 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning the Legibility of Visual Text Perturbations
Mar 10, 2023Many adversarial attacks in NLP perturb inputs to produce visually similar strings ('ergo' $\rightarrow$ '$\epsilon$rgo') which are legible to humans but degrade model performance. Although preserving legibility is a necessary condition for text perturbation, little work has been done to systematically characterize it; instead, legibility is typically loosely enforced via intuitions around the nature and extent of perturbations. Particularly, it is unclear to what extent can inputs be perturbed while preserving legibility, or how to quantify the legibility of a perturbed string. In this work, we address this gap by learning models that predict the legibility of a perturbed string, and rank candidate perturbations based on their legibility. To do so, we collect and release LEGIT, a human-annotated dataset comprising the legibility of visually perturbed text. Using this dataset, we build both text- and vision-based models which achieve up to $0.91$ F1 score in predicting whether an input is legible, and an accuracy of $0.86$ in predicting which of two given perturbations is more legible. Additionally, we discover that legible perturbations from the LEGIT dataset are more effective at lowering the performance of NLP models than best-known attack strategies, suggesting that current models may be vulnerable to a broad range of perturbations beyond what is captured by existing visual attacks. Data, code, and models are available at https://github.com/dvsth/learning-legibility-2023.
DIFFQG: Generating Questions to Summarize Factual Changes
Mar 01, 2023



Identifying the difference between two versions of the same article is useful to update knowledge bases and to understand how articles evolve. Paired texts occur naturally in diverse situations: reporters write similar news stories and maintainers of authoritative websites must keep their information up to date. We propose representing factual changes between paired documents as question-answer pairs, where the answer to the same question differs between two versions. We find that question-answer pairs can flexibly and concisely capture the updated contents. Provided with paired documents, annotators identify questions that are answered by one passage but answered differently or cannot be answered by the other. We release DIFFQG which consists of 759 QA pairs and 1153 examples of paired passages with no factual change. These questions are intended to be both unambiguous and information-seeking and involve complex edits, pushing beyond the capabilities of current question generation and factual change detection systems. Our dataset summarizes the changes between two versions of the document as questions and answers, studying automatic update summarization in a novel way.
On the State of the Art in Authorship Attribution and Authorship Verification
Sep 14, 2022


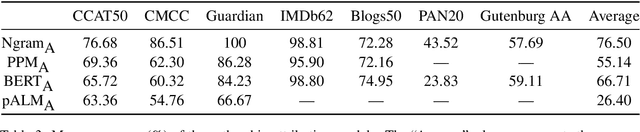
Despite decades of research on authorship attribution (AA) and authorship verification (AV), inconsistent dataset splits/filtering and mismatched evaluation methods make it difficult to assess the state of the art. In this paper, we present a survey of the fields, resolve points of confusion, introduce Valla that standardizes and benchmarks AA/AV datasets and metrics, provide a large-scale empirical evaluation, and provide apples-to-apples comparisons between existing methods. We evaluate eight promising methods on fifteen datasets (including distribution-shifted challenge sets) and introduce a new large-scale dataset based on texts archived by Project Gutenberg. Surprisingly, we find that a