 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Generalizable Robot Skills from Demonstrations in Cluttered Environments
Aug 04, 2018
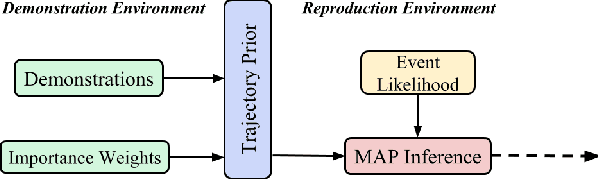
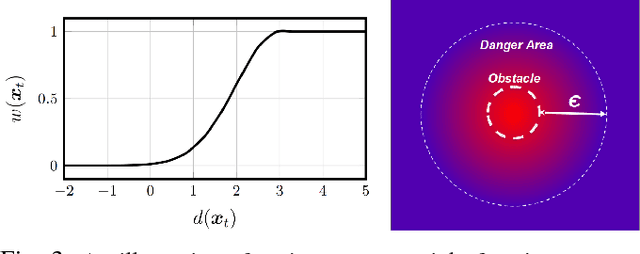
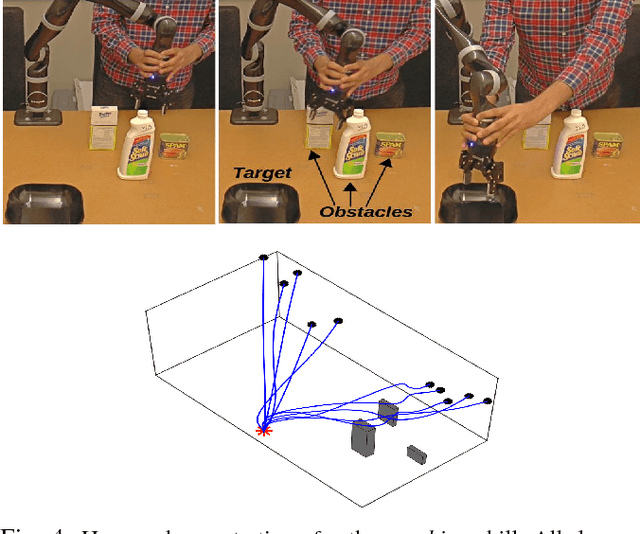
Learning from Demonstration (LfD) is a popular approach to endowing robots with skills without having to program them by hand. Typically, LfD relies on human demonstrations in clutter-free environments. This prevents the demonstrations from being affected by irrelevant objects, whose influence can obfuscate the true intention of the human or the constraints of the desired skill. However, it is unrealistic to assume that the robot's environment can always be restructured to remove clutter when capturing human demonstrations. To contend with this problem, we develop an importance weighted batch and incremental skill learning approach, building on a recent inference-based technique for skill representation and reproduction. Our approach reduces unwanted environmental influences on the learned skill, while still capturing the salient human behavior. We provide both batch and incremental versions of our approach and validate our algorithms on a 7-DOF JACO2 manipulator with reaching and placing skills.
