 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHandling Ontology Gaps in Semantic Parsing
Jun 27, 2024



The majority of Neural Semantic Parsing (NSP) models are developed with the assumption that there are no concepts outside the ones such models can represent with their target symbols (closed-world assumption). This assumption leads to generate hallucinated outputs rather than admitting their lack of knowledge. Hallucinations can lead to wrong or potentially offensive responses to users. Hence, a mechanism to prevent this behavior is crucial to build trusted NSP-based Question Answering agents. To that end, we propose the Hallucination Simulation Framework (HSF), a general setting for stimulating and analyzing NSP model hallucinations. The framework can be applied to any NSP task with a closed-ontology. Using the proposed framework and KQA Pro as the benchmark dataset, we assess state-of-the-art techniques for hallucination detection. We then present a novel hallucination detection strategy that exploits the computational graph of the NSP model to detect the NSP hallucinations in the presence of ontology gaps, out-of-domain utterances, and to recognize NSP errors, improving the F1-Score respectively by ~21, ~24% and ~1%. This is the first work in closed-ontology NSP that addresses the problem of recognizing ontology gaps. We release our code and checkpoints at https://github.com/amazon-science/handling-ontology-gaps-in-semantic-parsing.
CLASP: Few-Shot Cross-Lingual Data Augmentation for Semantic Parsing
Oct 14, 2022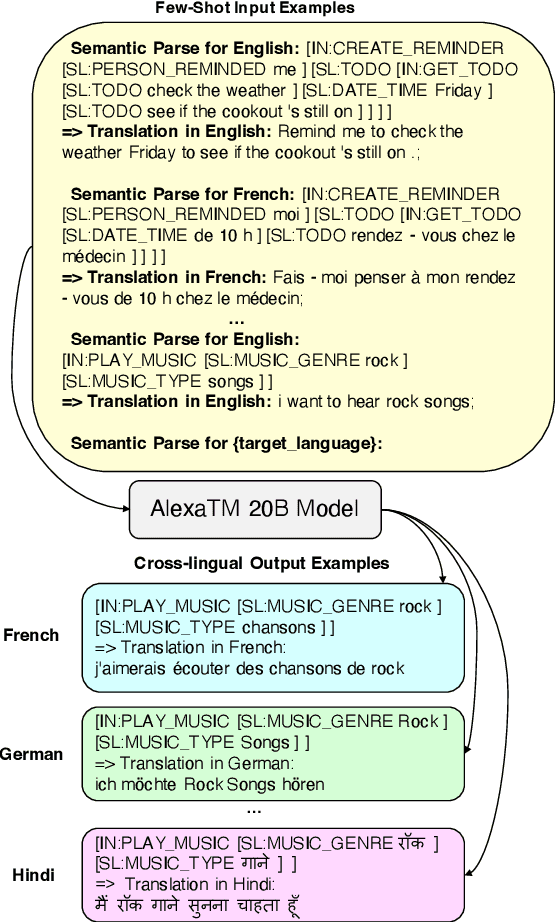
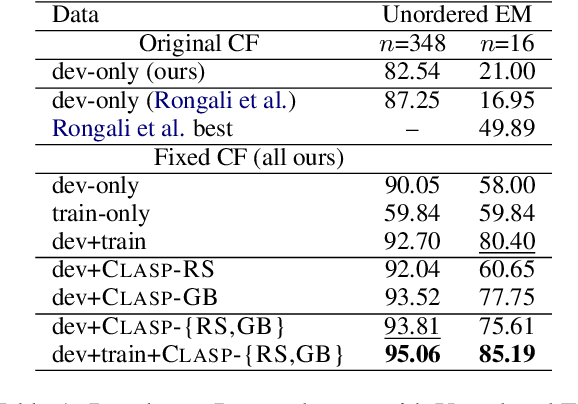

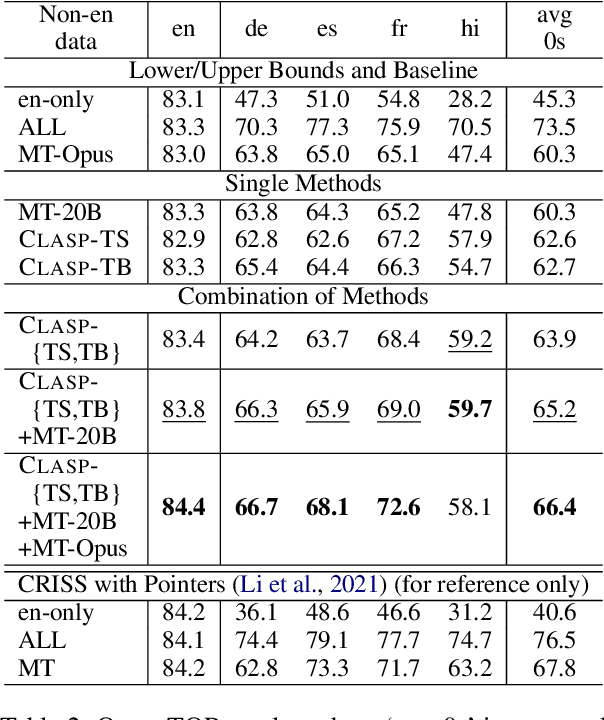
