 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Locate Visual Answer in Video Corpus Using Question
Oct 11, 2022
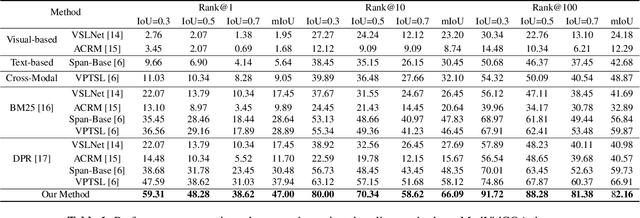
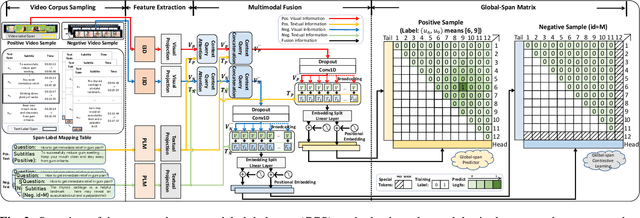

We introduce a novel task, named video corpus visual answer localization (VCVAL), which aims to locate the visual answer in a large collection of untrimmed, unsegmented instructional videos using a natural language question. This task requires a range of skills - the interaction between vision and language, video retrieval, passage comprehension, and visual answer localization. To solve these, we propose a cross-modal contrastive global-span (CCGS) method for the VCVAL, jointly training the video corpus retrieval and visual answer localization tasks. More precisely, we enhance the video question-answer semantic by adding element-wise visual information into the pre-trained language model, and designing a novel global-span predictor through fusion information to locate the visual answer point. The Global-span contrastive learning is adopted to differentiate the span point in the positive and negative samples with the global-span matrix. We have reconstructed a new dataset named MedVidCQA and benchmarked the VCVAL task, where the proposed method achieves state-of-the-art (SOTA) both in the video corpus retrieval and visual answer localization tasks. Most importantly, we pave a new path for understanding the instructional videos, performing detailed analyses on extensive experiments, which ushers in further research.
TransFiner: A Full-Scale Refinement Approach for Multiple Object Tracking
Jul 26, 2022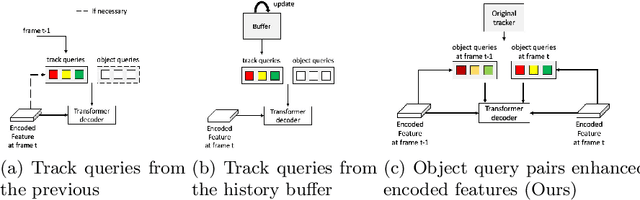
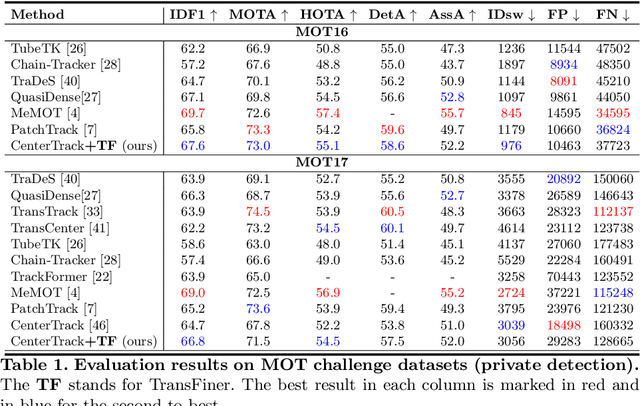
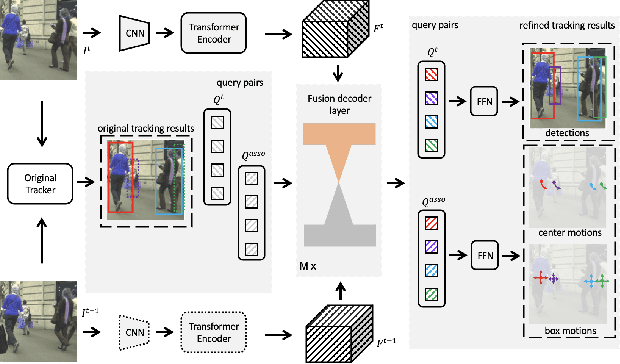
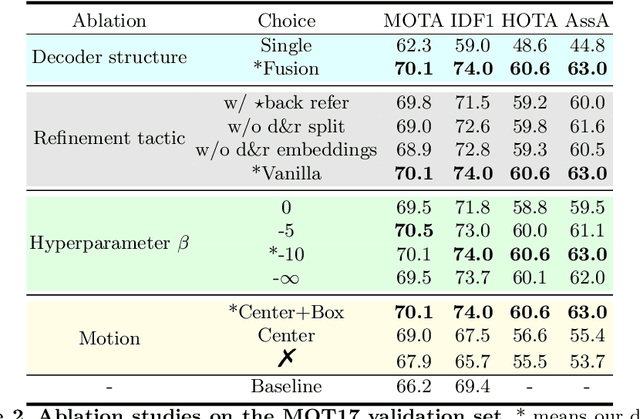
