 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData-Efficient Image Recognition with Contrastive Predictive Coding
May 22, 2019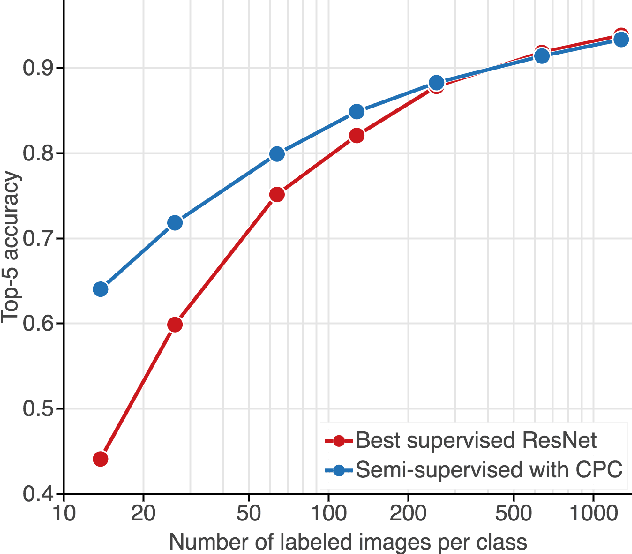
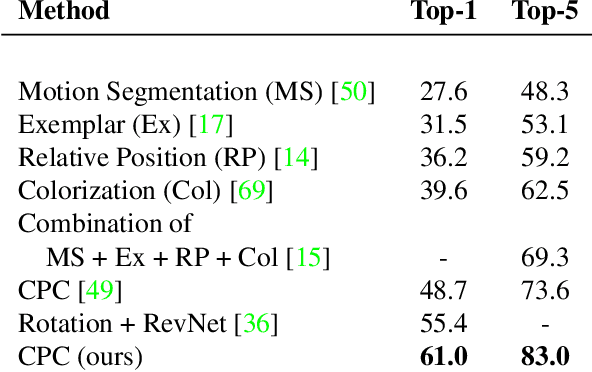
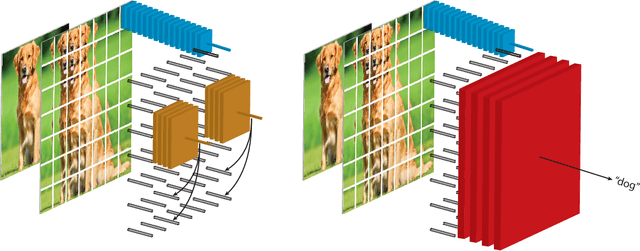
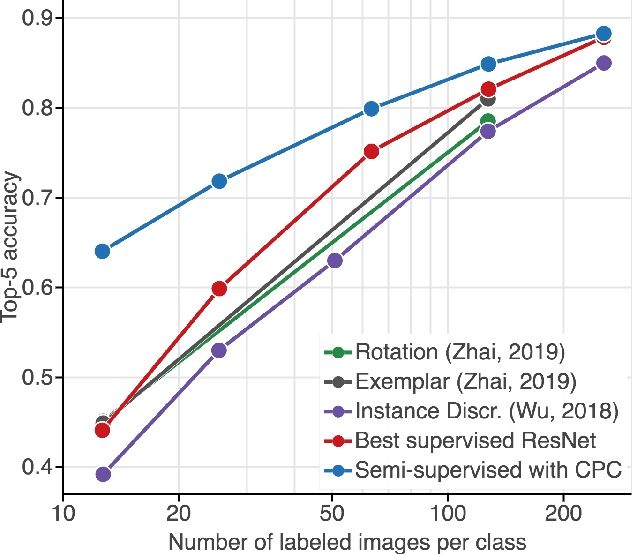
Large scale deep learning excels when labeled images are abundant, yet data-efficient learning remains a longstanding challenge. While biological vision is thought to leverage vast amounts of unlabeled data to solve classification problems with limited supervision, computer vision has so far not succeeded in this `semi-supervised' regime. Our work tackles this challenge with Contrastive Predictive Coding, an unsupervised objective which extracts stable structure from still images. The result is a representation which, equipped with a simple linear classifier, separates ImageNet categories better than all competing methods, and surpasses the performance of a fully-supervised AlexNet model. When given a small number of labeled images (as few as 13 per class), this representation retains a strong classification performance, outperforming state-of-the-art semi-supervised methods by 10% Top-5 accuracy and supervised methods by 20%. Finally, we find our unsupervised representation to serve as a useful substrate for image detection on the PASCAL-VOC 2007 dataset, approaching the performance of representations trained with a fully annotated ImageNet dataset. We expect these results to open the door to pipelines that use scalable unsupervised representations as a drop-in replacement for supervised ones for real-world vision tasks where labels are scarce.
