 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAUTOKD: Automatic Knowledge Distillation Into A Student Architecture Family
Nov 05, 2021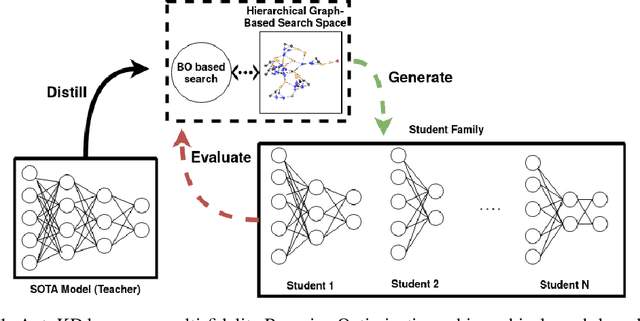
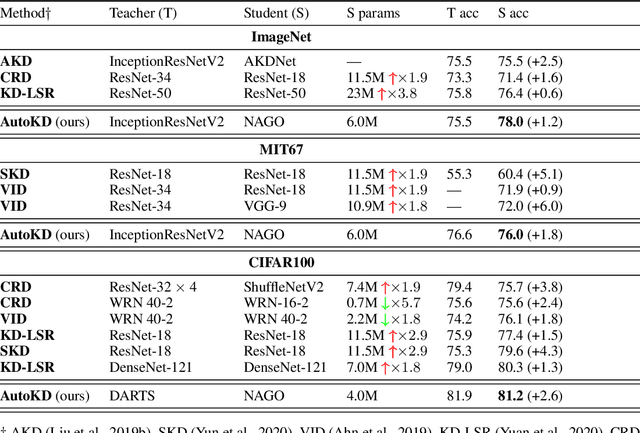
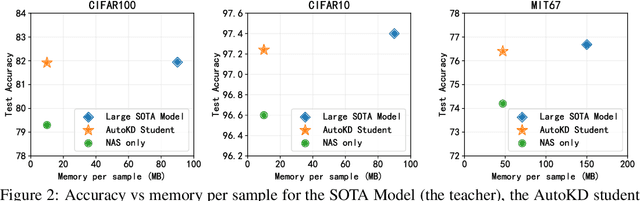
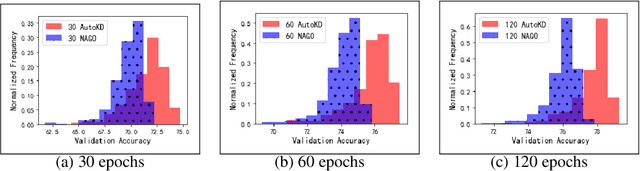
State-of-the-art results in deep learning have been improving steadily, in good part due to the use of larger models. However, widespread use is constrained by device hardware limitations, resulting in a substantial performance gap between state-of-the-art models and those that can be effectively deployed on small devices. While Knowledge Distillation (KD) theoretically enables small student models to emulate larger teacher models, in practice selecting a good student architecture requires considerable human expertise. Neural Architecture Search (NAS) appears as a natural solution to this problem but most approaches can be inefficient, as most of the computation is spent comparing architectures sampled from the same distribution, with negligible differences in performance. In this paper, we propose to instead search for a family of student architectures sharing the property of being good at learning from a given teacher. Our approach AutoKD, powered by Bayesian Optimization, explores a flexible graph-based search space, enabling us to automatically learn the optimal student architecture distribution and KD parameters, while being 20x more sample efficient compared to existing state-of-the-art. We evaluate our method on 3 datasets; on large images specifically, we reach the teacher performance while using 3x less memory and 10x less parameters. Finally, while AutoKD uses the traditional KD loss, it outperforms more advanced KD variants using hand-designed students.
