 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEstimating Model Performance under Domain Shifts with Class-Specific Confidence Scores
Jul 20, 2022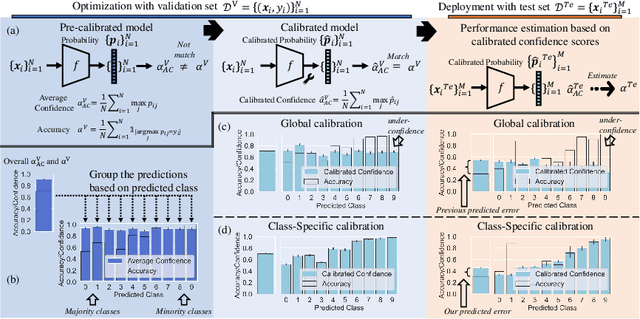
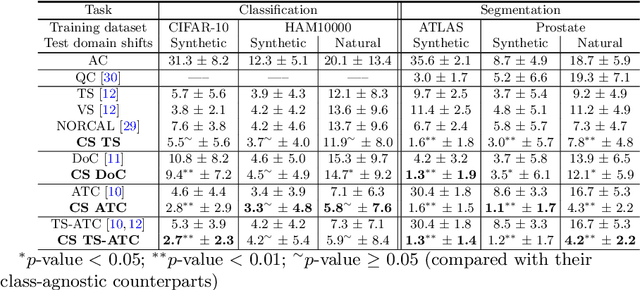
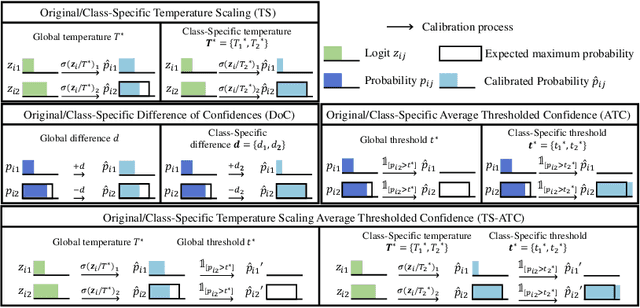
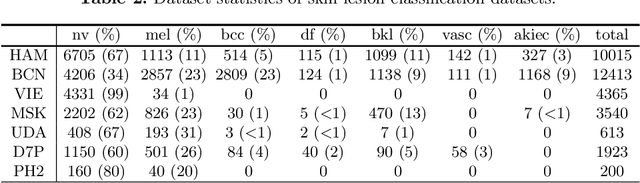
Machine learning models are typically deployed in a test setting that differs from the training setting, potentially leading to decreased model performance because of domain shift. If we could estimate the performance that a pre-trained model would achieve on data from a specific deployment setting, for example a certain clinic, we could judge whether the model could safely be deployed or if its performance degrades unacceptably on the specific data. Existing approaches estimate this based on the confidence of predictions made on unlabeled test data from the deployment's domain. We find existing methods struggle with data that present class imbalance, because the methods used to calibrate confidence do not account for bias induced by class imbalance, consequently failing to estimate class-wise accuracy. Here, we introduce class-wise calibration within the framework of performance estimation for imbalanced datasets. Specifically, we derive class-specific modifications of state-of-the-art confidence-based model evaluation methods including temperature scaling (TS), difference of confidences (DoC), and average thresholded confidence (ATC). We also extend the methods to estimate Dice similarity coefficient (DSC) in image segmentation. We conduct experiments on four tasks and find the proposed modifications consistently improve the estimation accuracy for imbalanced datasets. Our methods improve accuracy estimation by 18\% in classification under natural domain shifts, and double the estimation accuracy on segmentation tasks, when compared with prior methods.