A bottleneck to developing Semantic Parsing (SP) models is the need for a large volume of human-labeled training data. Given the complexity and cost of human annotation for SP, labeled data is often scarce, particularly in multilingual settings. Large Language Models (LLMs) excel at SP given only a few examples, however LLMs are unsuitable for runtime systems which require low latency. In this work, we propose CLASP, a simple method to improve low-resource SP for moderate-sized models: we generate synthetic data from AlexaTM 20B to augment the training set for a model 40x smaller (500M parameters). We evaluate on two datasets in low-resource settings: English PIZZA, containing either 348 or 16 real examples, and mTOP cross-lingual zero-shot, where training data is available only in English, and the model must generalize to four new languages. On both datasets, we show significant improvements over strong baseline methods.
One Semantic Parser to Parse Them All: Sequence to Sequence Multi-Task Learning on Semantic Parsing Datasets
Jun 14, 2021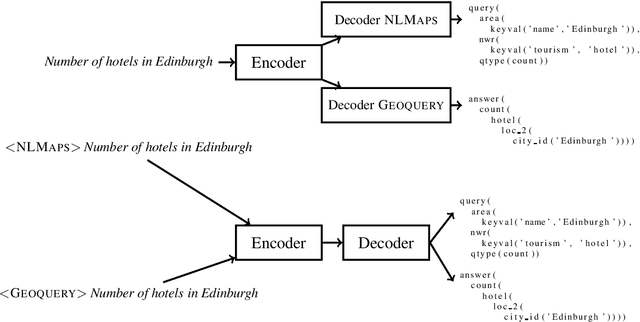

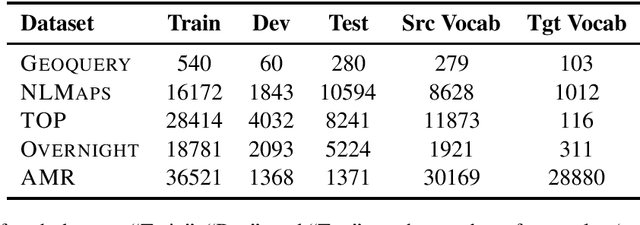
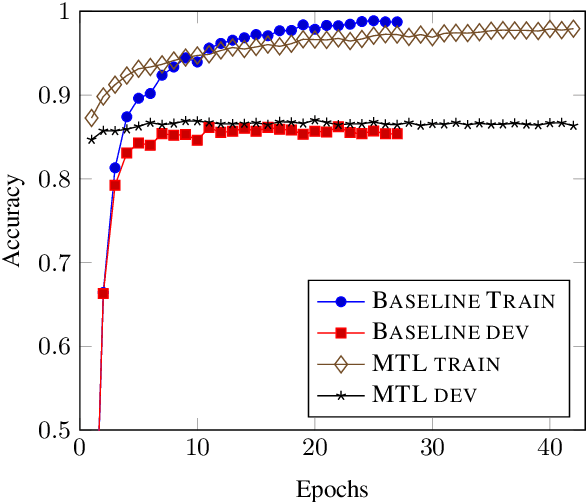
Semantic parsers map natural language utterances to meaning representations. The lack of a single standard for meaning representations led to the creation of a plethora of semantic parsing datasets. To unify different datasets and train a single model for them, we investigate the use of Multi-Task Learning (MTL) architectures. We experiment with five datasets (Geoquery, NLMaps, TOP, Overnight, AMR). We find that an MTL architecture that shares the entire network across datasets yields competitive or better parsing accuracies than the single-task baselines, while reducing the total number of parameters by 68%. We further provide evidence that MTL has also better compositional generalization than single-task models. We also present a comparison of task sampling methods and propose a competitive alternative to widespread proportional sampling strategies.
