 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtending Implicit Discourse Relation Recognition to the PDTB-3
Oct 13, 2020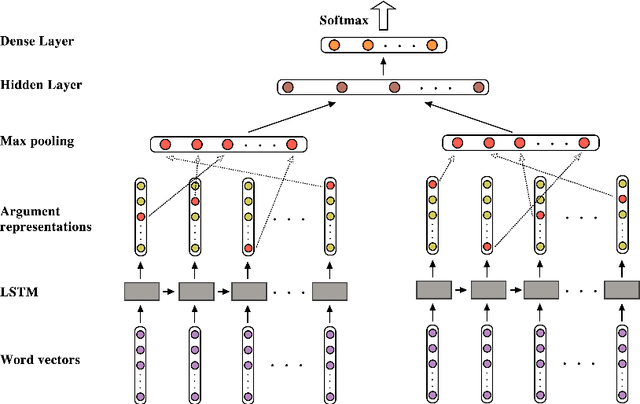
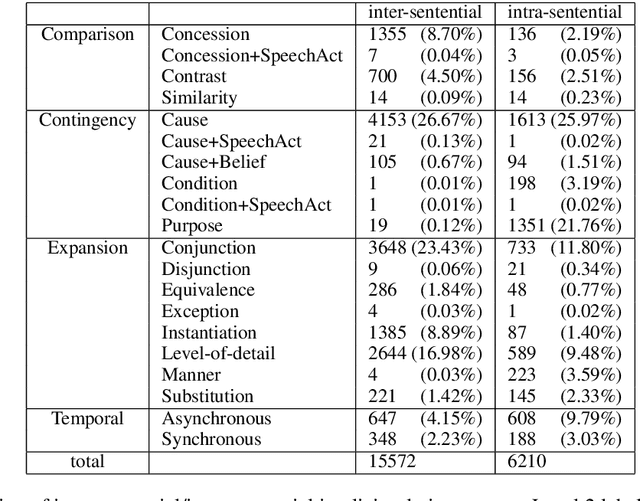
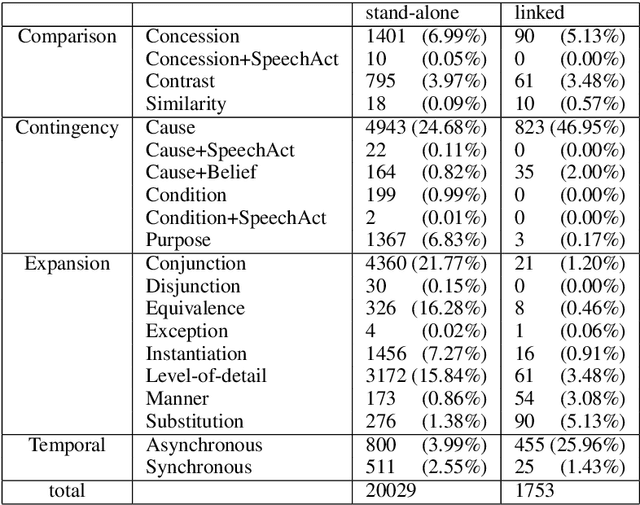
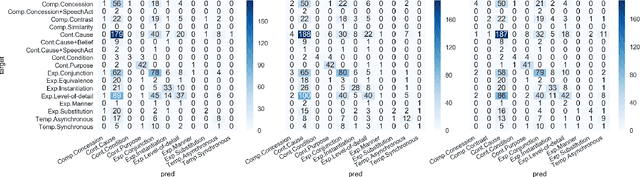
The PDTB-3 contains many more Implicit discourse relations than the previous PDTB-2. This is in part because implicit relations have now been annotated within sentences as well as between them. In addition, some now co-occur with explicit discourse relations, instead of standing on their own. Here we show that while this can complicate the problem of identifying the location of implicit discourse relations, it can in turn simplify the problem of identifying their senses. We present data to support this claim, as well as methods that can serve as a non-trivial baseline for future state-of-the-art recognizers for implicit discourse relations.
