 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVariation-based Cause Effect Identification
Nov 22, 2022



Mining genuine mechanisms underlying the complex data generation process in real-world systems is a fundamental step in promoting interpretability of, and thus trust in, data-driven models. Therefore, we propose a variation-based cause effect identification (VCEI) framework for causal discovery in bivariate systems from a single observational setting. Our framework relies on the principle of independence of cause and mechanism (ICM) under the assumption of an existing acyclic causal link, and offers a practical realization of this principle. Principally, we artificially construct two settings in which the marginal distributions of one covariate, claimed to be the cause, are guaranteed to have non-negligible variations. This is achieved by re-weighting samples of the marginal so that the resultant distribution is notably distinct from this marginal according to some discrepancy measure. In the causal direction, such variations are expected to have no impact on the effect generation mechanism. Therefore, quantifying the impact of these variations on the conditionals reveals the genuine causal direction. Moreover, we formulate our approach in the kernel-based maximum mean discrepancy, lifting all constraints on the data types of cause-and-effect covariates, and rendering such artificial interventions a convex optimization problem. We provide a series of experiments on real and synthetic data showing that VCEI is, in principle, competitive to other cause effect identification frameworks.
Prompt Tuning for Parameter-efficient Medical Image Segmentation
Nov 16, 2022Neural networks pre-trained on a self-supervision scheme have become the standard when operating in data rich environments with scarce annotations. As such, fine-tuning a model to a downstream task in a parameter-efficient but effective way, e.g. for a new set of classes in the case of semantic segmentation, is of increasing importance. In this work, we propose and investigate several contributions to achieve a parameter-efficient but effective adaptation for semantic segmentation on two medical imaging datasets. Relying on the recently popularized prompt tuning approach, we provide a prompt-able UNet (PUNet) architecture, that is frozen after pre-training, but adaptable throughout the network by class-dependent learnable prompt tokens. We pre-train this architecture with a dedicated dense self-supervision scheme based on assignments to online generated prototypes (contrastive prototype assignment, CPA) of a student teacher combination alongside a concurrent segmentation loss on a subset of classes. We demonstrate that the resulting neural network model is able to attenuate the gap between fully fine-tuned and parameter-efficiently adapted models on CT imaging datasets. As such, the difference between fully fine-tuned and prompt-tuned variants amounts to only 3.83 pp for the TCIA/BTCV dataset and 2.67 pp for the CT-ORG dataset in the mean Dice Similarity Coefficient (DSC, in %) while only prompt tokens, corresponding to 0.85% of the pre-trained backbone model with 6.8M frozen parameters, are adjusted. The code for this work is available on https://github.com/marcdcfischer/PUNet .
