 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging Gap between Image Pixels and Semantics via Supervision: A Survey
Jul 29, 2021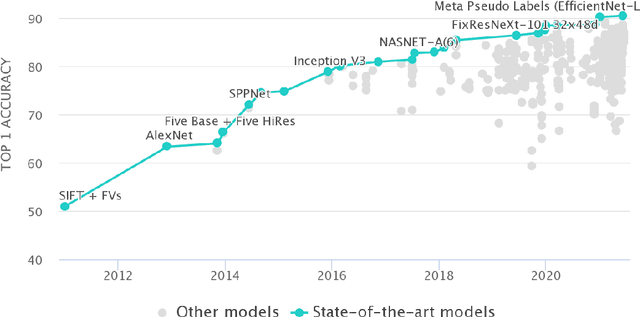
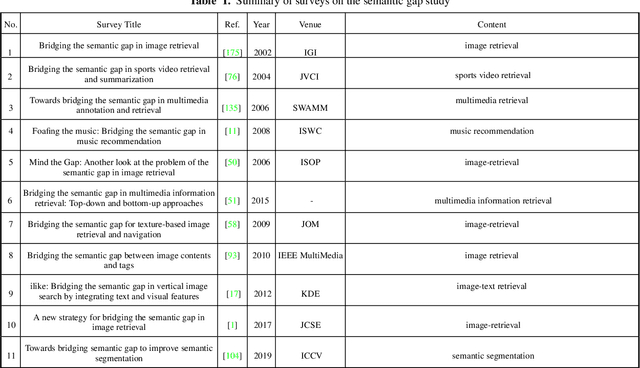

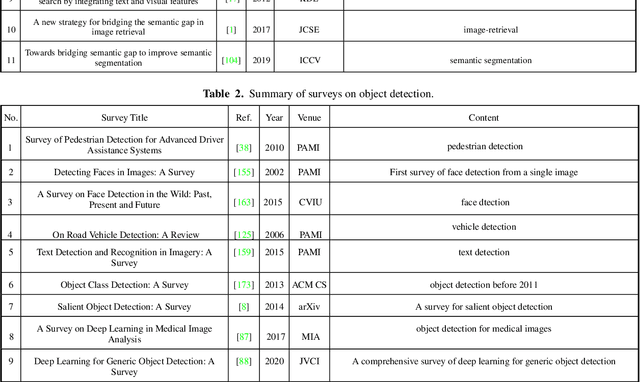
The fact that there exists a gap between low-level features and semantic meanings of images, called the semantic gap, is known for decades. Resolution of the semantic gap is a long standing problem. The semantic gap problem is reviewed and a survey on recent efforts in bridging the gap is made in this work. Most importantly, we claim that the semantic gap is primarily bridged through supervised learning today. Experiences are drawn from two application domains to illustrate this point: 1) object detection and 2) metric learning for content-based image retrieval (CBIR). To begin with, this paper offers a historical retrospective on supervision, makes a gradual transition to the modern data-driven methodology and introduces commonly used datasets. Then, it summarizes various supervision methods to bridge the semantic gap in the context of object detection and metric learning.