Reducing Quantity Hallucinations in Abstractive Summarization
Sep 28, 2020
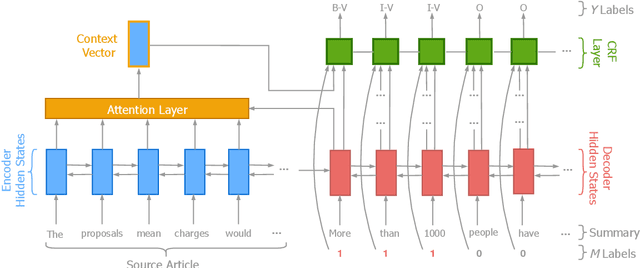

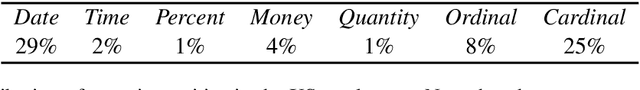
It is well-known that abstractive summaries are subject to hallucination---including material that is not supported by the original text. While summaries can be made hallucination-free by limiting them to general phrases, such summaries would fail to be very informative. Alternatively, one can try to avoid hallucinations by verifying that any specific entities in the summary appear in the original text in a similar context. This is the approach taken by our system, Herman. The system learns to recognize and verify quantity entities (dates, numbers, sums of money, etc.) in a beam-worth of abstractive summaries produced by state-of-the-art models, in order to up-rank those summaries whose quantity terms are supported by the original text. Experimental results demonstrate that the ROUGE scores of such up-ranked summaries have a higher Precision than summaries that have not been up-ranked, without a comparable loss in Recall, resulting in higher F$_1$. Preliminary human evaluation of up-ranked vs. original summaries shows people's preference for the former.
Shallow Discourse Annotation for Chinese TED Talks
Apr 06, 2020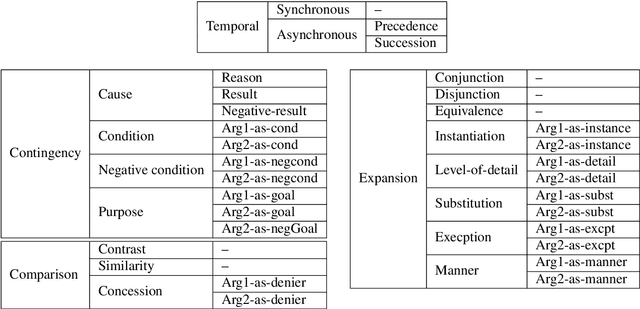
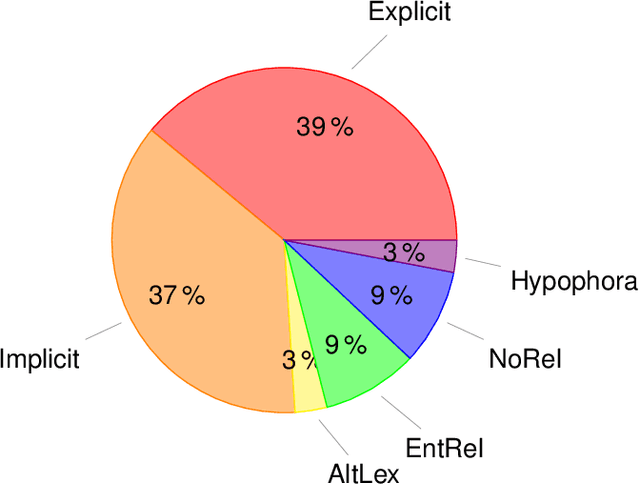
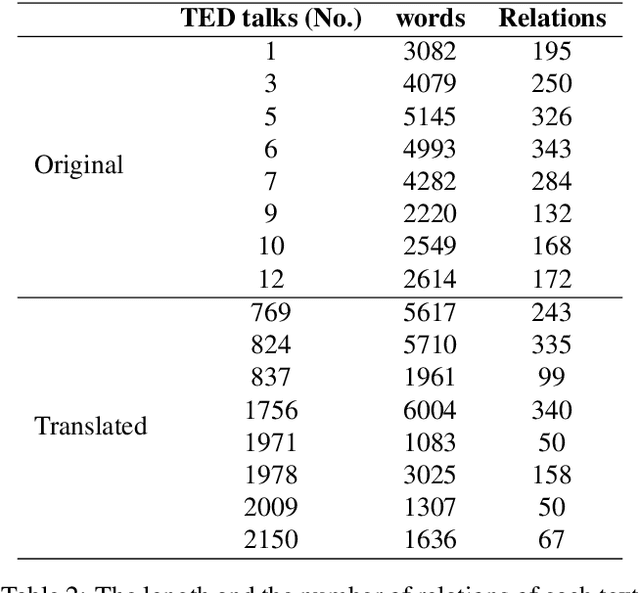
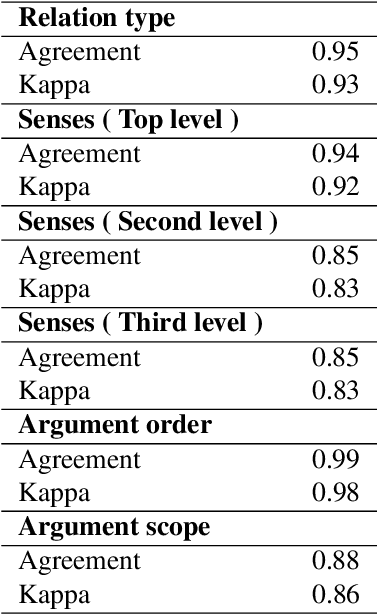
