 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnatomy-aware and acquisition-agnostic joint registration with SynthMorph
Jan 26, 2023Affine image registration is a cornerstone of medical-image processing and analysis. While classical algorithms can achieve excellent accuracy, they solve a time-consuming optimization for every new image pair. Deep-learning (DL) methods learn a function that maps an image pair to an output transform. Evaluating the functions is fast, but capturing large transforms can be challenging, and networks tend to struggle if a test-image characteristic shifts from the training domain, such as the contrast or resolution. A majority of affine methods are also agnostic to the anatomy the user wishes to align; the registration will be inaccurate if algorithms consider all structures in the image. We address these shortcomings with a fast, robust, and easy-to-use DL tool for affine and deformable registration of any brain image without preprocessing, right off the MRI scanner. First, we rigorously analyze how competing architectures learn affine transforms across a diverse set of neuroimaging data, aiming to truly capture the behavior of methods in the real world. Second, we leverage a recent strategy to train networks with wildly varying images synthesized from label maps, yielding robust performance across acquisition specifics. Third, we optimize the spatial overlap of select anatomical labels, which enables networks to distinguish between anatomy of interest and irrelevant structures, removing the need for preprocessing that excludes content that would otherwise reduce the accuracy of anatomy-specific registration. We combine the affine model with prior work on deformable registration and test brain-specific registration across a landscape of MRI protocols unseen at training, demonstrating consistent and improved accuracy compared to existing tools. We distribute our code and tool at https://w3id.org/synthmorph, providing a single complete end-to-end solution for registration of brain MRI.
Data Consistent Deep Rigid MRI Motion Correction
Jan 25, 2023



Motion artifacts are a pervasive problem in MRI, leading to misdiagnosis or mischaracterization in population-level imaging studies. Current retrospective rigid intra-slice motion correction techniques jointly optimize estimates of the image and the motion parameters. In this paper, we use a deep network to reduce the joint image-motion parameter search to a search over rigid motion parameters alone. Our network produces a reconstruction as a function of two inputs: corrupted k-space data and motion parameters. We train the network using simulated, motion-corrupted k-space data generated from known motion parameters. At test-time, we estimate unknown motion parameters by minimizing a data consistency loss between the motion parameters, the network-based image reconstruction given those parameters, and the acquired measurements. Intra-slice motion correction experiments on simulated and realistic 2D fast spin echo brain MRI achieve high reconstruction fidelity while retaining the benefits of explicit data consistency-based optimization. Our code is publicly available at https://www.github.com/nalinimsingh/neuroMoCo.
SuperWarp: Supervised Learning and Warping on U-Net for Invariant Subvoxel-Precise Registration
May 15, 2022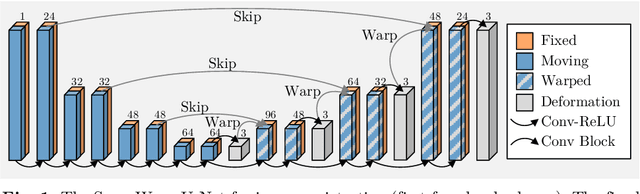

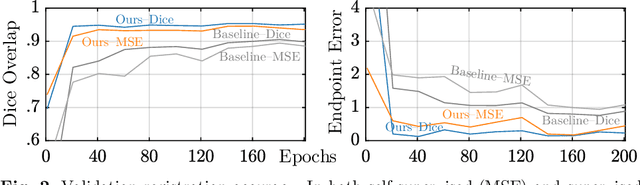

In recent years, learning-based image registration methods have gradually moved away from direct supervision with target warps to instead use self-supervision, with excellent results in several registration benchmarks. These approaches utilize a loss function that penalizes the intensity differences between the fixed and moving images, along with a suitable regularizer on the deformation. In this paper, we argue that the relative failure of supervised registration approaches can in part be blamed on the use of regular U-Nets, which are jointly tasked with feature extraction, feature matching, and estimation of deformation. We introduce one simple but crucial modification to the U-Net that disentangles feature extraction and matching from deformation prediction, allowing the U-Net to warp the features, across levels, as the deformation field is evolved. With this modification, direct supervision using target warps begins to outperform self-supervision approaches that require segmentations, presenting new directions for registration when images do not have segmentations. We hope that our findings in this preliminary workshop paper will re-ignite research interest in supervised image registration techniques. Our code is publicly available from https://github.com/balbasty/superwarp.
