 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDuckSegmentation: A segmentation model based on the AnYue Hemp Duck Dataset
Mar 27, 2025



The modernization of smart farming is a way to improve agricultural production efficiency, and improve the agricultural production environment. Although many large models have achieved high accuracy in the task of object recognition and segmentation, they cannot really be put into use in the farming industry due to their own poor interpretability and limitations in computational volume. In this paper, we built AnYue Shelduck Dateset, which contains a total of 1951 Shelduck datasets, and performed target detection and segmentation annotation with the help of professional annotators. Based on AnYue ShelduckDateset, this paper describes DuckProcessing, an efficient and powerful module for duck identification based on real shelduckfarms. First of all, using the YOLOv8 module designed to divide the mahjong between them, Precision reached 98.10%, Recall reached 96.53% and F1 score reached 0.95 on the test set. Again using the DuckSegmentation segmentation model, DuckSegmentation reached 96.43% mIoU. Finally, the excellent DuckSegmentation was used as the teacher model, and through knowledge distillation, Deeplabv3 r50 was used as the student model, and the final student model achieved 94.49% mIoU on the test set. The method provides a new way of thinking in practical sisal duck smart farming.
Adaptive Learning-based Model Predictive Control Strategy for Drift Vehicles
Feb 07, 2025



Drift vehicle control offers valuable insights to support safe autonomous driving in extreme conditions, which hinges on tracking a particular path while maintaining the vehicle states near the drift equilibrium points (DEP). However, conventional tracking methods are not adaptable for drift vehicles due to their opposite steering angle and yaw rate. In this paper, we propose an adaptive path tracking (APT) control method to dynamically adjust drift states to follow the reference path, improving the commonly utilized predictive path tracking methods with released computation burden. Furthermore, existing control strategies necessitate a precise system model to calculate the DEP, which can be more intractable due to the highly nonlinear drift dynamics and sensitive vehicle parameters. To tackle this problem, an adaptive learning-based model predictive control (ALMPC) strategy is proposed based on the APT method, where an upper-level Bayesian optimization is employed to learn the DEP and APT control law to instruct a lower-level MPC drift controller. This hierarchical system architecture can also resolve the inherent control conflict between path tracking and drifting by separating these objectives into different layers. The ALMPC strategy is verified on the Matlab-Carsim platform, and simulation results demonstrate its effectiveness in controlling the drift vehicle to follow a clothoid-based reference path even with the misidentified road friction parameter.
A Data-Driven Aggressive Autonomous Racing Framework Utilizing Local Trajectory Planning with Velocity Prediction
Oct 15, 2024The development of autonomous driving has boosted the research on autonomous racing. However, existing local trajectory planning methods have difficulty planning trajectories with optimal velocity profiles at racetracks with sharp corners, thus weakening the performance of autonomous racing. To address this problem, we propose a local trajectory planning method that integrates Velocity Prediction based on Model Predictive Contour Control (VPMPCC). The optimal parameters of VPMPCC are learned through Bayesian Optimization (BO) based on a proposed novel Objective Function adapted to Racing (OFR). Specifically, VPMPCC achieves velocity prediction by encoding the racetrack as a reference velocity profile and incorporating it into the optimization problem. This method optimizes the velocity profile of local trajectories, especially at corners with significant curvature. The proposed OFR balances racing performance with vehicle safety, ensuring safe and efficient BO training. In the simulation, the number of training iterations for OFR-based BO is reduced by 42.86% compared to the state-of-the-art method. The optimal simulation-trained parameters are then applied to a real-world F1TENTH vehicle without retraining. During prolonged racing on a custom-built racetrack featuring significant sharp corners, the mean velocity of VPMPCC reaches 93.18% of the vehicle's handling limits. The released code is available at https://github.com/zhouhengli/VPMPCC.
Exploring Parity Challenges in Reinforcement Learning through Curriculum Learning with Noisy Labels
Dec 08, 2023

This paper delves into applying reinforcement learning (RL) in strategy games, particularly those characterized by parity challenges, as seen in specific positions of Go and Chess and a broader range of impartial games. We propose a simulated learning process, structured within a curriculum learning framework and augmented with noisy labels, to mirror the intricacies of self-play learning scenarios. This approach thoroughly analyses how neural networks (NNs) adapt and evolve from elementary to increasingly complex game positions. Our empirical research indicates that even minimal label noise can significantly impede NNs' ability to discern effective strategies, a difficulty that intensifies with the growing complexity of the game positions. These findings underscore the urgent need for advanced methodologies in RL training, specifically tailored to counter the obstacles imposed by noisy evaluations. The development of such methodologies is crucial not only for enhancing NN proficiency in strategy games with significant parity elements but also for broadening the resilience and efficiency of RL systems across diverse and complex environments.
Impartial Games: A Challenge for Reinforcement Learning
May 25, 2022

