 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Learning Convolutions from Scratch
Jul 27, 2020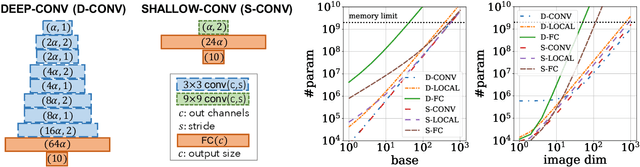
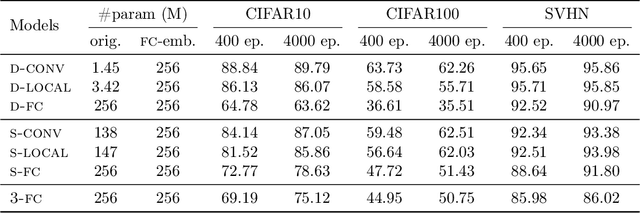
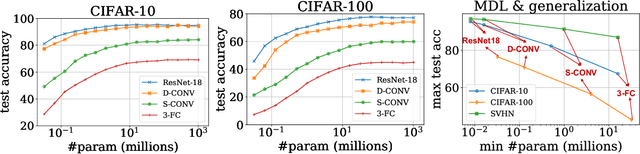
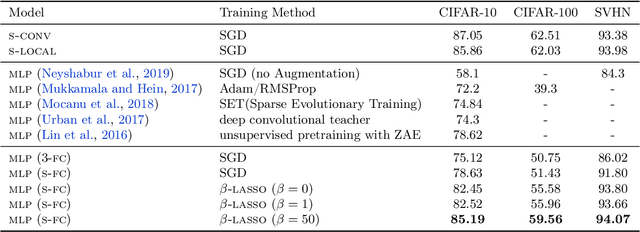
Convolution is one of the most essential components of architectures used in computer vision. As machine learning moves towards reducing the expert bias and learning it from data, a natural next step seems to be learning convolution-like structures from scratch. This, however, has proven elusive. For example, current state-of-the-art architecture search algorithms use convolution as one of the existing modules rather than learning it from data. In an attempt to understand the inductive bias that gives rise to convolutions, we investigate minimum description length as a guiding principle and show that in some settings, it can indeed be indicative of the performance of architectures. To find architectures with small description length, we propose $\beta$-LASSO, a simple variant of LASSO algorithm that, when applied on fully-connected networks for image classification tasks, learns architectures with local connections and achieves state-of-the-art accuracies for training fully-connected nets on CIFAR-10 (85.19%), CIFAR-100 (59.56%) and SVHN (94.07%) bridging the gap between fully-connected and convolutional nets.
Observational Overfitting in Reinforcement Learning
Dec 28, 2019
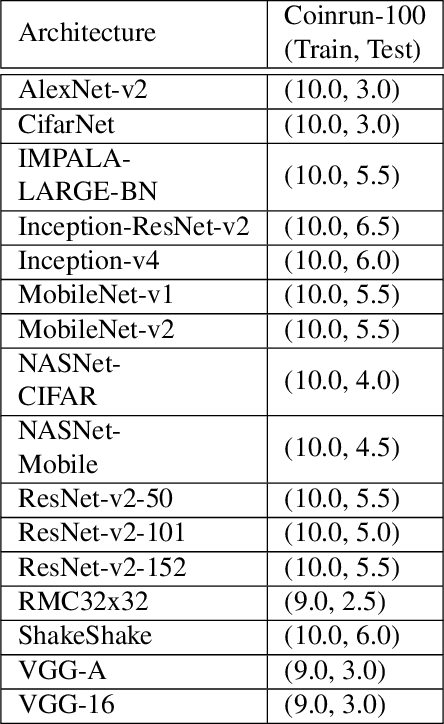
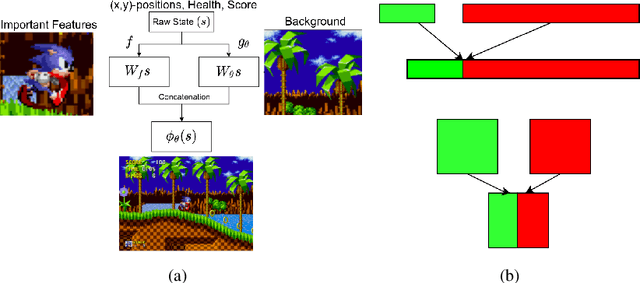

A major component of overfitting in model-free reinforcement learning (RL) involves the case where the agent may mistakenly correlate reward with certain spurious features from the observations generated by the Markov Decision Process (MDP). We provide a general framework for analyzing this scenario, which we use to design multiple synthetic benchmarks from only modifying the observation space of an MDP. When an agent overfits to different observation spaces even if the underlying MDP dynamics is fixed, we term this observational overfitting. Our experiments expose intriguing properties especially with regards to implicit regularization, and also corroborate results from previous works in RL generalization and supervised learning (SL).