Learning the Effect of Registration Hyperparameters with HyperMorph
Mar 30, 2022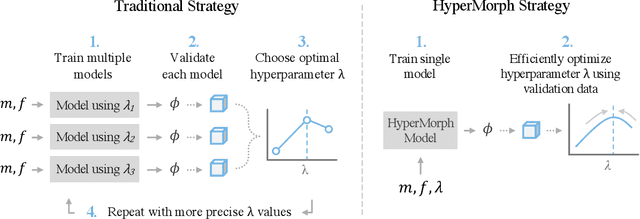
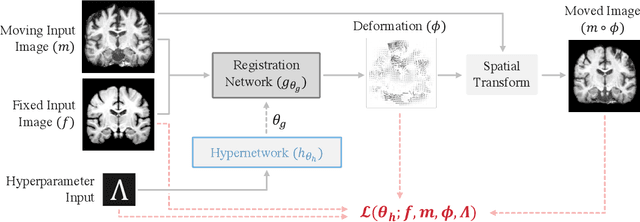

We introduce HyperMorph, a framework that facilitates efficient hyperparameter tuning in learning-based deformable image registration. Classical registration algorithms perform an iterative pair-wise optimization to compute a deformation field that aligns two images. Recent learning-based approaches leverage large image datasets to learn a function that rapidly estimates a deformation for a given image pair. In both strategies, the accuracy of the resulting spatial correspondences is strongly influenced by the choice of certain hyperparameter values. However, an effective hyperparameter search consumes substantial time and human effort as it often involves training multiple models for different fixed hyperparameter values and may lead to suboptimal registration. We propose an amortized hyperparameter learning strategy to alleviate this burden by learning the impact of hyperparameters on deformation fields. We design a meta network, or hypernetwork, that predicts the parameters of a registration network for input hyperparameters, thereby comprising a single model that generates the optimal deformation field corresponding to given hyperparameter values. This strategy enables fast, high-resolution hyperparameter search at test-time, reducing the inefficiency of traditional approaches while increasing flexibility. We also demonstrate additional benefits of HyperMorph, including enhanced robustness to model initialization and the ability to rapidly identify optimal hyperparameter values specific to a dataset, image contrast, task, or even anatomical region, all without the need to retrain models. We make our code publicly available at http://hypermorph.voxelmorph.net.