Structured agents for physical construction
May 13, 2019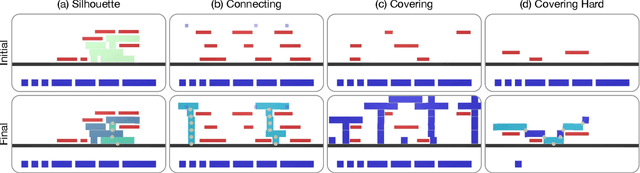
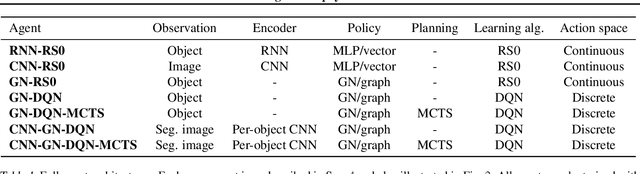
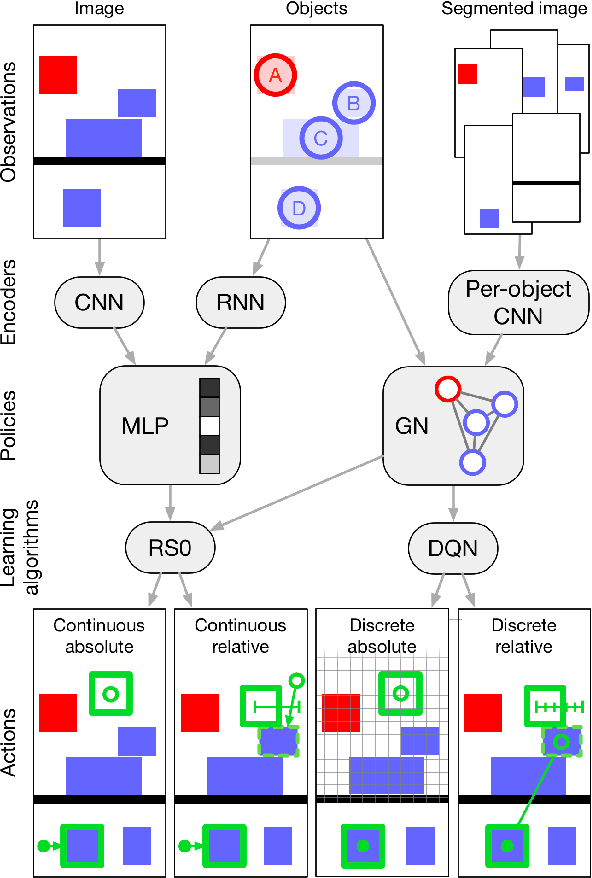
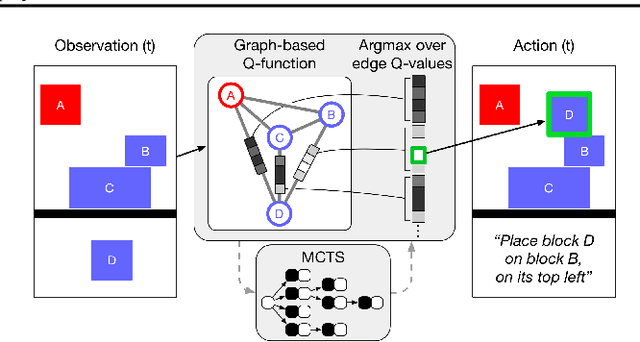
Physical construction---the ability to compose objects, subject to physical dynamics, to serve some function---is fundamental to human intelligence. We introduce a suite of challenging physical construction tasks inspired by how children play with blocks, such as matching a target configuration, stacking blocks to connect objects together, and creating shelter-like structures over target objects. We examine how a range of deep reinforcement learning agents fare on these challenges, and introduce several new approaches which provide superior performance. Our results show that agents which use structured representations (e.g., objects and scene graphs) and structured policies (e.g., object-centric actions) outperform those which use less structured representations, and generalize better beyond their training when asked to reason about larger scenes. Model-based agents which use Monte-Carlo Tree Search also outperform strictly model-free agents in our most challenging construction problems. We conclude that approaches which combine structured representations and reasoning with powerful learning are a key path toward agents that possess rich intuitive physics, scene understanding, and planning.