Vector Quantisation for Robust Segmentation
Jul 05, 2022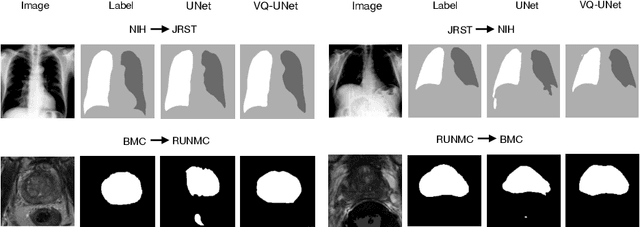
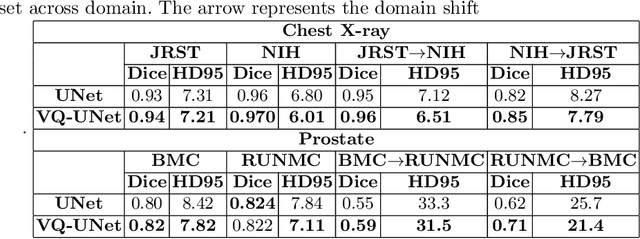


The reliability of segmentation models in the medical domain depends on the model's robustness to perturbations in the input space. Robustness is a particular challenge in medical imaging exhibiting various sources of image noise, corruptions, and domain shifts. Obtaining robustness is often attempted via simulating heterogeneous environments, either heuristically in the form of data augmentation or by learning to generate specific perturbations in an adversarial manner. We propose and justify that learning a discrete representation in a low dimensional embedding space improves robustness of a segmentation model. This is achieved with a dictionary learning method called vector quantisation. We use a set of experiments designed to analyse robustness in both the latent and output space under domain shift and noise perturbations in the input space. We adapt the popular UNet architecture, inserting a quantisation block in the bottleneck. We demonstrate improved segmentation accuracy and better robustness on three segmentation tasks. Code is available at \url{https://github.com/AinkaranSanthi/Vector-Quantisation-for-Robust-Segmentation}
GLANCE: Global to Local Architecture-Neutral Concept-based Explanations
Jul 05, 2022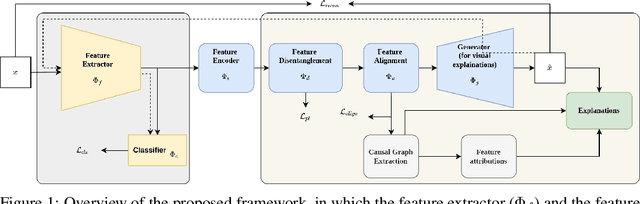

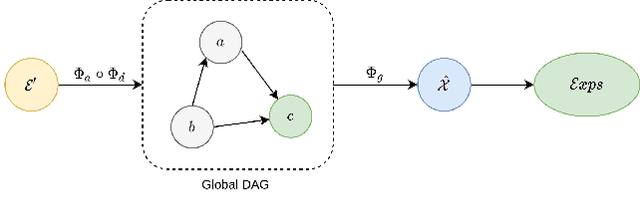
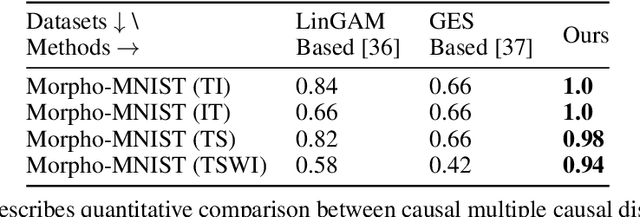
Most of the current explainability techniques focus on capturing the importance of features in input space. However, given the complexity of models and data-generating processes, the resulting explanations are far from being `complete', in that they lack an indication of feature interactions and visualization of their `effect'. In this work, we propose a novel twin-surrogate explainability framework to explain the decisions made by any CNN-based image classifier (irrespective of the architecture). For this, we first disentangle latent features from the classifier, followed by aligning these features to observed/human-defined `context' features. These aligned features form semantically meaningful concepts that are used for extracting a causal graph depicting the `perceived' data-generating process, describing the inter- and intra-feature interactions between unobserved latent features and observed `context' features. This causal graph serves as a global model from which local explanations of different forms can be extracted. Specifically, we provide a generator to visualize the `effect' of interactions among features in latent space and draw feature importance therefrom as local explanations. Our framework utilizes adversarial knowledge distillation to faithfully learn a representation from the classifiers' latent space and use it for extracting visual explanations. We use the styleGAN-v2 architecture with an additional regularization term to enforce disentanglement and alignment. We demonstrate and evaluate explanations obtained with our framework on Morpho-MNIST and on the FFHQ human faces dataset. Our framework is available at \url{https://github.com/koriavinash1/GLANCE-Explanations}.