Towards Discriminative and Transferable One-Stage Few-Shot Object Detectors
Oct 11, 2022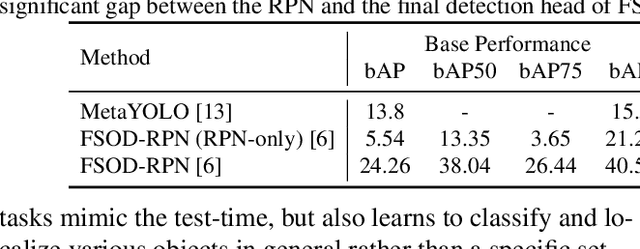
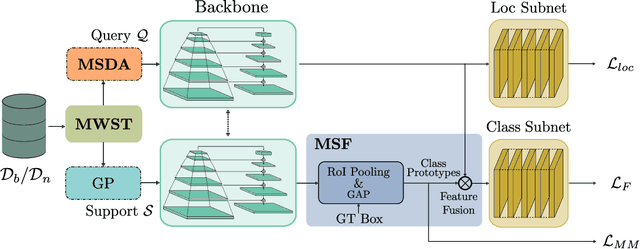
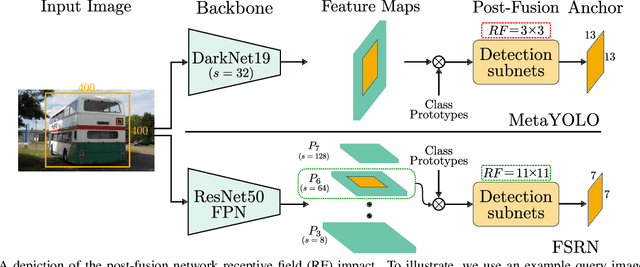
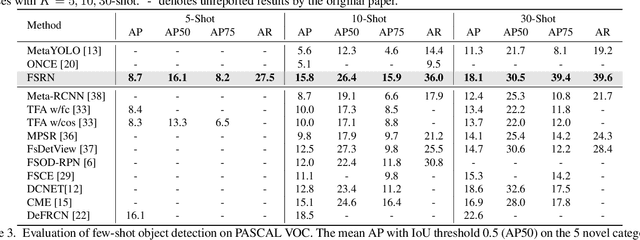
Recent object detection models require large amounts of annotated data for training a new classes of objects. Few-shot object detection (FSOD) aims to address this problem by learning novel classes given only a few samples. While competitive results have been achieved using two-stage FSOD detectors, typically one-stage FSODs underperform compared to them. We make the observation that the large gap in performance between two-stage and one-stage FSODs are mainly due to their weak discriminability, which is explained by a small post-fusion receptive field and a small number of foreground samples in the loss function. To address these limitations, we propose the Few-shot RetinaNet (FSRN) that consists of: a multi-way support training strategy to augment the number of foreground samples for dense meta-detectors, an early multi-level feature fusion providing a wide receptive field that covers the whole anchor area and two augmentation techniques on query and source images to enhance transferability. Extensive experiments show that the proposed approach addresses the limitations and boosts both discriminability and transferability. FSRN is almost two times faster than two-stage FSODs while remaining competitive in accuracy, and it outperforms the state-of-the-art of one-stage meta-detectors and also some two-stage FSODs on the MS-COCO and PASCAL VOC benchmarks.
Experts in the Loop: Conditional Variable Selection for Accelerating Post-Silicon Analysis Based on Deep Learning
Sep 30, 2022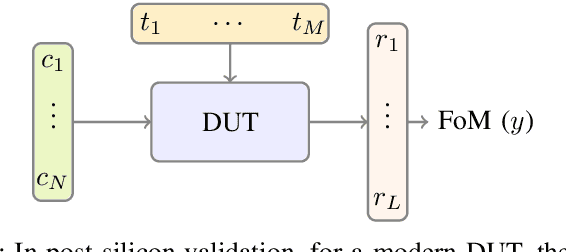
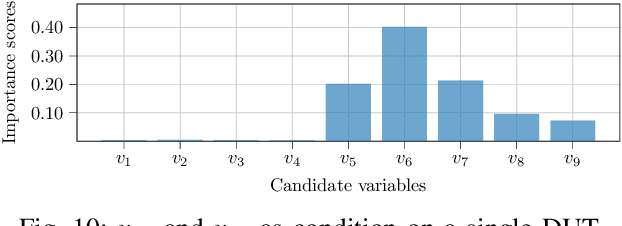
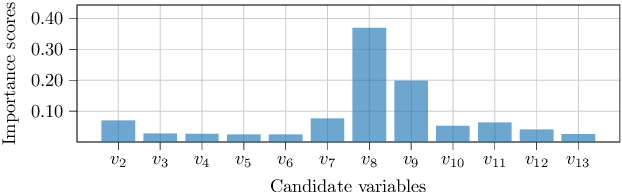
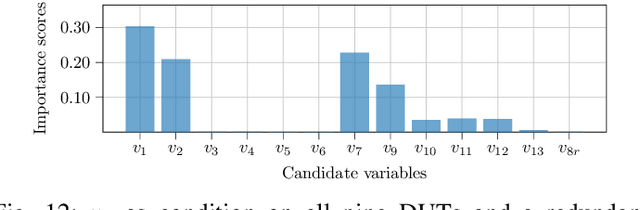
Post-silicon validation is one of the most critical processes in modern semiconductor manufacturing. Specifically, correct and deep understanding in test cases of manufactured devices is key to enable post-silicon tuning and debugging. This analysis is typically performed by experienced human experts. However, with the fast development in semiconductor industry, test cases can contain hundreds of variables. The resulting high-dimensionality poses enormous challenges to experts. Thereby, some recent prior works have introduced data-driven variable selection algorithms to tackle these problems and achieved notable success. Nevertheless, for these methods, experts are not involved in training and inference phases, which may lead to bias and inaccuracy due to the lack of prior knowledge. Hence, this work for the first time aims to design a novel conditional variable selection approach while keeping experts in the loop. In this way, we expect that our algorithm can be more efficiently and effectively trained to identify the most critical variables under certain expert knowledge. Extensive experiments on both synthetic and real-world datasets from industry have been conducted and shown the effectiveness of our method.