STEAP: simultaneous trajectory estimation and planning
Jul 27, 2018


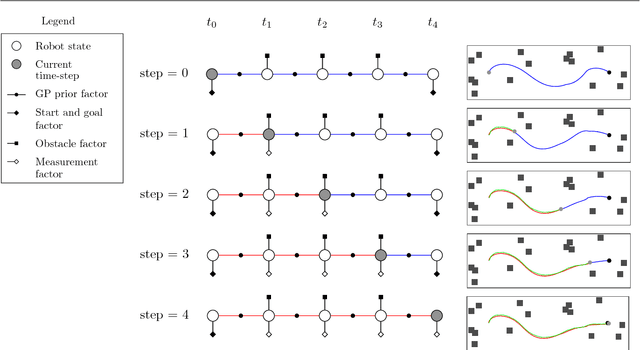
We present a unified probabilistic framework for simultaneous trajectory estimation and planning (STEAP). Estimation and planning problems are usually considered separately, however, within our framework we show that solving them simultaneously can be more accurate and efficient. The key idea is to compute the full continuous-time trajectory from start to goal at each time-step. While the robot traverses the trajectory, the history portion of the trajectory signifies the solution to the estimation problem, and the future portion of the trajectory signifies a solution to the planning problem. Building on recent probabilistic inference approaches to continuous-time localization and mapping and continuous-time motion planning, we solve the joint problem by iteratively recomputing the maximum a posteriori trajectory conditioned on all available sensor data and cost information. Our approach can contend with high-degree-of-freedom (DOF) trajectory spaces, uncertainty due to limited sensing capabilities, model inaccuracy, the stochastic effect of executing actions, and can find a solution in real-time. We evaluate our framework empirically in both simulation and on a mobile manipulator.
Semantically Meaningful View Selection
Jul 26, 2018
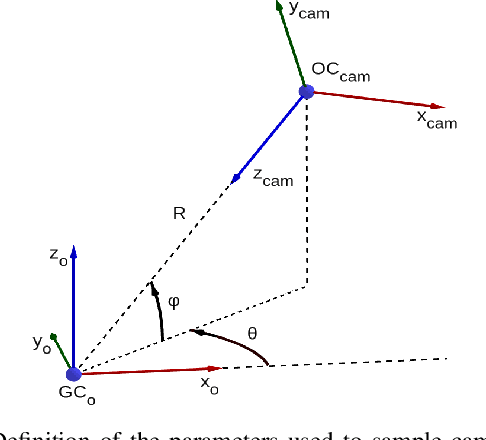

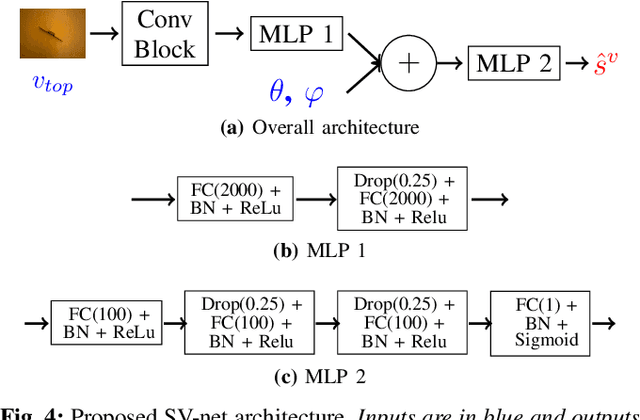
An understanding of the nature of objects could help robots to solve both high-level abstract tasks and improve performance at lower-level concrete tasks. Although deep learning has facilitated progress in image understanding, a robot's performance in problems like object recognition often depends on the angle from which the object is observed. Traditionally, robot sorting tasks rely on a fixed top-down view of an object. By changing its viewing angle, a robot can select a more semantically informative view leading to better performance for object recognition. In this paper, we introduce the problem of semantic view selection, which seeks to find good camera poses to gain semantic knowledge about an observed object. We propose a conceptual formulation of the problem, together with a solvable relaxation based on clustering. We then present a new image dataset consisting of around 10k images representing various views of 144 objects under different poses. Finally we use this dataset to propose a first solution to the problem by training a neural network to predict a "semantic score" from a top view image and camera pose. The views predicted to have higher scores are then shown to provide better clustering results than fixed top-down views.