SynthStrip: Skull-Stripping for Any Brain Image
Mar 18, 2022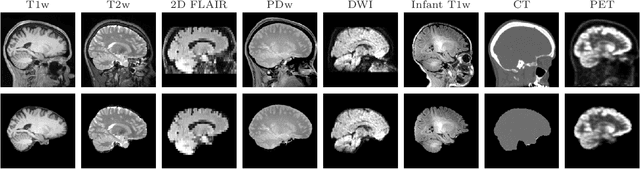
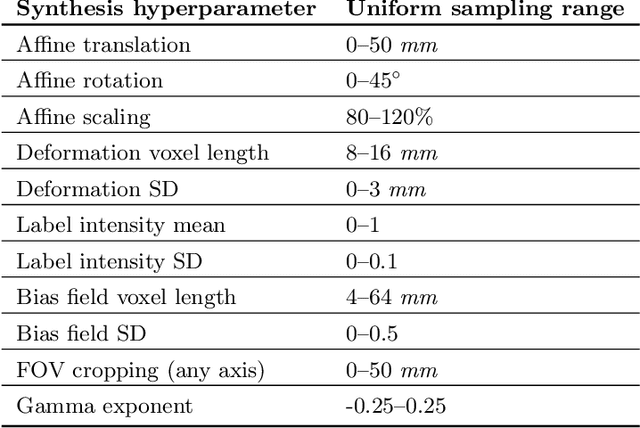
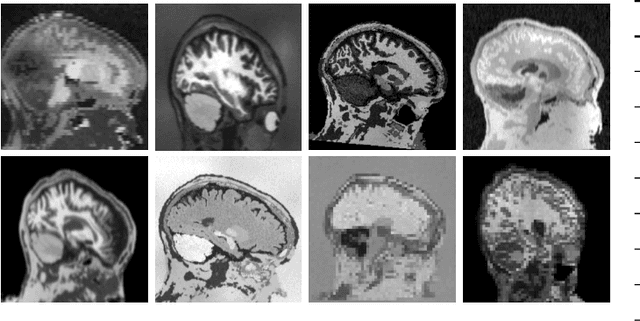
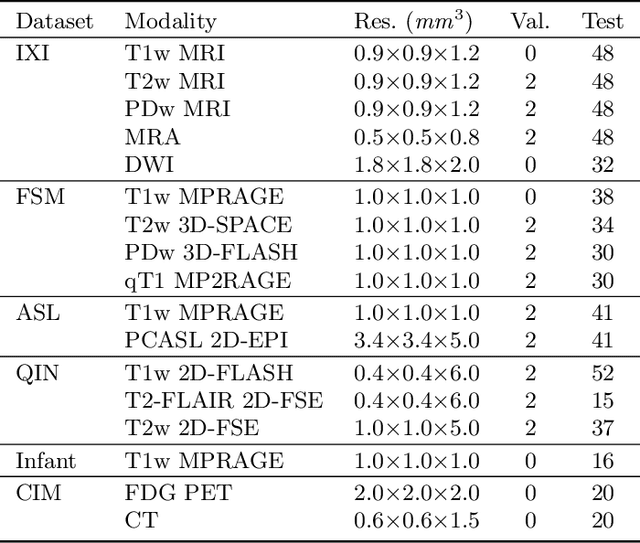
The removal of non-brain signal from magnetic resonance imaging (MRI) data, known as skull-stripping, is an integral component of many neuroimage analysis streams. Despite their abundance, popular classical skull-stripping methods are usually tailored to images with specific acquisition properties, namely near-isotropic resolution and T1-weighted (T1w) MRI contrast, which are prevalent in research settings. As a result, existing tools tend to adapt poorly to other image types, such as stacks of thick slices acquired with fast spin-echo (FSE) MRI that are common in the clinic. While learning-based approaches for brain extraction have gained traction in recent years, these methods face a similar burden, as they are only effective for image types seen during the training procedure. To achieve robust skull-stripping across a landscape of protocols, we introduce SynthStrip, a rapid, learning-based brain-extraction tool. By leveraging anatomical segmentations to generate an entirely synthetic training dataset with anatomies, intensity distributions, and artifacts that far exceed the realistic range of medical images, SynthStrip learns to successfully generalize to a variety of real acquired brain images, removing the need for training data with target contrasts. We demonstrate the efficacy of SynthStrip for a diverse set of image acquisitions and resolutions across subject populations, ranging from newborn to adult. We show substantial improvements in accuracy over popular skull-stripping baselines - all with a single trained model. Our method and labeled evaluation data are available at https://w3id.org/synthstrip.
