 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSibylSense: Adaptive Rubric Learning via Memory Tuning and Adversarial Probing
Feb 24, 2026Designing aligned and robust rewards for open-ended generation remains a key barrier to RL post-training. Rubrics provide structured, interpretable supervision, but scaling rubric construction is difficult: expert rubrics are costly, prompted rubrics are often superficial or inconsistent, and fixed-pool discriminative rubrics can saturate and drift, enabling reward hacking. We present SibylSense, an inference-time learning approach that adapts a frozen rubric generator through a tunable memory bank of validated rubric items. Memory is updated via verifier-based item rewards measured by reference-candidate answer discriminative gaps from a handful of examples. SibylSense alternates memory tuning with a rubric-adversarial policy update that produces rubric-satisfying candidate answers, shrinking discriminative gaps and driving the rubric generator to capture new quality dimensions. Experiments on two open-ended tasks show that SibylSense yields more discriminative rubrics and improves downstream RL performance over static and non-adaptive baselines.
Leveraging Semantic Cues from Foundation Vision Models for Enhanced Local Feature Correspondence
Oct 12, 2024



Visual correspondence is a crucial step in key computer vision tasks, including camera localization, image registration, and structure from motion. The most effective techniques for matching keypoints currently involve using learned sparse or dense matchers, which need pairs of images. These neural networks have a good general understanding of features from both images, but they often struggle to match points from different semantic areas. This paper presents a new method that uses semantic cues from foundation vision model features (like DINOv2) to enhance local feature matching by incorporating semantic reasoning into existing descriptors. Therefore, the learned descriptors do not require image pairs at inference time, allowing feature caching and fast matching using similarity search, unlike learned matchers. We present adapted versions of six existing descriptors, with an average increase in performance of 29% in camera localization, with comparable accuracy to existing matchers as LightGlue and LoFTR in two existing benchmarks. Both code and trained models are available at https://www.verlab.dcc.ufmg.br/descriptors/reasoning_accv24
XFeat: Accelerated Features for Lightweight Image Matching
Apr 30, 2024



We introduce a lightweight and accurate architecture for resource-efficient visual correspondence. Our method, dubbed XFeat (Accelerated Features), revisits fundamental design choices in convolutional neural networks for detecting, extracting, and matching local features. Our new model satisfies a critical need for fast and robust algorithms suitable to resource-limited devices. In particular, accurate image matching requires sufficiently large image resolutions - for this reason, we keep the resolution as large as possible while limiting the number of channels in the network. Besides, our model is designed to offer the choice of matching at the sparse or semi-dense levels, each of which may be more suitable for different downstream applications, such as visual navigation and augmented reality. Our model is the first to offer semi-dense matching efficiently, leveraging a novel match refinement module that relies on coarse local descriptors. XFeat is versatile and hardware-independent, surpassing current deep learning-based local features in speed (up to 5x faster) with comparable or better accuracy, proven in pose estimation and visual localization. We showcase it running in real-time on an inexpensive laptop CPU without specialized hardware optimizations. Code and weights are available at www.verlab.dcc.ufmg.br/descriptors/xfeat_cvpr24.
Improving the matching of deformable objects by learning to detect keypoints
Sep 12, 2023



We propose a novel learned keypoint detection method to increase the number of correct matches for the task of non-rigid image correspondence. By leveraging true correspondences acquired by matching annotated image pairs with a specified descriptor extractor, we train an end-to-end convolutional neural network (CNN) to find keypoint locations that are more appropriate to the considered descriptor. For that, we apply geometric and photometric warpings to images to generate a supervisory signal, allowing the optimization of the detector. Experiments demonstrate that our method enhances the Mean Matching Accuracy of numerous descriptors when used in conjunction with our detection method, while outperforming the state-of-the-art keypoint detectors on real images of non-rigid objects by 20 p.p. We also apply our method on the complex real-world task of object retrieval where our detector performs on par with the finest keypoint detectors currently available for this task. The source code and trained models are publicly available at https://github.com/verlab/LearningToDetect_PRL_2023
* This is the accepted version of the paper to appear at Pattern Recognition Letters (PRL). The final journal version will be available at https://doi.org/10.1016/j.patrec.2023.08.012
Enhancing Deformable Local Features by Jointly Learning to Detect and Describe Keypoints
Apr 02, 2023



