 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCovariate Distribution Aware Meta-learning
Jul 08, 2020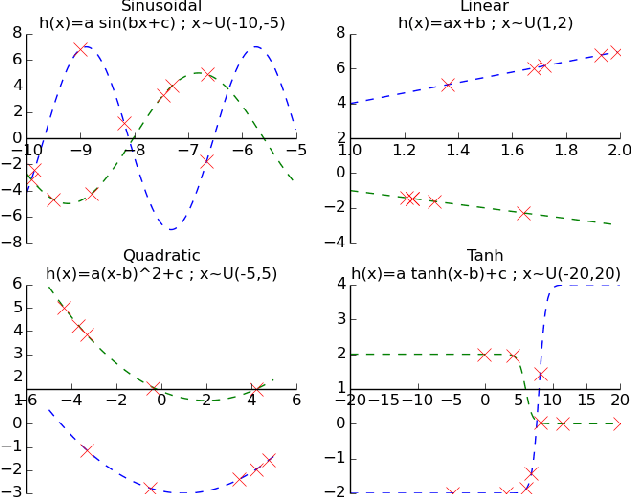
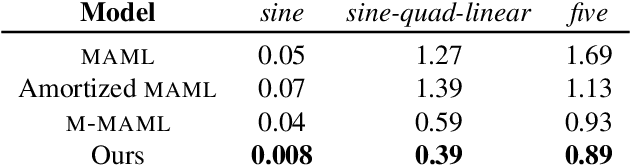
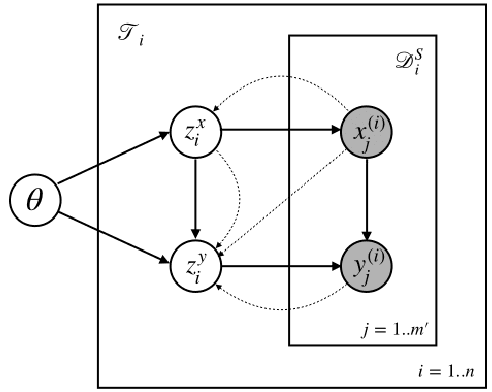
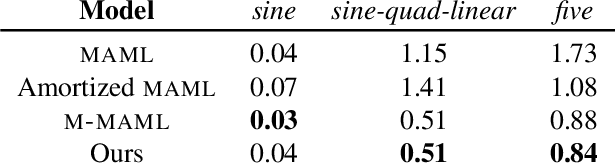
Meta-learning has proven to be successful at few-shot learning across the regression, classification and reinforcement learning paradigms. Recent approaches have adopted Bayesian interpretations to improve gradient based meta-learners by quantifying the uncertainty of the post-adaptation estimates. Most of these works almost completely ignore the latent relationship between the covariate distribution (p(x)) of a task and the corresponding conditional distribution p(y|x). In this paper, we identify the need to explicitly model the meta-distribution over the task covariates in a hierarchical Bayesian framework. We begin by introducing a graphical model that explicitly leverages very few samples drawn from p(x) to better infer the posterior over the optimal parameters of the conditional distribution (p(y|x)) for each task. Based on this model we provide an inference strategy and a corresponding meta-algorithm that explicitly accounts for the meta-distribution over task covariates. Finally, we demonstrate the significant gains of our proposed algorithm on a synthetic regression dataset.