Improving Image Clustering With Multiple Pretrained CNN Feature Extractors
Jul 20, 2018
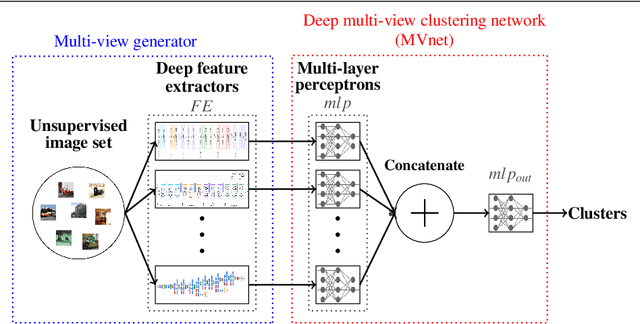
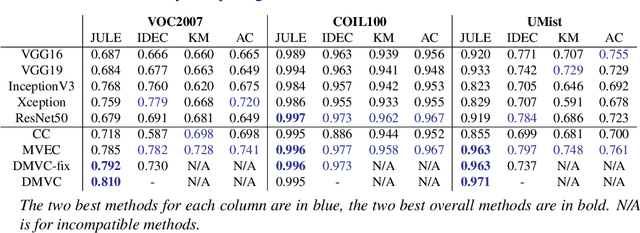

For many image clustering problems, replacing raw image data with features extracted by a pretrained convolutional neural network (CNN), leads to better clustering performance. However, the specific features extracted, and, by extension, the selected CNN architecture, can have a major impact on the clustering results. In practice, this crucial design choice is often decided arbitrarily due to the impossibility of using cross-validation with unsupervised learning problems. However, information contained in the different pretrained CNN architectures may be complementary, even when pretrained on the same data. To improve clustering performance, we rephrase the image clustering problem as a multi-view clustering (MVC) problem that considers multiple different pretrained feature extractors as different "views" of the same data. We then propose a multi-input neural network architecture that is trained end-to-end to solve the MVC problem effectively. Our experimental results, conducted on three different natural image datasets, show that: 1. using multiple pretrained CNNs jointly as feature extractors improves image clustering; 2. using an end-to-end approach improves MVC; and 3. combining both produces state-of-the-art results for the problem of image clustering.
Truncated Horizon Policy Search: Combining Reinforcement Learning & Imitation Learning
May 29, 2018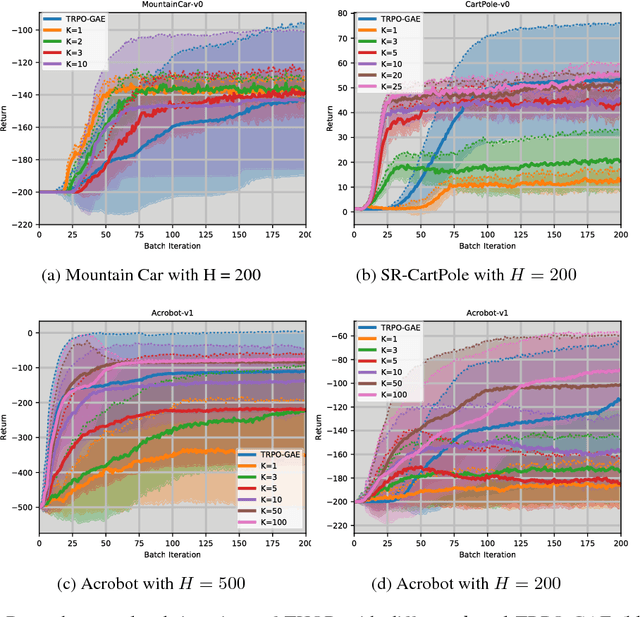
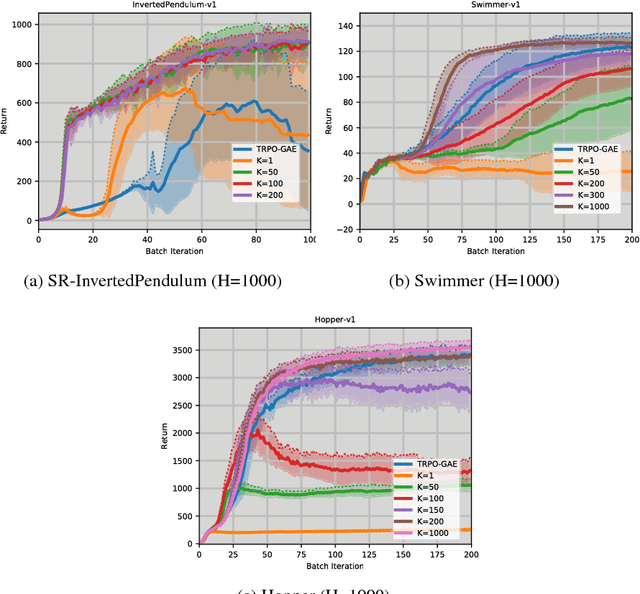
In this paper, we propose to combine imitation and reinforcement learning via the idea of reward shaping using an oracle. We study the effectiveness of the near-optimal cost-to-go oracle on the planning horizon and demonstrate that the cost-to-go oracle shortens the learner's planning horizon as function of its accuracy: a globally optimal oracle can shorten the planning horizon to one, leading to a