 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRCRank: Multimodal Ranking of Root Causes of Slow Queries in Cloud Database Systems
Mar 06, 2025



With the continued migration of storage to cloud database systems,the impact of slow queries in such systems on services and user experience is increasing. Root-cause diagnosis plays an indispensable role in facilitating slow-query detection and revision. This paper proposes a method capable of both identifying possible root cause types for slow queries and ranking these according to their potential for accelerating slow queries. This enables prioritizing root causes with the highest impact, in turn improving slow-query revision effectiveness. To enable more accurate and detailed diagnoses, we propose the multimodal Ranking for the Root Causes of slow queries (RCRank) framework, which formulates root cause analysis as a multimodal machine learning problem and leverages multimodal information from query statements, execution plans, execution logs, and key performance indicators. To obtain expressive embeddings from its heterogeneous multimodal input, RCRank integrates self-supervised pre-training that enhances cross-modal alignment and task relevance. Next, the framework integrates root-cause-adaptive cross Transformers that enable adaptive fusion of multimodal features with varying characteristics. Finally, the framework offers a unified model that features an impact-aware training objective for identifying and ranking root causes. We report on experiments on real and synthetic datasets, finding that RCRank is capable of consistently outperforming the state-of-the-art methods at root cause identification and ranking according to a range of metrics.
Keeping Yourself is Important in Downstream Tuning Multimodal Large Language Model
Mar 06, 2025Multi-modal Large Language Models (MLLMs) integrate visual and linguistic reasoning to address complex tasks such as image captioning and visual question answering. While MLLMs demonstrate remarkable versatility, MLLMs appears limited performance on special applications. But tuning MLLMs for downstream tasks encounters two key challenges: Task-Expert Specialization, where distribution shifts between pre-training and target datasets constrain target performance, and Open-World Stabilization, where catastrophic forgetting erases the model general knowledge. In this work, we systematically review recent advancements in MLLM tuning methodologies, classifying them into three paradigms: (I) Selective Tuning, (II) Additive Tuning, and (III) Reparameterization Tuning. Furthermore, we benchmark these tuning strategies across popular MLLM architectures and diverse downstream tasks to establish standardized evaluation analysis and systematic tuning principles. Finally, we highlight several open challenges in this domain and propose future research directions. To facilitate ongoing progress in this rapidly evolving field, we provide a public repository that continuously tracks developments: https://github.com/WenkeHuang/Awesome-MLLM-Tuning.
Class-Aware PillarMix: Can Mixed Sample Data Augmentation Enhance 3D Object Detection with Radar Point Clouds?
Mar 04, 2025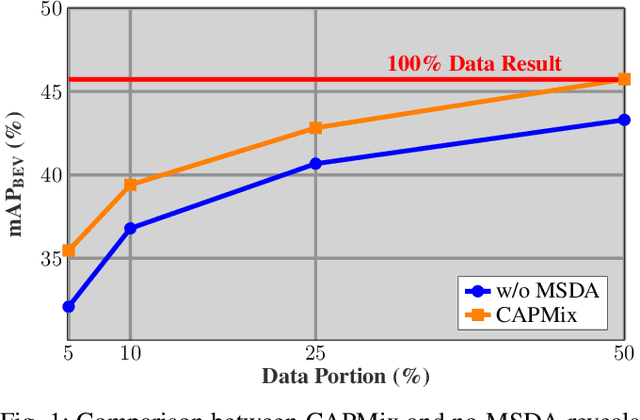
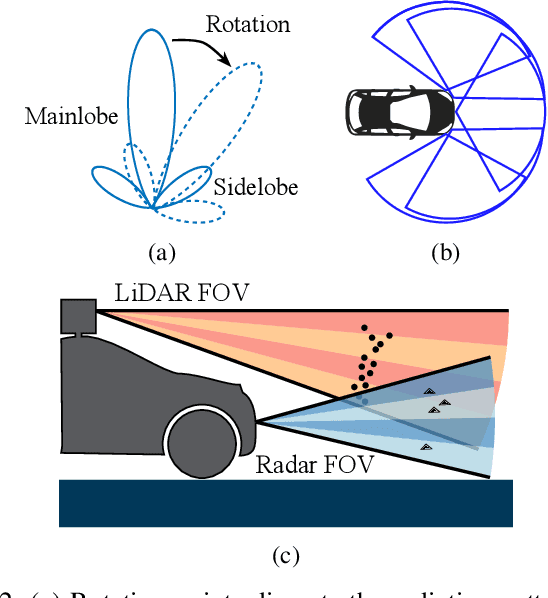
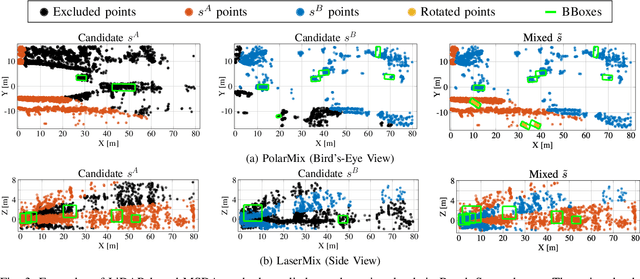
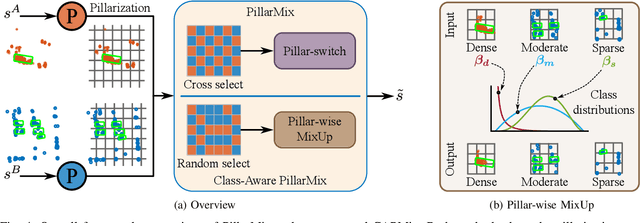