Politeness Transfer: A Tag and Generate Approach
May 01, 2020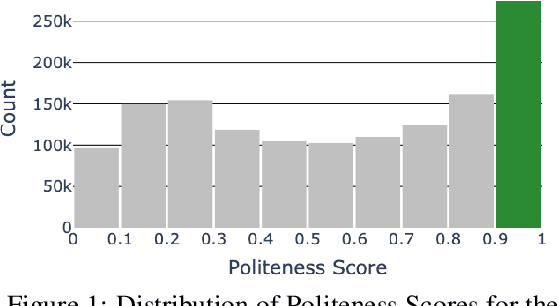
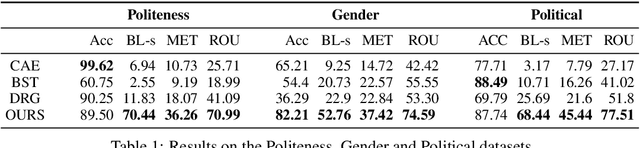
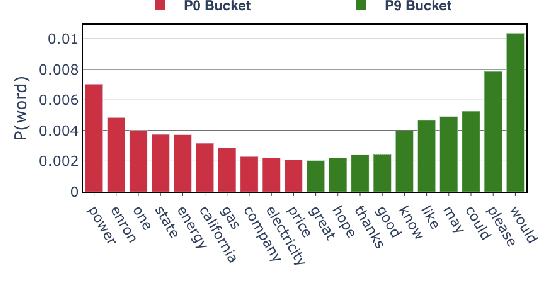

This paper introduces a new task of politeness transfer which involves converting non-polite sentences to polite sentences while preserving the meaning. We also provide a dataset of more than 1.39 instances automatically labeled for politeness to encourage benchmark evaluations on this new task. We design a tag and generate pipeline that identifies stylistic attributes and subsequently generates a sentence in the target style while preserving most of the source content. For politeness as well as five other transfer tasks, our model outperforms the state-of-the-art methods on automatic metrics for content preservation, with a comparable or better performance on style transfer accuracy. Additionally, our model surpasses existing methods on human evaluations for grammaticality, meaning preservation and transfer accuracy across all the six style transfer tasks. The data and code is located at https://github.com/tag-and-generate.
Robust Density Estimation under Besov IPM Losses
Apr 18, 2020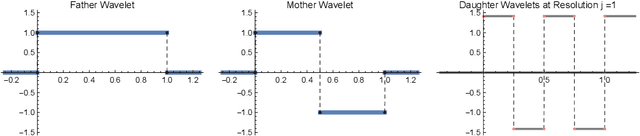
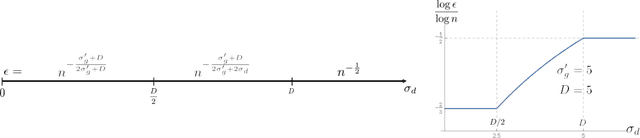
We study minimax convergence rates of nonparametric density estimation in the Huber contamination model, in which a proportion of the data comes from an unknown outlier distribution. We provide the first results for this problem under a large family of losses, called Besov integral probability metrics (IPMs), that includes $\mathcal{L}^p$, Wasserstein, Kolmogorov-Smirnov, and other common distances between probability distributions. Specifically, under a range of smoothness assumptions on the population and outlier distributions, we show that a re-scaled thresholding wavelet series estimator achieves minimax optimal convergence rates under a wide variety of losses. Finally, based on connections that have recently been shown between nonparametric density estimation under IPM losses and generative adversarial networks (GANs), we show that certain GAN architectures also achieve these minimax rates.