Exploiting temporal context for 3D human pose estimation in the wild
May 10, 2019
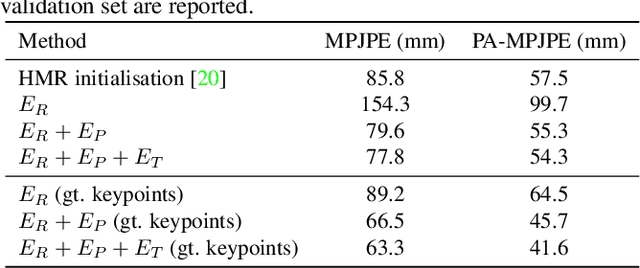
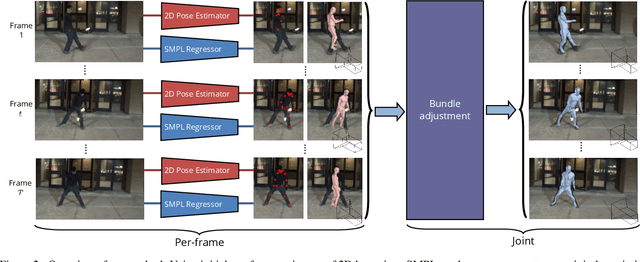
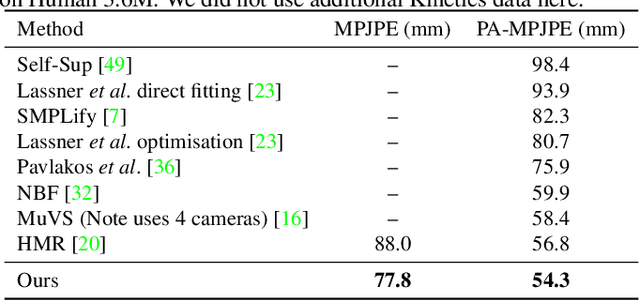
We present a bundle-adjustment-based algorithm for recovering accurate 3D human pose and meshes from monocular videos. Unlike previous algorithms which operate on single frames, we show that reconstructing a person over an entire sequence gives extra constraints that can resolve ambiguities. This is because videos often give multiple views of a person, yet the overall body shape does not change and 3D positions vary slowly. Our method improves not only on standard mocap-based datasets like Human 3.6M -- where we show quantitative improvements -- but also on challenging in-the-wild datasets such as Kinetics. Building upon our algorithm, we present a new dataset of more than 3 million frames of YouTube videos from Kinetics with automatically generated 3D poses and meshes. We show that retraining a single-frame 3D pose estimator on this data improves accuracy on both real-world and mocap data by evaluating on the 3DPW and HumanEVA datasets.
