 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisentangled Information Bottleneck guided Privacy-Protective JSCC for Image Transmission
Sep 19, 2023Joint source and channel coding (JSCC) has attracted increasing attention due to its robustness and high efficiency. However, JSCC is vulnerable to privacy leakage due to the high relevance between the source image and channel input. In this paper, we propose a disentangled information bottleneck guided privacy-protective JSCC (DIB-PPJSCC) for image transmission, which aims at protecting private information as well as achieving superior communication performance at the legitimate receiver. In particular, we propose a DIB objective to disentangle private and public information. The goal is to compress the private information in the public subcodewords, preserve the private information in the private subcodewords and improve the reconstruction quality simultaneously. In order to optimize JSCC neural networks using the DIB objective, we derive a differentiable estimation of the DIB objective based on the variational approximation and the density-ratio trick. Additionally, we design a password-based privacy-protective (PP) algorithm which can be jointly optimized with JSCC neural networks to encrypt the private subcodewords. Specifically, we employ a private information encryptor to encrypt the private subcodewords before transmission, and a corresponding decryptor to recover the private information at the legitimate receiver. A loss function for jointly training the encryptor, decryptor and JSCC decoder is derived based on the maximum entropy principle, which aims at maximizing the eavesdropping uncertainty as well as improving the reconstruction quality. Experimental results show that DIB-PPJSCC can reduce the eavesdropping accuracy on private information up to $15\%$ and reduce $10\%$ inference time compared to existing privacy-protective JSCC and traditional separate methods.
Privacy-Aware Joint Source-Channel Coding for image transmission based on Disentangled Information Bottleneck
Sep 15, 2023Current privacy-aware joint source-channel coding (JSCC) works aim at avoiding private information transmission by adversarially training the JSCC encoder and decoder under specific signal-to-noise ratios (SNRs) of eavesdroppers. However, these approaches incur additional computational and storage requirements as multiple neural networks must be trained for various eavesdroppers' SNRs to determine the transmitted information. To overcome this challenge, we propose a novel privacy-aware JSCC for image transmission based on disentangled information bottleneck (DIB-PAJSCC). In particular, we derive a novel disentangled information bottleneck objective to disentangle private and public information. Given the separate information, the transmitter can transmit only public information to the receiver while minimizing reconstruction distortion. Since DIB-PAJSCC transmits only public information regardless of the eavesdroppers' SNRs, it can eliminate additional training adapted to eavesdroppers' SNRs. Experimental results show that DIB-PAJSCC can reduce the eavesdropping accuracy on private information by up to 20\% compared to existing methods.
Federated Inference with Reliable Uncertainty Quantification over Wireless Channels via Conformal Prediction
Aug 08, 2023Consider a setting in which devices and a server share a pre-trained model. The server wishes to make an inference on a new input given the model. Devices have access to data, previously not used for training, and can communicate to the server over a common wireless channel. If the devices have no access to the new input, can communication from devices to the server enhance the quality of the inference decision at the server? Recent work has introduced federated conformal prediction (CP), which leverages devices-to-server communication to improve the reliability of the server's decision. With federated CP, devices communicate to the server information about the loss accrued by the shared pre-trained model on the local data, and the server leverages this information to calibrate a decision interval, or set, so that it is guaranteed to contain the correct answer with a pre-defined target reliability level. Previous work assumed noise-free communication, whereby devices can communicate a single real number to the server. In this paper, we study for the first time federated CP in a wireless setting. We introduce a novel protocol, termed wireless federated conformal prediction (WFCP), which builds on type-based multiple access (TBMA) and on a novel quantile correction strategy. WFCP is proved to provide formal reliability guarantees in terms of coverage of the predicted set produced by the server. Using numerical results, we demonstrate the significant advantages of WFCP against digital implementations of existing federated CP schemes, especially in regimes with limited communication resources and/or large number of devices.
Integrating Listwise Ranking into Pairwise-based Image-Text Retrieval
May 26, 2023



Image-Text Retrieval (ITR) is essentially a ranking problem. Given a query caption, the goal is to rank candidate images by relevance, from large to small. The current ITR datasets are constructed in a pairwise manner. Image-text pairs are annotated as positive or negative. Correspondingly, ITR models mainly use pairwise losses, such as triplet loss, to learn to rank. Pairwise-based ITR increases positive pair similarity while decreasing negative pair similarity indiscriminately. However, the relevance between dissimilar negative pairs is different. Pairwise annotations cannot reflect this difference in relevance. In the current datasets, pairwise annotations miss many correlations. There are many potential positive pairs among the pairs labeled as negative. Pairwise-based ITR can only rank positive samples before negative samples, but cannot rank negative samples by relevance. In this paper, we integrate listwise ranking into conventional pairwise-based ITR. Listwise ranking optimizes the entire ranking list based on relevance scores. Specifically, we first propose a Relevance Score Calculation (RSC) module to calculate the relevance score of the entire ranked list. Then we choose the ranking metric, Normalized Discounted Cumulative Gain (NDCG), as the optimization objective. We transform the non-differentiable NDCG into a differentiable listwise loss, named Smooth-NDCG (S-NDCG). Our listwise ranking approach can be plug-and-play integrated into current pairwise-based ITR models. Experiments on ITR benchmarks show that integrating listwise ranking can improve the performance of current ITR models and provide more user-friendly retrieval results. The code is available at https://github.com/AAA-Zheng/Listwise_ITR.