Text corpora annotated with language-related properties are an important resource for the development of Language Technology. The current work contributes a new resource for Chinese Language Technology and for Chinese-English translation, in the form of a set of TED talks (some originally given in English, some in Chinese) that have been annotated with discourse relations in the style of the Penn Discourse TreeBank, adapted to properties of Chinese text that are not present in English. The resource is currently unique in annotating discourse-level properties of planned spoken monologues rather than of written text. An inter-annotator agreement study demonstrates that the annotation scheme is able to achieve highly reliable results.
Findings of the 2016 WMT Shared Task on Cross-lingual Pronoun Prediction
Nov 27, 2019
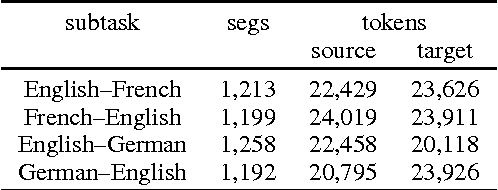

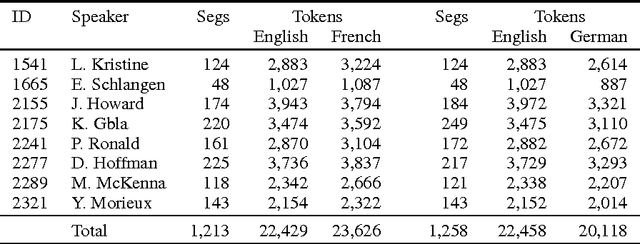
We describe the design, the evaluation setup, and the results of the 2016 WMT shared task on cross-lingual pronoun prediction. This is a classification task in which participants are asked to provide predictions on what pronoun class label should replace a placeholder value in the target-language text, provided in lemmatised and PoS-tagged form. We provided four subtasks, for the English-French and English-German language pairs, in both directions. Eleven teams participated in the shared task; nine for the English-French subtask, five for French-English, nine for English-German, and six for German-English. Most of the submissions outperformed two strong language-model based baseline systems, with systems using deep recurrent neural networks outperforming those using other architectures for most language pairs.