Adversarial Attacks on Graph Classification via Bayesian Optimisation
Nov 04, 2021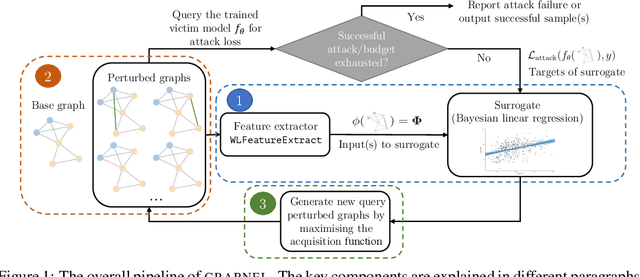
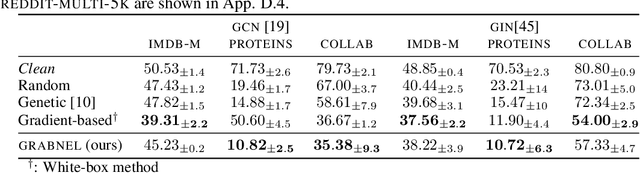
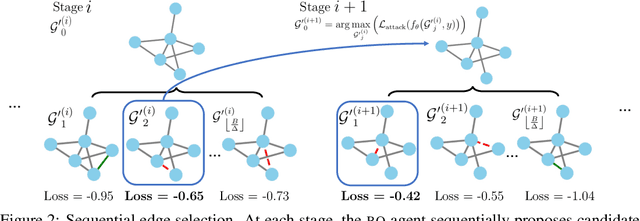
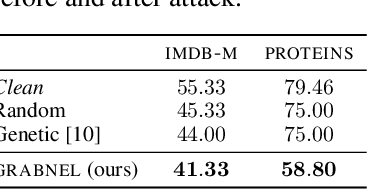
Graph neural networks, a popular class of models effective in a wide range of graph-based learning tasks, have been shown to be vulnerable to adversarial attacks. While the majority of the literature focuses on such vulnerability in node-level classification tasks, little effort has been dedicated to analysing adversarial attacks on graph-level classification, an important problem with numerous real-life applications such as biochemistry and social network analysis. The few existing methods often require unrealistic setups, such as access to internal information of the victim models, or an impractically-large number of queries. We present a novel Bayesian optimisation-based attack method for graph classification models. Our method is black-box, query-efficient and parsimonious with respect to the perturbation applied. We empirically validate the effectiveness and flexibility of the proposed method on a wide range of graph classification tasks involving varying graph properties, constraints and modes of attack. Finally, we analyse common interpretable patterns behind the adversarial samples produced, which may shed further light on the adversarial robustness of graph classification models.
DHA: End-to-End Joint Optimization of Data Augmentation Policy, Hyper-parameter and Architecture
Sep 13, 2021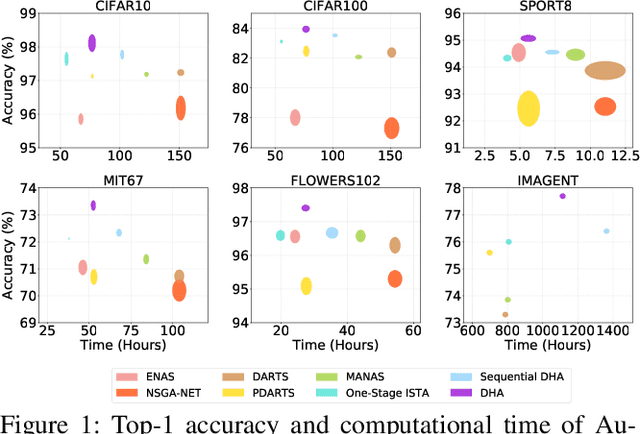