SUD: Supervision by Denoising for Medical Image Segmentation
Feb 07, 2022Training a fully convolutional network for semantic segmentation typically requires a large, labeled dataset with little label noise if good generalization is to be guaranteed. For many segmentation problems, however, data with pixel- or voxel-level labeling accuracy are scarce due to the cost of manual labeling. This problem is exacerbated in domains where manual annotation is difficult, resulting in large amounts of variability in the labeling even across domain experts. Therefore, training segmentation networks to generalize better by learning from both labeled and unlabeled images (called semi-supervised learning) is problem of both practical and theoretical interest. However, traditional semi-supervised learning methods for segmentation often necessitate hand-crafting a differentiable regularizer specific to a given segmentation problem, which can be extremely time-consuming. In this work, we propose "supervision by denoising" (SUD), a framework that enables us to supervise segmentation models using their denoised output as targets. SUD unifies temporal ensembling and spatial denoising techniques under a spatio-temporal denoising framework and alternates denoising and network weight update in an optimization framework for semi-supervision. We validate SUD on three tasks-kidney and tumor (3D), and brain (3D) segmentation, and cortical parcellation (2D)-demonstrating a significant improvement in the Dice overlap and the Hausdorff distance of segmentations over supervised-only and temporal ensemble baselines.
SynthSeg: Domain Randomisation for Segmentation of Brain MRI Scans of any Contrast and Resolution
Jul 20, 2021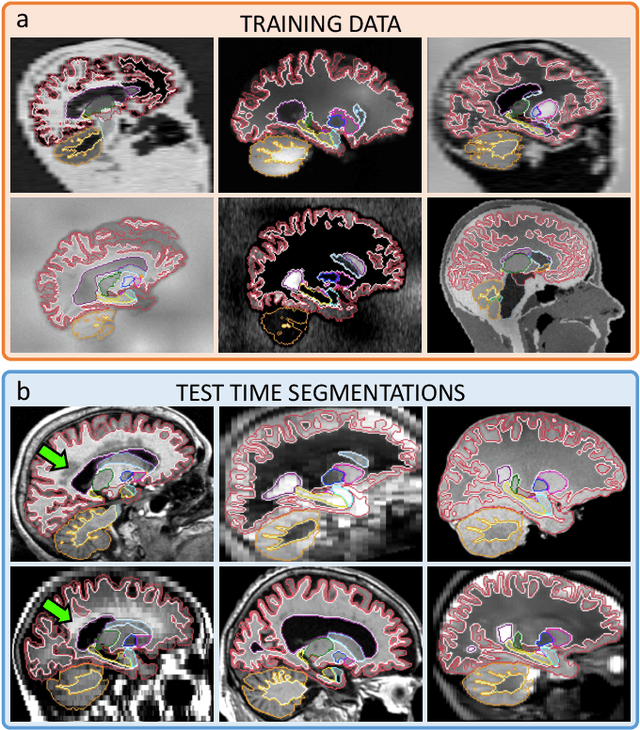
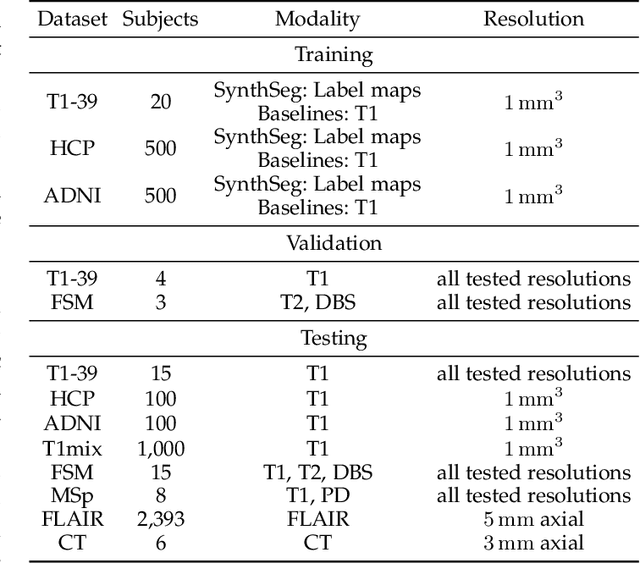
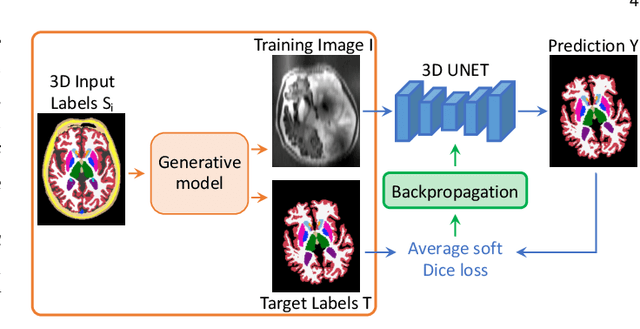
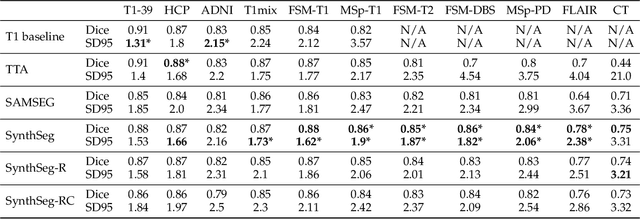
Despite advances in data augmentation and transfer learning, convolutional neural networks (CNNs) have difficulties generalising to unseen target domains. When applied to segmentation of brain MRI scans, CNNs are highly sensitive to changes in resolution and contrast: even within the same MR modality, decreases in performance can be observed across datasets. We introduce SynthSeg, the first segmentation CNN agnostic to brain MRI scans of any contrast and resolution. SynthSeg is trained