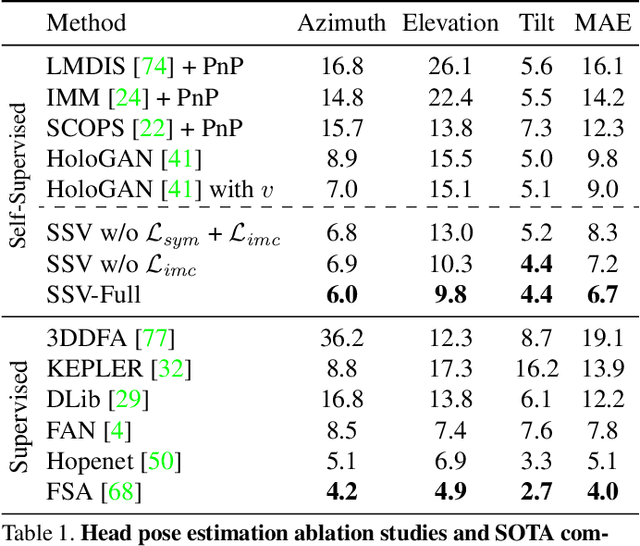
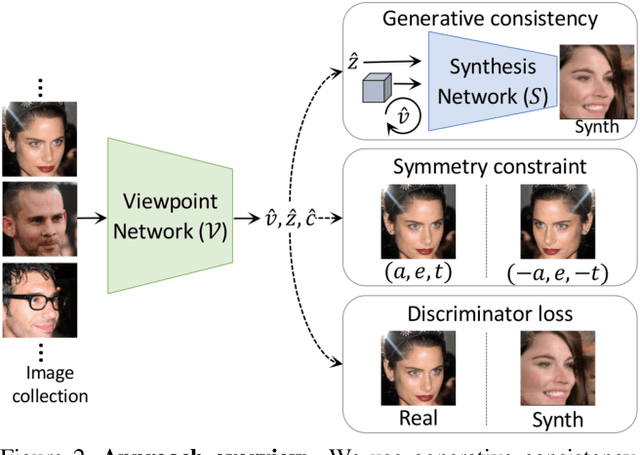
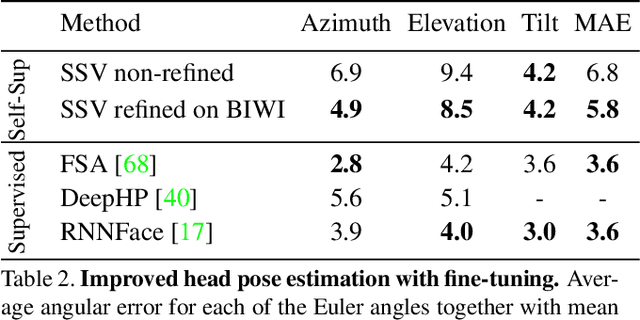
Training deep neural networks to estimate the viewpoint of objects requires large labeled training datasets. However, manually labeling viewpoints is notoriously hard, error-prone, and time-consuming. On the other hand, it is relatively easy to mine many unlabelled images of an object category from the internet, e.g., of cars or faces. We seek to answer the research question of whether such unlabeled collections of in-the-wild images can be successfully utilized to train viewpoint estimation networks for general object categories purely via self-supervision. Self-supervision here refers to the fact that the only true supervisory signal that the network has is the input image itself. We propose a novel learning framework which incorporates an analysis-by-synthesis paradigm to reconstruct images in a viewpoint aware manner with a generative network, along with symmetry and adversarial constraints to successfully supervise our viewpoint estimation network. We show that our approach performs competitively to fully-supervised approaches for several object categories like human faces, cars, buses, and trains. Our work opens up further research in self-supervised viewpoint learning and serves as a robust baseline for it. We open-source our code at https://github.com/NVlabs/SSV.
