 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePose Optimization for Autonomous Driving Datasets using Neural Rendering Models
Apr 22, 2025



Autonomous driving systems rely on accurate perception and localization of the ego car to ensure safety and reliability in challenging real-world driving scenarios. Public datasets play a vital role in benchmarking and guiding advancement in research by providing standardized resources for model development and evaluation. However, potential inaccuracies in sensor calibration and vehicle poses within these datasets can lead to erroneous evaluations of downstream tasks, adversely impacting the reliability and performance of the autonomous systems. To address this challenge, we propose a robust optimization method based on Neural Radiance Fields (NeRF) to refine sensor poses and calibration parameters, enhancing the integrity of dataset benchmarks. To validate improvement in accuracy of our optimized poses without ground truth, we present a thorough evaluation process, relying on reprojection metrics, Novel View Synthesis rendering quality, and geometric alignment. We demonstrate that our method achieves significant improvements in sensor pose accuracy. By optimizing these critical parameters, our approach not only improves the utility of existing datasets but also paves the way for more reliable autonomous driving models. To foster continued progress in this field, we make the optimized sensor poses publicly available, providing a valuable resource for the research community.
Leveraging Semantic Cues from Foundation Vision Models for Enhanced Local Feature Correspondence
Oct 12, 2024



Visual correspondence is a crucial step in key computer vision tasks, including camera localization, image registration, and structure from motion. The most effective techniques for matching keypoints currently involve using learned sparse or dense matchers, which need pairs of images. These neural networks have a good general understanding of features from both images, but they often struggle to match points from different semantic areas. This paper presents a new method that uses semantic cues from foundation vision model features (like DINOv2) to enhance local feature matching by incorporating semantic reasoning into existing descriptors. Therefore, the learned descriptors do not require image pairs at inference time, allowing feature caching and fast matching using similarity search, unlike learned matchers. We present adapted versions of six existing descriptors, with an average increase in performance of 29% in camera localization, with comparable accuracy to existing matchers as LightGlue and LoFTR in two existing benchmarks. Both code and trained models are available at https://www.verlab.dcc.ufmg.br/descriptors/reasoning_accv24
3DGS-Calib: 3D Gaussian Splatting for Multimodal SpatioTemporal Calibration
Mar 18, 2024



Reliable multimodal sensor fusion algorithms require accurate spatiotemporal calibration. Recently, targetless calibration techniques based on implicit neural representations have proven to provide precise and robust results. Nevertheless, such methods are inherently slow to train given the high computational overhead caused by the large number of sampled points required for volume rendering. With the recent introduction of 3D Gaussian Splatting as a faster alternative to implicit representation methods, we propose to leverage this new rendering approach to achieve faster multi-sensor calibration. We introduce 3DGS-Calib, a new calibration method that relies on the speed and rendering accuracy of 3D Gaussian Splatting to achieve multimodal spatiotemporal calibration that is accurate, robust, and with a substantial speed-up compared to methods relying on implicit neural representations. We demonstrate the superiority of our proposal with experimental results on sequences from KITTI-360, a widely used driving dataset.
SOAC: Spatio-Temporal Overlap-Aware Multi-Sensor Calibration using Neural Radiance Fields
Nov 27, 2023



In rapidly-evolving domains such as autonomous driving, the use of multiple sensors with different modalities is crucial to ensure high operational precision and stability. To correctly exploit the provided information by each sensor in a single common frame, it is essential for these sensors to be accurately calibrated. In this paper, we leverage the ability of Neural Radiance Fields (NeRF) to represent different sensors modalities in a common volumetric representation to achieve robust and accurate spatio-temporal sensor calibration. By designing a partitioning approach based on the visible part of the scene for each sensor, we formulate the calibration problem using only the overlapping areas. This strategy results in a more robust and accurate calibration that is less prone to failure. We demonstrate that our approach works on outdoor urban scenes by validating it on multiple established driving datasets. Results show that our method is able to get better accuracy and robustness compared to existing methods.
Joint 3D Shape and Motion Estimation from Rolling Shutter Light-Field Images
Nov 02, 2023