Deep Feature Selection Using a Novel Complementary Feature Mask
Sep 25, 2022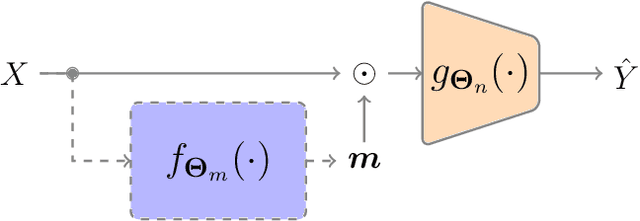
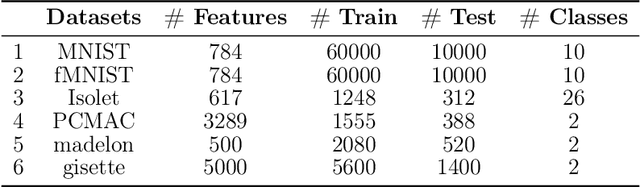
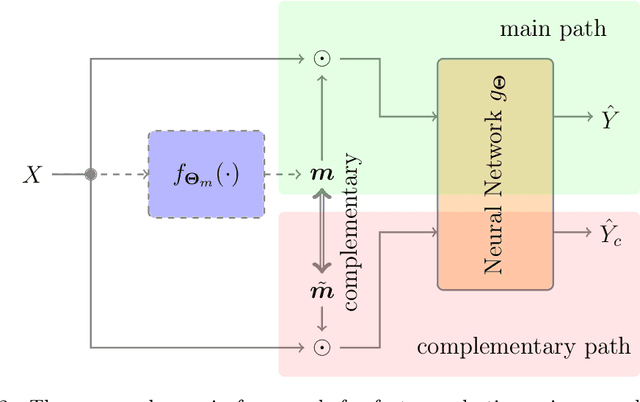
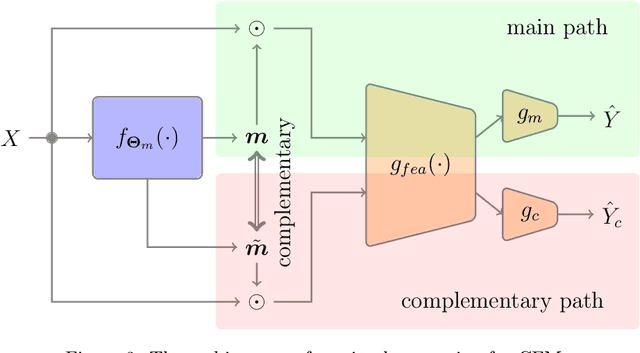
Feature selection has drawn much attention over the last decades in machine learning because it can reduce data dimensionality while maintaining the original physical meaning of features, which enables better interpretability than feature extraction. However, most existing feature selection approaches, especially deep-learning-based, often focus on the features with great importance scores only but neglect those with less importance scores during training as well as the order of important candidate features. This can be risky since some important and relevant features might be unfortunately ignored during training, leading to suboptimal solutions or misleading selections. In our work, we deal with feature selection by exploiting the features with less importance scores and propose a feature selection framework based on a novel complementary feature mask. Our method is generic and can be easily integrated into existing deep-learning-based feature selection approaches to improve their performance as well. Experiments have been conducted on benchmarking datasets and shown that the proposed method can select more representative and informative features than the state of the art.