* cross-lingual pronoun prediction, WMT, shared task, English, German, French
GECOR: An End-to-End Generative Ellipsis and Co-reference Resolution Model for Task-Oriented Dialogue
Sep 26, 2019
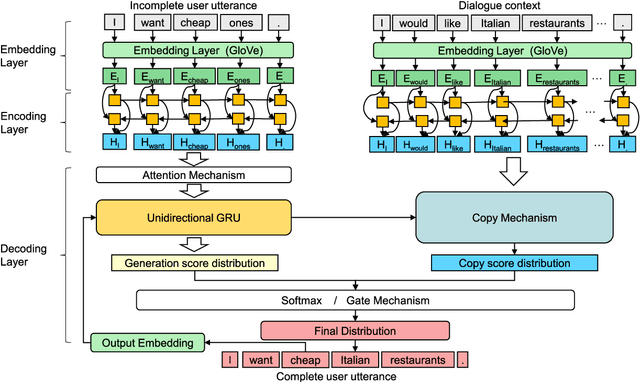
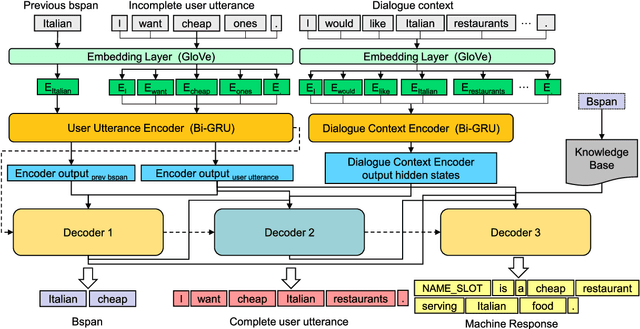

Ellipsis and co-reference are common and ubiquitous especially in multi-turn dialogues. In this paper, we treat the resolution of ellipsis and co-reference in dialogue as a problem of generating omitted or referred expressions from the dialogue context. We therefore propose a unified end-to-end Generative Ellipsis and CO-reference Resolution model (GECOR) in the context of dialogue. The model can generate a new pragmatically complete user utterance by alternating the generation and copy mode for each user utterance. A multi-task learning framework is further proposed to integrate the GECOR into an end-to-end task-oriented dialogue. In order to train both the GECOR and the multi-task learning framework, we manually construct a new dataset on the basis of the public dataset CamRest676 with both ellipsis and co-reference annotation. On this dataset, intrinsic evaluations on the resolution of ellipsis and co-reference show that the GECOR model significantly outperforms the sequence-to-sequence (seq2seq) baseline model in terms of EM, BLEU and F1 while extrinsic evaluations on the downstream dialogue task demonstrate that our multi-task learning framework with GECOR achieves a higher success rate of task completion than TSCP, a state-of-the-art end-to-end task-oriented dialogue model.
A survey of cross-lingual features for zero-shot cross-lingual semantic parsing
Aug 27, 2019
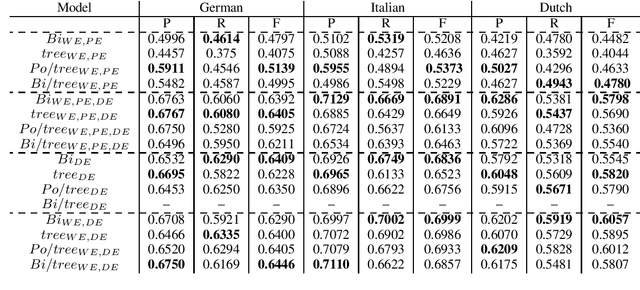
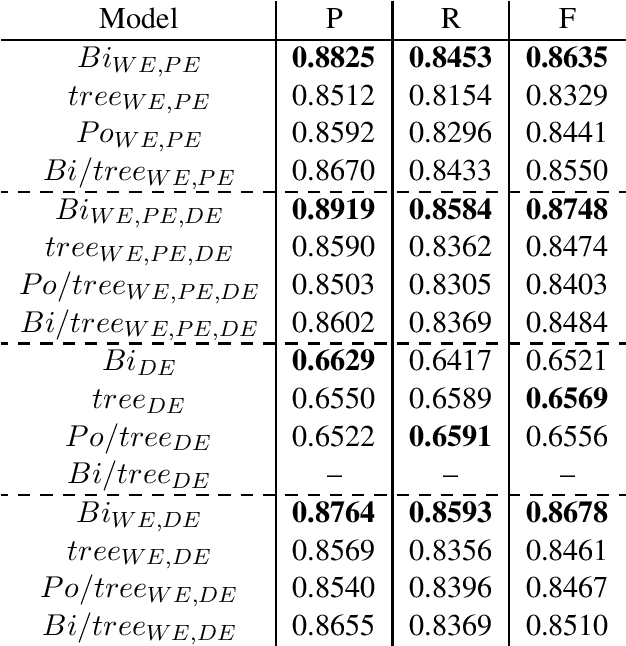
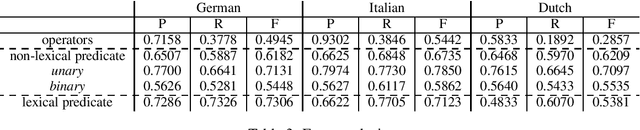
The availability of corpora to train semantic parsers in English has lead to significant advances in the field. Unfortunately, for languages other than English, annotation is scarce and so are developed parsers. We then ask: could a parser trained in English be applied to language that it hasn't been trained on? To answer this question we explore zero-shot cross-lingual semantic parsing where we train an available coarse-to-fine semantic parser (Liu et al., 2018) using cross-lingual word embeddings and universal dependencies in English and test it on Italian, German and Dutch. Results on the Parallel Meaning Bank - a multilingual semantic graphbank, show that Universal Dependency features significantly boost performance when used in conjunction with other lexical features but modelling the UD structure directly when encoding the input does not.