Visual Camera Re-Localization from RGB and RGB-D Images Using DSAC
Feb 27, 2020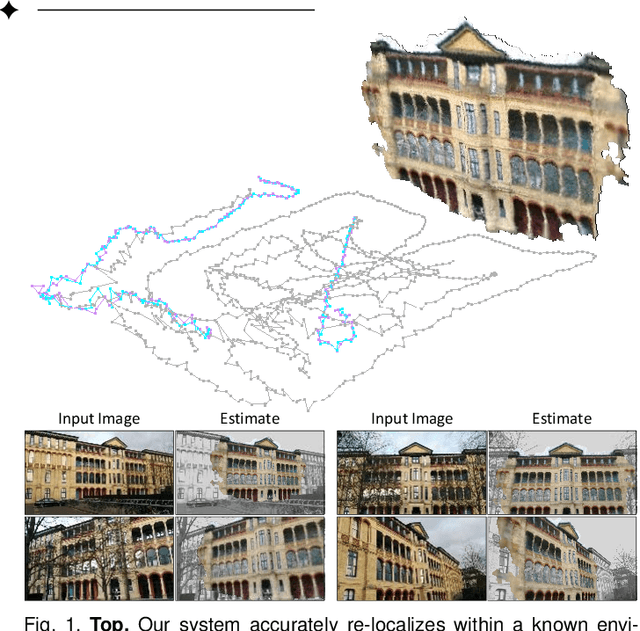

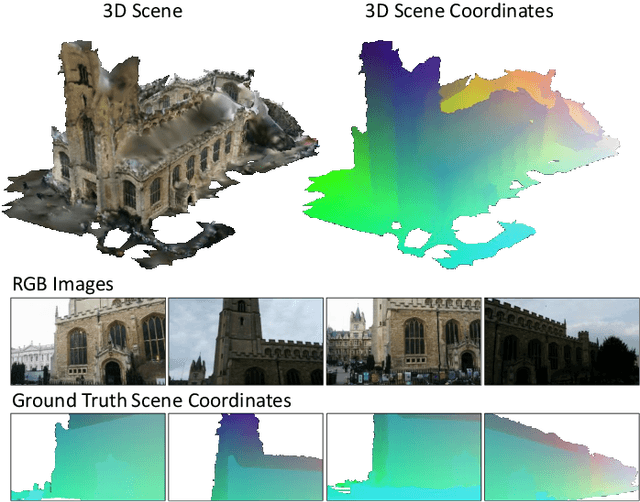
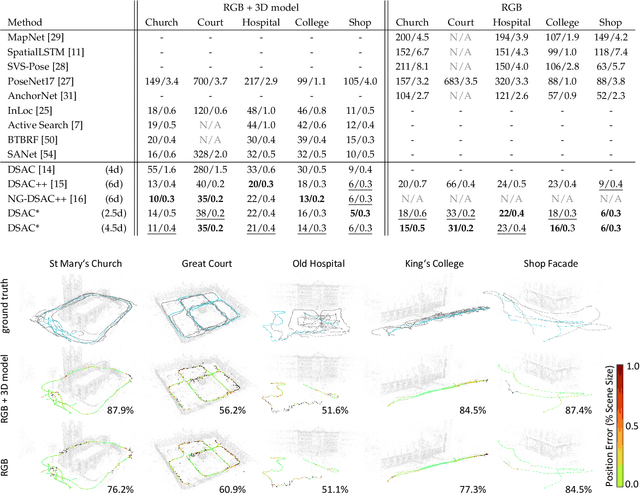
We describe a learning-based system that estimates the camera position and orientation from a single input image relative to a known environment. The system is flexible w.r.t. the amount of information available at test and at training time, catering to different applications. Input images can be RGB-D or RGB, and a 3D model of the environment can be utilized for training but is not necessary. In the minimal case, our system requires only RGB images and ground truth poses at training time, and it requires only a single RGB image at test time. The framework consists of a deep neural network and fully differentiable pose optimization. The neural network predicts so called scene coordinates, i.e. dense correspondences between the input image and 3D scene space of the environment. The pose optimization implements robust fitting of pose parameters using differentiable RANSAC (DSAC) to facilitate end-to-end training. The system, an extension of DSAC++ and referred to as DSAC*, achieves state-of-the-art accuracy an various public datasets for RGB-based re-localization, and competitive accuracy for RGB-D based re-localization.