Video Action Transformer Network
Dec 06, 2018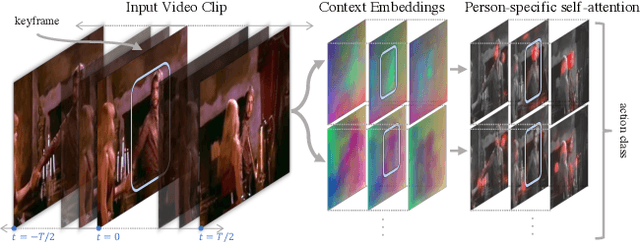
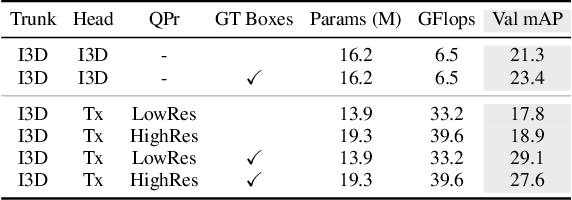
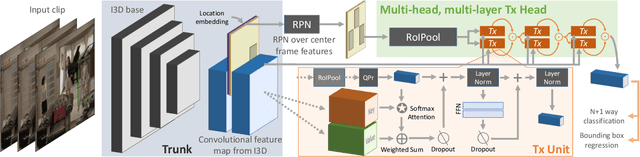

We introduce the Action Transformer model for recognizing and localizing human actions in video clips. We repurpose a Transformer-style architecture to aggregate features from the spatiotemporal context around the person whose actions we are trying to classify. We show that by using high-resolution, person-specific, class-agnostic queries, the model spontaneously learns to track individual people and to pick up on semantic context from the actions of others. Additionally its attention mechanism learns to emphasize hands and faces, which are often crucial to discriminate an action - all without explicit supervision other than boxes and class labels. We train and test our Action Transformer network on the Atomic Visual Actions (AVA) dataset, outperforming the state-of-the-art by a significant margin - more than 7.5% absolute (40% relative) improvement, using only raw RGB frames as input.
The Visual QA Devil in the Details: The Impact of Early Fusion and Batch Norm on CLEVR
Sep 11, 2018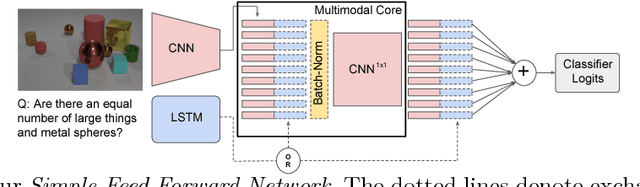
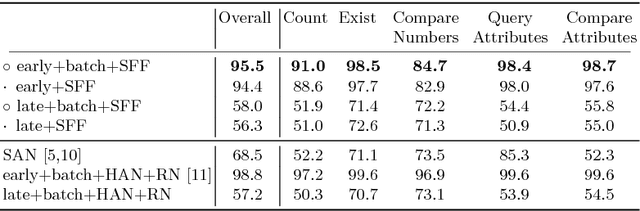
Visual QA is a pivotal challenge for higher-level reasoning, requiring understanding language, vision, and relationships between many objects in a scene. Although datasets like CLEVR are designed to be unsolvable without such complex relational reasoning, some surprisingly simple feed-forward, "holistic" models have recently shown strong performance on this dataset. These models lack any kind of explicit iterative, symbolic reasoning procedure, which are hypothesized to be necessary for counting objects, narrowing down the set of relevant objects based on several attributes, etc. The reason for this strong performance is poorly understood. Hence, our work analyzes such models, and finds that minor architectural elements are crucial to performance. In particular, we find that \textit{early fusion} of language and vision provides large performance improvements. This contrasts with the late fusion approaches popular at the dawn of Visual QA. We propose a simple module we call Multimodal Core, which we hypothesize performs the fundamental operations for multimodal tasks. We believe that understanding why these elements are so important to complex question answering will aid the design of better-performing algorithms for Visual QA while minimizing hand-engineering effort.