Multiple object tracking (MOT) is the task containing detection and association. Plenty of trackers have achieved competitive performance. Unfortunately, for the lack of informative exchange on these subtasks, they are often biased toward one of the two and remain underperforming in complex scenarios, such as the expected false negatives and mistaken trajectories of targets when passing each other. In this paper, we propose TransFiner, a transformer-based post-refinement approach for MOT. It is a generic attachment framework that leverages the images and tracking results (locations and class predictions) from the original tracker as inputs, which are then used to launch TransFiner powerfully. Moreover, TransFiner depends on query pairs, which produce pairs of detection and motion through the fusion decoder and achieve comprehensive tracking improvement. We also provide targeted refinement by labeling query pairs according to different refinement levels. Experiments show that our design is effective, on the MOT17 benchmark, we elevate the CenterTrack from 67.8% MOTA and 64.7% IDF1 to 71.5% MOTA and 66.8% IDF1.
Scene-Aware Prompt for Multi-modal Dialogue Understanding and Generation
Jul 05, 2022
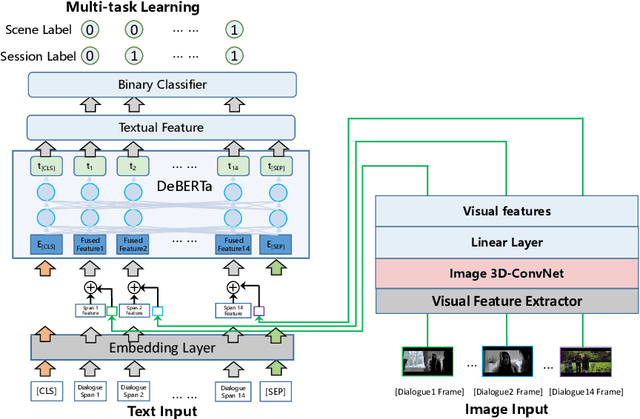
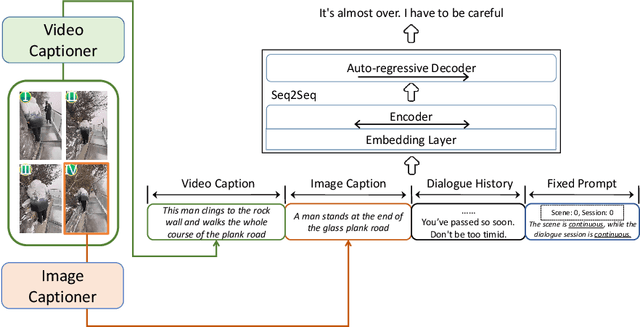
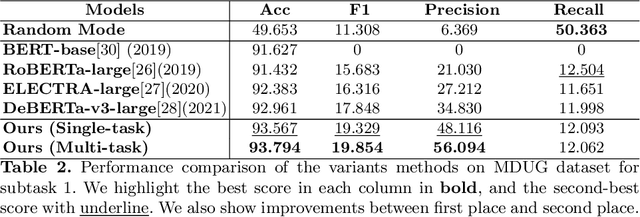
This paper introduces the schemes of Team LingJing's experiments in NLPCC-2022-Shared-Task-4 Multi-modal Dialogue Understanding and Generation (MDUG). The MDUG task can be divided into two phases: multi-modal context understanding and response generation. To fully leverage the visual information for both scene understanding and dialogue generation, we propose the scene-aware prompt for the MDUG task. Specifically, we utilize the multi-tasking strategy for jointly modelling the scene- and session- multi-modal understanding. The visual captions are adopted to aware the scene information, while the fixed-type templated prompt based on the scene- and session-aware labels are used to further improve the dialogue generation performance. Extensive experimental results show that the proposed method has achieved state-of-the-art (SOTA) performance compared with other competitive methods, where we rank the 1-st in all three subtasks in this MDUG competition.