Selectively Hard Negative Mining for Alleviating Gradient Vanishing in Image-Text Matching
Mar 01, 2023



Recently, a series of Image-Text Matching (ITM) methods achieve impressive performance. However, we observe that most existing ITM models suffer from gradients vanishing at the beginning of training, which makes these models prone to falling into local minima. Most ITM models adopt triplet loss with Hard Negative mining (HN) as the optimization objective. We find that optimizing an ITM model using only the hard negative samples can easily lead to gradient vanishing. In this paper, we derive the condition under which the gradient vanishes during training. When the difference between the positive pair similarity and the negative pair similarity is close to 0, the gradients on both the image and text encoders will approach 0. To alleviate the gradient vanishing problem, we propose a Selectively Hard Negative Mining (SelHN) strategy, which chooses whether to mine hard negative samples according to the gradient vanishing condition. SelHN can be plug-and-play applied to existing ITM models to give them better training behavior. To further ensure the back-propagation of gradients, we construct a Residual Visual Semantic Embedding model with SelHN, denoted as RVSE++. Extensive experiments on two ITM benchmarks demonstrate the strength of RVSE++, achieving state-of-the-art performance.
Deep Joint Source-Channel Coding for Wireless Image Transmission with Semantic Importance
Feb 05, 2023The sixth-generation mobile communication system proposes the vision of smart interconnection of everything, which requires accomplishing communication tasks while ensuring the performance of intelligent tasks. A joint source-channel coding method based on semantic importance is proposed, which aims at preserving semantic information during wireless image transmission and thereby boosting the performance of intelligent tasks for images at the receiver. Specifically, we first propose semantic importance weight calculation method, which is based on the gradient of intelligent task's perception results with respect to the features. Then, we design the semantic loss function in the way of using semantic weights to weight the features. Finally, we train the deep joint source-channel coding network using the semantic loss function. Experiment results demonstrate that the proposed method achieves up to 57.7% and 9.1% improvement in terms of intelligent task's performance compared with the source-channel separation coding method and the deep sourcechannel joint coding method without considering semantics at the same compression rate and signal-to-noise ratio, respectively.
Semantics-Aware Remote Estimation via Information Bottleneck-Inspired Type Based Multiple Access
Dec 19, 2022


Type-based multiple access (TBMA) is a semantics-aware multiple access protocol for remote inference. In TBMA, codewords are reused across transmitting sensors, with each codeword being assigned to a different observation value. Existing TBMA protocols are based on fixed shared codebooks and on conventional maximum-likelihood or Bayesian decoders, which require knowledge of the distributions of observations and channels. In this letter, we propose a novel design principle for TBMA based on the information bottleneck (IB). In the proposed IB-TBMA protocol, the shared codebook is jointly optimized with a decoder based on artificial neural networks (ANNs), so as to adapt to source, observations, and channel statistics based on data only. We also introduce the Compressed IB-TBMA (CB-TBMA) protocol, which improves IB-TBMA by enabling a reduction in the number of codewords via an IB-inspired clustering phase. Numerical results demonstrate the importance of a joint design of codebook and neural decoder, and validate the benefits of codebook compression.