Learning Visual Question Answering by Bootstrapping Hard Attention
Aug 01, 2018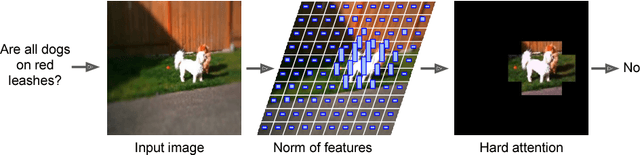
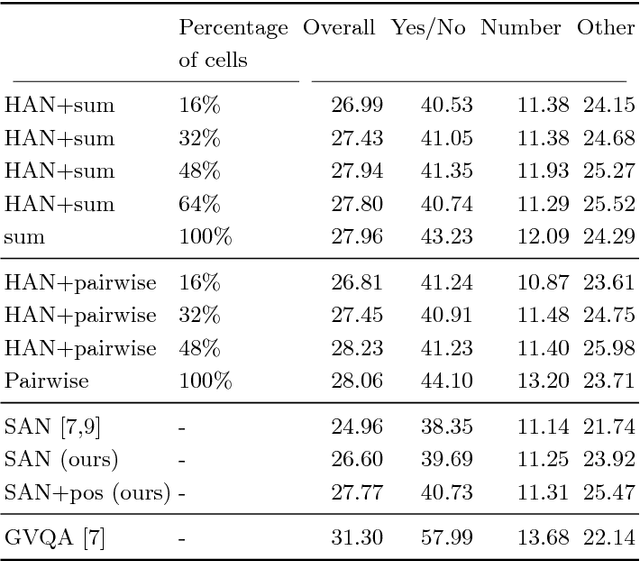
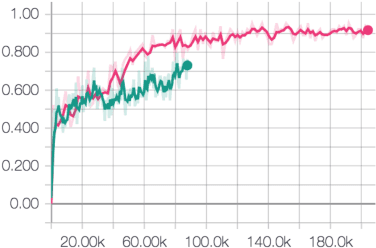
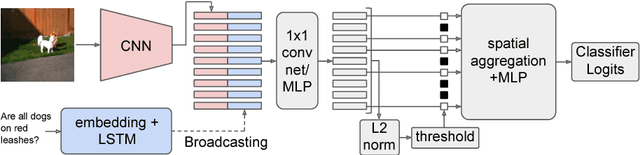
Attention mechanisms in biological perception are thought to select subsets of perceptual information for more sophisticated processing which would be prohibitive to perform on all sensory inputs. In computer vision, however, there has been relatively little exploration of hard attention, where some information is selectively ignored, in spite of the success of soft attention, where information is re-weighted and aggregated, but never filtered out. Here, we introduce a new approach for hard attention and find it achieves very competitive performance on a recently-released visual question answering datasets, equalling and in some cases surpassing similar soft attention architectures while entirely ignoring some features. Even though the hard attention mechanism is thought to be non-differentiable, we found that the feature magnitudes correlate with semantic relevance, and provide a useful signal for our mechanism's attentional selection criterion. Because hard attention selects important features of the input information, it can also be more efficient than analogous soft attention mechanisms. This is especially important for recent approaches that use non-local pairwise operations, whereby computational and memory costs are quadratic in the size of the set of features.
A Better Baseline for AVA
Jul 26, 2018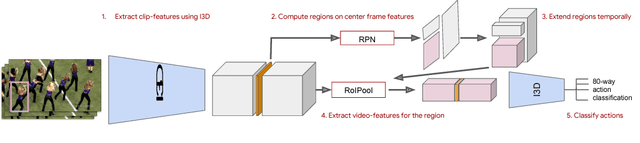
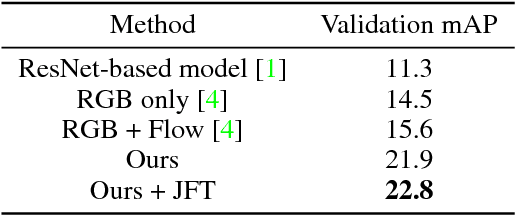
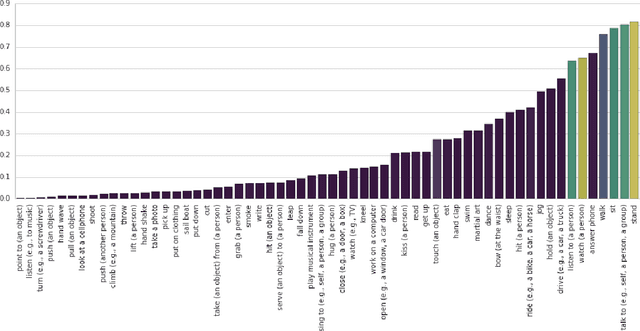

We introduce a simple baseline for action localization on the AVA dataset. The model builds upon the Faster R-CNN bounding box detection framework, adapted to operate on pure spatiotemporal features - in our case produced exclusively by an I3D model pretrained on Kinetics. This model obtains 21.9% average AP on the validation set of AVA v2.1, up from 14.5% for the best RGB spatiotemporal model used in the original AVA paper (which was pretrained on Kinetics and ImageNet), and up from 11.3 of the publicly available baseline using a ResNet101 image feature extractor, that was pretrained on ImageNet. Our final model obtains 22.8%/21.9% mAP on the val/test sets and outperforms all submissions to the AVA challenge at CVPR 2018.