Structural Neural Encoders for AMR-to-text Generation
May 20, 2019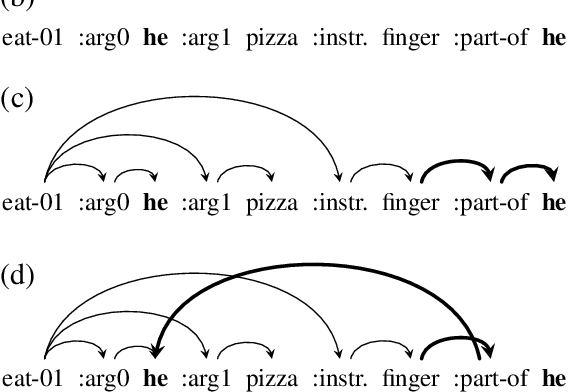
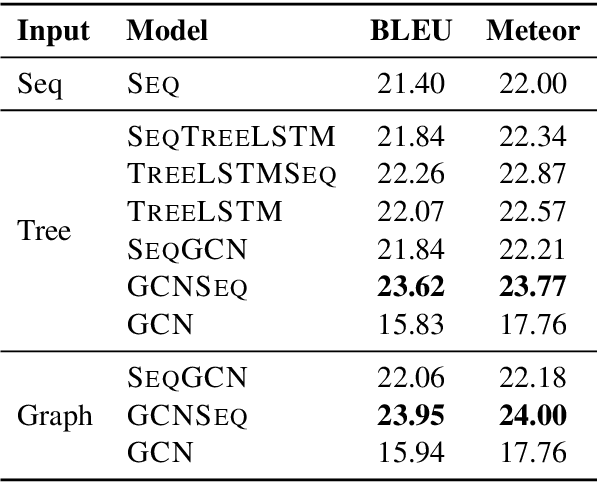
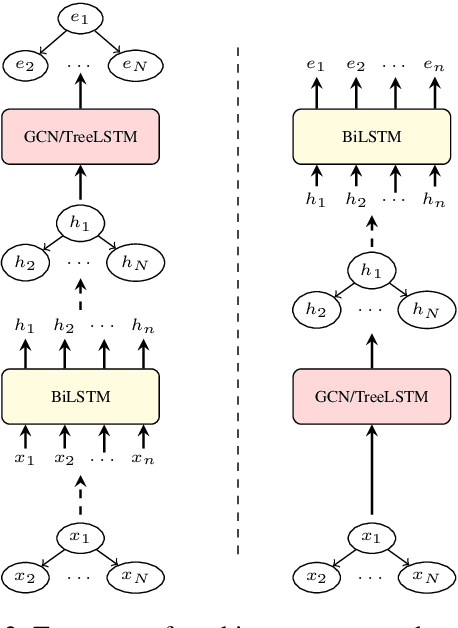
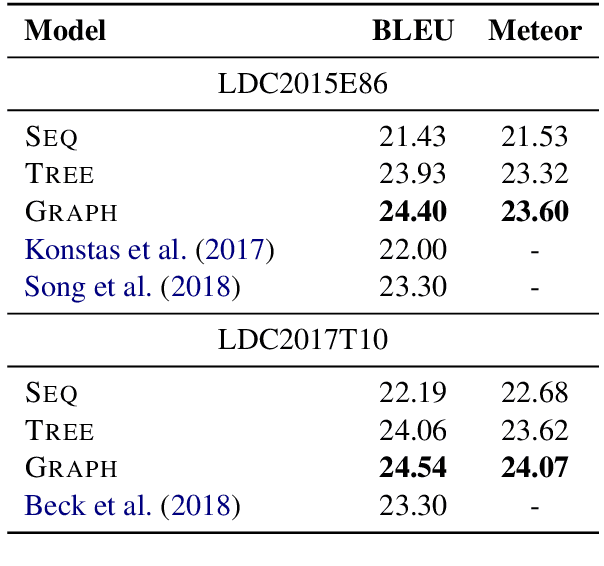
AMR-to-text generation is a problem recently introduced to the NLP community, in which the goal is to generate sentences from Abstract Meaning Representation (AMR) graphs. Sequence-to-sequence models can be used to this end by converting the AMR graphs to strings. Approaching the problem while working directly with graphs requires the use of graph-to-sequence models that encode the AMR graph into a vector representation. Such encoding has been shown to be beneficial in the past, and unlike sequential encoding, it allows us to explicitly capture reentrant structures in the AMR graphs. We investigate the extent to which