Image-Text Retrieval with Binary and Continuous Label Supervision
Oct 20, 2022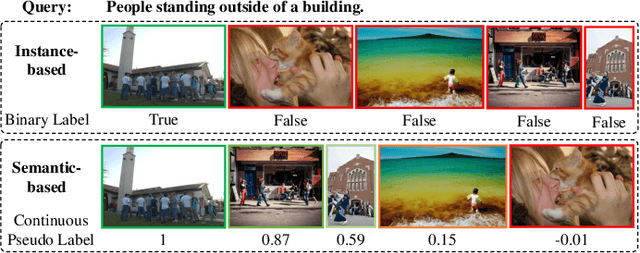
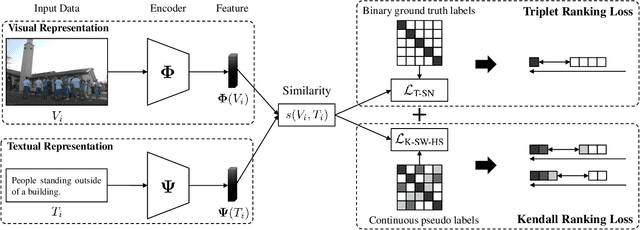
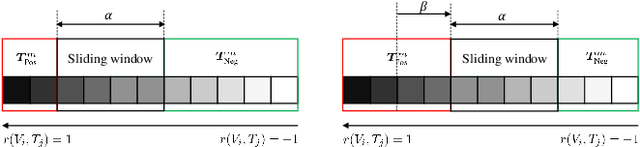
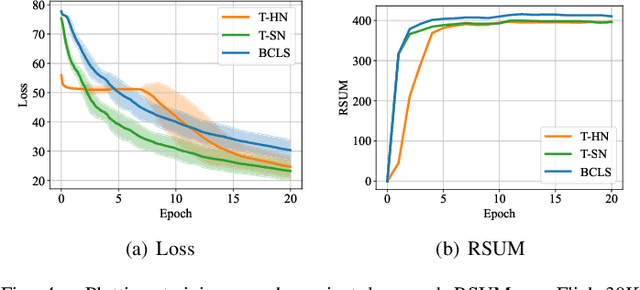
Most image-text retrieval work adopts binary labels indicating whether a pair of image and text matches or not. Such a binary indicator covers only a limited subset of image-text semantic relations, which is insufficient to represent relevance degrees between images and texts described by continuous labels such as image captions. The visual-semantic embedding space obtained by learning binary labels is incoherent and cannot fully characterize the relevance degrees. In addition to the use of binary labels, this paper further incorporates continuous pseudo labels (generally approximated by text similarity between captions) to indicate the relevance degrees. To learn a coherent embedding space, we propose an image-text retrieval framework with Binary and Continuous Label Supervision (BCLS), where binary labels are used to guide the retrieval model to learn limited binary correlations, and continuous labels are complementary to the learning of image-text semantic relations. For the learning of binary labels, we improve the common Triplet ranking loss with Soft Negative mining (Triplet-SN) to improve convergence. For the learning of continuous labels, we design Kendall ranking loss inspired by Kendall rank correlation coefficient (Kendall), which improves the correlation between the similarity scores predicted by the retrieval model and the continuous labels. To mitigate the noise introduced by the continuous pseudo labels, we further design Sliding Window sampling and Hard Sample mining strategy (SW-HS) to alleviate the impact of noise and reduce the complexity of our framework to the same order of magnitude as the triplet ranking loss. Extensive experiments on two image-text retrieval benchmarks demonstrate that our method can improve the performance of state-of-the-art image-text retrieval models.
Unified Loss of Pair Similarity Optimization for Vision-Language Retrieval
Sep 28, 2022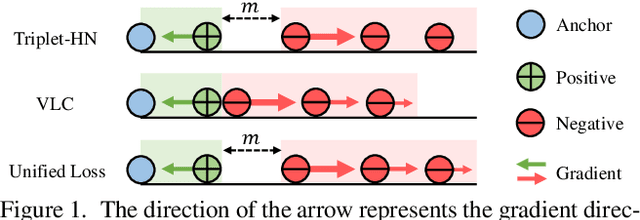
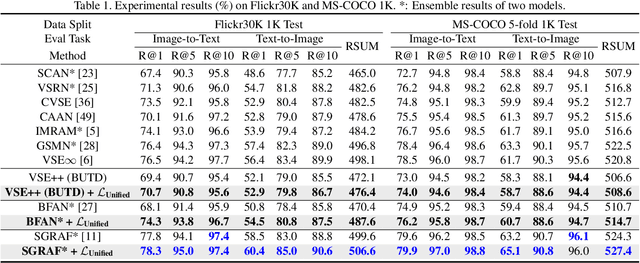
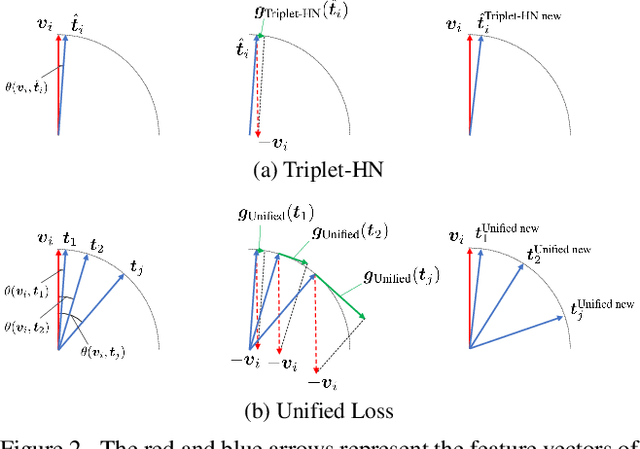