The intriguing role of module criticality in the generalization of deep networks
Dec 04, 2019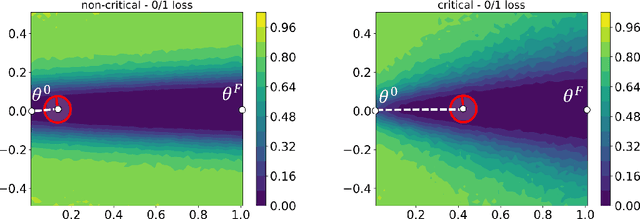
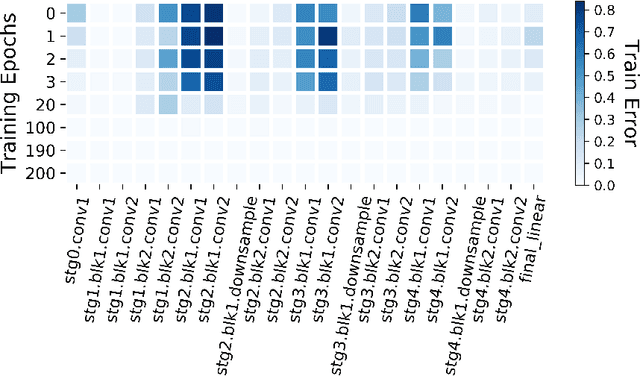
We study the phenomenon that some modules of deep neural networks (DNNs) are more critical than others. Meaning that rewinding their parameter values back to initialization, while keeping other modules fixed at the trained parameters, results in a large drop in the network's performance. Our analysis reveals interesting properties of the loss landscape which leads us to propose a complexity measure, called module criticality, based on the shape of the valleys that connects the initial and final values of the module parameters. We formulate how generalization relates to the module criticality, and show that this measure is able to explain the superior generalization performance of some architectures over others, whereas earlier measures fail to do so.
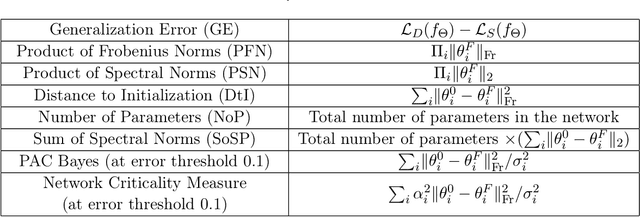
Fantastic Generalization Measures and Where to Find Them
Dec 04, 2019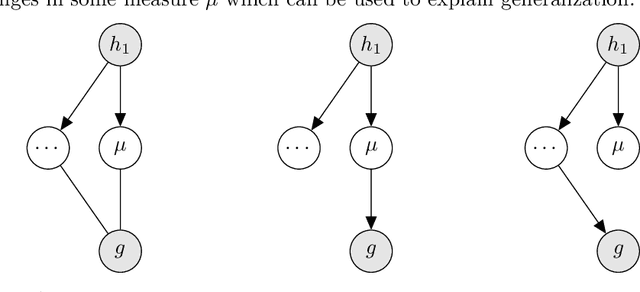
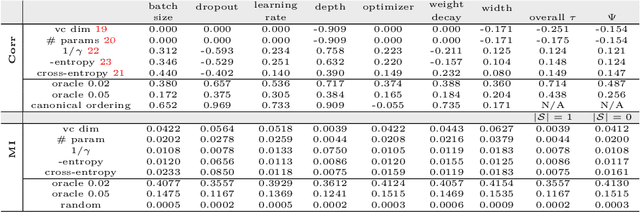
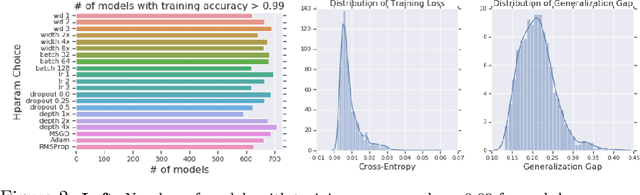
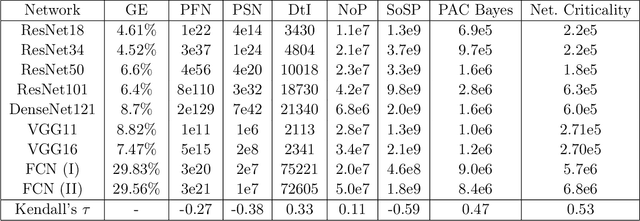
Generalization of deep networks has been of great interest in recent years, resulting in a number of theoretically and empirically motivated complexity measures. However, most papers proposing such measures study only a small set of models, leaving open the question of whether the conclusion drawn from those experiments would remain valid in other settings. We present the first large scale study of generalization in deep networks. We investigate more then 40 complexity measures taken from both theoretical bounds and empirical studies. We train over 10,000 convolutional networks by systematically varying commonly used hyperparameters. Hoping to uncover potentially causal relationships between each measure and generalization, we analyze carefully controlled experiments and show surprising failures of some measures as well as promising measures for further research.