one-step greedy Markov Decision Process which is much easier to optimize, while an oracle that is far away from the optimality requires planning over a longer horizon to achieve near-optimal performance. Hence our new insight bridges the gap and interpolates between imitation learning and reinforcement learning. Motivated by the above mentioned insights, we propose Truncated HORizon Policy Search (THOR), a method that focuses on searching for policies that maximize the total reshaped reward over a finite planning horizon when the oracle is sub-optimal. We experimentally demonstrate that a gradient-based implementation of THOR can achieve superior performance compared to RL baselines and IL baselines even when the oracle is sub-optimal.
Dual Policy Iteration
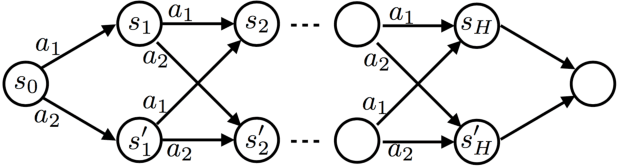
May 28, 2018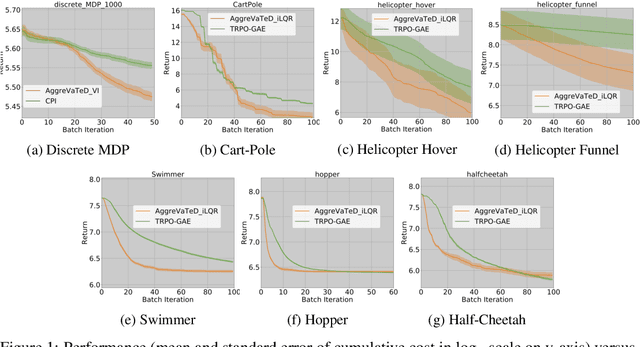
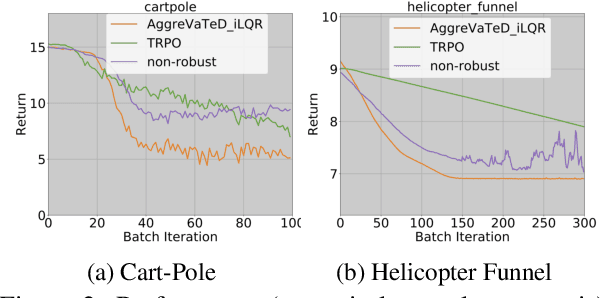
Recently, a novel class of Approximate Policy Iteration (API) algorithms have demonstrated impressive practical performance (e.g., ExIt from [2], AlphaGo-Zero from [27]). This new family of algorithms maintains, and alternately optimizes, two policies: a fast, reactive policy (e.g., a deep neural network) deployed at test time, and a slow, non-reactive policy (e.g., Tree Search), that can plan multiple steps ahead. The reactive policy is updated under supervision from the non-reactive policy, while the non-reactive policy is improved with guidance from the reactive policy. In this work we study this Dual Policy Iteration (DPI) strategy in an alternating optimization framework and provide a convergence analysis that extends existing API theory. We also develop a special instance of this framework which reduces the update of non-reactive policies to model-based optimal control using learned local models, and provides a theoretically sound way of unifying model-free and model-based RL approaches with unknown dynamics. We demonstrate the efficacy of our approach on various continuous control Markov Decision Processes.