Segmentation of Cardiac Structures via Successive Subspace Learning with Saab Transform from Cine MRI
Jul 22, 2021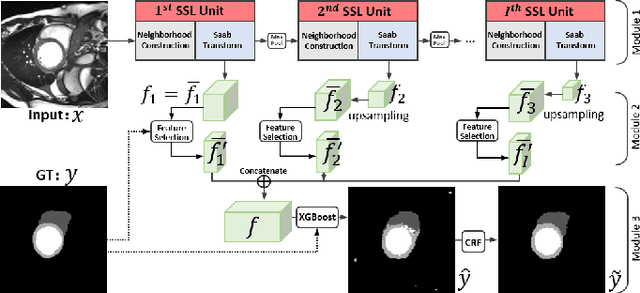

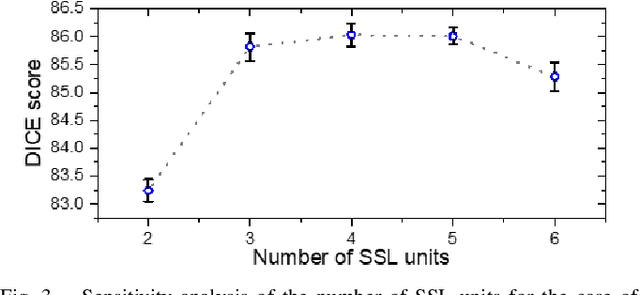

Assessment of cardiovascular disease (CVD) with cine magnetic resonance imaging (MRI) has been used to non-invasively evaluate detailed cardiac structure and function. Accurate segmentation of cardiac structures from cine MRI is a crucial step for early diagnosis and prognosis of CVD, and has been greatly improved with convolutional neural networks (CNN). There, however, are a number of limitations identified in CNN models, such as limited interpretability and high complexity, thus limiting their use in clinical practice. In this work, to address the limitations, we propose a lightweight and interpretable machine learning model, successive subspace learning with the subspace approximation with adjusted bias (Saab) transform, for accurate and efficient segmentation from cine MRI. Specifically, our segmentation framework is comprised of the following steps: (1) sequential expansion of near-to-far neighborhood at different resolutions; (2) channel-wise subspace approximation using the Saab transform for unsupervised dimension reduction; (3) class-wise entropy guided feature selection for supervised dimension reduction; (4) concatenation of features and pixel-wise classification with gradient boost; and (5) conditional random field for post-processing. Experimental results on the ACDC 2017 segmentation database, showed that our framework performed better than state-of-the-art U-Net models with 200$\times$ fewer parameters in delineating the left ventricle, right ventricle, and myocardium, thus showing its potential to be used in clinical practice.
TGHop: An Explainable, Efficient and Lightweight Method for Texture Generation
Jul 08, 2021
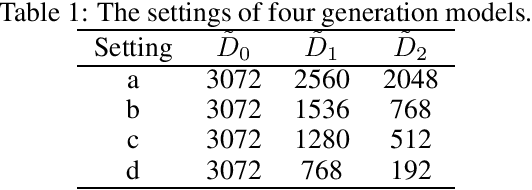
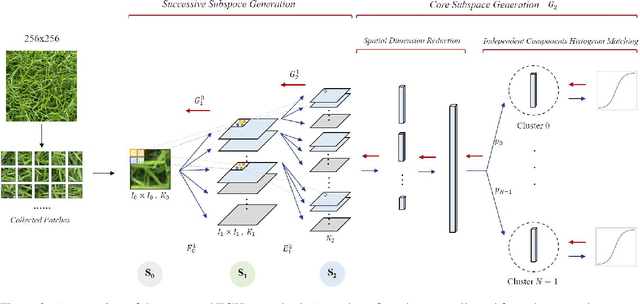

An explainable, efficient and lightweight method for texture generation, called TGHop (an acronym of Texture Generation PixelHop), is proposed in this work. Although synthesis of visually pleasant texture can be achieved by deep neural networks, the associated models are large in size, difficult to explain in theory, and computationally expensive in training. In contrast, TGHop is small in its model size, mathematically transparent, efficient in training and inference, and able to generate high quality texture. Given an exemplary texture, TGHop first crops many sample patches out of it to form a collection of sample patches called the source. Then, it analyzes pixel statistics of samples from the source and obtains a sequence of fine-to-coarse subspaces for these patches by using the PixelHop++ framework. To generate texture patches with TGHop, we begin with the coarsest subspace, which is called the core, and attempt to generate samples in each subspace by following the distribution of real samples. Finally, texture patches are stitched to form texture images of a large size. It is demonstrated by experimental results that TGHop can generate texture images of superior quality with a small model size and at a fast speed.