Hierarchical Symbolic Reasoning in Hyperbolic Space for Deep Discriminative Models
Jul 05, 2022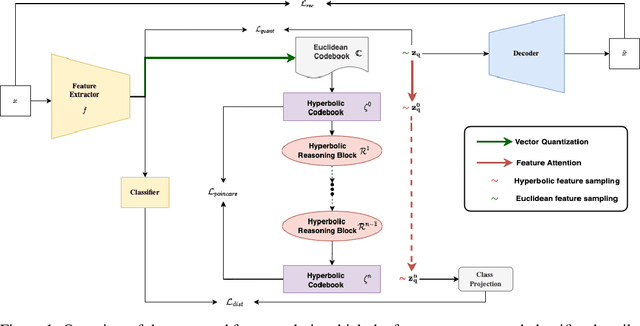
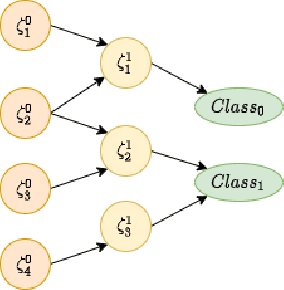
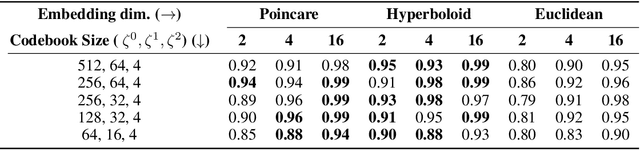
Explanations for \emph{black-box} models help us understand model decisions as well as provide information on model biases and inconsistencies. Most of the current explainability techniques provide a single level of explanation, often in terms of feature importance scores or feature attention maps in input space. Our focus is on explaining deep discriminative models at \emph{multiple levels of abstraction}, from fine-grained to fully abstract explanations. We achieve this by using the natural properties of \emph{hyperbolic geometry} to more efficiently model a hierarchy of symbolic features and generate \emph{hierarchical symbolic rules} as part of our explanations. Specifically, for any given deep discriminative model, we distill the underpinning knowledge by discretisation of the continuous latent space using vector quantisation to form symbols, followed by a \emph{hyperbolic reasoning block} to induce an \emph{abstraction tree}. We traverse the tree to extract explanations in terms of symbolic rules and its corresponding visual semantics. We demonstrate the effectiveness of our method on the MNIST and AFHQ high-resolution animal faces dataset. Our framework is available at \url{https://github.com/koriavinash1/SymbolicInterpretability}.