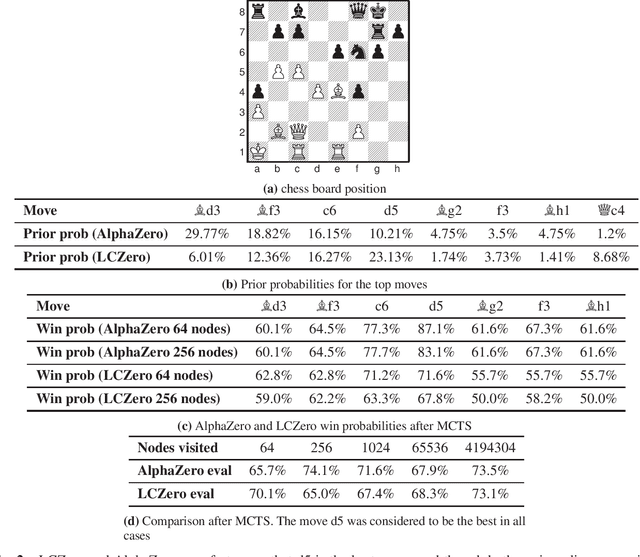

The AlphaZero algorithm and its successor MuZero have revolutionised several competitive strategy games, including chess, Go, and shogi and video games like Atari, by learning to play these games better than any human and any specialised computer program. Aside from knowing the rules, AlphaZero had no prior knowledge of each game. This dramatically advanced progress on a long-standing AI challenge to create programs that can learn for themselves from first principles. Theoretically, there are well-known limits to the power of deep learning for strategy games like chess, Go, and shogi, as they are known to be NEXPTIME hard. Some papers have argued that the AlphaZero methodology has limitations and is unsuitable for general AI. However, none of these works has suggested any specific limits for any particular game. In this paper, we provide more powerful bottlenecks than previously suggested. We present the first concrete example of a game - namely the (children) game of nim - and other impartial games that seem to be a stumbling block for AlphaZero and similar reinforcement learning algorithms. We show experimentally that the bottlenecks apply to both the policy and value networks. Since solving nim can be done in linear time using logarithmic space i.e. has very low-complexity, our experimental results supersede known theoretical limits based on many games' PSPACE (and NEXPTIME) completeness. We show that nim can be learned on small boards, but when the board size increases, AlphaZero style algorithms rapidly fail to improve. We quantify the difficulties for various setups, parameter settings and computational resources. Our results might help expand the AlphaZero self-play paradigm by allowing it to use meta-actions during training and/or actual game play like applying abstract transformations, or reading and writing to an external memory.
A Hybrid Natural Language Generation System Integrating Rules and Deep Learning Algorithms
Jun 17, 2020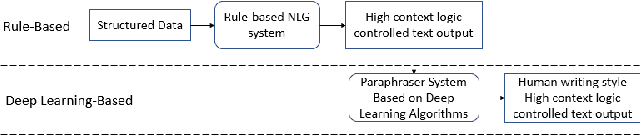
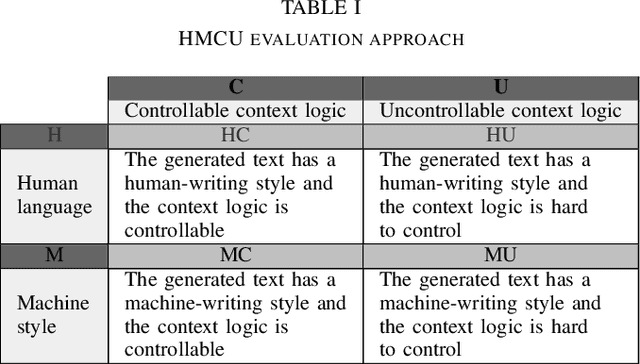
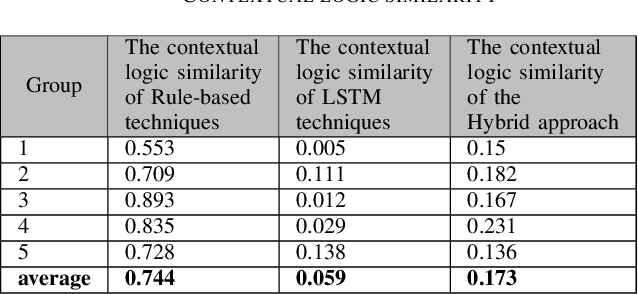
This paper proposes an enhanced natural language generation system combining the merits of both rule-based approaches and modern deep learning algorithms, boosting its performance to the extent where the generated textual content is capable of exhibiting agile human-writing styles and the content logic of which is highly controllable. We also come up with a novel approach called HMCU to measure the performance of the natural language processing comprehensively and precisely.