Explicit and implicit models in infrared and visible image fusion
Jun 20, 2022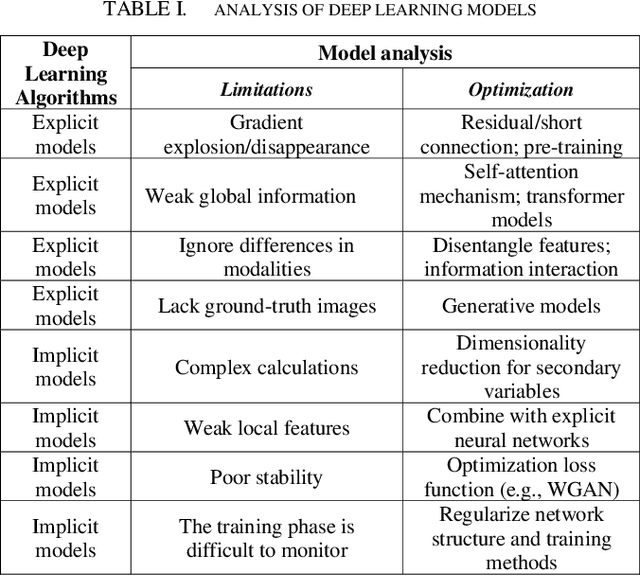
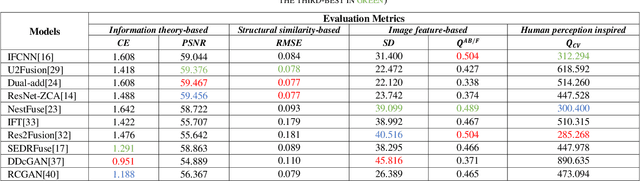
Infrared and visible images, as multi-modal image pairs, show significant differences in the expression of the same scene. The image fusion task is faced with two problems: one is to maintain the unique features between different modalities, and the other is to maintain features at various levels like local and global features. This paper discusses the limitations of deep learning models in image fusion and the corresponding optimization strategies. Based on artificially designed structures and constraints, we divide models into explicit models, and implicit models that adaptively learn high-level features or can establish global pixel associations. Ten models for comparison experiments on 21 test sets were screened. The qualitative and quantitative results show that the implicit models have more comprehensive ability to learn image features. At the same time, the stability of them needs to be improved. Aiming at the advantages and limitations to be solved by existing algorithms, we discuss the main problems of multi-modal image fusion and future research directions.