Talking to myself: self-dialogues as data for conversational agents
Sep 19, 2018
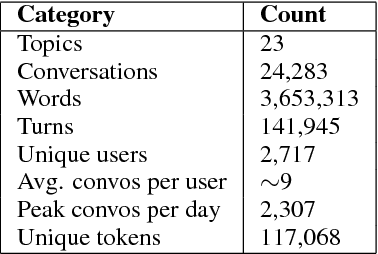
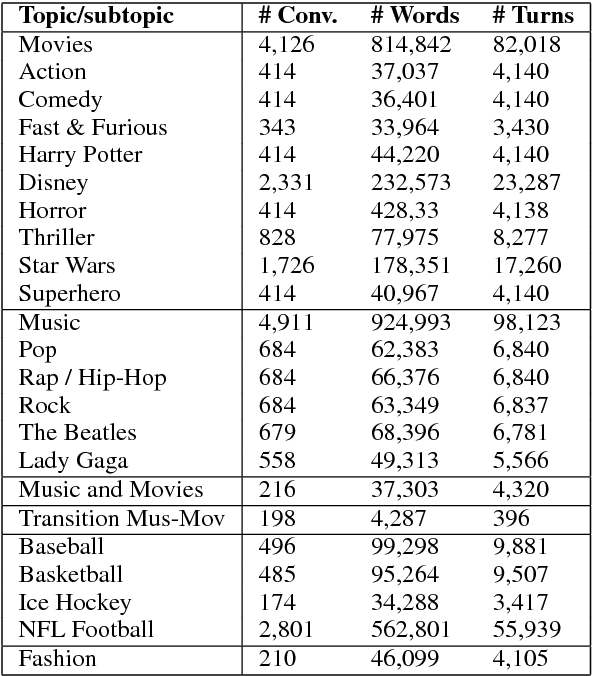
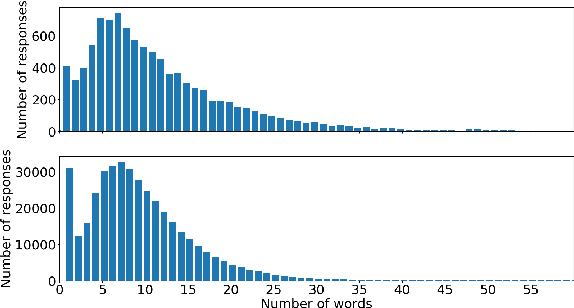
Conversational agents are gaining popularity with the increasing ubiquity of smart devices. However, training agents in a data driven manner is challenging due to a lack of suitable corpora. This paper presents a novel method for gathering topical, unstructured conversational data in an efficient way: self-dialogues through crowd-sourcing. Alongside this paper, we include a corpus of 3.6 million words across 23 topics. We argue the utility of the corpus by comparing self-dialogues with standard two-party conversations as well as data from other corpora.