with synthetic data sampled from a generative model inspired by Bayesian segmentation. Crucially, we adopt a \textit{domain randomisation} strategy where we fully randomise the generation parameters to maximise the variability of the training data. Consequently, SynthSeg can segment preprocessed and unpreprocessed real scans of any target domain, without retraining or fine-tuning. Because SynthSeg only requires segmentations to be trained (no images), it can learn from label maps obtained automatically from existing datasets of different populations (e.g., with atrophy and lesions), thus achieving robustness to a wide range of morphological variability. We demonstrate SynthSeg on 5,500 scans of 6 modalities and 10 resolutions, where it exhibits unparalleled generalisation compared to supervised CNNs, test time adaptation, and Bayesian segmentation. The code and trained model are available at https://github.com/BBillot/SynthSeg.
Unsupervised learning of MRI tissue properties using MRI physics models
Jul 06, 2021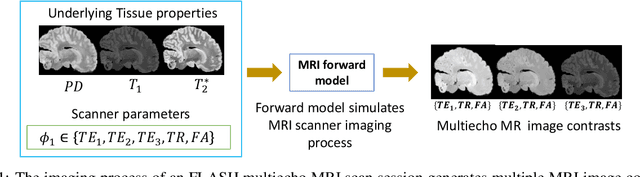

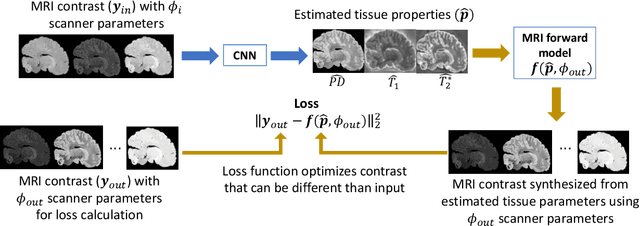
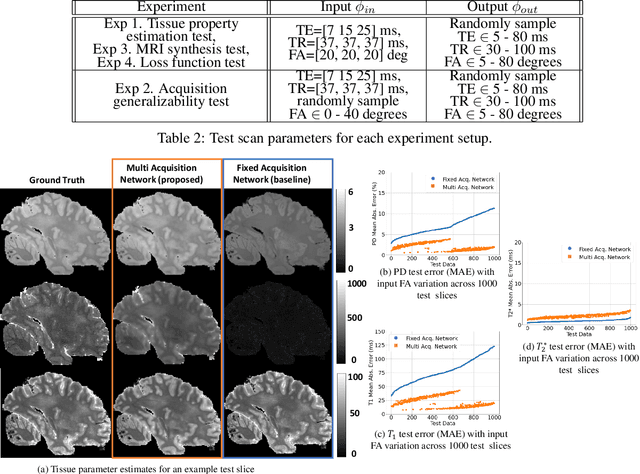
In neuroimaging, MRI tissue properties characterize underlying neurobiology, provide quantitative biomarkers for neurological disease detection and analysis, and can be used to synthesize arbitrary MRI contrasts. Estimating tissue properties from a single scan session using a protocol available on all clinical scanners promises to reduce scan time and cost, enable quantitative analysis in routine clinical scans and provide scan-independent biomarkers of disease. However, existing tissue properties estimation methods - most often $\mathbf{T_1}$ relaxation, $\mathbf{T_2^*}$ relaxation, and proton density ($\mathbf{PD}$) - require data from multiple scan sessions and cannot estimate all properties from a single clinically available MRI protocol such as the multiecho MRI scan. In addition, the widespread use of non-standard acquisition parameters across clinical imaging sites require estimation methods that can generalize across varying scanner parameters. However, existing learning methods are acquisition protocol specific and cannot estimate from heterogenous clinical data from different imaging sites. In this work we propose an unsupervised deep-learning strategy that employs MRI physics to estimate all three