 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActive Flow Expansion for Out-of-Distribution Discovery: from Theory to Molecules
Jun 07, 2026Standard flow and diffusion pre-training matches the distribution of available data (e.g., molecules), which often covers only a small fraction of the valid design space. In generative discovery, however, one aims to sample valid new-to-nature designs, assigned negligible probability under, and thus inaccessible to, standard models fitted to the observed data. To overcome this limitation, we depart from data distribution matching and view a generative model through its generable set: the region it covers with non-negligible probability. This allows to introduce a new learning principle for out-of-distribution flow modeling: enlarging a model's generable set to increase coverage of the valid design space. We propose Active Flow Expansion (ActFlow), a continued pre-training method that employs verifier feedback to expand a pre-trained model over new valid regions by iteratively adapting to synthetic data generated through active exploration in the learned flow representation. Theoretically, we establish to our knowledge first-of-their-kind statistical learning guarantees for out-of-distribution flow modeling, analyzing generable set expansion as a local-to-global reachability process over a learned representation. Empirically, we assess ActFlow with suitable out-of-distribution generative modeling metrics across small organic molecules, mid-sized drug-like molecules, therapeutic peptides, and protein sequence design tasks. Results show that ActFlow expands valid coverage far beyond the region modeled by the initial pre-trained model, significantly outperforming widely adopted synthetic flow pre-training methods.
A Tutorial on the Non-Asymptotic Theory of System Identification
Sep 07, 2023This tutorial serves as an introduction to recently developed non-asymptotic methods in the theory of -- mainly linear -- system identification. We emphasize tools we deem particularly useful for a range of problems in this domain, such as the covering technique, the Hanson-Wright Inequality and the method of self-normalized martingales. We then employ these tools to give streamlined proofs of the performance of various least-squares based estimators for identifying the parameters in autoregressive models. We conclude by sketching out how the ideas presented herein can be extended to certain nonlinear identification problems.
How Are Learned Perception-Based Controllers Impacted by the Limits of Robust Control?
Apr 02, 2021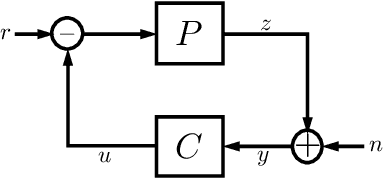
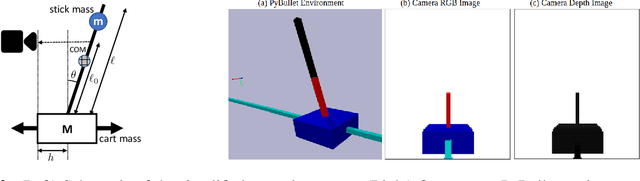
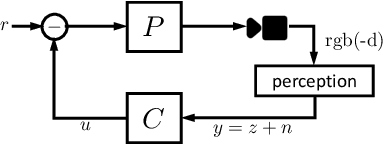
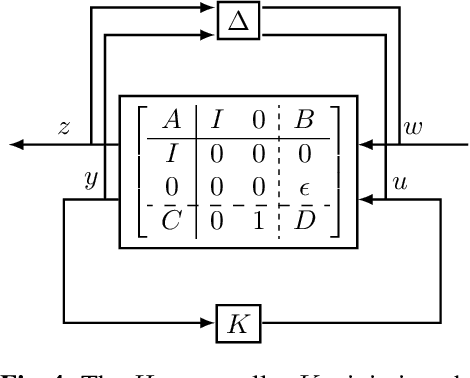
The difficulty of optimal control problems has classically been characterized in terms of system properties such as minimum eigenvalues of controllability/observability gramians. We revisit these characterizations in the context of the increasing popularity of data-driven techniques like reinforcement learning (RL), and in control settings where input observations are high-dimensional images and transition dynamics are unknown. Specifically, we ask: to what extent are quantifiable control and perceptual difficulty metrics of a task predictive of the performance and sample complexity of data-driven controllers? We modulate two different types of partial observability in a cartpole "stick-balancing" problem -- (i) the height of one visible fixation point on the cartpole, which can be used to tune fundamental limits of performance achievable by any controller, and by (ii) the level of perception noise in the fixation point position inferred from depth or RGB images of the cartpole. In these settings, we empirically study two popular families of controllers: RL and system identification-based $H_\infty$ control, using visually estimated system state. Our results show that the fundamental limits of robust control have corresponding implications for the sample-efficiency and performance of learned perception-based controllers. Visit our project website https://jxu.ai/rl-vs-control-web for more information.