Distributional Gaussian Processes Layers for Out-of-Distribution Detection
Jun 27, 2022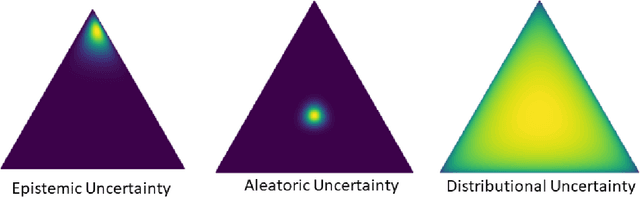
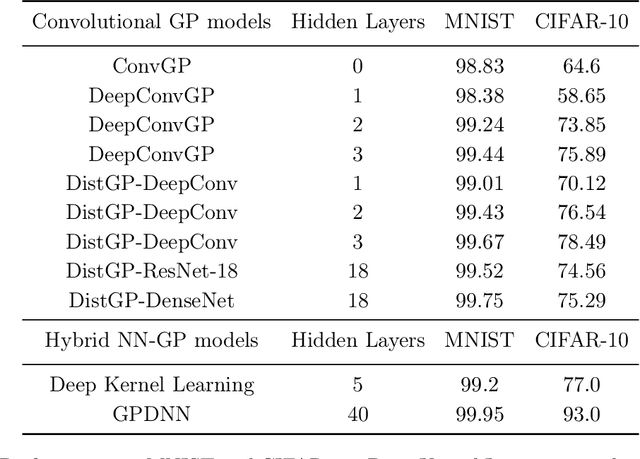
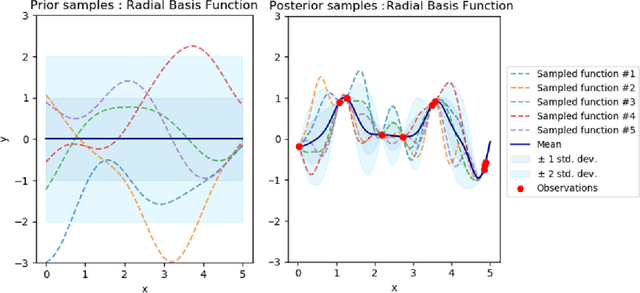
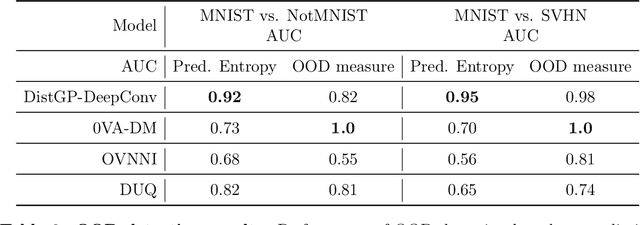
Machine learning models deployed on medical imaging tasks must be equipped with out-of-distribution detection capabilities in order to avoid erroneous predictions. It is unsure whether out-of-distribution detection models reliant on deep neural networks are suitable for detecting domain shifts in medical imaging. Gaussian Processes can reliably separate in-distribution data points from out-of-distribution data points via their mathematical construction. Hence, we propose a parameter efficient Bayesian layer for hierarchical convolutional Gaussian Processes that incorporates Gaussian Processes operating in Wasserstein-2 space to reliably propagate uncertainty. This directly replaces convolving Gaussian Processes with a distance-preserving affine operator on distributions. Our experiments on brain tissue-segmentation show that the resulting architecture approaches the performance of well-established deterministic segmentation algorithms (U-Net), which has not been achieved with previous hierarchical Gaussian Processes. Moreover, by applying the same segmentation model to out-of-distribution data (i.e., images with pathology such as brain tumors), we show that our uncertainty estimates result in out-of-distribution detection that outperforms the capabilities of previous Bayesian networks and reconstruction-based approaches that learn normative distributions. To facilitate future work our code is publicly available.
Metrics reloaded: Pitfalls and recommendations for image analysis validation
Jun 03, 2022



The field of automatic biomedical image analysis crucially depends on robust and meaningful performance metrics for algorithm validation. Current metric usage, however, is often ill-informed and does not reflect the underlying domain interest. Here, we present a comprehensive framework that guides researchers towards choosing performance metrics in a problem-aware manner. Specifically, we focus on biomedical image analysis problems that can be interpreted as a classification task at image, object or pixel level. The framework first compiles domain interest-, target structure-, data set- and algorithm output-related properties of a given problem into a problem fingerprint, while also mapping it to the appropriate problem category, namely image-level classification, semantic segmentation, instance segmentation, or object detection. It then guides users through the process of selecting and applying a set of appropriate validation metrics while making them aware of potential pitfalls related to individual choices. In this paper, we describe the current status of the Metrics Reloaded recommendation framework, with the goal of obtaining constructive feedback from the image analysis community. The current version has been developed within an international consortium of more than 60 image analysis experts and will be made openly available as a user-friendly toolkit after community-driven optimization.