traditional Ngram-based model performs best on 5 (of 7) AA tasks, achieving an average macro-accuracy of $76.50\%$ (compared to $66.71\%$ for a BERT-based model). However, on the two AA datasets with the greatest number of words per author, as well as on the AV datasets, BERT-based models perform best. While AV methods are easily applied to AA, they are seldom included as baselines in AA papers. We show that through the application of hard-negative mining, AV methods are competitive alternatives to AA methods. Valla and all experiment code can be found here: https://github.com/JacobTyo/Valla
Characterizing the Efficiency vs. Accuracy Trade-off for Long-Context NLP Models
Apr 15, 2022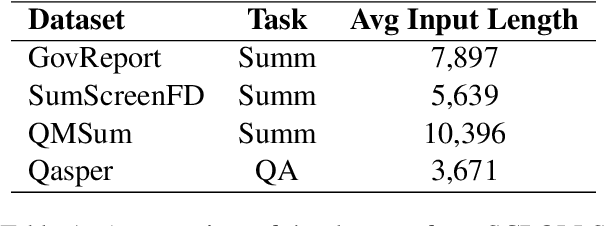
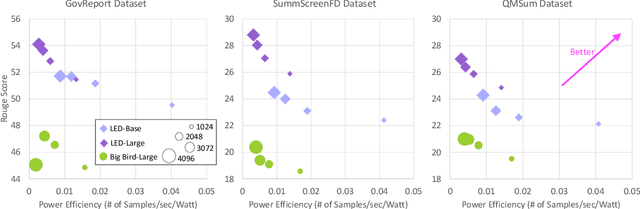
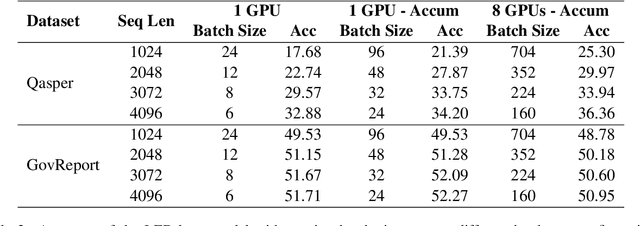
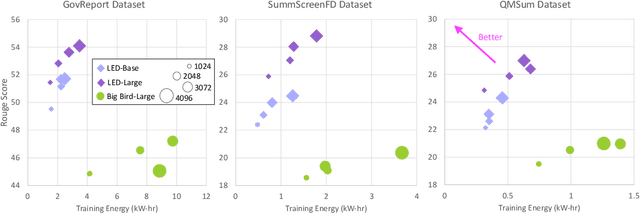
With many real-world applications of Natural Language Processing (NLP) comprising of long texts, there has been a rise in NLP benchmarks that measure the accuracy of models that can handle longer input sequences. However, these benchmarks do not consider the trade-offs between accuracy, speed, and power consumption as input sizes or model sizes are varied. In this work, we perform a systematic study of this accuracy vs. efficiency trade-off on two widely used long-sequence models - Longformer-Encoder-Decoder (LED) and Big Bird - during fine-tuning and inference on four datasets from the SCROLLS benchmark. To study how this trade-off differs across hyperparameter settings, we compare the models across four sequence lengths (1024, 2048, 3072, 4096) and two model sizes (base and large) under a fixed resource budget. We find that LED consistently achieves better accuracy at lower energy costs than Big Bird. For summarization, we find that increasing model size is more energy efficient than increasing sequence length for higher accuracy. However, this comes at the cost of a large drop in inference speed. For question answering, we find that smaller models are both more efficient and more accurate due to the larger training batch sizes possible under a fixed resource budget.
ASQA: Factoid Questions Meet Long-Form Answers
Apr 12, 2022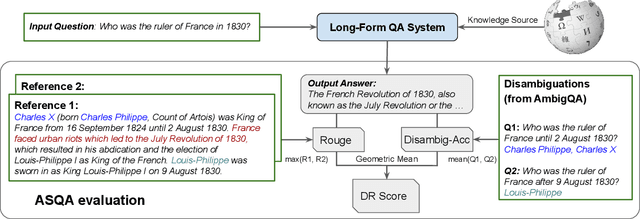

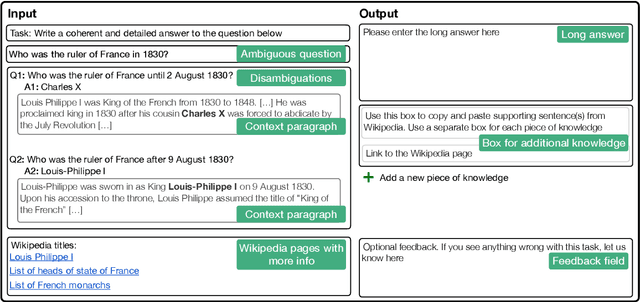
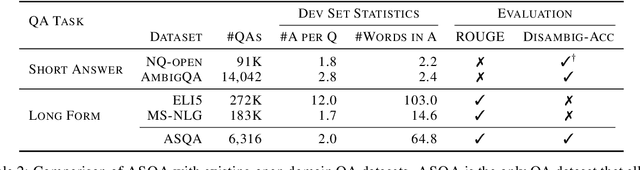
An abundance of datasets and availability of reliable evaluation metrics have resulted in strong progress in factoid question answering (QA). This progress, however, does not easily transfer to the task of long-form QA, where the goal is to answer questions that require in-depth explanations. The hurdles include (i) a lack of high-quality data, and (ii) the absence of a well-defined notion of the answer's quality. In this work, we address these problems by (i) releasing a novel dataset and a task that we call ASQA (Answer Summaries for Questions which are Ambiguous); and (ii) proposing a reliable metric for measuring performance on ASQA. Our task focuses on factoid questions that are ambiguous, that is, have different correct answers depending on interpretation. Answers to ambiguous questions should synthesize factual information from multiple sources into a long-form summary that resolves the ambiguity. In contrast to existing long-form QA tasks (such as ELI5), ASQA admits a clear notion of correctness: a user faced with a good summary should be able to answer different interpretations of the original ambiguous question. We use this notion of correctness to define an automated metric of performance for ASQA. Our analysis demonstrates an agreement between this metric and human judgments, and reveals a considerable gap between human performance and strong baselines.