CMGAN: Conformer-Based Metric-GAN for Monaural Speech Enhancement
Sep 23, 2022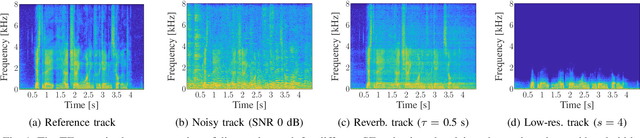
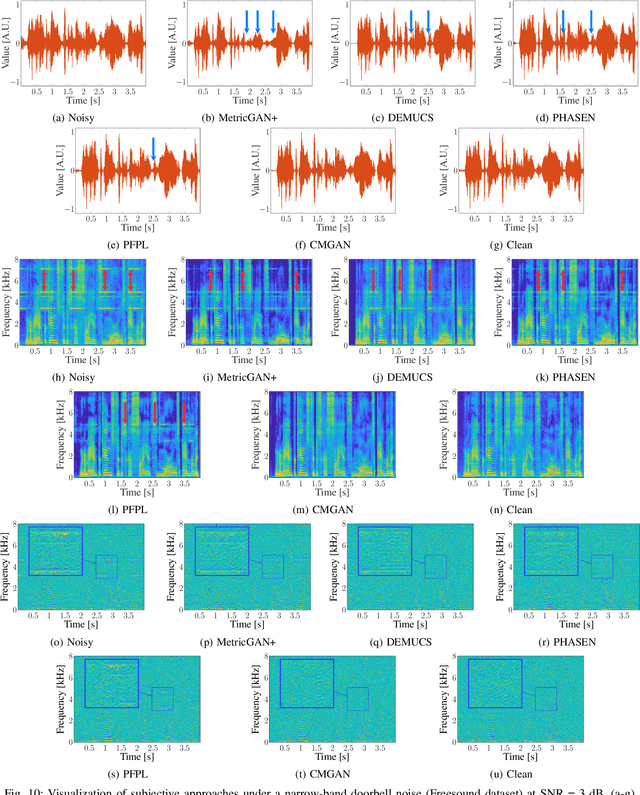
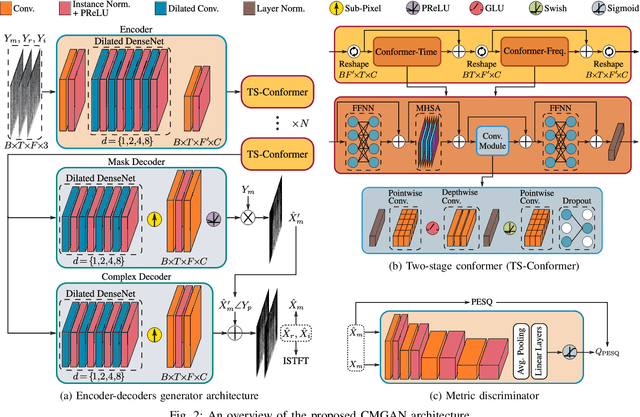
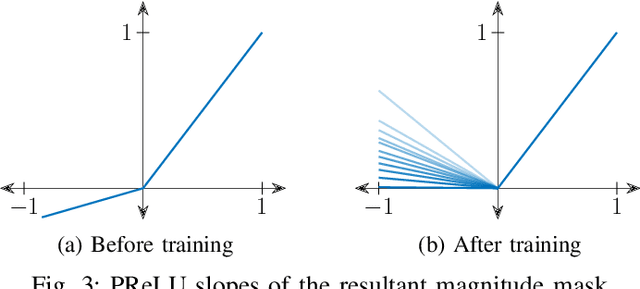
Convolution-augmented transformers (Conformers) are recently proposed in various speech-domain applications, such as automatic speech recognition (ASR) and speech separation, as they can capture both local and global dependencies. In this paper, we propose a conformer-based metric generative adversarial network (CMGAN) for speech enhancement (SE) in the time-frequency (TF) domain. The generator encodes the magnitude and complex spectrogram information using two-stage conformer blocks to model both time and frequency dependencies. The decoder then decouples the estimation into a magnitude mask decoder branch to filter out unwanted distortions and a complex refinement branch to further improve the magnitude estimation and implicitly enhance the phase information. Additionally, we include a metric discriminator to alleviate metric mismatch by optimizing the generator with respect to a corresponding evaluation score. Objective and subjective evaluations illustrate that CMGAN is able to show superior performance compared to state-of-the-art methods in three speech enhancement tasks (denoising, dereverberation and super-resolution). For instance, quantitative denoising analysis on Voice Bank+DEMAND dataset indicates that CMGAN outperforms various previous models with a margin, i.e., PESQ of 3.41 and SSNR of 11.10 dB.