In this paper, we propose an approach to address the problem of 3D reconstruction of scenes from a single image captured by a light-field camera equipped with a rolling shutter sensor. Our method leverages the 3D information cues present in the light-field and the motion information provided by the rolling shutter effect. We present a generic model for the imaging process of this sensor and a two-stage algorithm that minimizes the re-projection error while considering the position and motion of the camera in a motion-shape bundle adjustment estimation strategy. Thereby, we provide an instantaneous 3D shape-and-pose-and-velocity sensing paradigm. To the best of our knowledge, this is the first study to leverage this type of sensor for this purpose. We also present a new benchmark dataset composed of different light-fields showing rolling shutter effects, which can be used as a common base to improve the evaluation and tracking the progress in the field. We demonstrate the effectiveness and advantages of our approach through several experiments conducted for different scenes and types of motions. The source code and dataset are publicly available at: https://github.com/ICB-Vision-AI/RSLF
Alignment-free HDR Deghosting with Semantics Consistent Transformer
May 29, 2023



High dynamic range (HDR) imaging aims to retrieve information from multiple low-dynamic range inputs to generate realistic output. The essence is to leverage the contextual information, including both dynamic and static semantics, for better image generation. Existing methods often focus on the spatial misalignment across input frames caused by the foreground and/or camera motion. However, there is no research on jointly leveraging the dynamic and static context in a simultaneous manner. To delve into this problem, we propose a novel alignment-free network with a Semantics Consistent Transformer (SCTNet) with both spatial and channel attention modules in the network. The spatial attention aims to deal with the intra-image correlation to model the dynamic motion, while the channel attention enables the inter-image intertwining to enhance the semantic consistency across frames. Aside from this, we introduce a novel realistic HDR dataset with more variations in foreground objects, environmental factors, and larger motions. Extensive comparisons on both conventional datasets and ours validate the effectiveness of our method, achieving the best trade-off on the performance and the computational cost.
Object Segmentation by Mining Cross-Modal Semantics
May 23, 2023



Multi-sensor clues have shown promise for object segmentation, but inherent noise in each sensor, as well as the calibration error in practice, may bias the segmentation accuracy. In this paper, we propose a novel approach by mining the Cross-Modal Semantics to guide the fusion and decoding of multimodal features, with the aim of controlling the modal contribution based on relative entropy. We explore semantics among the multimodal inputs in two aspects: the modality-shared consistency and the modality-specific variation. Specifically, we propose a novel network, termed XMSNet, consisting of (1) all-round attentive fusion (AF), (2) coarse-to-fine decoder (CFD), and (3) cross-layer self-supervision. On the one hand, the AF block explicitly dissociates the shared and specific representation and learns to weight the modal contribution by adjusting the proportion, region, and pattern, depending upon the quality. On the other hand, our CFD initially decodes the shared feature and then refines the output through specificity-aware querying. Further, we enforce semantic consistency across the decoding layers to enable interaction across network hierarchies, improving feature discriminability. Exhaustive comparison on eleven datasets with depth or thermal clues, and on two challenging tasks, namely salient and camouflage object segmentation, validate our effectiveness in terms of both performance and robustness.
Mobile Mapping Mesh Change Detection and Update
Mar 13, 2023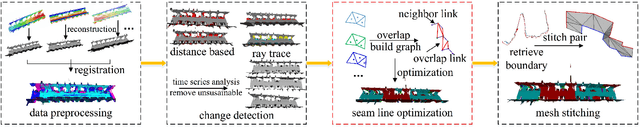
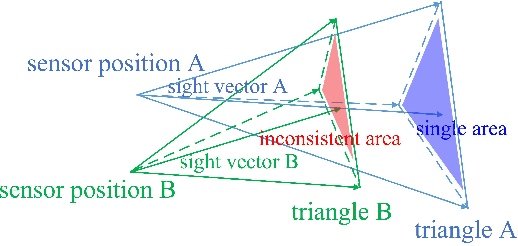
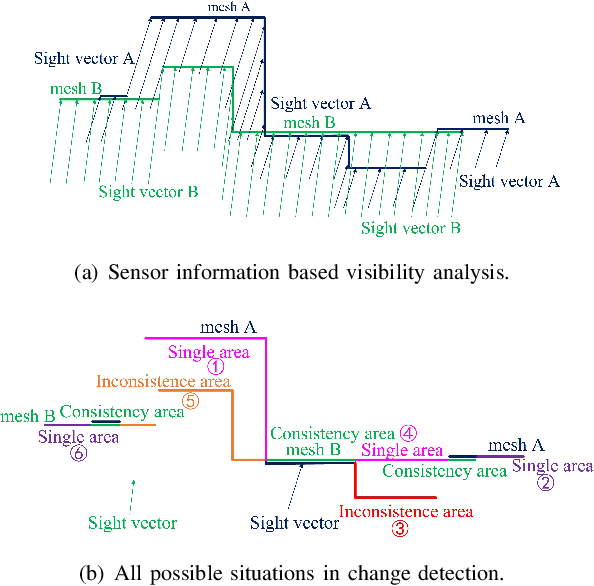