reentrancies (nodes with multiple parents) have an impact on AMR-to-text generation by comparing graph encoders to tree encoders, where reentrancies are not preserved. We show that improvements in the treatment of reentrancies and long-range dependencies contribute to higher overall scores for graph encoders. Our best model achieves 24.40 BLEU on LDC2015E86, outperforming the state of the art by 1.1 points and 24.54 BLEU on LDC2017T10, outperforming the state of the art by 1.24 points.
Practical Semantic Parsing for Spoken Language Understanding
Mar 19, 2019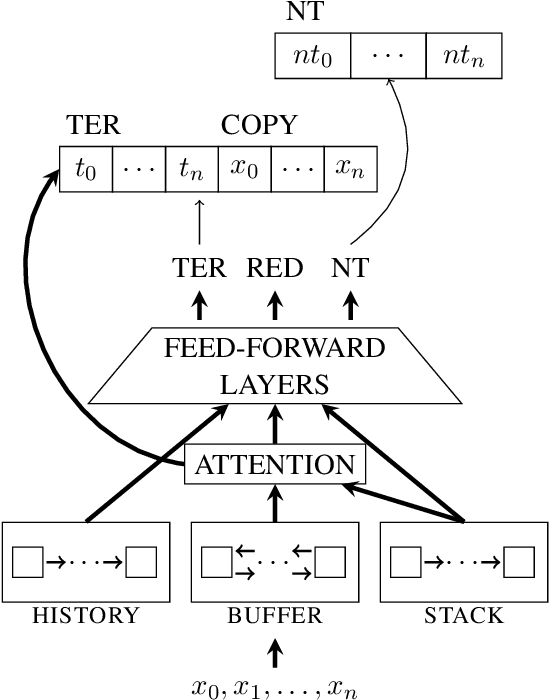
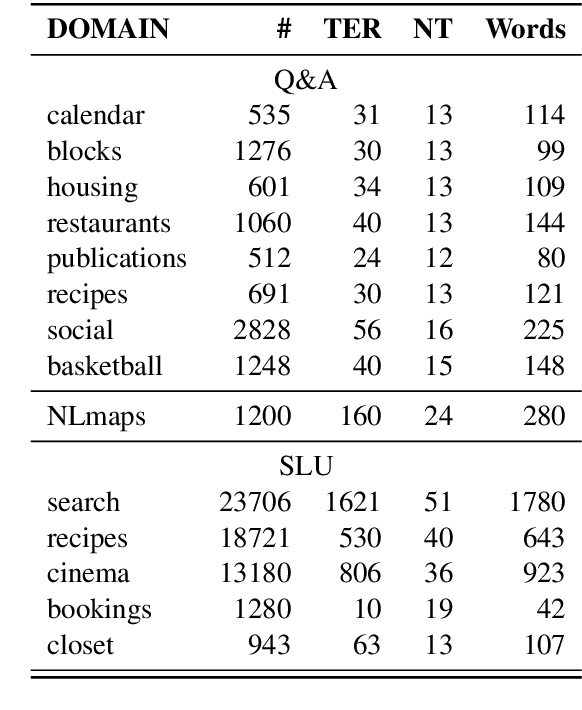
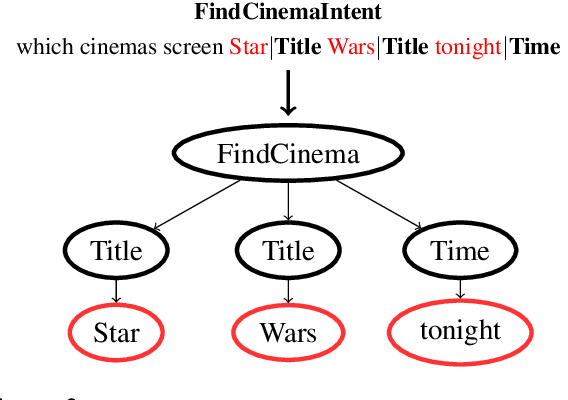
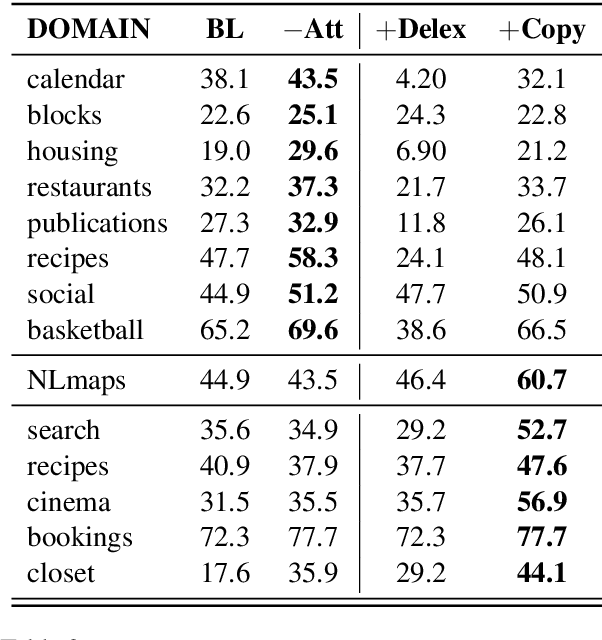
Executable semantic parsing is the task of converting natural language utterances into logical forms that can be directly used as queries to get a response. We build a transfer learning framework for executable semantic parsing. We show that the framework is effective for Question Answering (Q&A) as well as for Spoken Language Understanding (SLU). We further investigate the case where a parser on a new domain can be learned by exploiting data on other domains, either via multi-task learning between the target domain and an auxiliary domain or via pre-training on the auxiliary domain and fine-tuning on the target domain. With either flavor of transfer learning, we are able to improve performance on most domains; we experiment with public data sets such as Overnight and NLmaps as well as with commercial SLU data. The experiments carried out on data sets that are different in nature show how executable semantic parsing can unify different areas of NLP such as Q&A and SLU.