Time-Aware Language Models as Temporal Knowledge Bases
Jun 29, 2021
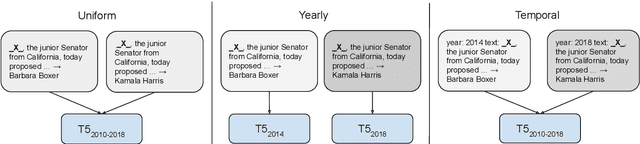
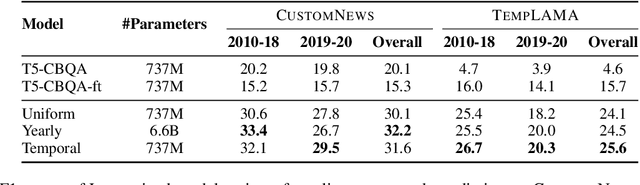
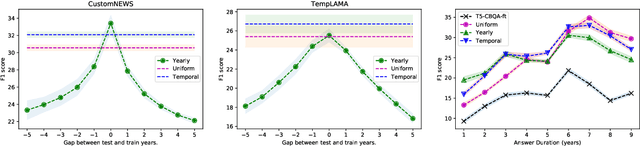
Many facts come with an expiration date, from the name of the President to the basketball team Lebron James plays for. But language models (LMs) are trained on snapshots of data collected at a specific moment in time, and this can limit their utility, especially in the closed-book setting where the pretraining corpus must contain the facts the model should memorize. We introduce a diagnostic dataset aimed at probing LMs for factual knowledge that changes over time and highlight problems with LMs at either end of the spectrum -- those trained on specific slices of temporal data, as well as those trained on a wide range of temporal data. To mitigate these problems, we propose a simple technique for jointly modeling text with its timestamp. This improves memorization of seen facts from the training time period, as well as calibration on predictions about unseen facts from future time periods. We also show that models trained with temporal context can be efficiently ``refreshed'' as new data arrives, without the need for retraining from scratch.
Fool Me Twice: Entailment from Wikipedia Gamification
Apr 10, 2021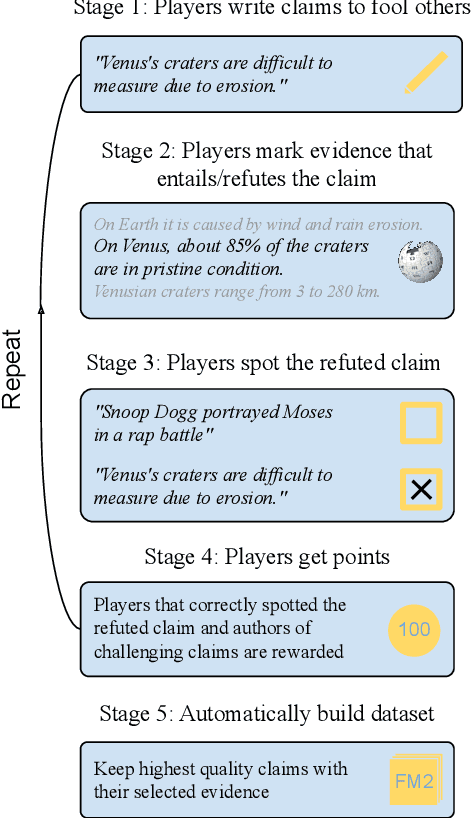
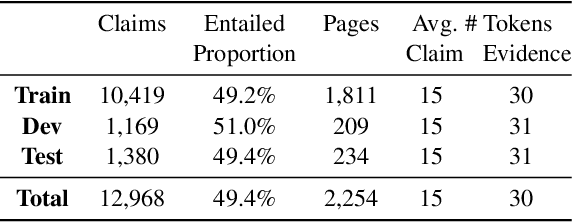

We release FoolMeTwice (FM2 for short), a large dataset of challenging entailment pairs collected through a fun multi-player game. Gamification encourages adversarial examples, drastically lowering the number of examples that can be solved using "shortcuts" compared to other popular entailment datasets. Players are presented with two tasks. The first task asks the player to write a plausible claim based on the evidence from a Wikipedia page. The second one shows two plausible claims written by other players, one of which is false, and the goal is to identify it before the time runs out. Players "pay" to see clues retrieved from the evidence pool: the more evidence the player needs, the harder the claim. Game-play between motivated players leads to diverse strategies for crafting claims, such as temporal inference and diverting to unrelated evidence, and results in higher quality data for the entailment and evidence retrieval tasks. We open source the dataset and the game code.