Due to the significant effort required for data collection and annotation in 3D perception tasks, mixed sample data augmentation (MSDA) has been widely studied to generate diverse training samples by mixing existing data. Recently, many MSDA techniques have been developed for point clouds, but they mainly target LiDAR data, leaving their application to radar point clouds largely unexplored. In this paper, we examine the feasibility of applying existing MSDA methods to radar point clouds and identify several challenges in adapting these techniques. These obstacles stem from the radar's irregular angular distribution, deviations from a single-sensor polar layout in multi-radar setups, and point sparsity. To address these issues, we propose Class-Aware PillarMix (CAPMix), a novel MSDA approach that applies MixUp at the pillar level in 3D point clouds, guided by class labels. Unlike methods that rely a single mix ratio to the entire sample, CAPMix assigns an independent ratio to each pillar, boosting sample diversity. To account for the density of different classes, we use class-specific distributions: for dense objects (e.g., large vehicles), we skew ratios to favor points from another sample, while for sparse objects (e.g., pedestrians), we sample more points from the original. This class-aware mixing retains critical details and enriches each sample with new information, ultimately generating more diverse training data. Experimental results demonstrate that our method not only significantly boosts performance but also outperforms existing MSDA approaches across two datasets (Bosch Street and K-Radar). We believe that this straightforward yet effective approach will spark further investigation into MSDA techniques for radar data.
SEE: See Everything Every Time -- Adaptive Brightness Adjustment for Broad Light Range Images via Events
Feb 28, 2025Event cameras, with a high dynamic range exceeding $120dB$, significantly outperform traditional embedded cameras, robustly recording detailed changing information under various lighting conditions, including both low- and high-light situations. However, recent research on utilizing event data has primarily focused on low-light image enhancement, neglecting image enhancement and brightness adjustment across a broader range of lighting conditions, such as normal or high illumination. Based on this, we propose a novel research question: how to employ events to enhance and adaptively adjust the brightness of images captured under broad lighting conditions? To investigate this question, we first collected a new dataset, SEE-600K, consisting of 610,126 images and corresponding events across 202 scenarios, each featuring an average of four lighting conditions with over a 1000-fold variation in illumination. Subsequently, we propose a framework that effectively utilizes events to smoothly adjust image brightness through the use of prompts. Our framework captures color through sensor patterns, uses cross-attention to model events as a brightness dictionary, and adjusts the image's dynamic range to form a broad light-range representation (BLR), which is then decoded at the pixel level based on the brightness prompt. Experimental results demonstrate that our method not only performs well on the low-light enhancement dataset but also shows robust performance on broader light-range image enhancement using the SEE-600K dataset. Additionally, our approach enables pixel-level brightness adjustment, providing flexibility for post-processing and inspiring more imaging applications. The dataset and source code are publicly available at:https://github.com/yunfanLu/SEE.
