 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing Graph Neural Networks to model the performance of Deep Neural Networks
Aug 27, 2021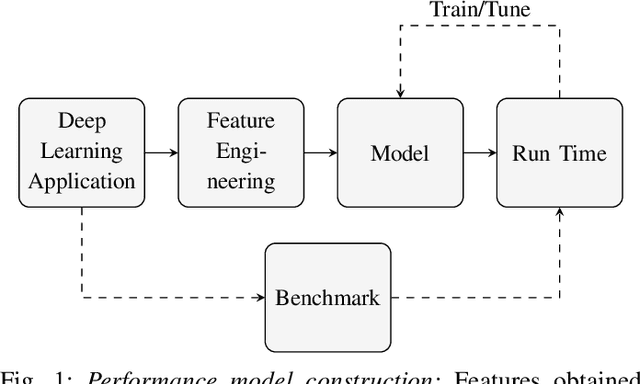
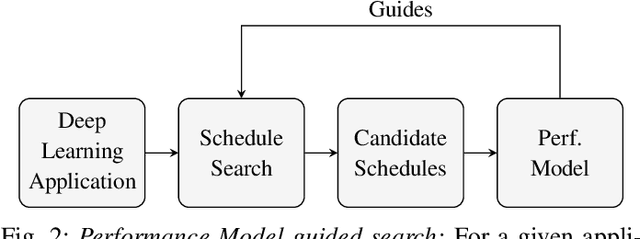
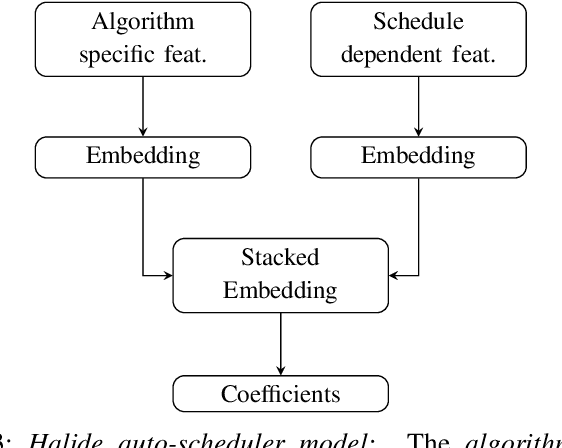
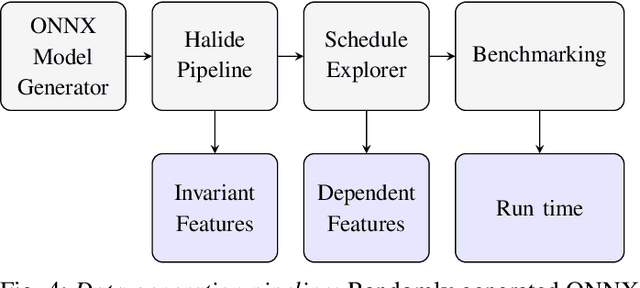
With the unprecedented proliferation of machine learning software, there is an ever-increasing need to generate efficient code for such applications. State-of-the-art deep-learning compilers like TVM and Halide incorporate a learning-based performance model to search the space of valid implementations of a given deep learning algorithm. For a given application, the model generates a performance metric such as the run time without executing the application on hardware. Such models speed up the compilation process by obviating the need to benchmark an enormous number of candidate implementations, referred to as schedules, on hardware. Existing performance models employ feed-forward networks, recurrent networks, or decision tree ensembles to estimate the performance of different implementations of a neural network. Graphs present a natural and intuitive way to model deep-learning networks where each node represents a computational stage or operation. Incorporating the inherent graph structure of these workloads in the performance model can enable a better representation and learning of inter-stage interactions. The accuracy of a performance model has direct implications on the efficiency of the search strategy, making it a crucial component of this class of deep-learning compilers. In this work, we develop a novel performance model that adopts a graph representation. In our model, each stage of computation represents a node characterized by features that capture the operations performed by the stage. The interaction between nodes is achieved using graph convolutions. Experimental evaluation shows a 7:75x and 12x reduction in prediction error compared to the Halide and TVM models, respectively.