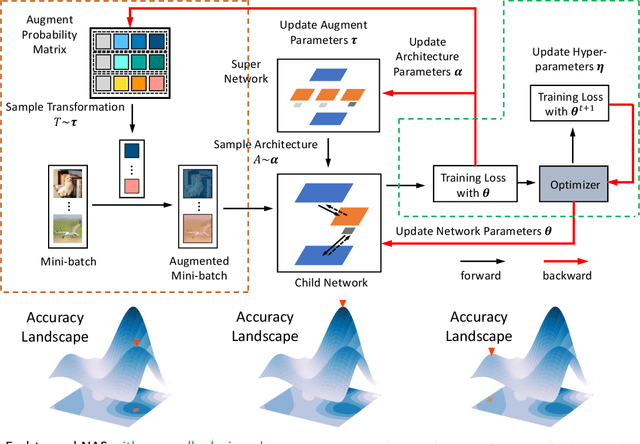
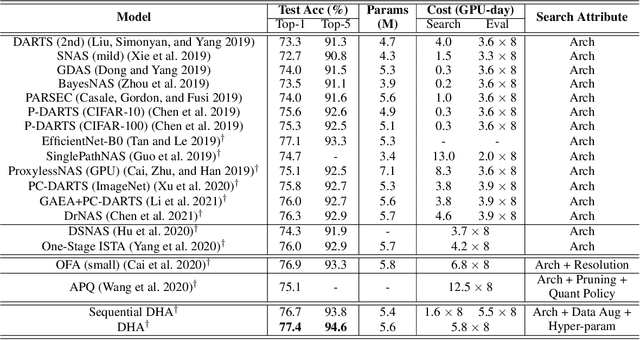
Automated machine learning (AutoML) usually involves several crucial components, such as Data Augmentation (DA) policy, Hyper-Parameter Optimization (HPO), and Neural Architecture Search (NAS). Although many strategies have been developed for automating these components in separation, joint optimization of these components remains challenging due to the largely increased search dimension and the variant input types of each component. Meanwhile, conducting these components in a sequence often requires careful coordination by human experts and may lead to sub-optimal results. In parallel to this, the common practice of searching for the optimal architecture first and then retraining it before deployment in NAS often suffers from low performance correlation between the search and retraining stages. An end-to-end solution that integrates the AutoML components and returns a ready-to-use model at the end of the search is desirable. In view of these, we propose DHA, which achieves joint optimization of Data augmentation policy, Hyper-parameter and Architecture. Specifically, end-to-end NAS is achieved in a differentiable manner by optimizing a compressed lower-dimensional feature space, while DA policy and HPO are updated dynamically at the same time. Experiments show that DHA achieves state-of-the-art (SOTA) results on various datasets, especially 77.4\% accuracy on ImageNet with cell based search space, which is higher than current SOTA by 0.5\%. To the best of our knowledge, we are the first to efficiently and jointly optimize DA policy, NAS, and HPO in an end-to-end manner without retraining.