A Comparative Study on Unsupervised Anomaly Detection for Time Series: Experiments and Analysis
Sep 10, 2022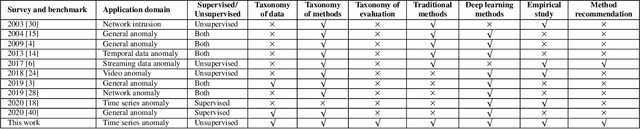
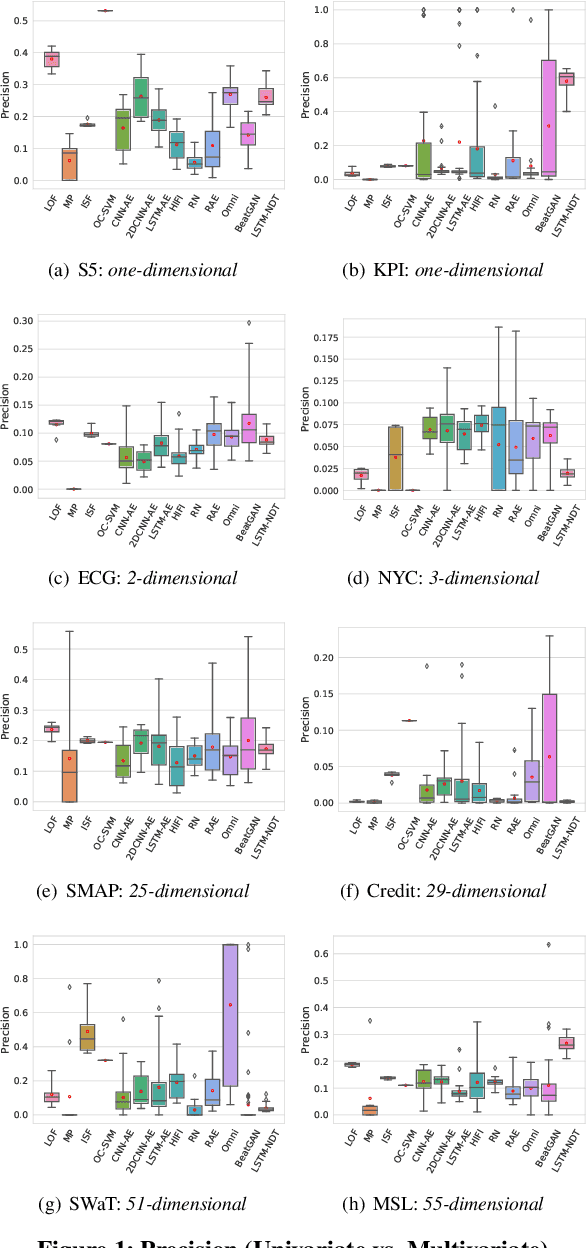
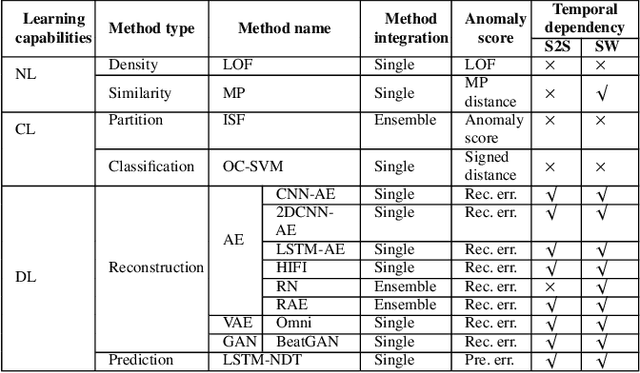

The continued digitization of societal processes translates into a proliferation of time series data that cover applications such as fraud detection, intrusion detection, and energy management, where anomaly detection is often essential to enable reliability and safety. Many recent studies target anomaly detection for time series data. Indeed, area of time series anomaly detection is characterized by diverse data, methods, and evaluation strategies, and comparisons in existing studies consider only part of this diversity, which makes it difficult to select the best method for a particular problem setting. To address this shortcoming, we introduce taxonomies for data, methods, and evaluation strategies, provide a comprehensive overview of unsupervised time series anomaly detection using the taxonomies, and systematically evaluate and compare state-of-the-art traditional as well as deep learning techniques. In the empirical study using nine publicly available datasets, we apply the most commonly-used performance evaluation metrics to typical methods under a fair implementation standard. Based on the structuring offered by the taxonomies, we report on empirical studies and provide guidelines, in the form of comparative tables, for choosing the methods most suitable for particular application settings. Finally, we propose research directions for this dynamic field.
Design Automation for Fast, Lightweight, and Effective Deep Learning Models: A Survey