Talking to myself: self-dialogues as data for conversational agents
Sep 19, 2018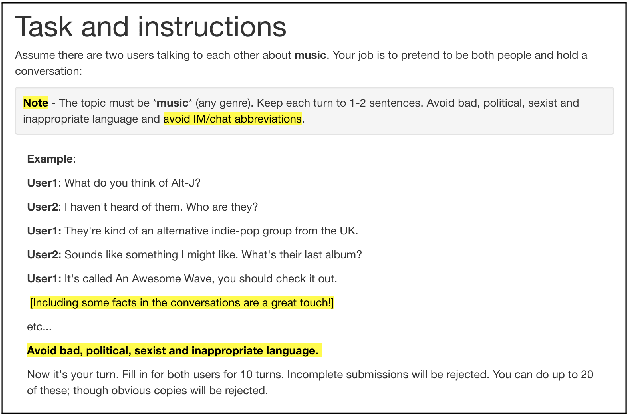
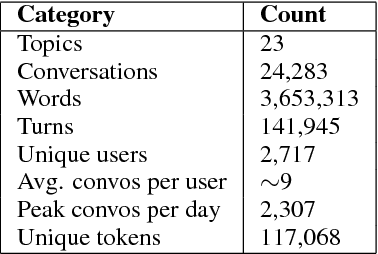
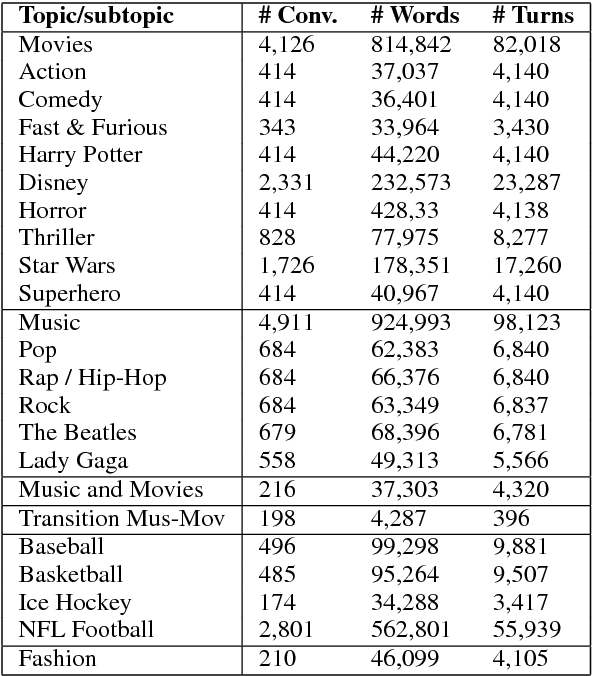
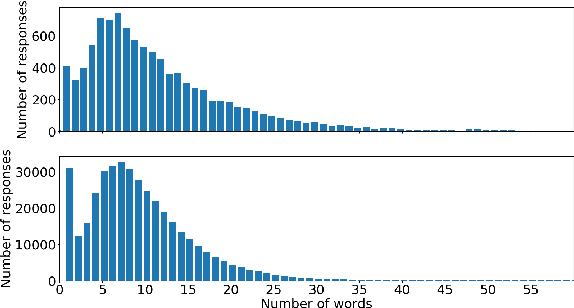
Conversational agents are gaining popularity with the increasing ubiquity of smart devices. However, training agents in a data driven manner is challenging due to a lack of suitable corpora. This paper presents a novel method for gathering topical, unstructured conversational data in an efficient way: self-dialogues through crowd-sourcing. Alongside this paper, we include a corpus of 3.6 million words across 23 topics. We argue the utility of the corpus by comparing self-dialogues with standard two-party conversations as well as data from other corpora.