Towards Layer-wise Image Vectorization
Jun 09, 2022
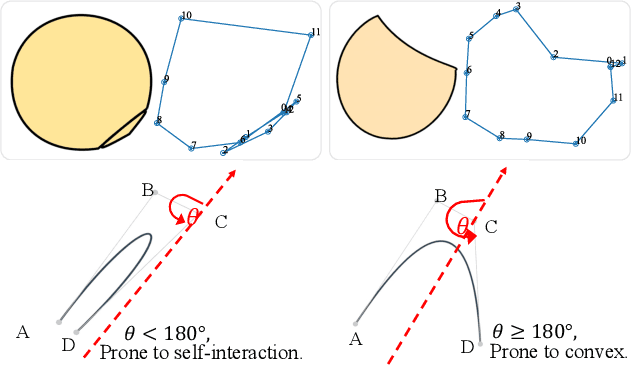


Image rasterization is a mature technique in computer graphics, while image vectorization, the reverse path of rasterization, remains a major challenge. Recent advanced deep learning-based models achieve vectorization and semantic interpolation of vector graphs and demonstrate a better topology of generating new figures. However, deep models cannot be easily generalized to out-of-domain testing data. The generated SVGs also contain complex and redundant shapes that are not quite convenient for further editing. Specifically, the crucial layer-wise topology and fundamental semantics in images are still not well understood and thus not fully explored. In this work, we propose Layer-wise Image Vectorization, namely LIVE, to convert raster images to SVGs and simultaneously maintain its image topology. LIVE can generate compact SVG forms with layer-wise structures that are semantically consistent with human perspective. We progressively add new bezier paths and optimize these paths with the layer-wise framework, newly designed loss functions, and component-wise path initialization technique. Our experiments demonstrate that LIVE presents more plausible vectorized forms than prior works and can be generalized to new images. With the help of this newly learned topology, LIVE initiates human editable SVGs for both designers and other downstream applications. Codes are made available at https://github.com/Picsart-AI-Research/LIVE-Layerwise-Image-Vectorization.
Stop Filtering: Multi-View Attribute-Enhanced Dialogue Learning
May 23, 2022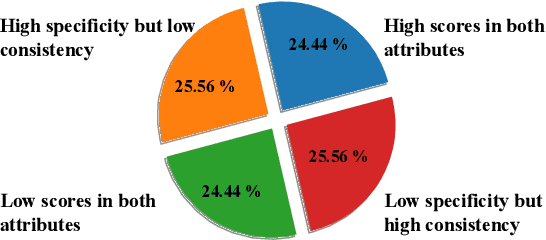
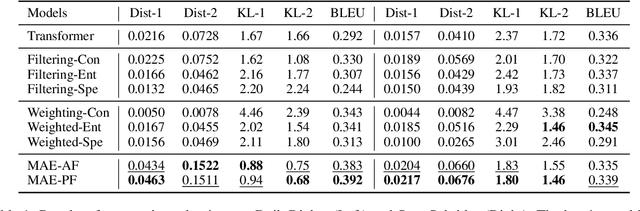
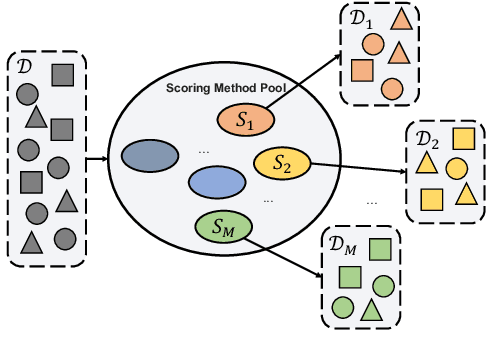
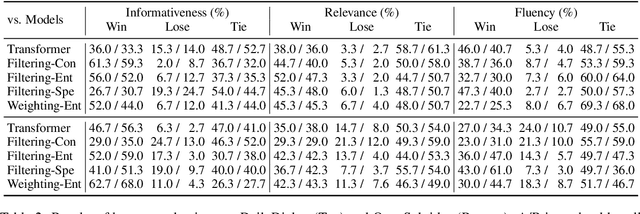
There is a growing interest in improving the conversational ability of models by filtering the raw dialogue corpora. Previous filtering strategies usually rely on a scoring method to assess and discard samples from one perspective, enabling the model to enhance the corresponding dialogue attributes (e.g., consistency) more easily. However, the discarded samples may obtain high scores in other perspectives and can provide regularization effects on the model learning, which causes the performance improvement to be sensitive to the filtering ratio. In this work, we propose a multi-view attribute-enhanced dialogue learning framework that strengthens the attribute-related features more robustly and comprehensively. Instead of filtering the raw dataset to train the model, our framework first pre-trains the model on the raw dataset and then fine-tunes it through adapters on the selected sub-sets, which also enhances certain attributes of responses but without suffering from the problems mentioned above. Considering the variety of the dialogue attribute, we further design a multi-view enhancement mechanism, including multi-view selection and inter-view fusion. It groups the high-quality samples from multiple perspectives, respectively, and enhances different attributes of responses with the corresponding sample sets and adapters, keeping knowledge independent and allowing flexible integration. Empirical results and analysis show that our framework can improve the performance significantly in terms of enhancing dialogue attributes and fusing view-specific knowledge.