Kickstarting Deep Reinforcement Learning
Mar 10, 2018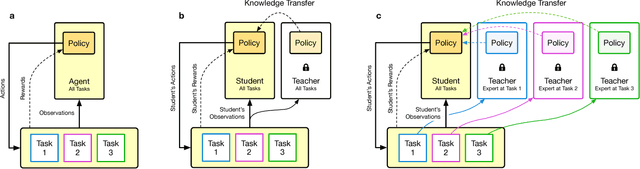
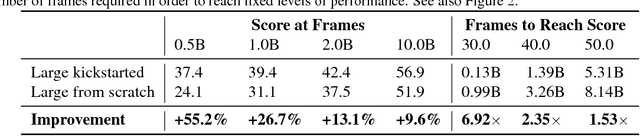
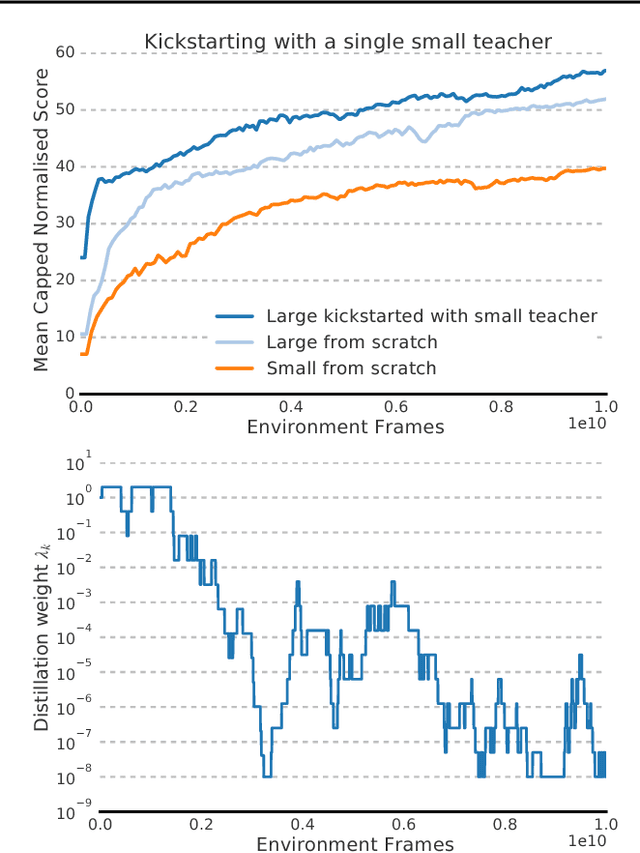
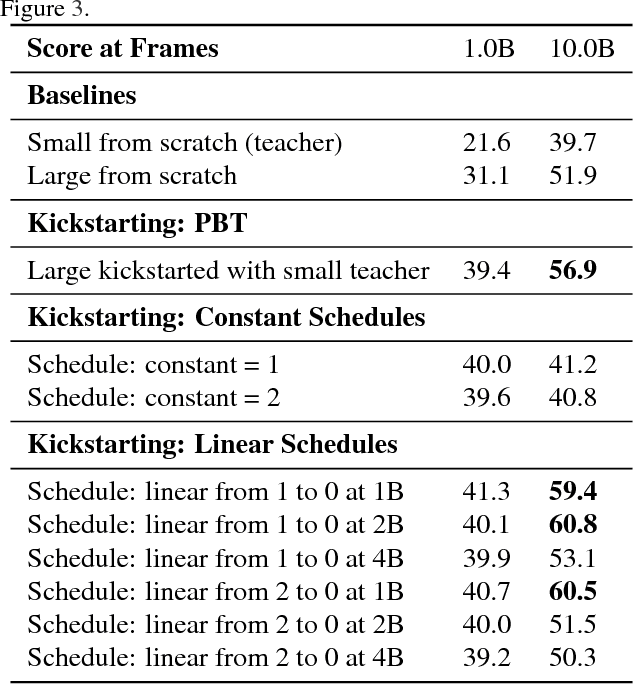
We present a method for using previously-trained 'teacher' agents to kickstart the training of a new 'student' agent. To this end, we leverage ideas from policy distillation and population based training. Our method places no constraints on the architecture of the teacher or student agents, and it regulates itself to allow the students to surpass their teachers in performance. We show that, on a challenging and computationally-intensive multi-task benchmark (DMLab-30), kickstarted training improves the data efficiency of new agents, making it significantly easier to iterate on their design. We also show that the same kickstarting pipeline can allow a single student agent to leverage multiple 'expert' teachers which specialize on individual tasks. In this setting kickstarting yields surprisingly large gains, with the kickstarted agent matching the performance of an agent trained from scratch in almost 10x fewer steps, and surpassing its final performance by 42 percent. Kickstarting is conceptually simple and can easily be incorporated into reinforcement learning experiments.