Aug 22, 2022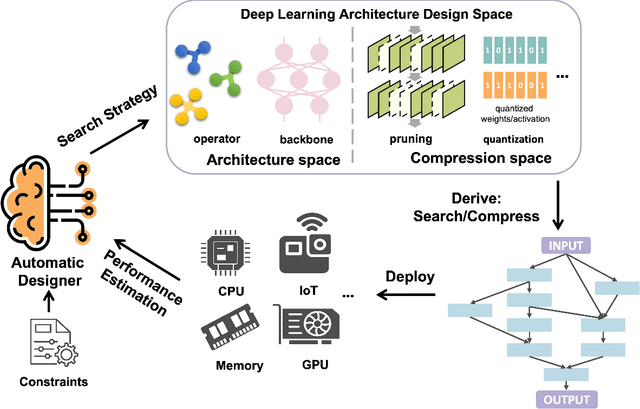
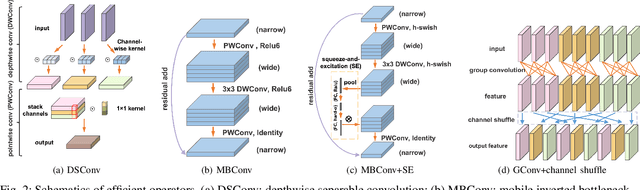
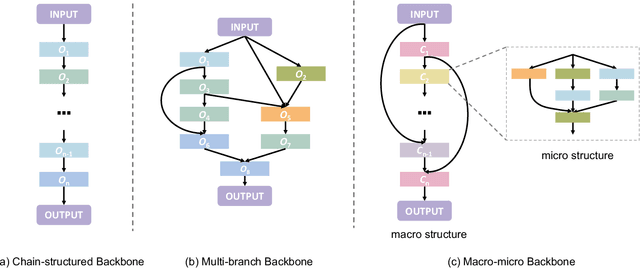
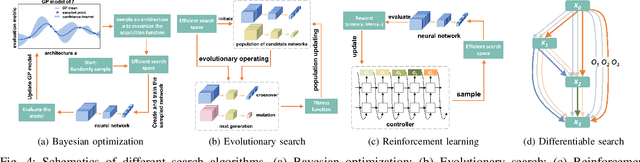
Deep learning technologies have demonstrated remarkable effectiveness in a wide range of tasks, and deep learning holds the potential to advance a multitude of applications, including in edge computing, where deep models are deployed on edge devices to enable instant data processing and response. A key challenge is that while the application of deep models often incurs substantial memory and computational costs, edge devices typically offer only very limited storage and computational capabilities that may vary substantially across devices. These characteristics make it difficult to build deep learning solutions that unleash the potential of edge devices while complying with their constraints. A promising approach to addressing this challenge is to automate the design of effective deep learning models that are lightweight, require only a little storage, and incur only low computational overheads. This survey offers comprehensive coverage of studies of design automation techniques for deep learning models targeting edge computing. It offers an overview and comparison of key metrics that are used commonly to quantify the proficiency of models in terms of effectiveness, lightness, and computational costs. The survey then proceeds to cover three categories of the state-of-the-art of deep model design automation techniques: automated neural architecture search, automated model compression, and joint automated design and compression. Finally, the survey covers open issues and directions for future research.