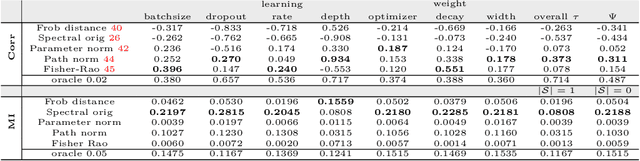
Stronger generalization bounds for deep nets via a compression approach
Nov 05, 2018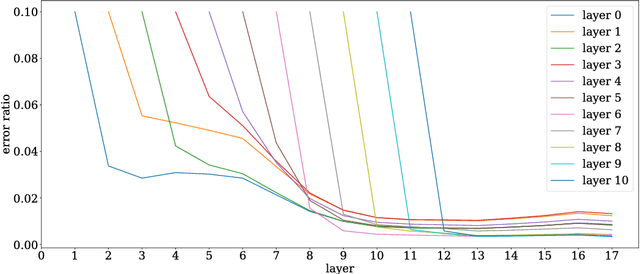
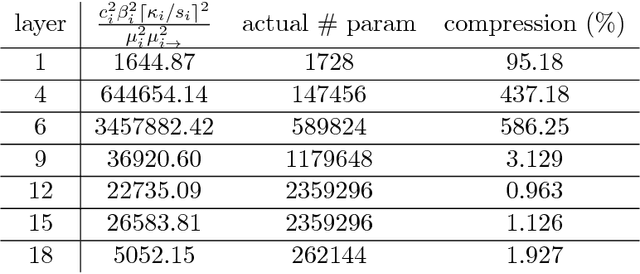
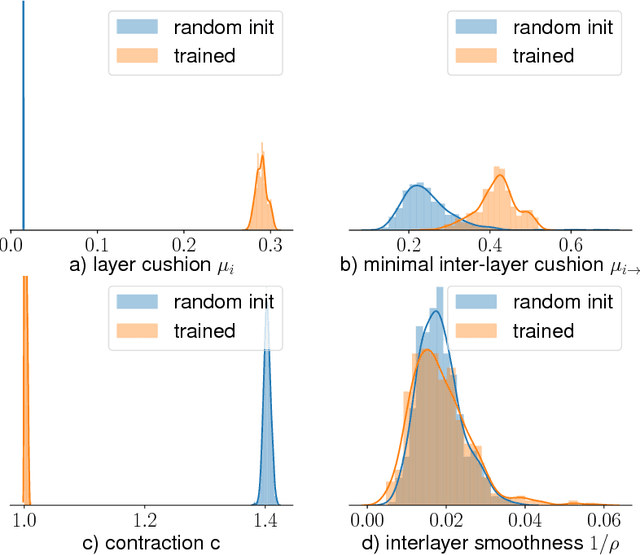
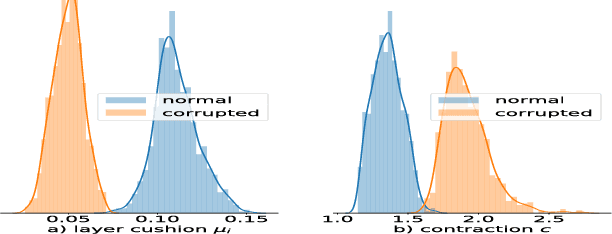
Deep nets generalize well despite having more parameters than the number of training samples. Recent works try to give an explanation using PAC-Bayes and Margin-based analyses, but do not as yet result in sample complexity bounds better than naive parameter counting. The current paper shows generalization bounds that're orders of magnitude better in practice. These rely upon new succinct reparametrizations of the trained net --- a compression that is explicit and efficient. These yield generalization bounds via a simple compression-based framework introduced here. Our results also provide some theoretical justification for widespread empirical success in compressing deep nets. Analysis of correctness of our compression relies upon some newly identified \textquotedblleft noise stability\textquotedblright properties of trained deep nets, which are also experimentally verified. The study of these properties and resulting generalization bounds are also extended to convolutional nets, which had eluded earlier attempts on proving generalization.