tissue properties from a single multiecho MRI scan session, and generalizes across varying acquisition parameters. The proposed strategy optimizes accurate synthesis of new MRI contrasts from estimated latent tissue properties, enabling unsupervised training, we also employ random acquisition parameters during training to achieve acquisition generalization. We provide the first demonstration of estimating all tissue properties from a single multiecho scan session. We demonstrate improved accuracy and generalizability for tissue property estimation and MRI synthesis.
Robust joint registration of multiple stains and MRI for multimodal 3D histology reconstruction: Application to the Allen human brain atlas
May 04, 2021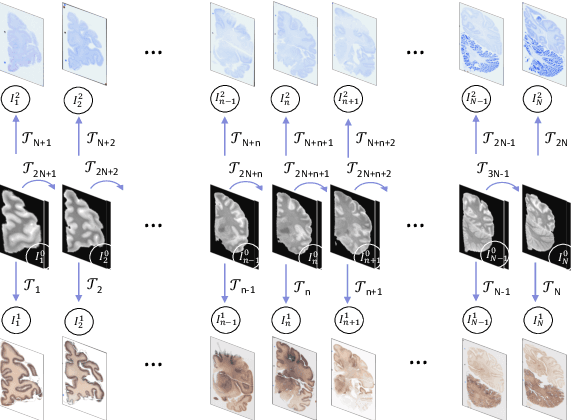
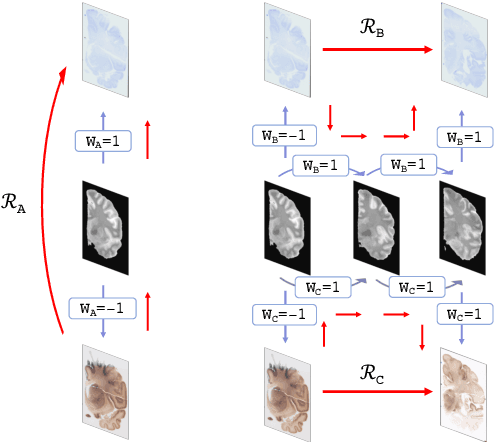
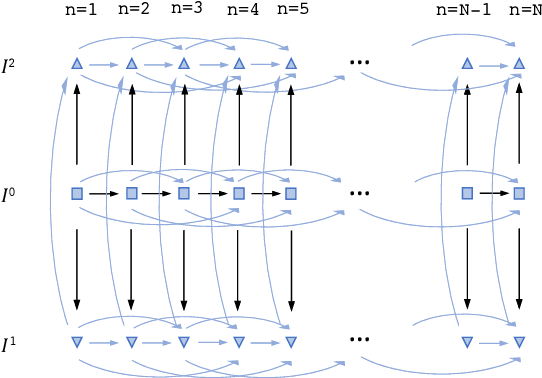
Joint registration of a stack of 2D histological sections to recover 3D structure (3D histology reconstruction) finds application in areas such as atlas building and validation of in vivo imaging. Straighforward pairwise registration of neighbouring sections yields smooth reconstructions but has well-known problems such as banana effect (straightening of curved structures) and z-shift (drift). While these problems can be alleviated with an external, linearly aligned reference (e.g., Magnetic Resonance images), registration is often inaccurate due to contrast differences and the strong nonlinear distortion of the tissue, including artefacts such as folds and tears. In this paper, we present a probabilistic model of spatial deformation that yields reconstructions for multiple histological stains that that are jointly smooth, robust to outliers, and follow the reference shape. The model relies on a spanning tree of latent transforms connecting all the sections and slices, and assumes that the registration between any pair of images can be see as a noisy version of the composition of (possibly inverted) latent transforms connecting the two images. Bayesian inference is used to compute the most likely latent transforms given a set of pairwise registrations between image pairs within and across modalities. Results on synthetic deformations on multiple MR modalities, show that our method can accurately and robustly register multiple contrasts even in the presence of outliers. The 3D histology reconstruction