Gradual Test-Time Adaptation by Self-Training and Style Transfer
Aug 16, 2022
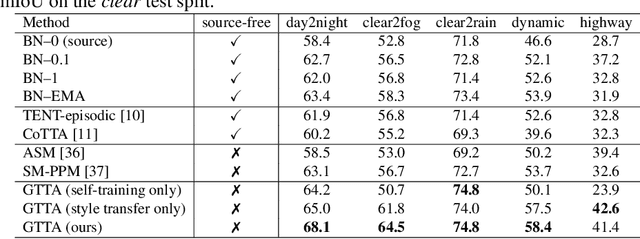
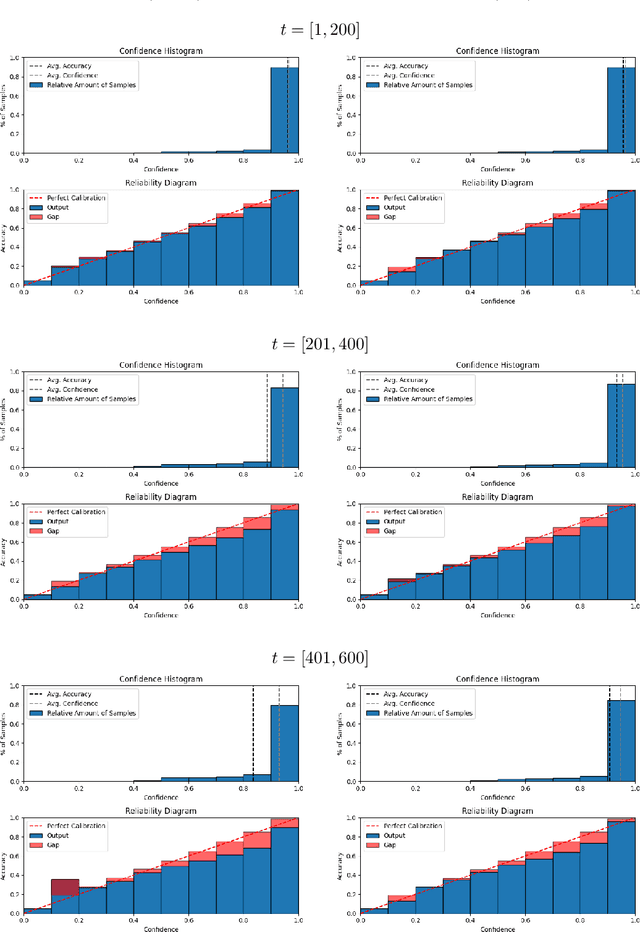
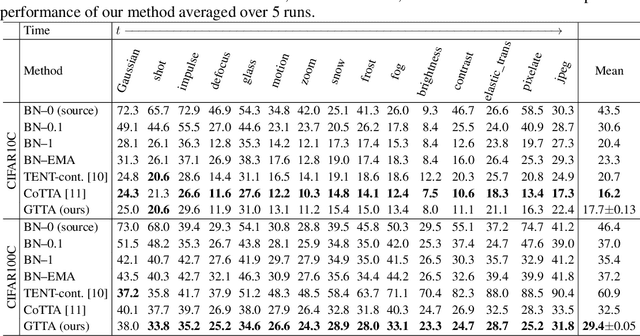
Domain shifts at test-time are inevitable in practice. Test-time adaptation addresses this problem by adapting the model during deployment. Recent work theoretically showed that self-training can be a strong method in the setting of gradual domain shifts. In this work we show the natural connection between gradual domain adaptation and test-time adaptation. We publish a new synthetic dataset called CarlaTTA that allows to explore gradual domain shifts during test-time and evaluate several methods in the area of unsupervised domain adaptation and test-time adaptation. We propose a new method GTTA that is based on self-training and style transfer. GTTA explicitly exploits gradual domain shifts and sets a new standard in this area. We further demonstrate the effectiveness of our method on the continual and gradual CIFAR10C, CIFAR100C, and ImageNet-C benchmark.