How Powerful are Performance Predictors in Neural Architecture Search?
Apr 02, 2021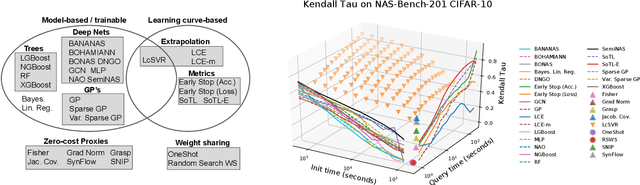
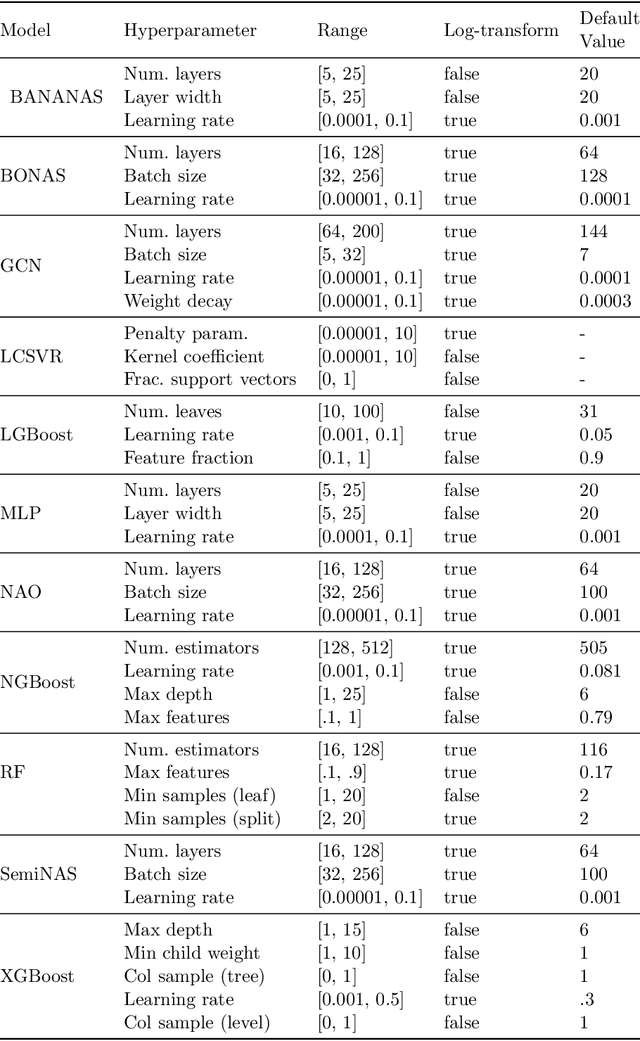
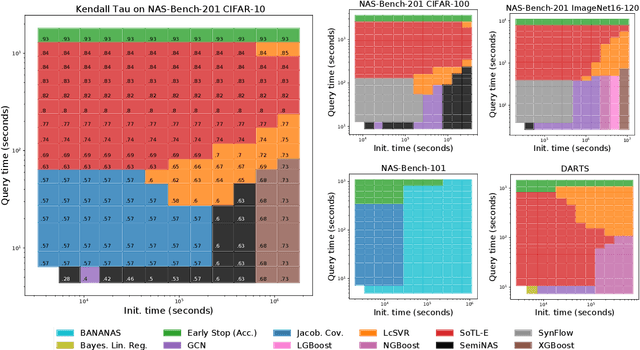
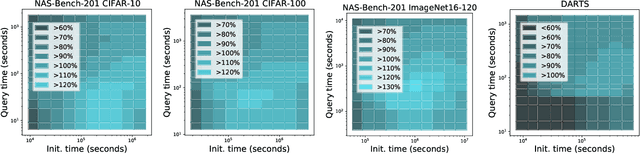
Early methods in the rapidly developing field of neural architecture search (NAS) required fully training thousands of neural networks. To reduce this extreme computational cost, dozens of techniques have since been proposed to predict the final performance of neural architectures. Despite the success of such performance prediction methods, it is not well-understood how different families of techniques compare to one another, due to the lack of an agreed-upon evaluation metric and optimization for different constraints on the initialization time and query time. In this work, we give the first large-scale study of performance predictors by analyzing 31 techniques ranging from learning curve extrapolation, to weight-sharing, to supervised learning, to "zero-cost" proxies. We test a number of correlation- and rank-based performance measures in a variety of settings, as well as the ability of each technique to speed up predictor-based NAS frameworks. Our results act as recommendations for the best predictors to use in different settings, and we show that certain families of predictors can be combined to achieve even better predictive power, opening up promising research directions. Our code, featuring a library of 31 performance predictors, is available at https://github.com/automl/naslib.