Spatio-Temporal Transformer for Dynamic Facial Expression Recognition in the Wild
May 10, 2022
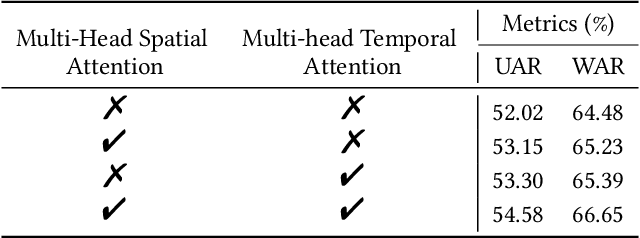
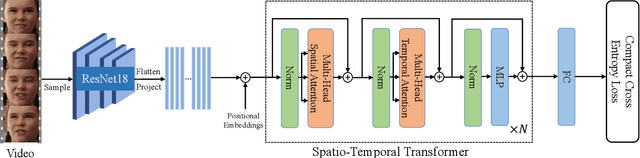
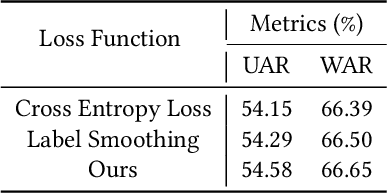
Previous methods for dynamic facial expression in the wild are mainly based on Convolutional Neural Networks (CNNs), whose local operations ignore the long-range dependencies in videos. To solve this problem, we propose the spatio-temporal Transformer (STT) to capture discriminative features within each frame and model contextual relationships among frames. Spatio-temporal dependencies are captured and integrated by our unified Transformer. Specifically, given an image sequence consisting of multiple frames as input, we utilize the CNN backbone to translate each frame into a visual feature sequence. Subsequently, the spatial attention and the temporal attention within each block are jointly applied for learning spatio-temporal representations at the sequence level. In addition, we propose the compact softmax cross entropy loss to further encourage the learned features have the minimum intra-class distance and the maximum inter-class distance. Experiments on two in-the-wild dynamic facial expression datasets (i.e., DFEW and AFEW) indicate that our method provides an effective way to make use of the spatial and temporal dependencies for dynamic facial expression recognition. The source code and the training logs will be made publicly available.
Diversifying Neural Dialogue Generation via Negative Distillation
May 05, 2022
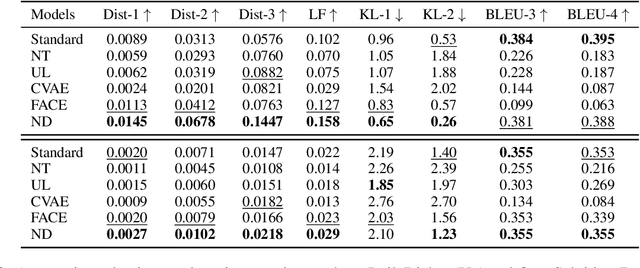
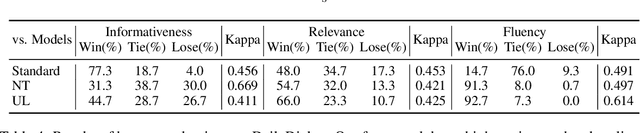
Generative dialogue models suffer badly from the generic response problem, limiting their applications to a few toy scenarios. Recently, an interesting approach, namely negative training, has been proposed to alleviate this problem by reminding the model not to generate high-frequency responses during training. However, its performance is hindered by two issues, ignoring low-frequency but generic responses and bringing low-frequency but meaningless responses. In this paper, we propose a novel negative training paradigm, called negative distillation, to keep the model away from the undesirable generic responses while avoiding the above problems. First, we introduce a negative teacher model that can produce query-wise generic responses, and then the student model is required to maximize the distance with multi-level negative knowledge. Empirical results show that our method outperforms previous negative training methods significantly.