Stabilizing GAN Training with Multiple Random Projections
Jun 23, 2018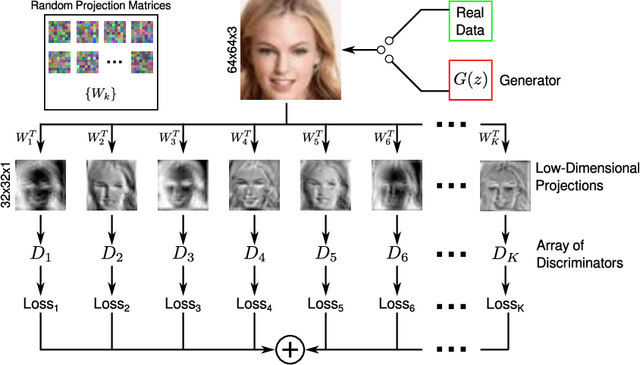
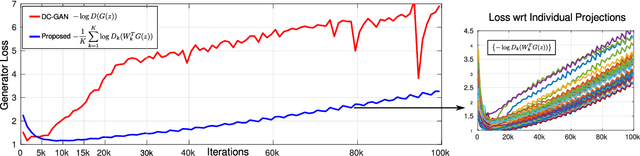


Training generative adversarial networks is unstable in high-dimensions as the true data distribution tends to be concentrated in a small fraction of the ambient space. The discriminator is then quickly able to classify nearly all generated samples as fake, leaving the generator without meaningful gradients and causing it to deteriorate after a point in training. In this work, we propose training a single generator simultaneously against an array of discriminators, each of which looks at a different random low-dimensional projection of the data. Individual discriminators, now provided with restricted views of the input, are unable to reject generated samples perfectly and continue to provide meaningful gradients to the generator throughout training. Meanwhile, the generator learns to produce samples consistent with the full data distribution to satisfy all discriminators simultaneously. We demonstrate the practical utility of this approach experimentally, and show that it is able to produce image samples with higher quality than traditional training with a single discriminator.
Towards Understanding the Role of Over-Parametrization in Generalization of Neural Networks
May 30, 2018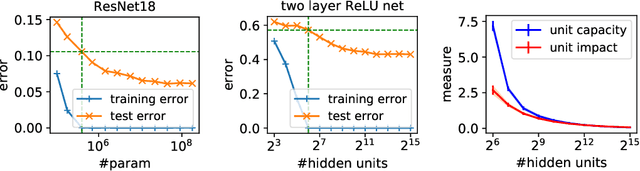
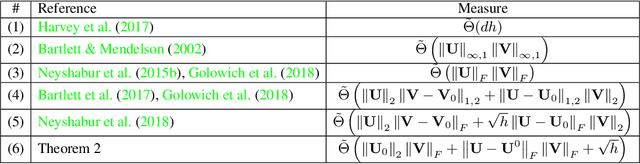
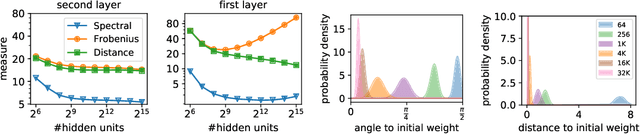

Despite existing work on ensuring generalization of neural networks in terms of scale sensitive complexity measures, such as norms, margin and sharpness, these complexity measures do not offer an explanation of why neural networks generalize better with over-parametrization. In this work we suggest a novel complexity measure based on unit-wise capacities resulting in a tighter generalization bound for two layer ReLU networks. Our capacity bound correlates with the behavior of test error with increasing network sizes, and could potentially explain the improvement in generalization with over-parametrization. We further present a matching lower bound for the Rademacher complexity that improves over previous capacity lower bounds for neural networks.
A PAC-Bayesian Approach to Spectrally-Normalized Margin Bounds for Neural Networks
Feb 23, 2018We present a generalization bound for feedforward neural networks in terms of the product of the spectral norm of the layers and the Frobenius norm of the weights. The generalization bound is derived using a PAC-Bayes analysis.