E-PixelHop: An Enhanced PixelHop Method for Object Classification
Jul 07, 2021
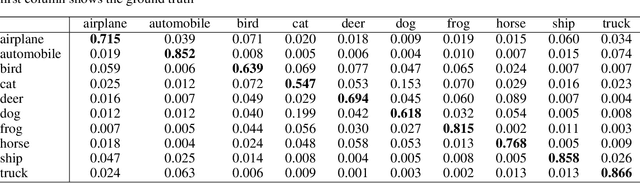
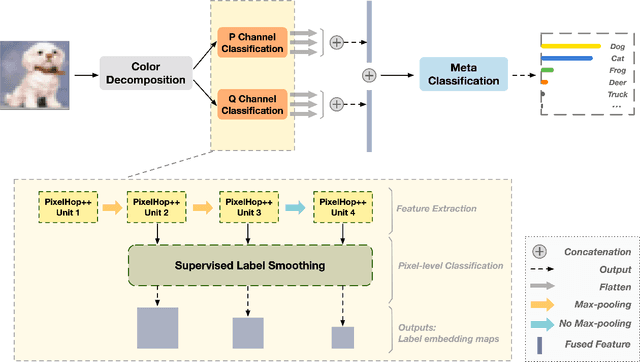
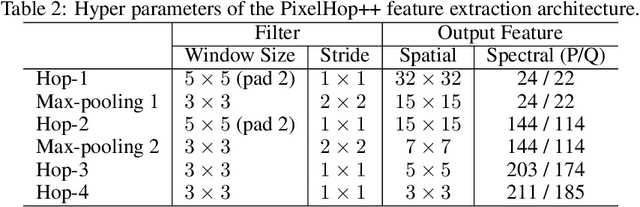
Based on PixelHop and PixelHop++, which are recently developed using the successive subspace learning (SSL) framework, we propose an enhanced solution for object classification, called E-PixelHop, in this work. E-PixelHop consists of the following steps. First, to decouple the color channels for a color image, we apply principle component analysis and project RGB three color channels onto two principle subspaces which are processed separately for classification. Second, to address the importance of multi-scale features, we conduct pixel-level classification at each hop with various receptive fields. Third, to further improve pixel-level classification accuracy, we develop a supervised label smoothing (SLS) scheme to ensure prediction consistency. Forth, pixel-level decisions from each hop and from each color subspace are fused together for image-level decision. Fifth, to resolve confusing classes for further performance boosting, we formulate E-PixelHop as a two-stage pipeline. In the first stage, multi-class classification is performed to get a soft decision for each class, where the top 2 classes with the highest probabilities are called confusing classes. Then,we conduct a binary classification in the second stage. The main contributions lie in Steps 1, 3 and 5.We use the classification of the CIFAR-10 dataset as an example to demonstrate the effectiveness of the above-mentioned key components of E-PixelHop.
AnomalyHop: An SSL-based Image Anomaly Localization Method
May 08, 2021

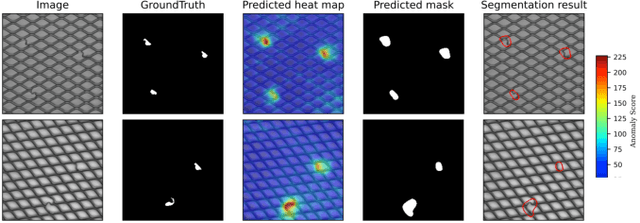
An image anomaly localization method based on the successive subspace learning (SSL) framework, called AnomalyHop, is proposed in this work. AnomalyHop consists of three modules: 1) feature extraction via successive subspace learning (SSL), 2) normality feature distributions modeling via Gaussian models, and 3) anomaly map generation and fusion. Comparing with state-of-the-art image anomaly localization methods based on deep neural networks (DNNs), AnomalyHop is mathematically transparent, easy to train, and fast in its inference speed. Besides, its area under the ROC curve (ROC-AUC) performance on the MVTec AD dataset is 95.9%, which is among the best of several benchmarking methods. Our codes are publicly available at Github.
Dynamic Texture Synthesis by Incorporating Long-range Spatial and Temporal Correlations
Apr 14, 2021

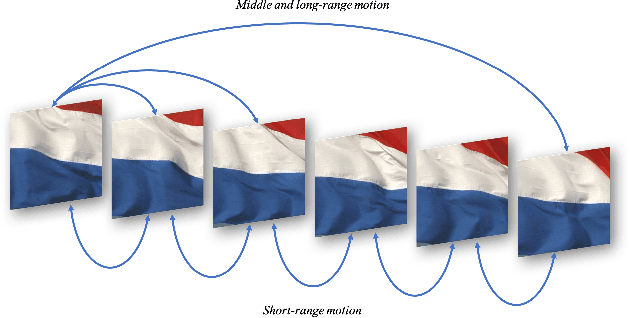

The main challenge of dynamic texture synthesis lies in how to maintain spatial and temporal consistency in synthesized videos. The major drawback of existing dynamic texture synthesis models comes from poor treatment of the long-range texture correlation and motion information. To address this problem, we incorporate a new loss term, called the Shifted Gram loss, to capture the structural and long-range correlation of the reference texture video. Furthermore, we introduce a frame sampling strategy to exploit long-period motion across multiple frames. With these two new techniques, the application scope of existing texture synthesis models can be extended. That is, they can synthesize not only homogeneous but also structured dynamic texture patterns. Thorough experimental results are provided to demonstrate that our proposed dynamic texture synthesis model offers state-of-the-art visual performance.