FLARES: Fast and Accurate LiDAR Multi-Range Semantic Segmentation
Feb 13, 20253D scene understanding is a critical yet challenging task in autonomous driving, primarily due to the irregularity and sparsity of LiDAR data, as well as the computational demands of processing large-scale point clouds. Recent methods leverage the range-view representation to improve processing efficiency. To mitigate the performance drop caused by information loss inherent to the "many-to-one" problem, where multiple nearby 3D points are mapped to the same 2D grids and only the closest is retained, prior works tend to choose a higher azimuth resolution for range-view projection. However, this can bring the drawback of reducing the proportion of pixels that carry information and heavier computation within the network. We argue that it is not the optimal solution and show that, in contrast, decreasing the resolution is more advantageous in both efficiency and accuracy. In this work, we present a comprehensive re-design of the workflow for range-view-based LiDAR semantic segmentation. Our approach addresses data representation, augmentation, and post-processing methods for improvements. Through extensive experiments on two public datasets, we demonstrate that our pipeline significantly enhances the performance of various network architectures over their baselines, paving the way for more effective LiDAR-based perception in autonomous systems.
Assessing Pre-trained Models for Transfer Learning through Distribution of Spectral Components
Dec 26, 2024



Pre-trained model assessment for transfer learning aims to identify the optimal candidate for the downstream tasks from a model hub, without the need of time-consuming fine-tuning. Existing advanced works mainly focus on analyzing the intrinsic characteristics of the entire features extracted by each pre-trained model or how well such features fit the target labels. This paper proposes a novel perspective for pre-trained model assessment through the Distribution of Spectral Components (DISCO). Through singular value decomposition of features extracted from pre-trained models, we investigate different spectral components and observe that they possess distinct transferability, contributing diversely to the fine-tuning performance. Inspired by this, we propose an assessment method based on the distribution of spectral components which measures the proportions of their corresponding singular values. Pre-trained models with features concentrating on more transferable components are regarded as better choices for transfer learning. We further leverage the labels of downstream data to better estimate the transferability of each spectral component and derive the final assessment criterion. Our proposed method is flexible and can be applied to both classification and regression tasks. We conducted comprehensive experiments across three benchmarks and two tasks including image classification and object detection, demonstrating that our method achieves state-of-the-art performance in choosing proper pre-trained models from the model hub for transfer learning.
EasyTime: Time Series Forecasting Made Easy
Dec 23, 2024



Time series forecasting has important applications across diverse domains. EasyTime, the system we demonstrate, facilitates easy use of time-series forecasting methods by researchers and practitioners alike. First, EasyTime enables one-click evaluation, enabling researchers to evaluate new forecasting methods using the suite of diverse time series datasets collected in the preexisting time series forecasting benchmark (TFB). This is achieved by leveraging TFB's flexible and consistent evaluation pipeline. Second, when practitioners must perform forecasting on a new dataset, a nontrivial first step is often to find an appropriate forecasting method. EasyTime provides an Automated Ensemble module that combines the promising forecasting methods to yield superior forecasting accuracy compared to individual methods. Third, EasyTime offers a natural language Q&A module leveraging large language models. Given a question like "Which method is best for long term forecasting on time series with strong seasonality?", EasyTime converts the question into SQL queries on the database of results obtained by TFB and then returns an answer in natural language and charts. By demonstrating EasyTime, we intend to show how it is possible to simplify the use of time series forecasting and to offer better support for the development of new generations of time series forecasting methods.