There are two popular loss functions used for vision-language retrieval, i.e., triplet loss and contrastive learning loss, both of them essentially minimize the difference between the similarities of negative pairs and positive pairs. More specifically, Triplet loss with Hard Negative mining (Triplet-HN), which is widely used in existing retrieval models to improve the discriminative ability, is easy to fall into local minima in training. On the other hand, Vision-Language Contrastive learning loss (VLC), which is widely used in the vision-language pre-training, has been shown to achieve significant performance gains on vision-language retrieval, but the performance of fine-tuning with VLC on small datasets is not satisfactory. This paper proposes a unified loss of pair similarity optimization for vision-language retrieval, providing a powerful tool for understanding existing loss functions. Our unified loss includes the hard sample mining strategy of VLC and introduces the margin used by the triplet loss for better similarity separation. It is shown that both Triplet-HN and VLC are special forms of our unified loss. Compared with the Triplet-HN, our unified loss has a fast convergence speed. Compared with the VLC, our unified loss is more discriminative and can provide better generalization in downstream fine-tuning tasks. Experiments on image-text and video-text retrieval benchmarks show that our unified loss can significantly improve the performance of the state-of-the-art retrieval models.
Deep Joint Source-Channel Coding Based on Semantics of Pixels
Aug 24, 2022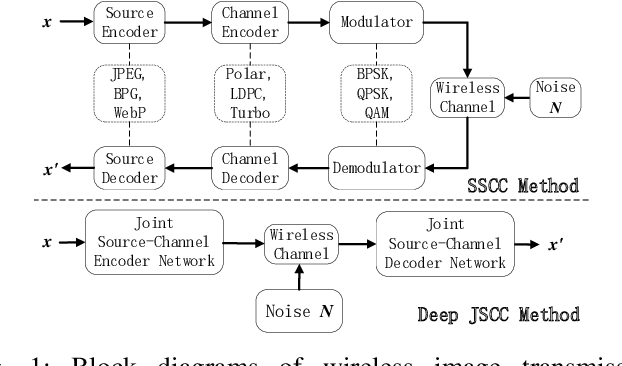
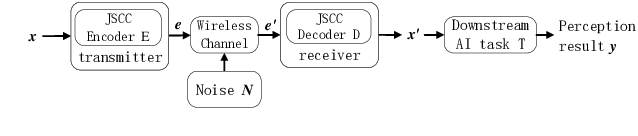
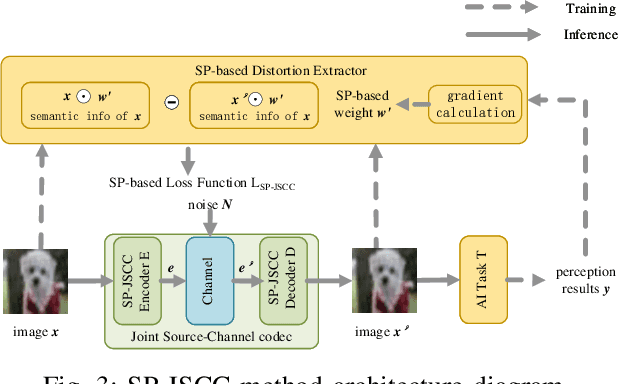
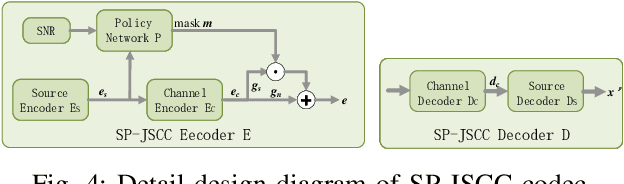
The semantic information of the image for intelligent tasks is hidden behind the pixels, and slight changes in the pixels will affect the performance of intelligent tasks. In order to preserve semantic information behind pixels for intelligent tasks during wireless image transmission, we propose a joint source-channel coding method based on semantics of pixels, which can improve the performance of intelligent tasks for images at the receiver by retaining semantic information. Specifically, we first utilize gradients of intelligent task's perception results with respect to pixels to represent the semantic importance of pixels. Then, we extract the semantic distortion, and train the deep joint source-channel coding network with the goal of minimizing semantic distortion rather than pixel's distortion. Experiment results demonstrate that the proposed method improves the performance of the intelligent classification task by 1.38% and 66% compared with the SOTA deep joint source-channel coding method and the traditional separately source-channel coding method at the same transmission ra te and signal-to-noise ratio.