Fast Policy Learning through Imitation and Reinforcement
May 26, 2018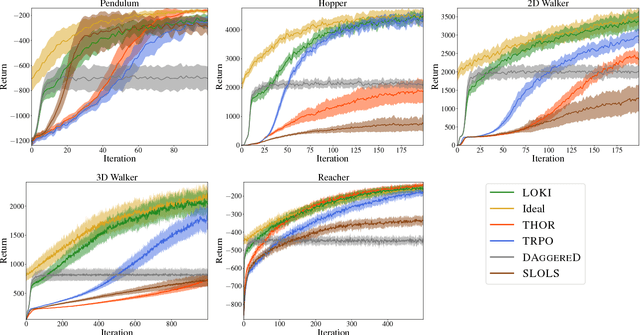
Imitation learning (IL) consists of a set of tools that leverage expert demonstrations to quickly learn policies. However, if the expert is suboptimal, IL can yield policies with inferior performance compared to reinforcement learning (RL). In this paper, we aim to provide an algorithm that combines the best aspects of RL and IL. We accomplish this by formulating several popular RL and IL algorithms in a common mirror descent framework, showing that these algorithms can be viewed as a variation on a single approach. We then propose LOKI, a strategy for policy learning that first performs a small but random number of IL iterations before switching to a policy gradient RL method. We show that if the switching time is properly randomized, LOKI can learn to outperform a suboptimal expert and converge faster than running policy gradient from scratch. Finally, we evaluate the performance of LOKI experimentally in several simulated environments.
Deep Forward and Inverse Perceptual Models for Tracking and Prediction
May 20, 2018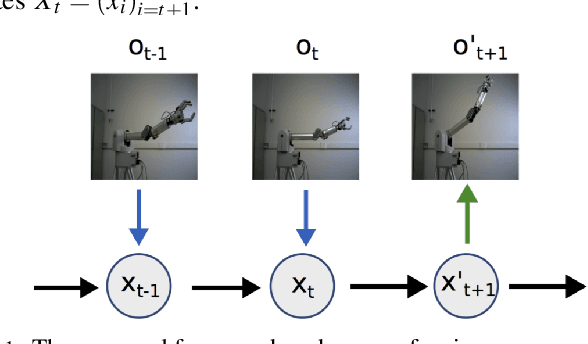
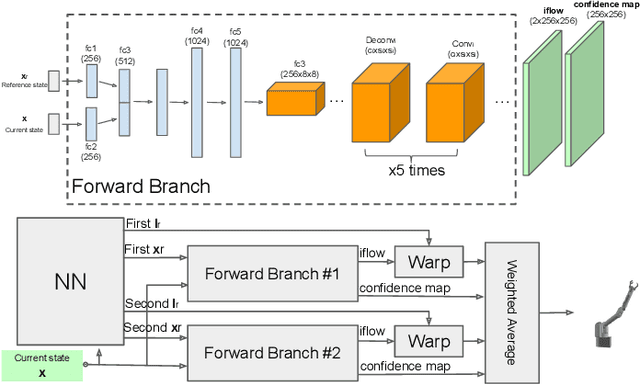
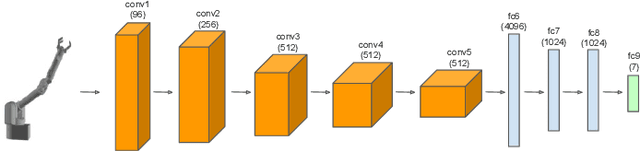

We consider the problems of learning forward models that map state to high-dimensional images and inverse models that map high-dimensional images to state in robotics. Specifically, we present a perceptual model for generating video frames from state with deep networks, and provide a framework for its use in tracking and prediction tasks. We show that our proposed model greatly outperforms standard deconvolutional methods and GANs for image generation, producing clear, photo-realistic images. We also develop a convolutional neural network model for state estimation and compare the result to an Extended Kalman Filter to estimate robot trajectories. We validate all models on a real robotic system.