Multi-task Self-Supervised Visual Learning
Aug 25, 2017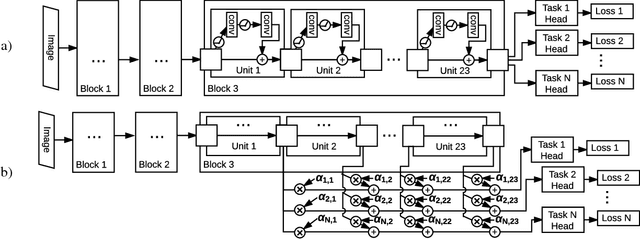
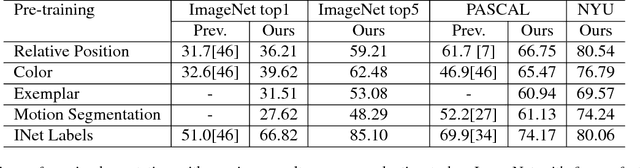
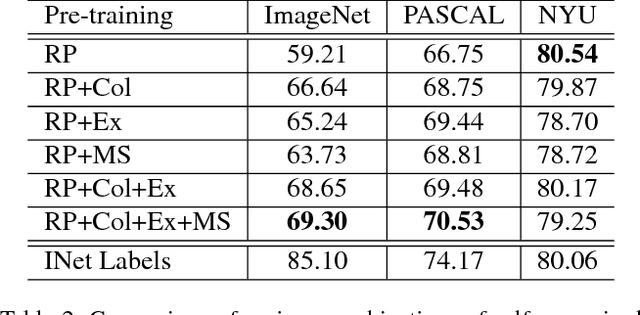
We investigate methods for combining multiple self-supervised tasks--i.e., supervised tasks where data can be collected without manual labeling--in order to train a single visual representation. First, we provide an apples-to-apples comparison of four different self-supervised tasks using the very deep ResNet-101 architecture. We then combine tasks to jointly train a network. We also explore lasso regularization to encourage the network to factorize the information in its representation, and methods for "harmonizing" network inputs in order to learn a more unified representation. We evaluate all methods on ImageNet classification, PASCAL VOC detection, and NYU depth prediction. Our results show that deeper networks work better, and that combining tasks--even via a naive multi-head architecture--always improves performance. Our best joint network nearly matches the PASCAL performance of a model pre-trained on ImageNet classification, and matches the ImageNet network on NYU depth prediction.