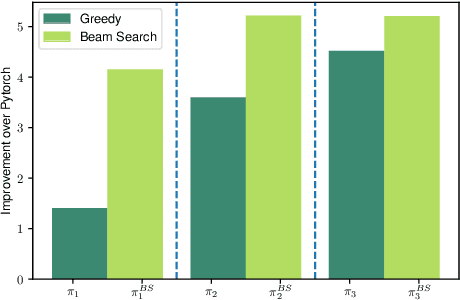
Learning Space Partitions for Path Planning
Jul 14, 2021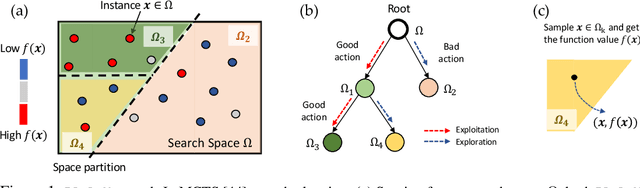

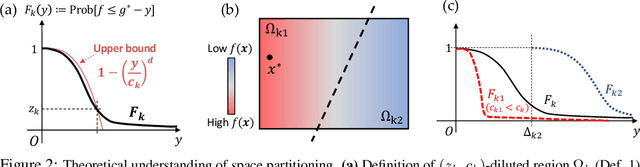
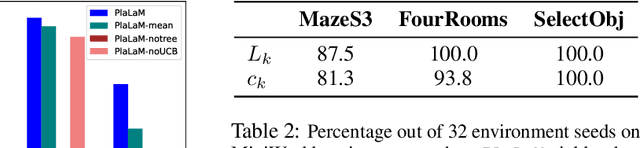
Path planning, the problem of efficiently discovering high-reward trajectories, often requires optimizing a high-dimensional and multimodal reward function. Popular approaches like CEM and CMA-ES greedily focus on promising regions of the search space and may get trapped in local maxima. DOO and VOOT balance exploration and exploitation, but use space partitioning strategies independent of the reward function to be optimized. Recently, LaMCTS empirically learns to partition the search space in a reward-sensitive manner for black-box optimization. In this paper, we develop a novel formal regret analysis for when and why such an adaptive region partitioning scheme works. We also propose a new path planning method PlaLaM which improves the function value estimation within each sub-region, and uses a latent representation of the search space. Empirically, PlaLaM outperforms existing path planning methods in 2D navigation tasks, especially in the presence of difficult-to-escape local optima, and shows benefits when plugged into model-based RL with planning components such as PETS. These gains transfer to highly multimodal real-world tasks, where we outperform strong baselines in compiler phase ordering by up to 245% and in molecular design by up to 0.4 on properties on a 0-1 scale. Code is available at https://github.com/yangkevin2/plalam.
Value Function Based Performance Optimization of Deep Learning Workloads
Nov 30, 2020
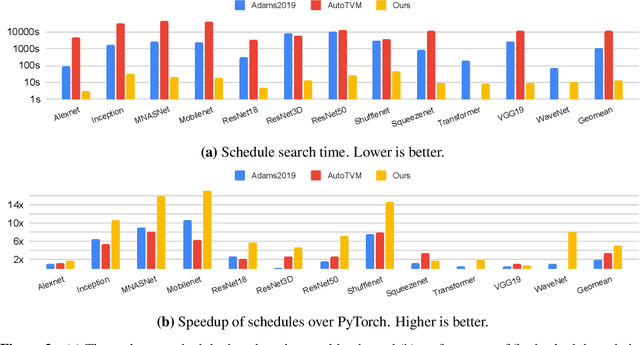
As machine learning techniques become ubiquitous, the efficiency of neural network implementations is becoming correspondingly paramount. Frameworks, such as Halide and TVM, separate out the algorithmic representation of the network from the schedule that determines its implementation. Finding good schedules, however, remains extremely challenging. We model this scheduling problem as a sequence of optimization choices, and present a new technique to accurately predict the expected performance of a partial schedule. By leveraging these predictions we can make these optimization decisions greedily and rapidly identify an efficient schedule. This enables us to find schedules that improve the throughput of deep neural networks by 2.6x over Halide and 1.5x over TVM. Moreover, our technique is two to three orders of magnitude faster than that of these tools, and completes in seconds instead of hours.
