 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCFEA: Collaborative Feature Ensembling Adaptation for Domain Adaptation in Unsupervised Optic Disc and Cup Segmentation
Oct 16, 2019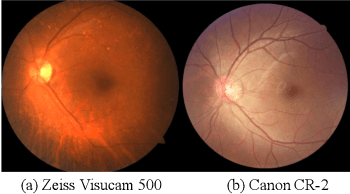

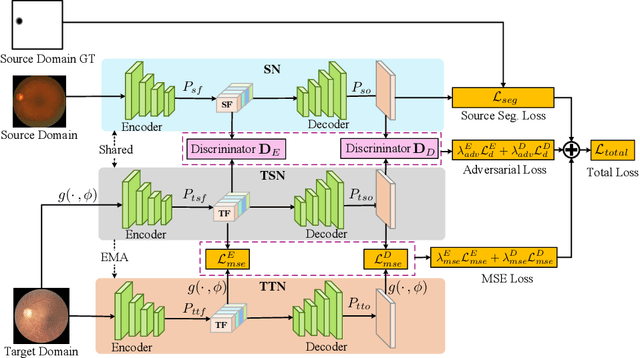

Recently, deep neural networks have demonstrated comparable and even better performance with board-certified ophthalmologists in well-annotated datasets. However, the diversity of retinal imaging devices poses a significant challenge: domain shift, which leads to performance degradation when applying the deep learning models to new testing domains. In this paper, we propose a novel unsupervised domain adaptation framework, called Collaborative Feature Ensembling Adaptation (CFEA), to effectively overcome this challenge. Our proposed CFEA is an interactive paradigm which presents an exquisite of collaborative adaptation through both adversarial learning and ensembling weights. In particular, we simultaneously achieve domain-invariance and maintain an exponential moving average of the historical predictions, which achieves a better prediction for the unlabeled data, via ensembling weights during training. Without annotating any sample from the target domain, multiple adversarial losses in encoder and decoder layers guide the extraction of domain-invariant features to confuse the domain classifier and meanwhile benefit the ensembling of smoothing weights. Comprehensive experimental results demonstrate that our CFEA model can overcome performance degradation and outperform the state-of-the-art methods in segmenting retinal optic disc and cup from fundus images. \textit{Code is available at \url{https://github.com/cswin/AWC}}.
A Hybrid Persian Sentiment Analysis Framework: Integrating Dependency Grammar Based Rules and Deep Neural Networks
Sep 30, 2019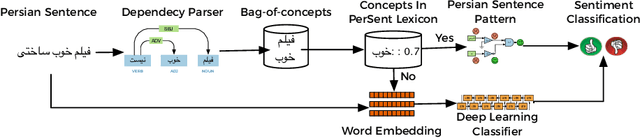

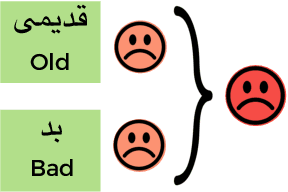
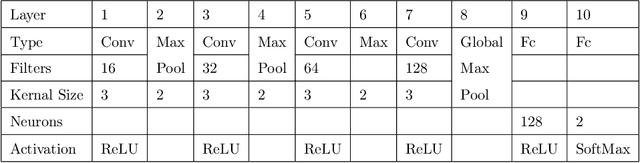
Social media hold valuable, vast and unstructured information on public opinion that can be utilized to improve products and services. The automatic analysis of such data, however, requires a deep understanding of natural language. Current sentiment analysis approaches are mainly based on word co-occurrence frequencies, which are inadequate in most practical cases. In this work, we propose a novel hybrid framework for concept-level sentiment analysis in Persian language, that integrates linguistic rules and deep learning to optimize polarity detection. When a pattern is triggered, the framework allows sentiments to flow from words to concepts based on symbolic dependency relations. When no pattern is triggered, the framework switches to its subsymbolic counterpart and leverages deep neural networks (DNN) to perform the classification. The proposed framework outperforms state-of-the-art approaches (including support vector machine, and logistic regression) and DNN classifiers (long short-term memory, and Convolutional Neural Networks) with a margin of 10-15% and 3-4% respectively, using benchmark Persian product and hotel reviews corpora.
Residual Attention based Network for Hand Bone Age Assessment
Dec 21, 2018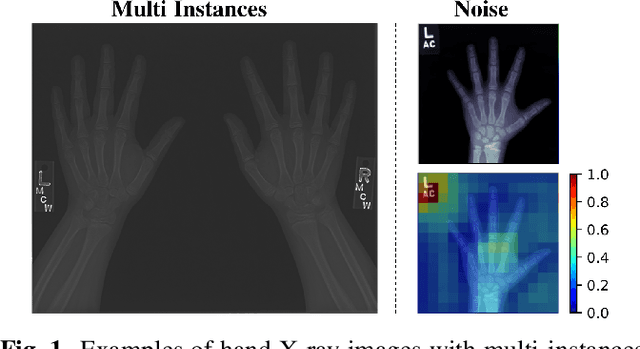