Edina: Building an Open Domain Socialbot with Self-dialogues
Sep 28, 2017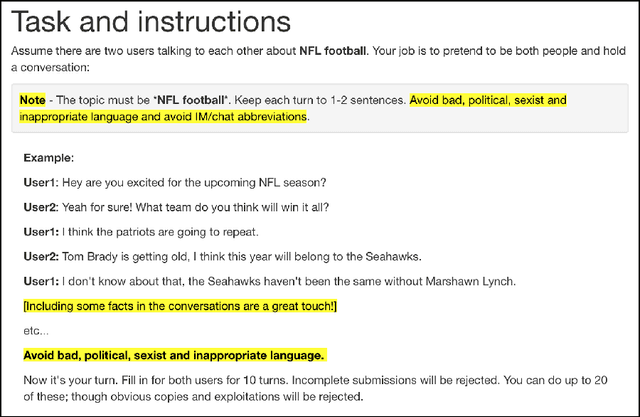

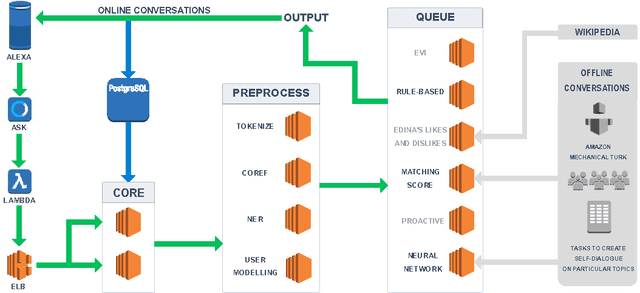

We present Edina, the University of Edinburgh's social bot for the Amazon Alexa Prize competition. Edina is a conversational agent whose responses utilize data harvested from Amazon Mechanical Turk (AMT) through an innovative new technique we call self-dialogues. These are conversations in which a single AMT Worker plays both participants in a dialogue. Such dialogues are surprisingly natural, efficient to collect and reflective of relevant and/or trending topics. These self-dialogues provide training data for a generative neural network as well as a basis for soft rules used by a matching score component. Each match of a soft rule against a user utterance is associated with a confidence score which we show is strongly indicative of reply quality, allowing this component to self-censor and be effectively integrated with other components. Edina's full architecture features a rule-based system backing off to a matching score, backing off to a generative neural network. Our hybrid data-driven methodology thus addresses both coverage limitations of a strictly rule-based approach and the lack of guarantees of a strictly machine-learning approach.
An Incremental Parser for Abstract Meaning Representation
Apr 10, 2017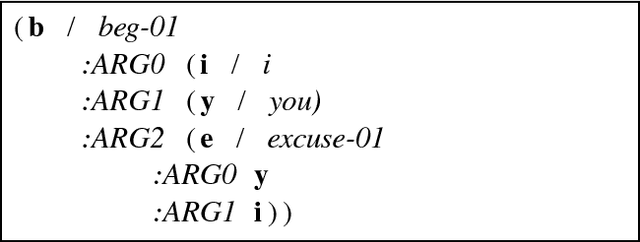
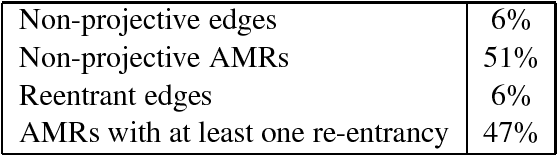
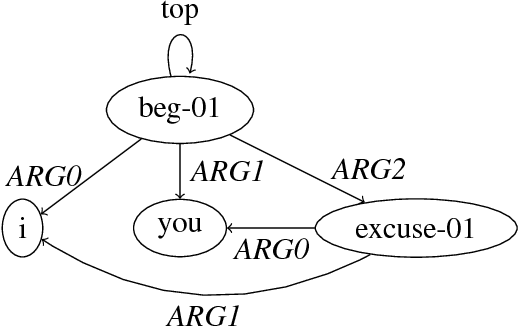
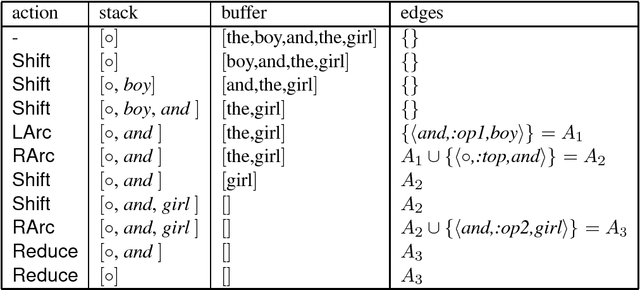
Meaning Representation (AMR) is a semantic representation for natural language that embeds annotations related to traditional tasks such as named entity recognition, semantic role labeling, word sense disambiguation and co-reference resolution. We describe a transition-based parser for AMR that parses sentences left-to-right, in linear time. We further propose a test-suite that assesses specific subtasks that are helpful in comparing AMR parsers, and show that our parser is competitive with the state of the art on the LDC2015E86 dataset and that it outperforms state-of-the-art parsers for recovering named entities and handling polarity.