DUET: Dual Clustering Enhanced Multivariate Time Series Forecasting
Dec 14, 2024



Multivariate time series forecasting is crucial for various applications, such as financial investment, energy management, weather forecasting, and traffic optimization. However, accurate forecasting is challenging due to two main factors. First, real-world time series often show heterogeneous temporal patterns caused by distribution shifts over time. Second, correlations among channels are complex and intertwined, making it hard to model the interactions among channels precisely and flexibly. In this study, we address these challenges by proposing a general framework called \textbf{DUET}, which introduces \underline{DU}al clustering on the temporal and channel dimensions to \underline{E}nhance multivariate \underline{T}ime series forecasting. First, we design a Temporal Clustering Module (TCM) that clusters time series into fine-grained distributions to handle heterogeneous temporal patterns. For different distribution clusters, we design various pattern extractors to capture their intrinsic temporal patterns, thus modeling the heterogeneity. Second, we introduce a novel Channel-Soft-Clustering strategy and design a Channel Clustering Module (CCM), which captures the relationships among channels in the frequency domain through metric learning and applies sparsification to mitigate the adverse effects of noisy channels. Finally, DUET combines TCM and CCM to incorporate both the temporal and channel dimensions. Extensive experiments on 25 real-world datasets from 10 application domains, demonstrate the state-of-the-art performance of DUET.
MM-Path: Multi-modal, Multi-granularity Path Representation Learning -- Extended Version
Nov 28, 2024



Developing effective path representations has become increasingly essential across various fields within intelligent transportation. Although pre-trained path representation learning models have shown improved performance, they predominantly focus on the topological structures from single modality data, i.e., road networks, overlooking the geometric and contextual features associated with path-related images, e.g., remote sensing images. Similar to human understanding, integrating information from multiple modalities can provide a more comprehensive view, enhancing both representation accuracy and generalization. However, variations in information granularity impede the semantic alignment of road network-based paths (road paths) and image-based paths (image paths), while the heterogeneity of multi-modal data poses substantial challenges for effective fusion and utilization. In this paper, we propose a novel Multi-modal, Multi-granularity Path Representation Learning Framework (MM-Path), which can learn a generic path representation by integrating modalities from both road paths and image paths. To enhance the alignment of multi-modal data, we develop a multi-granularity alignment strategy that systematically associates nodes, road sub-paths, and road paths with their corresponding image patches, ensuring the synchronization of both detailed local information and broader global contexts. To address the heterogeneity of multi-modal data effectively, we introduce a graph-based cross-modal residual fusion component designed to comprehensively fuse information across different modalities and granularities. Finally, we conduct extensive experiments on two large-scale real-world datasets under two downstream tasks, validating the effectiveness of the proposed MM-Path. The code is available at: https://github.com/decisionintelligence/MM-Path.
Distributed Computation Offloading for Energy Provision Minimization in WP-MEC Networks with Multiple HAPs
Nov 01, 2024



This paper investigates a wireless powered mobile edge computing (WP-MEC) network with multiple hybrid access points (HAPs) in a dynamic environment, where wireless devices (WDs) harvest energy from radio frequency (RF) signals of HAPs, and then compute their computation data locally (i.e., local computing mode) or offload it to the chosen HAPs (i.e., edge computing mode). In order to pursue a green computing design, we formulate an optimization problem that minimizes the long-term energy provision of the WP-MEC network subject to the energy, computing delay and computation data demand constraints. The transmit power of HAPs, the duration of the wireless power transfer (WPT) phase, the offloading decisions of WDs, the time allocation for offloading and the CPU frequency for local computing are jointly optimized adapting to the time-varying generated computation data and wireless channels of WDs. To efficiently address the formulated non-convex mixed integer programming (MIP) problem in a distributed manner, we propose a Two-stage Multi-Agent deep reinforcement learning-based Distributed computation Offloading (TMADO) framework, which consists of a high-level agent and multiple low-level agents. The high-level agent residing in all HAPs optimizes the transmit power of HAPs and the duration of the WPT phase, while each low-level agent residing in each WD optimizes its offloading decision, time allocation for offloading and CPU frequency for local computing. Simulation results show the superiority of the proposed TMADO framework in terms of the energy provision minimization.