Reasoning Over Virtual Knowledge Bases With Open Predicate Relations
Feb 14, 2021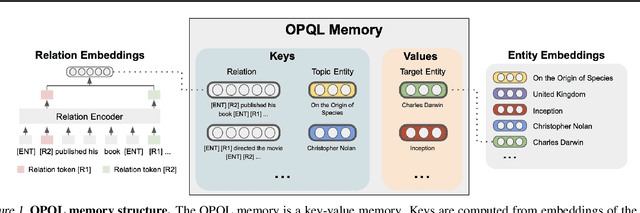
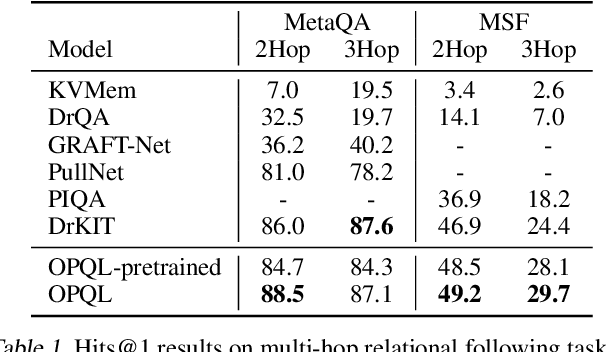
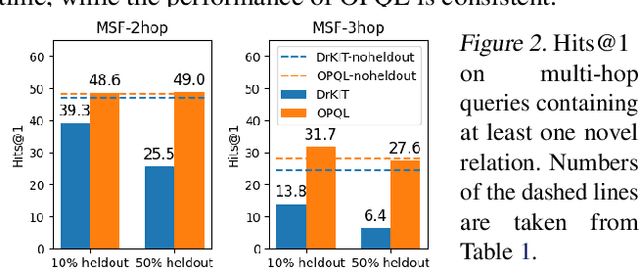
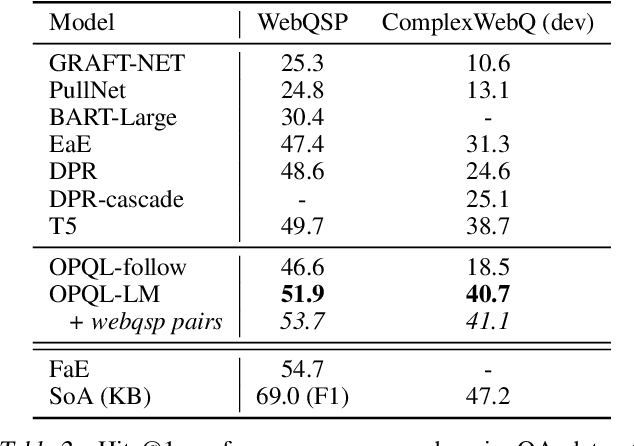
We present the Open Predicate Query Language (OPQL); a method for constructing a virtual KB (VKB) trained entirely from text. Large Knowledge Bases (KBs) are indispensable for a wide-range of industry applications such as question answering and recommendation. Typically, KBs encode world knowledge in a structured, readily accessible form derived from laborious human annotation efforts. Unfortunately, while they are extremely high precision, KBs are inevitably highly incomplete and automated methods for enriching them are far too inaccurate. Instead, OPQL constructs a VKB by encoding and indexing a set of relation mentions in a way that naturally enables reasoning and can be trained without any structured supervision. We demonstrate that OPQL outperforms prior VKB methods on two different KB reasoning tasks and, additionally, can be used as an external memory integrated into a language model (OPQL-LM) leading to improvements on two open-domain question answering tasks.