CalibDNN: Multimodal Sensor Calibration for Perception Using Deep Neural Networks
Mar 27, 2021Current perception systems often carry multimodal imagers and sensors such as 2D cameras and 3D LiDAR sensors. To fuse and utilize the data for downstream perception tasks, robust and accurate calibration of the multimodal sensor data is essential. We propose a novel deep learning-driven technique (CalibDNN) for accurate calibration among multimodal sensor, specifically LiDAR-Camera pairs. The key innovation of the proposed work is that it does not require any specific calibration targets or hardware assistants, and the entire processing is fully automatic with a single model and single iteration. Results comparison among different methods and extensive experiments on different datasets demonstrates the state-of-the-art performance.
R-PointHop: A Green, Accurate and Unsupervised Point Cloud Registration Method
Mar 15, 2021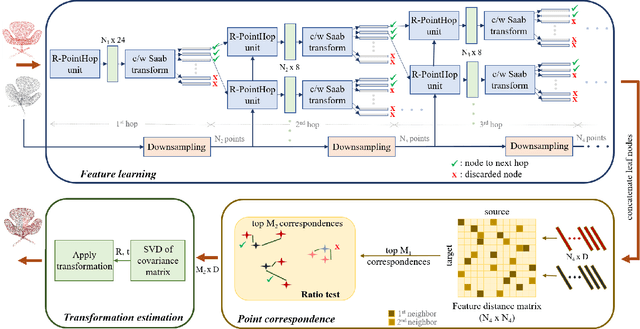
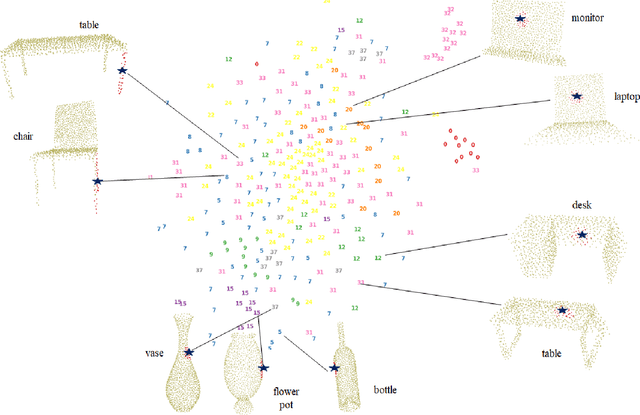

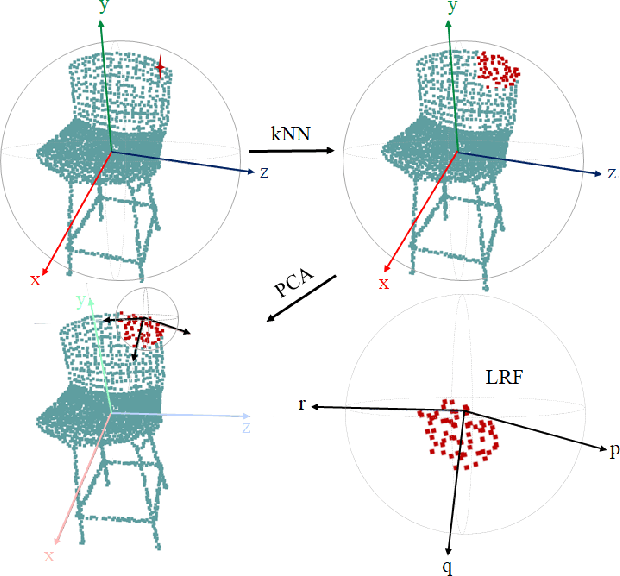
Inspired by the recent PointHop classification method, an unsupervised 3D point cloud registration method, called R-PointHop, is proposed in this work. R-PointHop first determines a local reference frame (LRF) for every point using its nearest neighbors and finds its local attributes. Next, R-PointHop obtains local-to-global hierarchical features by point downsampling, neighborhood expansion, attribute construction and dimensionality reduction steps. Thus, we can build the correspondence of points in the hierarchical feature space using the nearest neighbor rule. Afterwards, a subset of salient points of good correspondence is selected to estimate the 3D transformation. The use of LRF allows for hierarchical features of points to be invariant with respect to rotation and translation, thus making R-PointHop more robust in building point correspondence even when rotation angles are large. Experiments are conducted on the ModelNet40 and the Stanford Bunny dataset, which demonstrate the effectiveness of R-PointHop on the 3D point cloud registration task. R-PointHop is a green and accurate solution since its model size and training time are smaller than those of deep learning methods by an order of magnitude while its registration errors are smaller. Our codes are available on GitHub.