Failure Detection in Medical Image Classification: A Reality Check and Benchmarking Testbed
May 27, 2022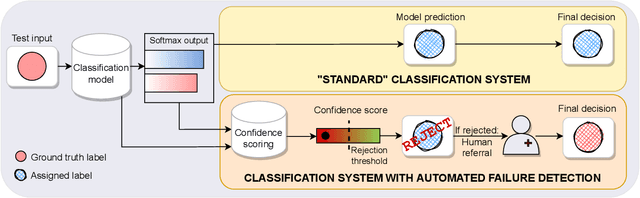
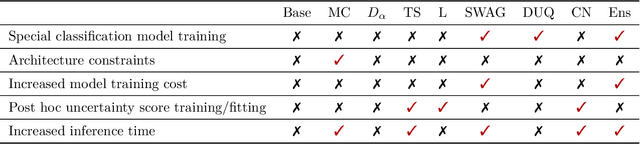
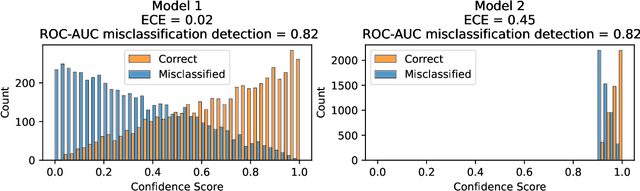
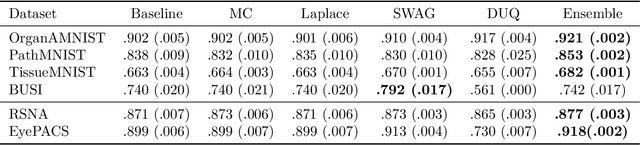
Failure detection in automated image classification is a critical safeguard for clinical deployment. Detected failure cases can be referred to human assessment, ensuring patient safety in computer-aided clinical decision making. Despite its paramount importance, there is insufficient evidence about the ability of state-of-the-art confidence scoring methods to detect test-time failures of classification models in the context of medical imaging. This paper provides a reality check, establishing the performance of in-domain misclassification detection methods, benchmarking 9 confidence scores on 6 medical imaging datasets with different imaging modalities, in multiclass and binary classification settings. Our experiments show that the problem of failure detection is far from being solved. We found that none of the benchmarked advanced methods proposed in the computer vision and machine learning literature can consistently outperform a simple softmax baseline. Our developed testbed facilitates future work in this important area.
Structured Uncertainty in the Observation Space of Variational Autoencoders
May 25, 2022
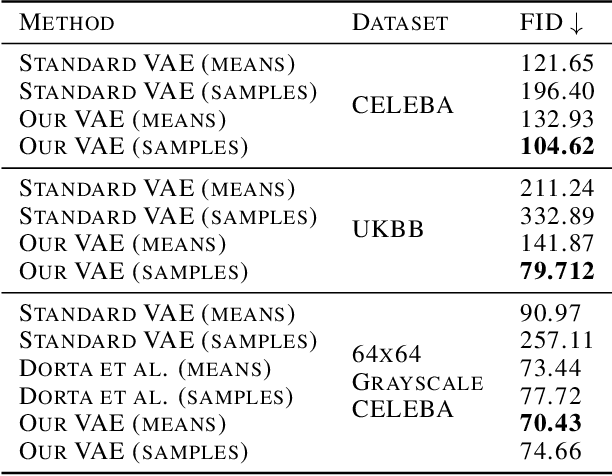
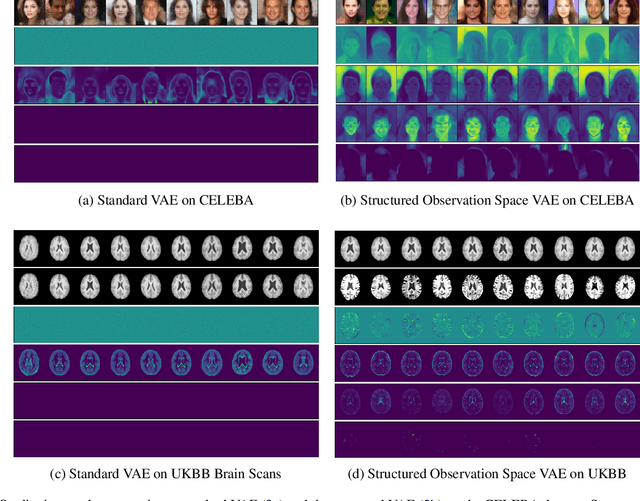

Variational autoencoders (VAEs) are a popular class of deep generative models with many variants and a wide range of applications. Improvements upon the standard VAE mostly focus on the modelling of the posterior distribution over the latent space and the properties of the neural network decoder. In contrast, improving the model for the observational distribution is rarely considered and typically defaults to a pixel-wise independent categorical or normal distribution. In image synthesis, sampling from such distributions produces spatially-incoherent results with uncorrelated pixel noise, resulting in only the sample mean being somewhat useful as an output prediction. In this paper, we aim to stay true to VAE theory by improving the samples from the observational distribution. We propose an alternative model for the observation space, encoding spatial dependencies via a low-rank parameterisation. We demonstrate that this new observational distribution has the ability to capture relevant covariance between pixels, resulting in spatially-coherent samples. In contrast to pixel-wise independent distributions, our samples seem to contain semantically meaningful variations from the mean allowing the prediction of multiple plausible outputs with a single forward pass.