LingYi: Medical Conversational Question Answering System based on Multi-modal Knowledge Graphs
Apr 20, 2022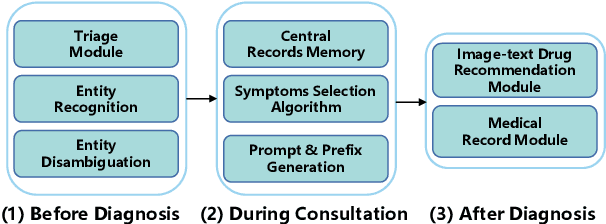
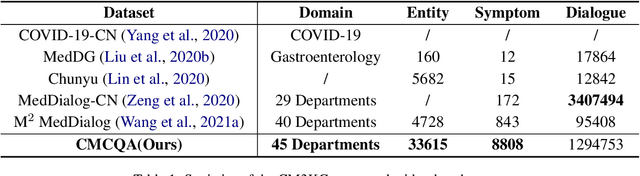
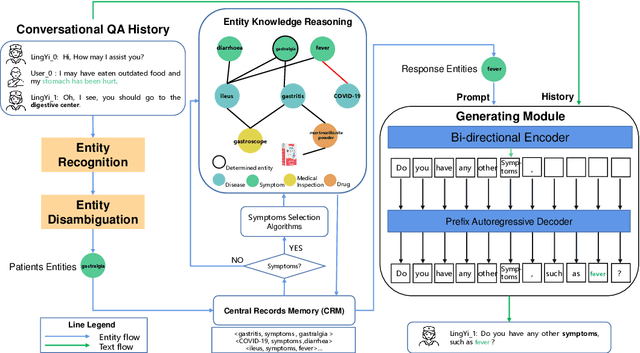
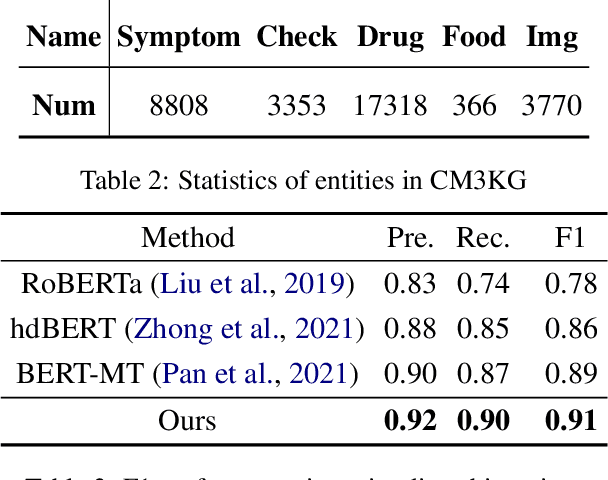
The medical conversational system can relieve the burden of doctors and improve the efficiency of healthcare, especially during the pandemic. This paper presents a medical conversational question answering (CQA) system based on the multi-modal knowledge graph, namely "LingYi", which is designed as a pipeline framework to maintain high flexibility. Our system utilizes automated medical procedures including medical triage, consultation, image-text drug recommendation and record. To conduct knowledge-grounded dialogues with patients, we first construct a Chinese Medical Multi-Modal Knowledge Graph (CM3KG) and collect a large-scale Chinese Medical CQA (CMCQA) dataset. Compared with the other existing medical question-answering systems, our system adopts several state-of-the-art technologies including medical entity disambiguation and medical dialogue generation, which is more friendly to provide medical services to patients. In addition, we have open-sourced our codes which contain back-end models and front-end web pages at https://github.com/WENGSYX/LingYi. The datasets including CM3KG at https://github.com/WENGSYX/CM3KG and CMCQA at https://github.com/WENGSYX/CMCQA are also released to further promote future research.