Convergence of Value Aggregation for Imitation Learning
Jan 22, 2018Value aggregation is a general framework for solving imitation learning problems. Based on the idea of data aggregation, it generates a policy sequence by iteratively interleaving policy optimization and evaluation in an online learning setting. While the existence of a good policy in the policy sequence can be guaranteed non-asymptotically, little is known about the convergence of the sequence or the performance of the last policy. In this paper, we debunk the common belief that value aggregation always produces a convergent policy sequence with improving performance. Moreover, we identify a critical stability condition for convergence and provide a tight non-asymptotic bound on the performance of the last policy. These new theoretical insights let us stabilize problems with regularization, which removes the inconvenient process of identifying the best policy in the policy sequence in stochastic problems.
Variational Inference for Gaussian Process Models with Linear Complexity
Jan 22, 2018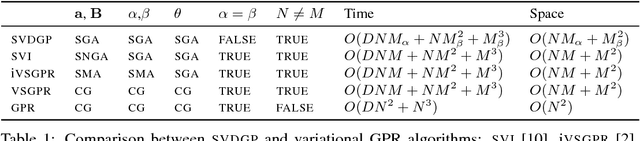
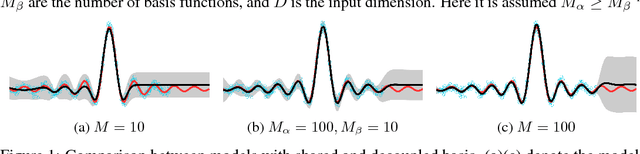
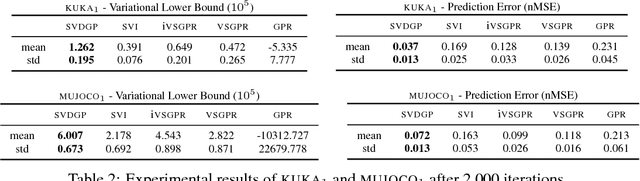
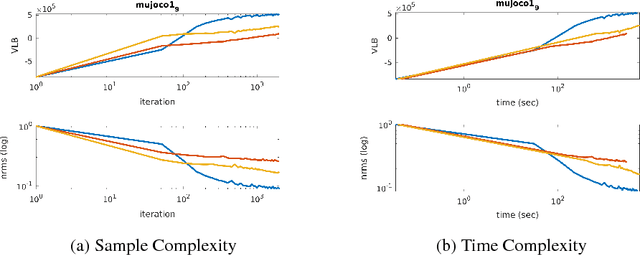
Large-scale Gaussian process inference has long faced practical challenges due to time and space complexity that is superlinear in dataset size. While sparse variational Gaussian process models are capable of learning from large-scale data, standard strategies for sparsifying the model can prevent the approximation of complex functions. In this work, we propose a novel variational Gaussian process model that decouples the representation of mean and covariance functions in reproducing kernel Hilbert space. We show that this new parametrization generalizes previous models. Furthermore, it yields a variational inference problem that can be solved by stochastic gradient ascent with time and space complexity that is only linear in the number of mean function parameters, regardless of the choice of kernels, likelihoods, and inducing points. This strategy makes the adoption of large-scale expressive Gaussian process models possible. We run several experiments on regression tasks and show that this decoupled approach greatly outperforms previous sparse variational Gaussian process inference procedures.