Federated Learning Enables Big Data for Rare Cancer Boundary Detection
Apr 25, 2022Although machine learning (ML) has shown promise in numerous domains, there are concerns about generalizability to out-of-sample data. This is currently addressed by centrally sharing ample, and importantly diverse, data from multiple sites. However, such centralization is challenging to scale (or even not feasible) due to various limitations. Federated ML (FL) provides an alternative to train accurate and generalizable ML models, by only sharing numerical model updates. Here we present findings from the largest FL study to-date, involving data from 71 healthcare institutions across 6 continents, to generate an automatic tumor boundary detector for the rare disease of glioblastoma, utilizing the largest dataset of such patients ever used in the literature (25,256 MRI scans from 6,314 patients). We demonstrate a 33% improvement over a publicly trained model to delineate the surgically targetable tumor, and 23% improvement over the tumor's entire extent. We anticipate our study to: 1) enable more studies in healthcare informed by large and diverse data, ensuring meaningful results for rare diseases and underrepresented populations, 2) facilitate further quantitative analyses for glioblastoma via performance optimization of our consensus model for eventual public release, and 3) demonstrate the effectiveness of FL at such scale and task complexity as a paradigm shift for multi-site collaborations, alleviating the need for data sharing.
Investigating underdiagnosis of AI algorithms in the presence of multiple sources of dataset bias
Jan 19, 2022Deep learning models have shown great potential for image-based diagnosis assisting clinical decision making. At the same time, an increasing number of reports raise concerns about the potential risk that machine learning could amplify existing health disparities due to human biases that are embedded in the training data. It is of great importance to carefully investigate the extent to which biases may be reproduced or even amplified if we wish to build fair artificial intelligence systems. Seyyed-Kalantari et al. advance this conversation by analysing the performance of a disease classifier across population subgroups. They raise performance disparities related to underdiagnosis as a point of concern; we identify areas from this analysis which we believe deserve additional attention. Specifically, we wish to highlight some theoretical and practical difficulties associated with assessing model fairness through testing on data drawn from the same biased distribution as the training data, especially when the sources and amount of biases are unknown.