Local feature extraction is a standard approach in computer vision for tackling important tasks such as image matching and retrieval. The core assumption of most methods is that images undergo affine transformations, disregarding more complicated effects such as non-rigid deformations. Furthermore, incipient works tailored for non-rigid correspondence still rely on keypoint detectors designed for rigid transformations, hindering performance due to the limitations of the detector. We propose DALF (Deformation-Aware Local Features), a novel deformation-aware network for jointly detecting and describing keypoints, to handle the challenging problem of matching deformable surfaces. All network components work cooperatively through a feature fusion approach that enforces the descriptors' distinctiveness and invariance. Experiments using real deforming objects showcase the superiority of our method, where it delivers 8% improvement in matching scores compared to the previous best results. Our approach also enhances the performance of two real-world applications: deformable object retrieval and non-rigid 3D surface registration. Code for training, inference, and applications are publicly available at https://verlab.dcc.ufmg.br/descriptors/dalf_cvpr23.
Learning to Detect Good Keypoints to Match Non-Rigid Objects in RGB Images
Dec 13, 2022



We present a novel learned keypoint detection method designed to maximize the number of correct matches for the task of non-rigid image correspondence. Our training framework uses true correspondences, obtained by matching annotated image pairs with a predefined descriptor extractor, as a ground-truth to train a convolutional neural network (CNN). We optimize the model architecture by applying known geometric transformations to images as the supervisory signal. Experiments show that our method outperforms the state-of-the-art keypoint detector on real images of non-rigid objects by 20 p.p. on Mean Matching Accuracy and also improves the matching performance of several descriptors when coupled with our detection method. We also employ the proposed method in one challenging realworld application: object retrieval, where our detector exhibits performance on par with the best available keypoint detectors. The source code and trained model are publicly available at https://github.com/verlab/LearningToDetect SIBGRAPI 2022
Learning Geodesic-Aware Local Features from RGB-D Images
Mar 22, 2022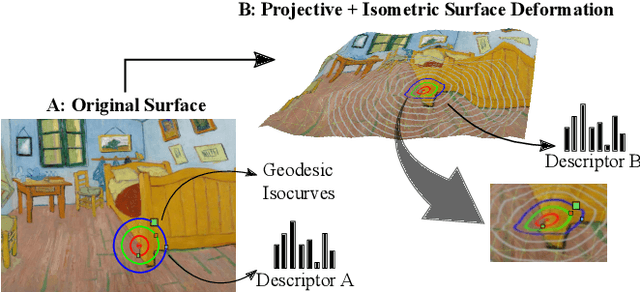
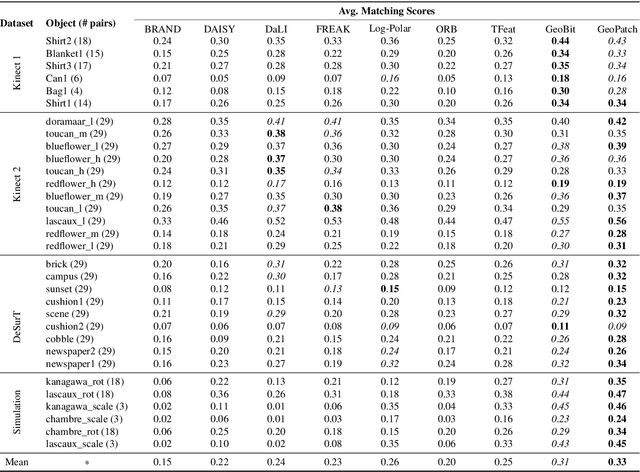
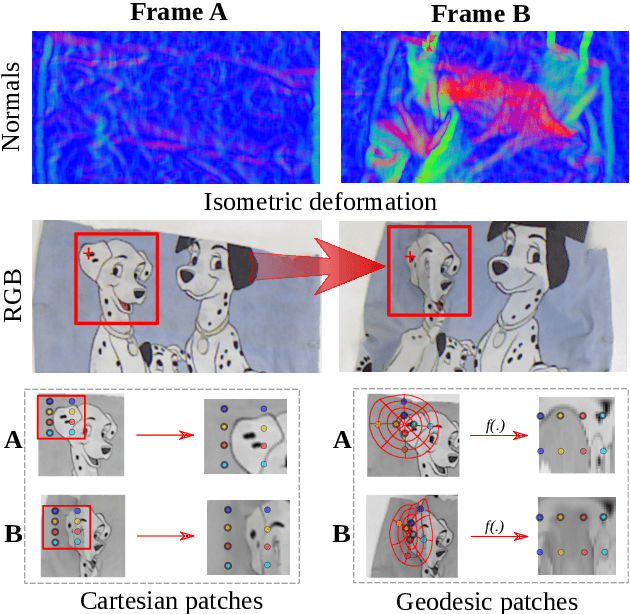
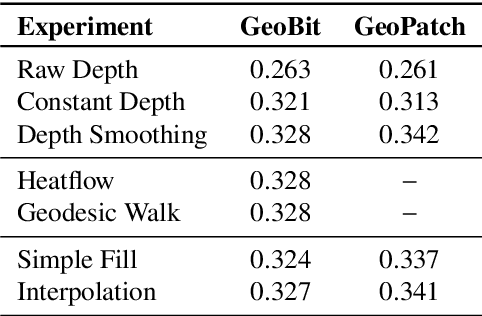
Most of the existing handcrafted and learning-based local descriptors are still at best approximately invariant to affine image transformations, often disregarding deformable surfaces. In this paper, we take one step further by proposing a new approach to compute descriptors from RGB-D images (where RGB refers to the pixel color brightness and D stands for depth information) that are invariant to isometric non-rigid deformations, as well as to scale changes and rotation. Our proposed description strategies are grounded on the key idea of learning feature representations on undistorted local image patches using surface geodesics. We design two complementary local descriptors strategies to compute geodesic-aware features efficiently: one efficient binary descriptor based on handcrafted binary tests (named GeoBit), and one learning-based descriptor (GeoPatch) with convolutional neural networks (CNNs) to compute features. In different experiments using real and publicly available RGB-D data benchmarks, they consistently outperforms state-of-the-art handcrafted and learning-based image and RGB-D descriptors in matching scores, as well as in object retrieval and non-rigid surface tracking experiments, with comparable processing times. We also provide to the community a new dataset with accurate matching annotations of RGB-D images of different objects (shirts, cloths, paintings, bags), subjected to strong non-rigid deformations, for evaluation benchmark of deformable surface correspondence algorithms.
Extracting Deformation-Aware Local Features by Learning to Deform
Nov 20, 2021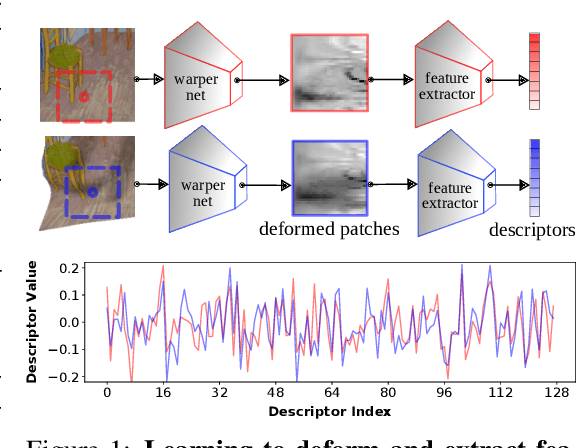
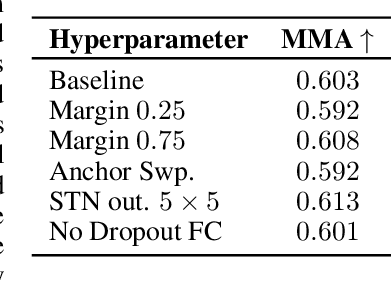