PyTorch: An Imperative Style, High-Performance Deep Learning Library
Dec 03, 2019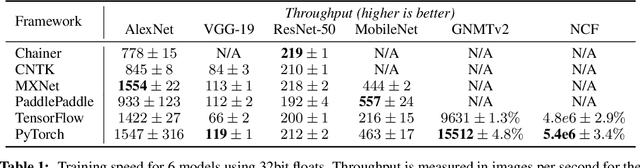

Deep learning frameworks have often focused on either usability or speed, but not both. PyTorch is a machine learning library that shows that these two goals are in fact compatible: it provides an imperative and Pythonic programming style that supports code as a model, makes debugging easy and is consistent with other popular scientific computing libraries, while remaining efficient and supporting hardware accelerators such as GPUs. In this paper, we detail the principles that drove the implementation of PyTorch and how they are reflected in its architecture. We emphasize that every aspect of PyTorch is a regular Python program under the full control of its user. We also explain how the careful and pragmatic implementation of the key components of its runtime enables them to work together to achieve compelling performance. We demonstrate the efficiency of individual subsystems, as well as the overall speed of PyTorch on several common benchmarks.
Device Placement Optimization with Reinforcement Learning
Jun 25, 2017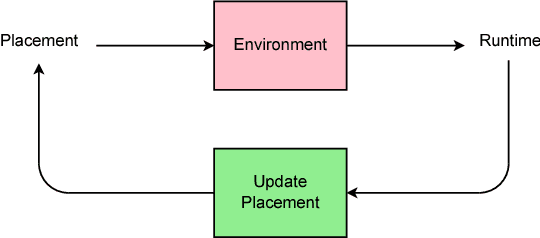
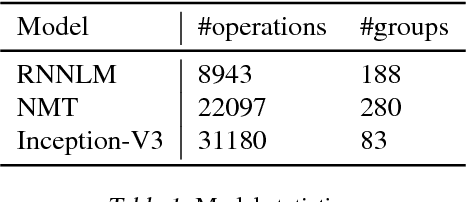
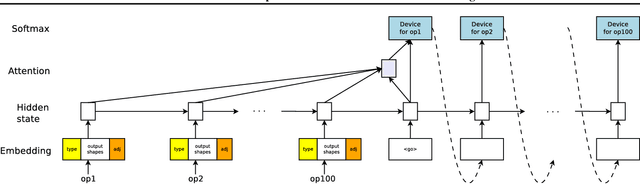
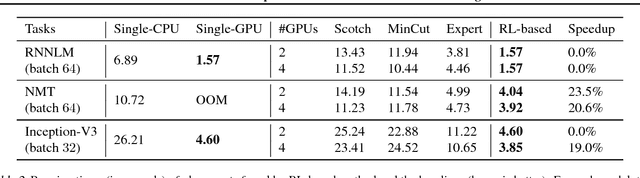
The past few years have witnessed a growth in size and computational requirements for training and inference with neural networks. Currently, a common approach to address these requirements is to use a heterogeneous distributed environment with a mixture of hardware devices such as CPUs and GPUs. Importantly, the decision of placing parts of the neural models on devices is often made by human experts based on simple heuristics and intuitions. In this paper, we propose a method which learns to optimize device placement for TensorFlow computational graphs. Key to our method is the use of a sequence-to-sequence model to predict which subsets of operations in a TensorFlow graph should run on which of the available devices. The execution time of the predicted placements is then used as the reward signal to optimize the parameters of the sequence-to-sequence model. Our main result is that on Inception-V3 for ImageNet classification, and on RNN LSTM, for language modeling and neural machine translation, our model finds non-trivial device placements that outperform hand-crafted heuristics and traditional algorithmic methods.