of two stains (Nissl and parvalbumin) from the Allen human brain atlas, show its benefits on real data with severe distortions. We also provide the correspondence to MNI space, bridging the gap between two of the most used atlases in histology and MRI. Data is available at https://openneuro.org/datasets/ds003590 and code at https://github.com/acasamitjana/3dhirest.
HyperMorph: Amortized Hyperparameter Learning for Image Registration
Jan 04, 2021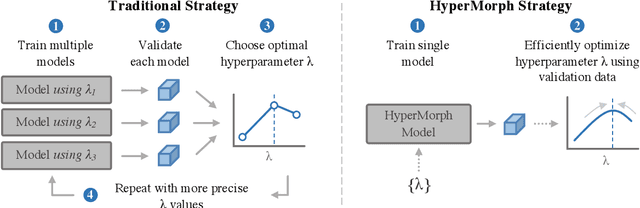

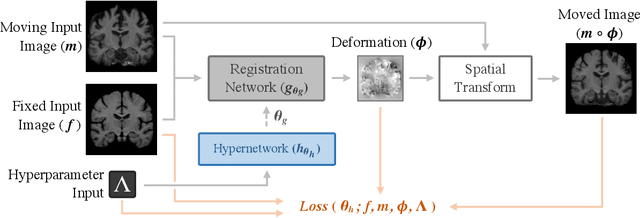
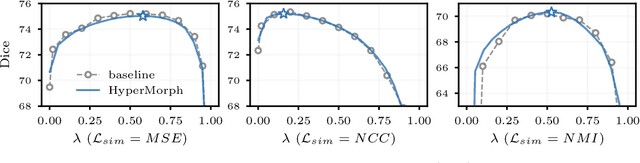
We present HyperMorph, a learning-based strategy for deformable image registration that removes the need to tune important registration hyperparameters during training. Classical registration methods solve an optimization problem to find a set of spatial correspondences between two images, while learning-based methods leverage a training dataset to learn a function that generates these correspondences. The quality of the results for both types of techniques depends greatly on the choice of hyperparameters. Unfortunately, hyperparameter tuning is time-consuming and typically involves training many separate models with various hyperparameter values, potentially leading to suboptimal results. To address this inefficiency, we introduce amortized hyperparameter learning for image registration, a novel strategy to learn the effects of hyperparameters on deformation fields. The proposed framework learns a hypernetwork that takes in an input hyperparameter and modulates a registration network to produce the optimal deformation field for that hyperparameter value. In effect, this strategy trains a single, rich model that enables rapid, fine-grained discovery of hyperparameter values from a continuous interval at test-time. We demonstrate that this approach can be used to optimize multiple hyperparameters considerably faster than existing search strategies, leading to a reduced computational and human burden and increased flexibility. We also show that this has several important benefits, including increased robustness to initialization and the ability to rapidly identify optimal hyperparameter values specific to a registration task, dataset, or even a single anatomical region - all without retraining the HyperMorph model. Our code is publicly available at http://voxelmorph.mit.edu.