Data-dependent Initializations of Convolutional Neural Networks
Sep 22, 2016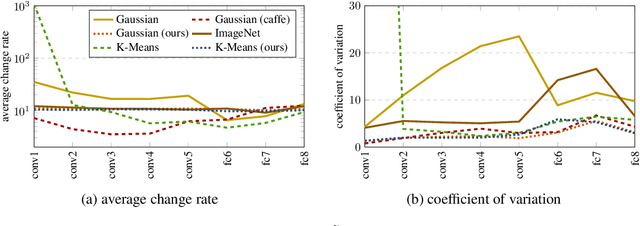
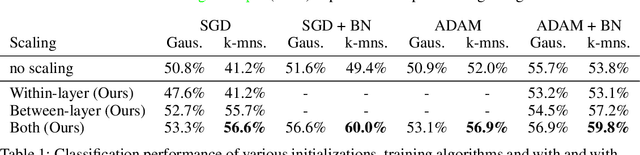
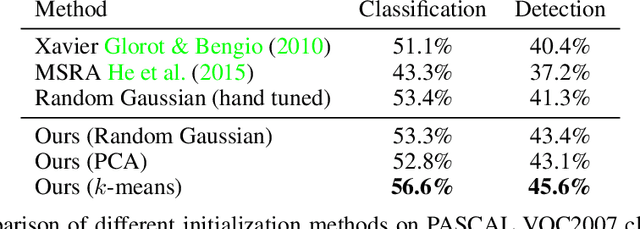
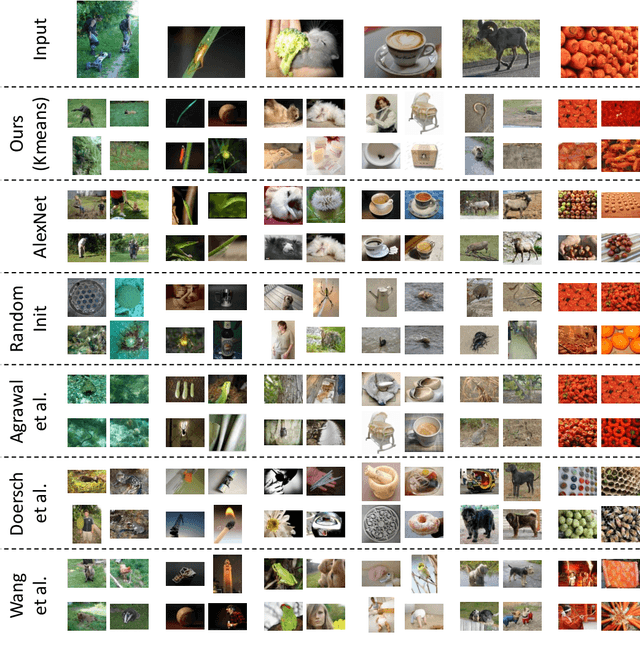
Convolutional Neural Networks spread through computer vision like a wildfire, impacting almost all visual tasks imaginable. Despite this, few researchers dare to train their models from scratch. Most work builds on one of a handful of ImageNet pre-trained models, and fine-tunes or adapts these for specific tasks. This is in large part due to the difficulty of properly initializing these networks from scratch. A small miscalibration of the initial weights leads to vanishing or exploding gradients, as well as poor convergence properties. In this work we present a fast and simple data-dependent initialization procedure, that sets the weights of a network such that all units in the network train at roughly the same rate, avoiding vanishing or exploding gradients. Our initialization matches the current state-of-the-art unsupervised or self-supervised pre-training methods on standard computer vision tasks, such as image classification and object detection, while being roughly three orders of magnitude faster. When combined with pre-training methods, our initialization significantly outperforms prior work, narrowing the gap between supervised and unsupervised pre-training.