Implicit Regularization in Deep Learning
Sep 08, 2017
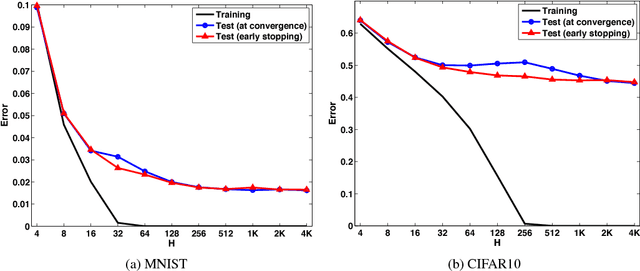
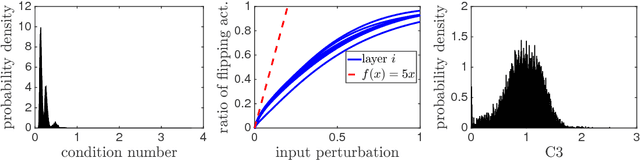
In an attempt to better understand generalization in deep learning, we study several possible explanations. We show that implicit regularization induced by the optimization method is playing a key role in generalization and success of deep learning models. Motivated by this view, we study how different complexity measures can ensure generalization and explain how optimization algorithms can implicitly regularize complexity measures. We empirically investigate the ability of these measures to explain different observed phenomena in deep learning. We further study the invariances in neural networks, suggest complexity measures and optimization algorithms that have similar invariances to those in neural networks and evaluate them on a number of learning tasks.
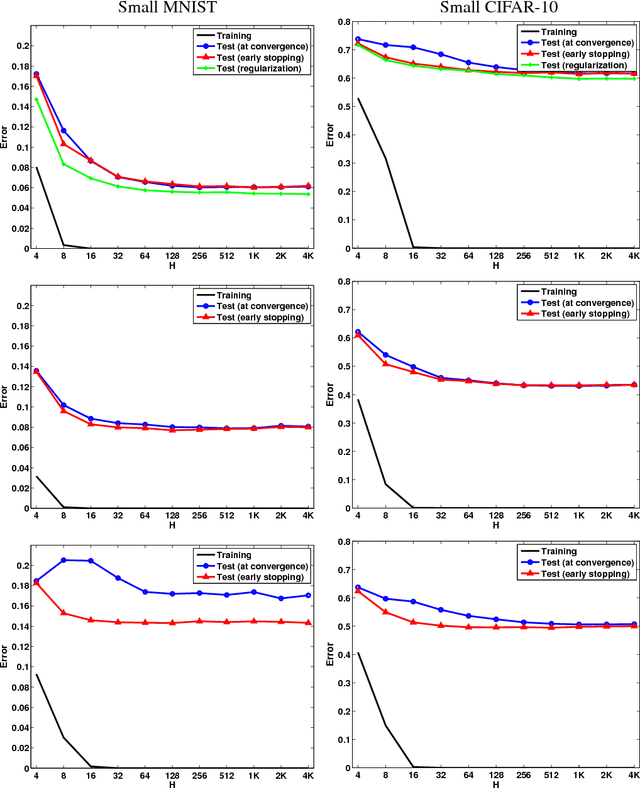
Exploring Generalization in Deep Learning
Jul 06, 2017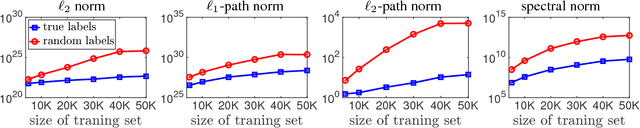
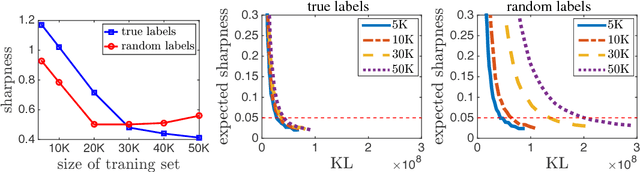
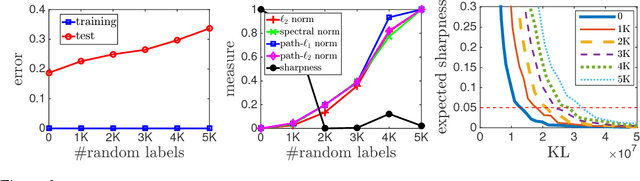
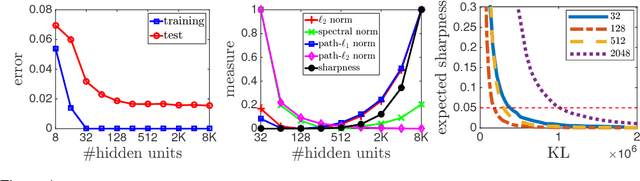
With a goal of understanding what drives generalization in deep networks, we consider several recently suggested explanations, including norm-based control, sharpness and robustness. We study how these measures can ensure generalization, highlighting the importance of scale normalization, and making a connection between sharpness and PAC-Bayes theory. We then investigate how well the measures explain different observed phenomena.