Evaluating Explanations: How much do explanations from the teacher aid students?
Dec 01, 2020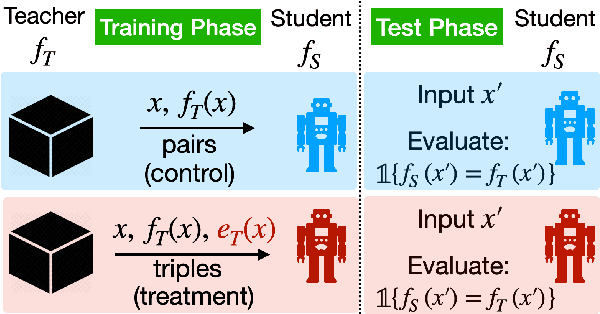
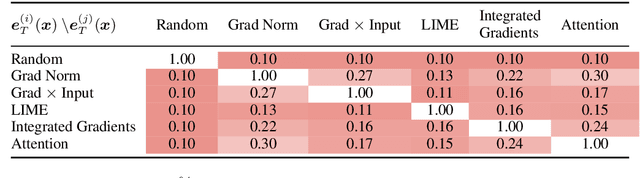

While many methods purport to explain predictions by highlighting salient features, what precise aims these explanations serve and how to evaluate their utility are often unstated. In this work, we formalize the value of explanations using a student-teacher paradigm that measures the extent to which explanations improve student models in learning to simulate the teacher model on unseen examples for which explanations are unavailable. Student models incorporate explanations in training (but not prediction) procedures. Unlike many prior proposals to evaluate explanations, our approach cannot be easily gamed, enabling principled, scalable, and automatic evaluation of attributions. Using our framework, we compare multiple attribution methods and observe consistent and quantitative differences amongst them across multiple learning strategies.
Weakly- and Semi-supervised Evidence Extraction
Nov 03, 2020
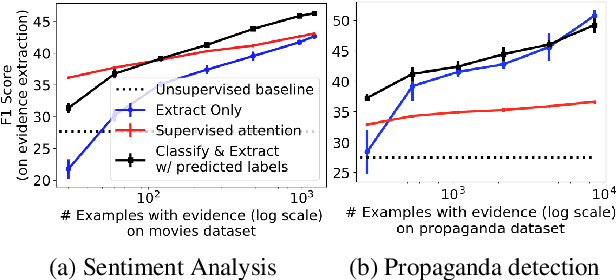

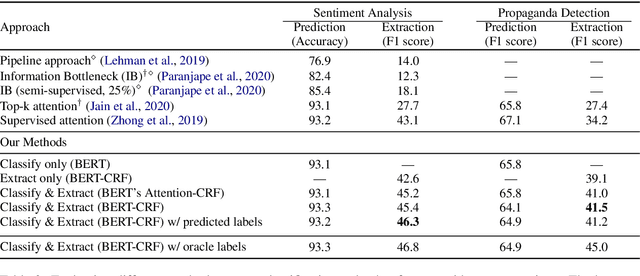
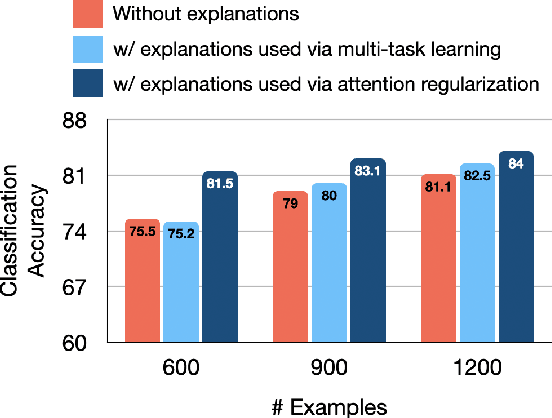
For many prediction tasks, stakeholders desire not only predictions but also supporting evidence that a human can use to verify its correctness. However, in practice, additional annotations marking supporting evidence may only be available for a minority of training examples (if available at all). In this paper, we propose new methods to combine few evidence annotations (strong semi-supervision) with abundant document-level labels (weak supervision) for the task of evidence extraction. Evaluating on two classification tasks that feature evidence annotations, we find that our methods outperform baselines adapted from the interpretability literature to our task. Our approach yields substantial gains with as few as hundred evidence annotations. Code and datasets to reproduce our work are available at https://github.com/danishpruthi/evidence-extraction.