Think Global and Act Local: Bayesian Optimisation over High-Dimensional Categorical and Mixed Search Spaces
Feb 14, 2021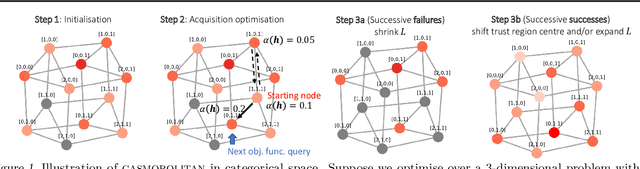

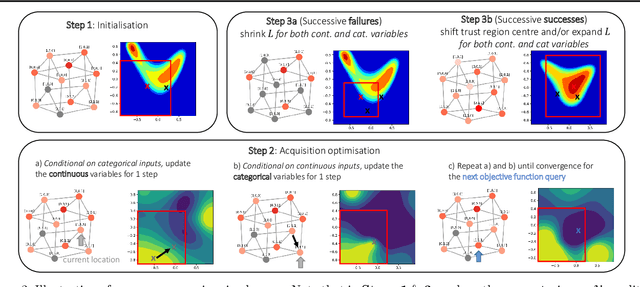
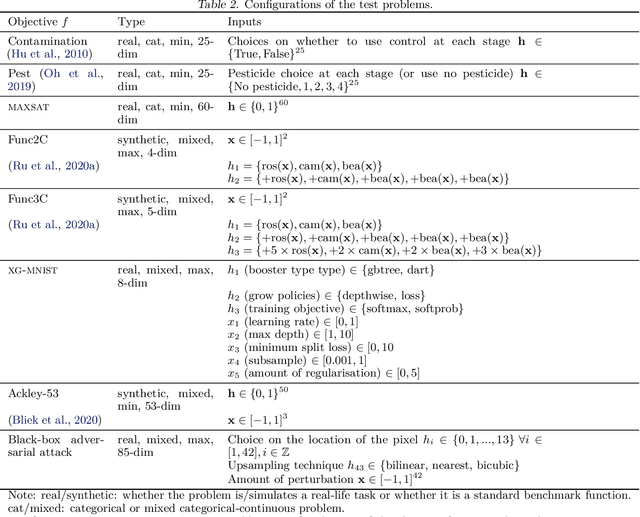
High-dimensional black-box optimisation remains an important yet notoriously challenging problem. Despite the success of Bayesian optimisation methods on continuous domains, domains that are categorical, or that mix continuous and categorical variables, remain challenging. We propose a novel solution -- we combine local optimisation with a tailored kernel design, effectively handling high-dimensional categorical and mixed search spaces, whilst retaining sample efficiency. We further derive convergence guarantee for the proposed approach. Finally, we demonstrate empirically that our method outperforms the current baselines on a variety of synthetic and real-world tasks in terms of performance, computational costs, or both.
A Bayesian Perspective on Training Speed and Model Selection
Oct 27, 2020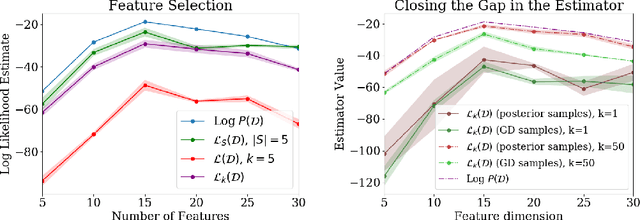
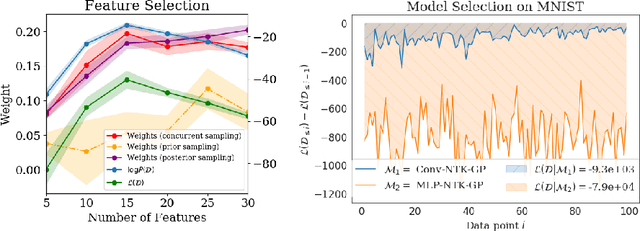
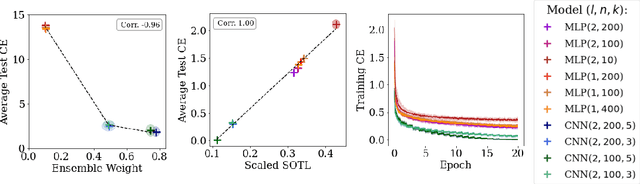
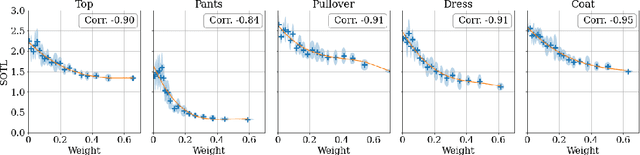
We take a Bayesian perspective to illustrate a connection between training speed and the marginal likelihood in linear models. This provides two major insights: first, that a measure of a model's training speed can be used to estimate its marginal likelihood. Second, that this measure, under certain conditions, predicts the relative weighting of models in linear model combinations trained to minimize a regression loss. We verify our results in model selection tasks for linear models and for the infinite-width limit of deep neural networks. We further provide encouraging empirical evidence that the intuition developed in these settings also holds for deep neural networks trained with stochastic gradient descent. Our results suggest a promising new direction towards explaining why neural networks trained with stochastic gradient descent are biased towards functions that generalize well.