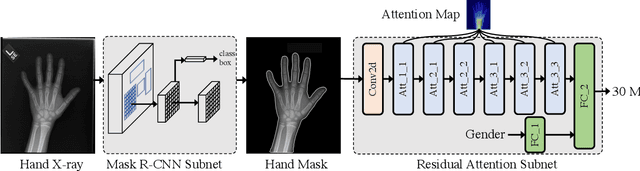

Computerized automatic methods have been employed to boost the productivity as well as objectiveness of hand bone age assessment. These approaches make predictions according to the whole X-ray images, which include other objects that may introduce distractions. Instead, our framework is inspired by the clinical workflow (Tanner-Whitehouse) of hand bone age assessment, which focuses on the key components of the hand. The proposed framework is composed of two components: a Mask R-CNN subnet of pixelwise hand segmentation and a residual attention network for hand bone age assessment. The Mask R-CNN subnet segments the hands from X-ray images to avoid the distractions of other objects (e.g., X-ray tags). The hierarchical attention components of the residual attention subnet force our network to focus on the key components of the X-ray images and generate the final predictions as well as the associated visual supports, which is similar to the assessment procedure of clinicians. We evaluate the performance of the proposed pipeline on the RSNA pediatric bone age dataset and the results demonstrate its superiority over the previous methods.
Saliency Detection via Bidirectional Absorbing Markov Chain
Aug 25, 2018
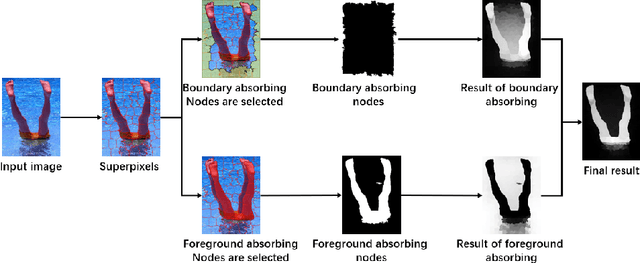


Traditional saliency detection via Markov chain only considers boundaries nodes. However, in addition to boundaries cues, background prior and foreground prior cues play a complementary role to enhance saliency detection. In this paper, we propose an absorbing Markov chain based saliency detection method considering both boundary information and foreground prior cues. The proposed approach combines both boundaries and foreground prior cues through bidirectional Markov chain. Specifically, the image is first segmented into superpixels and four boundaries nodes (duplicated as virtual nodes) are selected. Subsequently, the absorption time upon transition node's random walk to the absorbing state is calculated to obtain foreground possibility. Simultaneously, foreground prior as the virtual absorbing nodes is used to calculate the absorption time and obtain the background possibility. Finally, two obtained results are fused to obtain the combined saliency map using cost function for further optimization at multi-scale. Experimental results demonstrate the outperformance of our proposed model on 4 benchmark datasets as compared to 17 state-of-the-art methods.