Mobile mapping, in particular, Mobile Lidar Scanning (MLS) is increasingly widespread to monitor and map urban scenes at city scale with unprecedented resolution and accuracy. The resulting point cloud sampling of the scene geometry can be meshed in order to create a continuous representation for different applications: visualization, simulation, navigation, etc. Because of the highly dynamic nature of these urban scenes, long term mapping should rely on frequent map updates. A trivial solution is to simply replace old data with newer data each time a new acquisition is made. However it has two drawbacks: 1) the old data may be of higher quality (resolution, precision) than the new and 2) the coverage of the scene might be different in various acquisitions, including varying occlusions. In this paper, we propose a fully automatic pipeline to address these two issues by formulating the problem of merging meshes with different quality, coverage and acquisition time. Our method is based on a combined distance and visibility based change detection, a time series analysis to assess the sustainability of changes, a mesh mosaicking based on a global boolean optimization and finally a stitching of the resulting mesh pieces boundaries with triangle strips. Finally, our method is demonstrated on Robotcar and Stereopolis datasets.
MOISST: Multi-modal Optimization of Implicit Scene for SpatioTemporal calibration
Mar 07, 2023



With the recent advances in autonomous driving and the decreasing cost of LiDARs, the use of multi-modal sensor systems is on the rise. However, in order to make use of the information provided by a variety of complimentary sensors, it is necessary to accurately calibrate them. We take advantage of recent advances in computer graphics and implicit volumetric scene representation to tackle the problem of multi-sensor spatial and temporal calibration. Thanks to a new formulation of the implicit model optimization, we are able to jointly optimize calibration parameters along with scene representation based on radiometric and geometric measurements. Our method enables accurate and robust calibration from data captured in uncontrolled and unstructured urban environments, making our solution more scalable than existing calibration solutions. We demonstrate the accuracy and robustness of our method in urban scenes typically encountered in autonomous driving scenarios.
HiDAnet: RGB-D Salient Object Detection via Hierarchical Depth Awareness
Jan 18, 2023RGB-D saliency detection aims to fuse multi-modal cues to accurately localize salient regions. Existing works often adopt attention modules for feature modeling, with few methods explicitly leveraging fine-grained details to merge with semantic cues. Thus, despite the auxiliary depth information, it is still challenging for existing models to distinguish objects with similar appearances but at distinct camera distances. In this paper, from a new perspective, we propose a novel Hierarchical Depth Awareness network (HiDAnet) for RGB-D saliency detection. Our motivation comes from the observation that the multi-granularity properties of geometric priors correlate well with the neural network hierarchies. To realize multi-modal and multi-level fusion, we first use a granularity-based attention scheme to strengthen the discriminatory power of RGB and depth features separately. Then we introduce a unified cross dual-attention module for multi-modal and multi-level fusion in a coarse-to-fine manner. The encoded multi-modal features are gradually aggregated into a shared decoder. Further, we exploit a multi-scale loss to take full advantage of the hierarchical information. Extensive experiments on challenging benchmark datasets demonstrate that our HiDAnet performs favorably over the state-of-the-art methods by large margins.