TensorFlow: A system for large-scale machine learning
May 31, 2016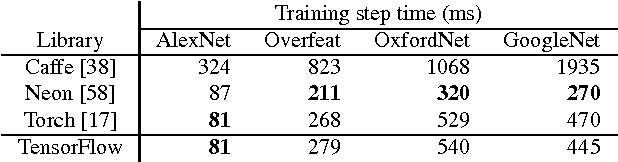

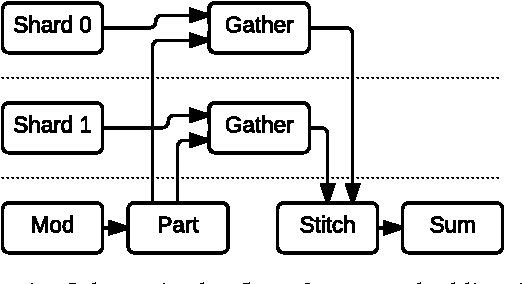
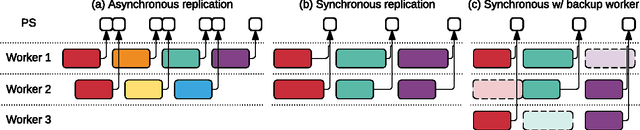
TensorFlow is a machine learning system that operates at large scale and in heterogeneous environments. TensorFlow uses dataflow graphs to represent computation, shared state, and the operations that mutate that state. It maps the nodes of a dataflow graph across many machines in a cluster, and within a machine across multiple computational devices, including multicore CPUs, general-purpose GPUs, and custom designed ASICs known as Tensor Processing Units (TPUs). This architecture gives flexibility to the application developer: whereas in previous "parameter server" designs the management of shared state is built into the system, TensorFlow enables developers to experiment with novel optimizations and training algorithms. TensorFlow supports a variety of applications, with particularly strong support for training and inference on deep neural networks. Several Google services use TensorFlow in production, we have released it as an open-source project, and it has become widely used for machine learning research. In this paper, we describe the TensorFlow dataflow model in contrast to existing systems, and demonstrate the compelling performance that TensorFlow achieves for several real-world applications.
TensorFlow: Large-Scale Machine Learning on Heterogeneous Distributed Systems
Mar 16, 2016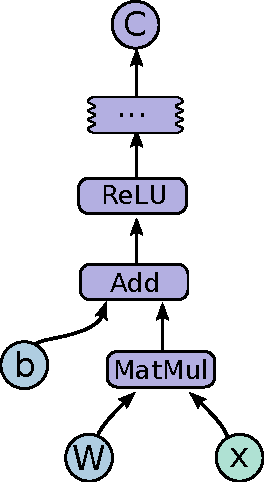

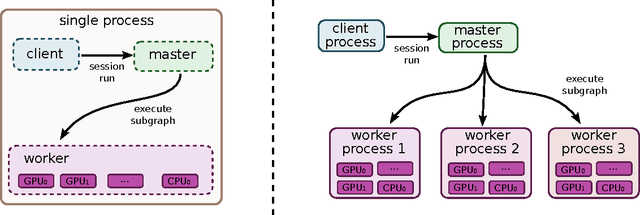
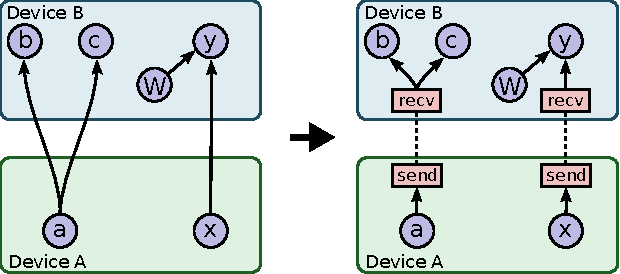
TensorFlow is an interface for expressing machine learning algorithms, and an implementation for executing such algorithms. A computation expressed using TensorFlow can be executed with little or no change on a wide variety of heterogeneous systems, ranging from mobile devices such as phones and tablets up to large-scale distributed systems of hundreds of machines and thousands of computational devices such as GPU cards. The system is flexible and can be used to express a wide variety of algorithms, including training and inference algorithms for deep neural network models, and it has been used for conducting research and for deploying machine learning systems into production across more than a dozen areas of computer science and other fields, including speech recognition, computer vision, robotics, information retrieval, natural language processing, geographic information extraction, and computational drug discovery. This paper describes the TensorFlow interface and an implementation of that interface that we have built at Google. The TensorFlow API and a reference implementation were released as an open-source package under the Apache 2.0 license in November, 2015 and are available at www.tensorflow.org.