Neural Architecture Search using Bayesian Optimisation with Weisfeiler-Lehman Kernel
Jun 13, 2020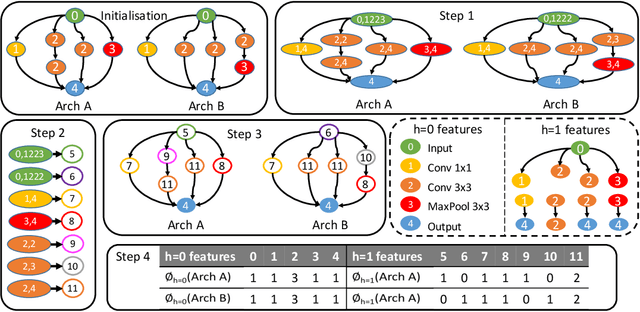
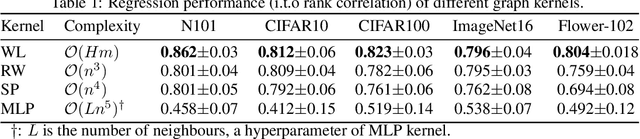
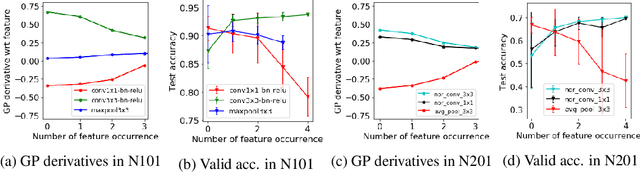
Bayesian optimisation (BO) has been widely used for hyperparameter optimisation but its application in neural architecture search (NAS) is limited due to the non-continuous, high-dimensional and graph-like search spaces. Current approaches either rely on encoding schemes, which are not scalable to large architectures and ignore the implicit topological structure of architectures, or use graph neural networks, which require additional hyperparameter tuning and a large amount of observed data, which is particularly expensive to obtain in NAS. We propose a neat BO approach for NAS, which combines the Weisfeiler-Lehman graph kernel with a Gaussian process surrogate to capture the topological structure of architectures, without having to explicitly define a Gaussian process over high-dimensional vector spaces. We also harness the interpretable features learnt via the graph kernel to guide the generation of new architectures. We demonstrate empirically that our surrogate model is scalable to large architectures and highly data-efficient; competing methods require 3 to 20 times more observations to achieve equally good prediction performance as ours. We finally show that our method outperforms existing NAS approaches to achieve state-of-the-art results on NAS datasets.
