 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrajFlow: Multi-modal Motion Prediction via Flow Matching
Jun 10, 2025Efficient and accurate motion prediction is crucial for ensuring safety and informed decision-making in autonomous driving, particularly under dynamic real-world conditions that necessitate multi-modal forecasts. We introduce TrajFlow, a novel flow matching-based motion prediction framework that addresses the scalability and efficiency challenges of existing generative trajectory prediction methods. Unlike conventional generative approaches that employ i.i.d. sampling and require multiple inference passes to capture diverse outcomes, TrajFlow predicts multiple plausible future trajectories in a single pass, significantly reducing computational overhead while maintaining coherence across predictions. Moreover, we propose a ranking loss based on the Plackett-Luce distribution to improve uncertainty estimation of predicted trajectories. Additionally, we design a self-conditioning training technique that reuses the model's own predictions to construct noisy inputs during a second forward pass, thereby improving generalization and accelerating inference. Extensive experiments on the large-scale Waymo Open Motion Dataset (WOMD) demonstrate that TrajFlow achieves state-of-the-art performance across various key metrics, underscoring its effectiveness for safety-critical autonomous driving applications. The code and other details are available on the project website https://traj-flow.github.io/.
ProspectNet: Weighted Conditional Attention for Future Interaction Modeling in Behavior Prediction
Aug 29, 2022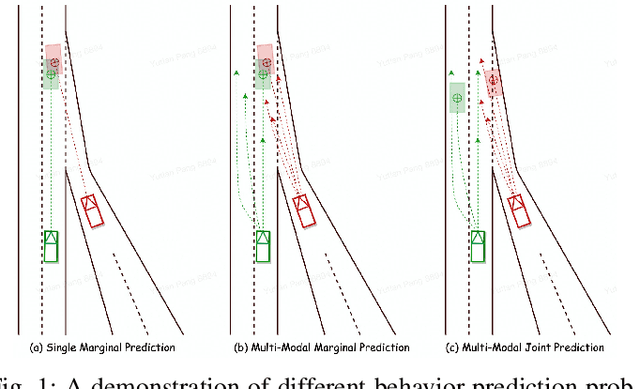


Behavior prediction plays an important role in integrated autonomous driving software solutions. In behavior prediction research, interactive behavior prediction is a less-explored area, compared to single-agent behavior prediction. Predicting the motion of interactive agents requires initiating novel mechanisms to capture the joint behaviors of the interactive pairs. In this work, we formulate the end-to-end joint prediction problem as a sequential learning process of marginal learning and joint learning of vehicle behaviors. We propose ProspectNet, a joint learning block that adopts the weighted attention score to model the mutual influence between interactive agent pairs. The joint learning block first weighs the multi-modal predicted candidate trajectories, then updates the ego-agent's embedding via cross attention. Furthermore, we broadcast the individual future predictions for each interactive agent into a pair-wise scoring module to select the top $K$ prediction pairs. We show that ProspectNet outperforms the Cartesian product of two marginal predictions, and achieves comparable performance on the Waymo Interactive Motion Prediction benchmarks.
Radar Camera Fusion via Representation Learning in Autonomous Driving
Mar 14, 2021
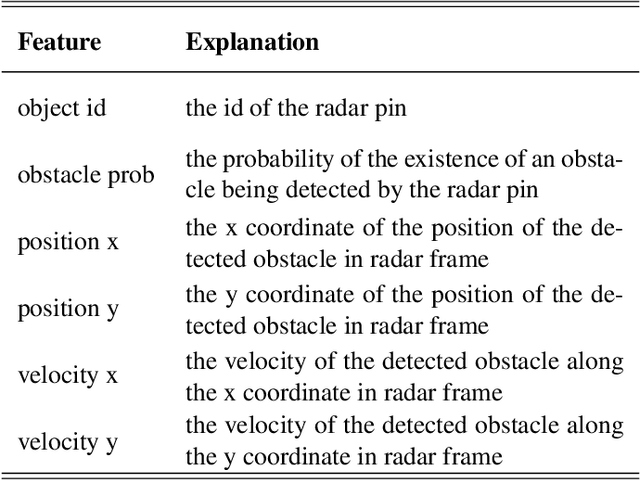

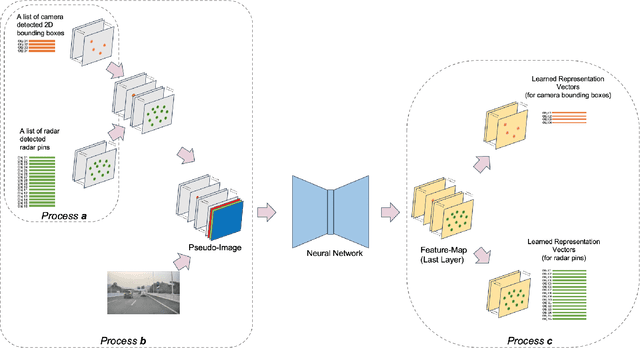
Radars and cameras are mature, cost-effective, and robust sensors and have been widely used in the perception stack of mass-produced autonomous driving systems. Due to their complementary properties, outputs from radar detection (radar pins) and camera perception (2D bounding boxes) are usually fused to generate the best perception results. The key to successful radar-camera fusion is accurate data association. The challenges in radar-camera association can be attributed to the complexity of driving scenes, the noisy and sparse nature of radar measurements, and the depth ambiguity from 2D bounding boxes. Traditional rule-based association methods are susceptible to performance degradation in challenging scenarios and failure in corner cases. In this study, we propose to address rad-cam association via deep representation learning, to explore feature-level interaction and global reasoning. Concretely, we design a loss sampling mechanism and an innovative ordinal loss to overcome the difficulty of imperfect labeling and to enforce critical human reasoning. Despite being trained with noisy labels generated by a rule-based algorithm, our proposed method achieves a performance of 92.2% F1 score, which is 11.6% higher than the rule-based teacher. Moreover, this data-driven method also lends itself to continuous improvement via corner case mining.