DefakeHop: A Light-Weight High-Performance Deepfake Detector
Mar 11, 2021
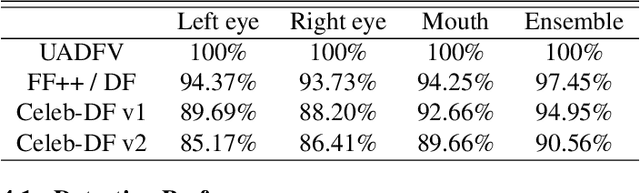
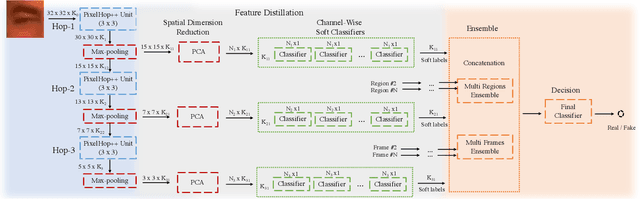
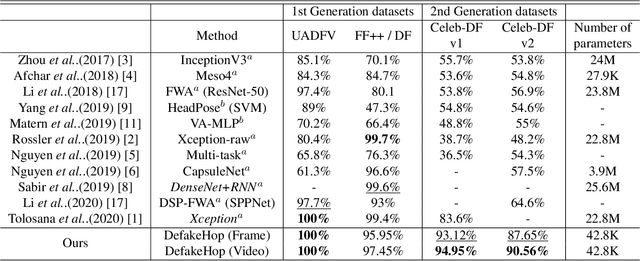
A light-weight high-performance Deepfake detection method, called DefakeHop, is proposed in this work. State-of-the-art Deepfake detection methods are built upon deep neural networks. DefakeHop extracts features automatically using the successive subspace learning (SSL) principle from various parts of face images. The features are extracted by c/w Saab transform and further processed by our feature distillation module using spatial dimension reduction and soft classification for each channel to get a more concise description of the face. Extensive experiments are conducted to demonstrate the effectiveness of the proposed DefakeHop method. With a small model size of 42,845 parameters, DefakeHop achieves state-of-the-art performance with the area under the ROC curve (AUC) of 100%, 94.95%, and 90.56% on UADFV, Celeb-DF v1 and Celeb-DF v2 datasets, respectively.
Successive Subspace Learning: An Overview
Feb 27, 2021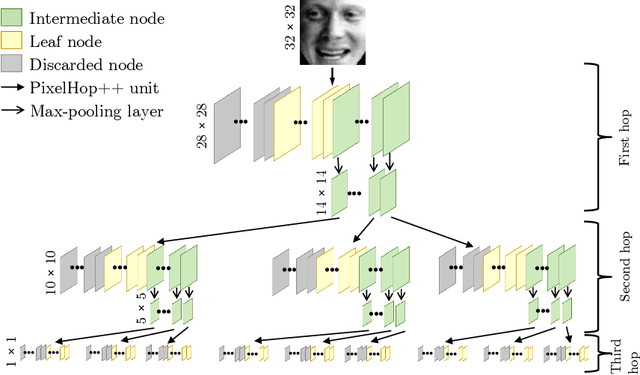
Successive Subspace Learning (SSL) offers a light-weight unsupervised feature learning method based on inherent statistical properties of data units (e.g. image pixels and points in point cloud sets). It has shown promising results, especially on small datasets. In this paper, we intuitively explain this method, provide an overview of its development, and point out some open questions and challenges for future research.