Continual Unsupervised Domain Adaptation for Semantic Segmentation using a Class-Specific Transfer
Aug 12, 2022
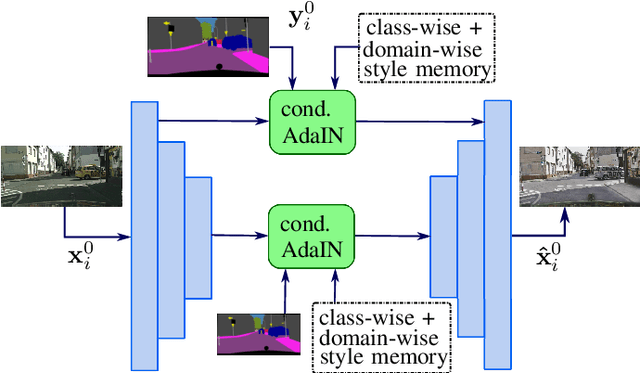
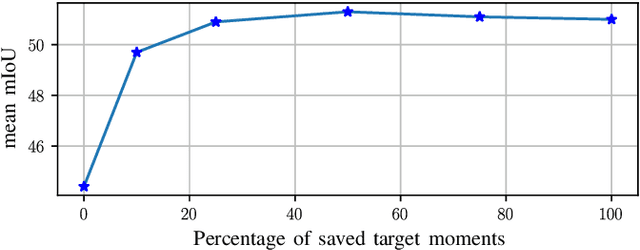
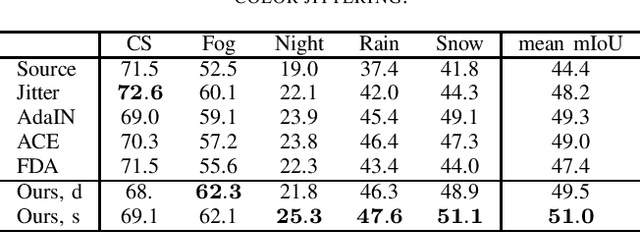
In recent years, there has been tremendous progress in the field of semantic segmentation. However, one remaining challenging problem is that segmentation models do not generalize to unseen domains. To overcome this problem, one either has to label lots of data covering the whole variety of domains, which is often infeasible in practice, or apply unsupervised domain adaptation (UDA), only requiring labeled source data. In this work, we focus on UDA and additionally address the case of adapting not only to a single domain, but to a sequence of target domains. This requires mechanisms preventing the model from forgetting its previously learned knowledge. To adapt a segmentation model to a target domain, we follow the idea of utilizing light-weight style transfer to convert the style of labeled source images into the style of the target domain, while retaining the source content. To mitigate the distributional shift between the source and the target domain, the model is fine-tuned on the transferred source images in a second step. Existing light-weight style transfer approaches relying on adaptive instance normalization (AdaIN) or Fourier transformation still lack performance and do not substantially improve upon common data augmentation, such as color jittering. The reason for this is that these methods do not focus on region- or class-specific differences, but mainly capture the most salient style. Therefore, we propose a simple and light-weight framework that incorporates two class-conditional AdaIN layers. To extract the class-specific target moments needed for the transfer layers, we use unfiltered pseudo-labels, which we show to be an effective approximation compared to real labels. We extensively validate our approach (CACE) on a synthetic sequence and further propose a challenging sequence consisting of real domains. CACE outperforms existing methods visually and quantitatively.