Revisiting the Train Loss: an Efficient Performance Estimator for Neural Architecture Search
Jun 08, 2020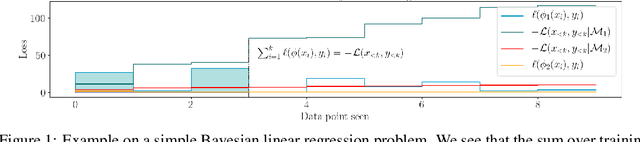
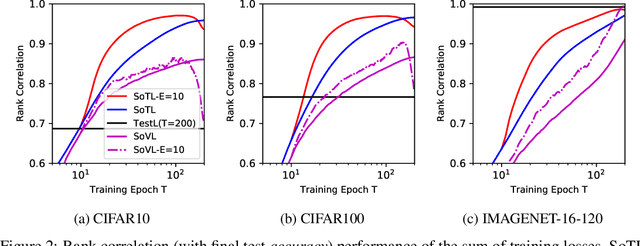
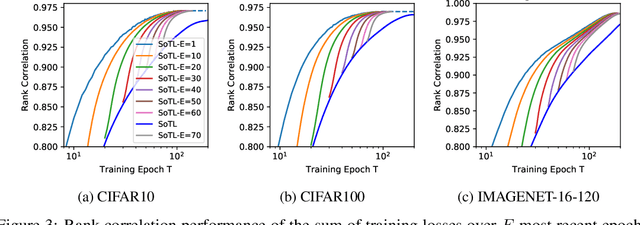
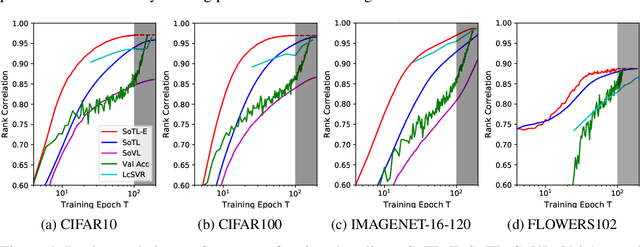
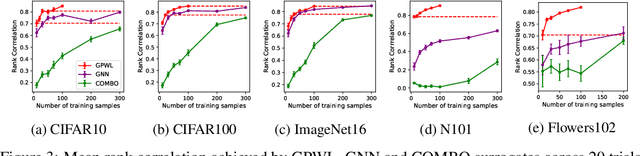
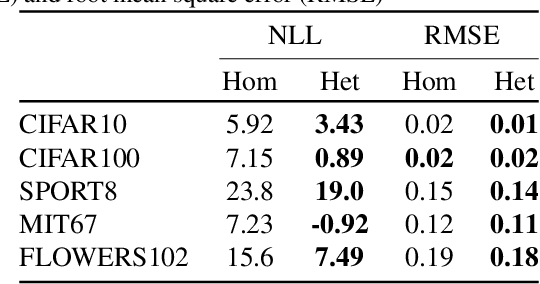
Reliable yet efficient evaluation of generalisation performance of a proposed architecture is crucial to the success of neural architecture search (NAS). Traditional approaches face a variety of limitations: training each architecture to completion is prohibitively expensive, early stopping estimates may correlate poorly with fully trained performance, and model-based estimators require large training sets. Instead, motivated by recent results linking training speed and generalisation with stochastic gradient descent, we propose to estimate the final test performance based on the sum of training losses. Our estimator is inspired by the marginal likelihood, which is used for Bayesian model selection. Our model-free estimator is simple, efficient, and cheap to implement, and does not require hyperparameter-tuning or surrogate training before deployment. We demonstrate empirically that our estimator consistently outperforms other baselines and can achieve a rank correlation of 0.95 with final test accuracy on the NAS-Bench201 dataset within 50 epochs.