Towards Visual-Prompt Temporal Answering Grounding in Medical Instructional Video
Mar 29, 2022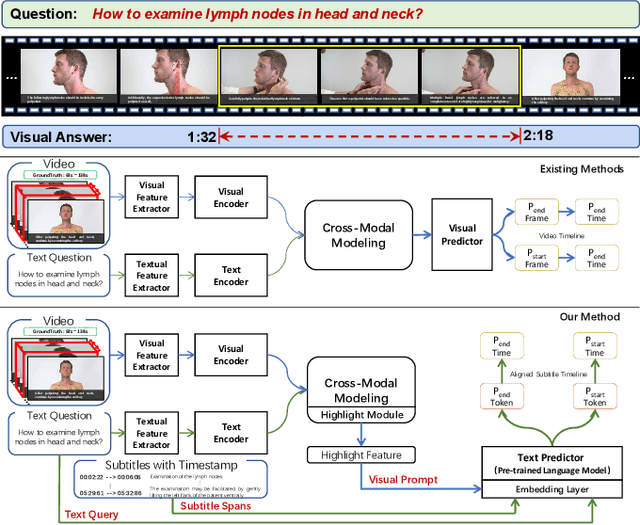
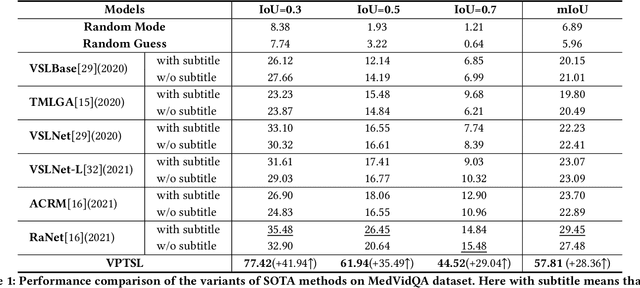
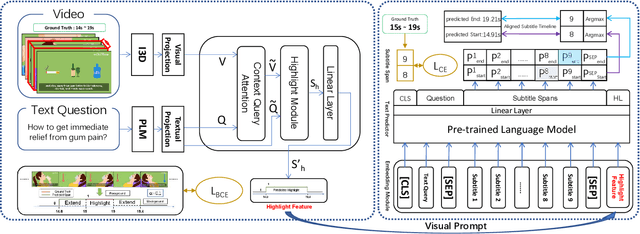

The temporal answering grounding in the video (TAGV) is a new task naturally derived from temporal sentence grounding in the video (TSGV). Given an untrimmed video and a text question, this task aims at locating the matching span from the video that can semantically answer the question. Existing methods tend to formulate the TAGV task with a visual span-based question answering (QA) approach by matching the visual frame span queried by the text question. However, due to the weak correlations and huge gaps of the semantic features between the textual question and visual answer, existing methods adopting visual span predictor perform poorly in the TAGV task. To bridge these gaps, we propose a visual-prompt text span localizing (VPTSL) method, which introduces the timestamped subtitles as a passage to perform the text span localization for the input text question, and prompts the visual highlight features into the pre-trained language model (PLM) for enhancing the joint semantic representations. Specifically, the context query attention is utilized to perform cross-modal interaction between the extracted textual and visual features. Then, the highlight features are obtained through the video-text highlighting for the visual prompt. To alleviate semantic differences between textual and visual features, we design the text span predictor by encoding the question, the subtitles, and the prompted visual highlight features with the PLM. As a result, the TAGV task is formulated to predict the span of subtitles matching the visual answer. Extensive experiments on the medical instructional dataset, namely MedVidQA, show that the proposed VPTSL outperforms the state-of-the-art (SOTA) method by 28.36% in terms of mIOU with a large margin, which demonstrates the effectiveness of the proposed visual prompt and the text span predictor.