Evaluating Machine Translation Performance on Chinese Idioms with a Blacklist Method
Feb 20, 2018
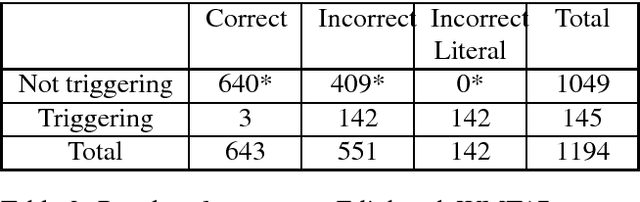

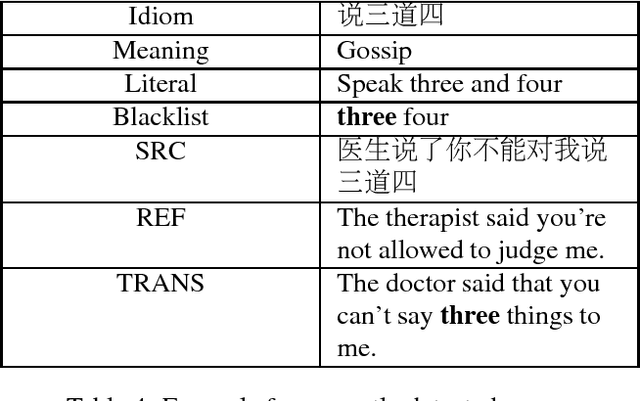
Idiom translation is a challenging problem in machine translation because the meaning of idioms is non-compositional, and a literal (word-by-word) translation is likely to be wrong. In this paper, we focus on evaluating the quality of idiom translation of MT systems. We introduce a new evaluation method based on an idiom-specific blacklist of literal translations, based on the insight that the occurrence of any blacklisted words in the translation output indicates a likely translation error. We introduce a dataset, CIBB (Chinese Idioms Blacklists Bank), and perform an evaluation of a state-of-the-art Chinese-English neural MT system. Our evaluation confirms that a sizable number of idioms in our test set are mistranslated (46.1%), that literal translation error is a common error type, and that our blacklist method is effective at identifying literal translation errors.
Edina: Building an Open Domain Socialbot with Self-dialogues
Sep 28, 2017

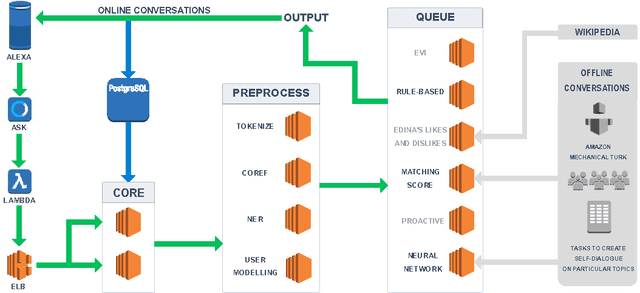

We present Edina, the University of Edinburgh's social bot for the Amazon Alexa Prize competition. Edina is a conversational agent whose responses utilize data harvested from Amazon Mechanical Turk (AMT) through an innovative new technique we call self-dialogues. These are conversations in which a single AMT Worker plays both participants in a dialogue. Such dialogues are surprisingly natural, efficient to collect and reflective of relevant and/or trending topics. These self-dialogues provide training data for a generative neural network as well as a basis for soft rules used by a matching score component. Each match of a soft rule against a user utterance is associated with a confidence score which we show is strongly indicative of reply quality, allowing this component to self-censor and be effectively integrated with other components. Edina's full architecture features a rule-based system backing off to a matching score, backing off to a generative neural network. Our hybrid data-driven methodology thus addresses both coverage limitations of a strictly rule-based approach and the lack of guarantees of a strictly machine-learning approach.
Anaphora and Discourse Structure
Sep 13, 2002We argue in this paper that many common adverbial phrases generally taken to signal a discourse relation between syntactically connected units within discourse structure, instead work anaphorically to contribute relational meaning, with only indirect dependence on discourse structure. This allows a simpler discourse structure to provide scaffolding for compositional semantics, and reveals multiple ways in which the relational meaning conveyed by adverbial connectives can interact with that associated with discourse structure. We conclude by sketching out a lexicalised grammar for discourse that facilitates discourse interpretation as a product of compositional rules, anaphor resolution and inference.