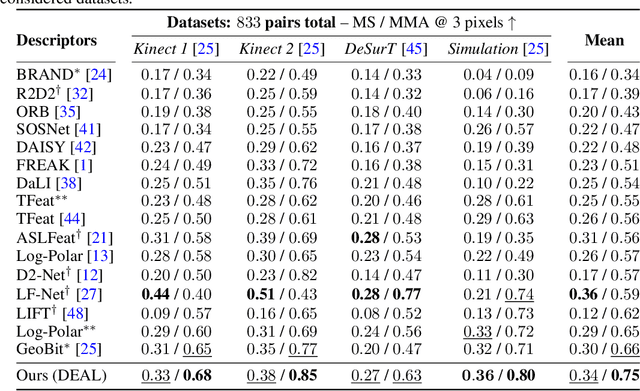
Despite the advances in extracting local features achieved by handcrafted and learning-based descriptors, they are still limited by the lack of invariance to non-rigid transformations. In this paper, we present a new approach to compute features from still images that are robust to non-rigid deformations to circumvent the problem of matching deformable surfaces and objects. Our deformation-aware local descriptor, named DEAL, leverages a polar sampling and a spatial transformer warping to provide invariance to rotation, scale, and image deformations. We train the model architecture end-to-end by applying isometric non-rigid deformations to objects in a simulated environment as guidance to provide highly discriminative local features. The experiments show that our method outperforms state-of-the-art handcrafted, learning-based image, and RGB-D descriptors in different datasets with both real and realistic synthetic deformable objects in still images. The source code and trained model of the descriptor are publicly available at https://www.verlab.dcc.ufmg.br/descriptors/neurips2021.