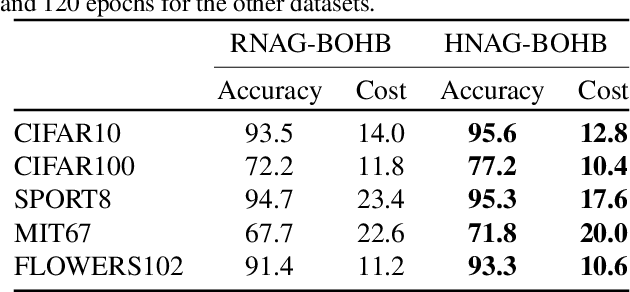
Neural Architecture Generator Optimization
Apr 03, 2020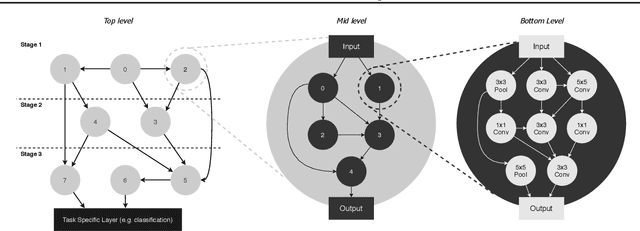
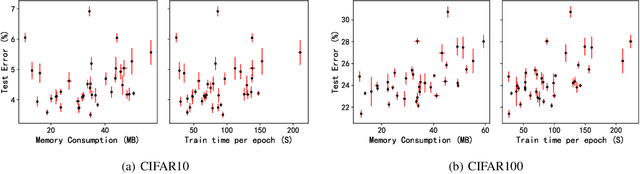
Neural Architecture Search (NAS) was first proposed to achieve state-of-the-art performance through the discovery of new architecture patterns, without human intervention. An over-reliance on expert knowledge in the search space design has however led to increased performance (local optima) without significant architectural breakthroughs, thus preventing truly novel solutions from being reached. In this work we propose 1) to cast NAS as a problem of finding the optimal network generator and 2) a new, hierarchical and graph-based search space capable of representing an extremely large variety of network types, yet only requiring few continuous hyper-parameters. This greatly reduces the dimensionality of the problem, enabling the effective use of Bayesian Optimisation as a search strategy. At the same time, we expand the range of valid architectures, motivating a multi-objective learning approach. We demonstrate the effectiveness of our strategy on six benchmark datasets and show that our search space generates extremely lightweight yet highly competitive models illustrating the benefits of a NAS approach that optimises over network generator selection.
Bayesian Optimisation over Multiple Continuous and Categorical Inputs
Jun 20, 2019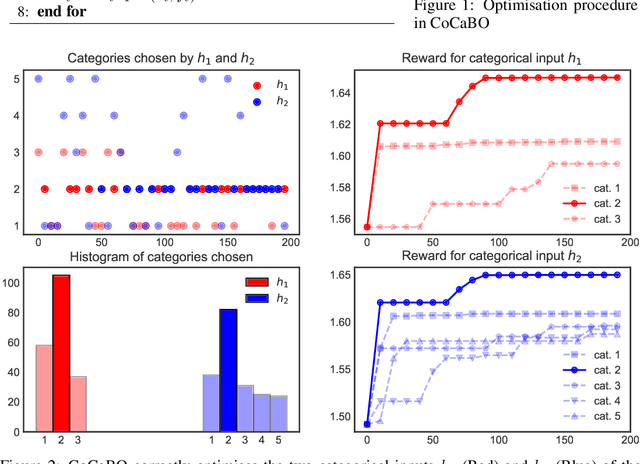

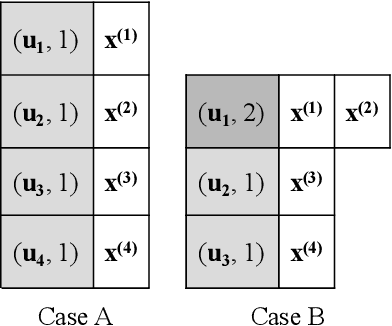

Efficient optimisation of black-box problems that comprise both continuous and categorical inputs is important, yet poses significant challenges. We propose a new approach, Continuous and Categorical Bayesian Optimisation (CoCaBO), which combines the strengths of multi-armed bandits and Bayesian optimisation to select values for both categorical and continuous inputs. We model this mixed-type space using a Gaussian Process kernel, designed to allow sharing of information across multiple categorical variables, each with multiple possible values; this allows CoCaBO to leverage all available data efficiently. We extend our method to the batch setting and propose an efficient selection procedure that dynamically balances exploration and exploitation whilst encouraging batch diversity. We demonstrate empirically that our method outperforms existing approaches on both synthetic and real-world optimisation tasks with continuous and categorical inputs.