Adaptive Sampling Distributed Stochastic Variance Reduced Gradient for Heterogeneous Distributed Datasets
Feb 20, 2020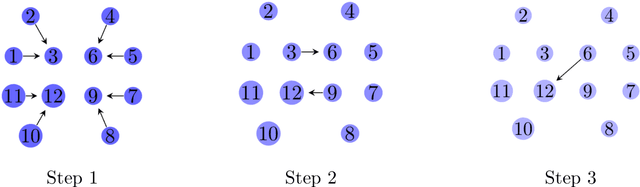
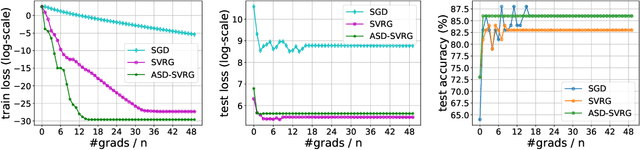
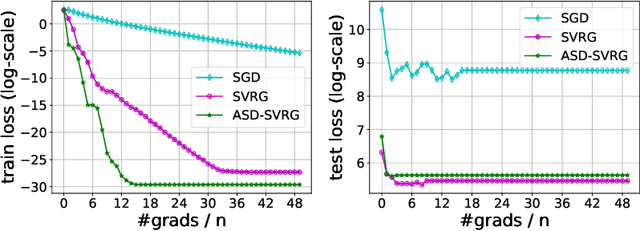
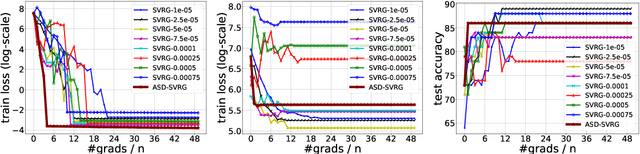
We study distributed optimization algorithms for minimizing the average of \emph{heterogeneous} functions distributed across several machines with a focus on communication efficiency. In such settings, naively using the classical stochastic gradient descent (SGD) or its variants (e.g., SVRG) with a uniform sampling of machines typically yields poor performance. It often leads to the dependence of convergence rate on maximum Lipschitz constant of gradients across the devices. In this paper, we propose a novel \emph{adaptive} sampling of machines specially catered to these settings. Our method relies on an adaptive estimate of local Lipschitz constants base on the information of past gradients. We show that the new way improves the dependence of convergence rate from maximum Lipschitz constant to \emph{average} Lipschitz constant across machines, thereby, significantly accelerating the convergence. Our experiments demonstrate that our method indeed speeds up the convergence of the standard SVRG algorithm in heterogeneous environments.
Optimal Adaptive Matrix Completion
Feb 06, 2020We study the problem of exact completion for $m \times n$ sized matrix of rank r with the adaptive sampling method. We introduce a relation of the exact completion problem with the sparsest vector of column and row spaces (which we call sparsity-number here). Using this relation, we propose matrix completion algorithms that exactly recovers the target matrix. These algorithms are superior to previous works in two important ways. First, our algorithms exactly recover $\mu_0$-coherent column space matrices by probability at least $1-\epsilon$ using much smaller observations complexity than - $\mathcal{O}(\mu_0 rn \mathrm{log}\frac{r}{\epsilon})$ - the state of art. Specifically, many of the previous adaptive sampling methods require to observe the entire matrix when the column space is highly coherent. However, we show that our method is still able to recover this type of matrices by observing a small fraction of entries under many scenarios. Second, we propose an exact completion algorithm, which requires minimal pre-information as either row or column space is not being highly coherent. We provide an extension of these algorithms that is robust to sparse random noise. Besides, we propose an additional low-rank estimation algorithm that is robust to any small noise by adaptively studying the shape of column space. At the end of the paper, we provide experimental results that illustrate the strength of the algorithms proposed here.
Unsupervised Program Synthesis for Images using Tree-Structured LSTM
Jan 27, 2020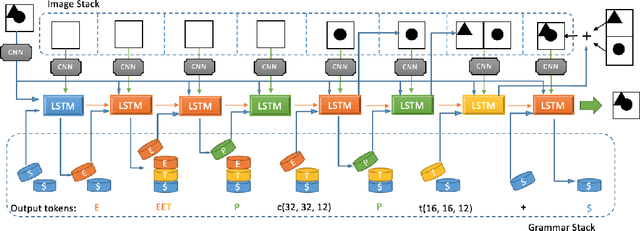
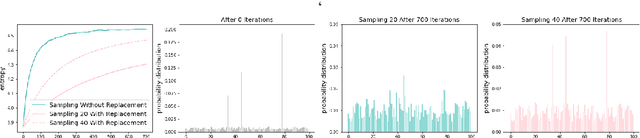

Program synthesis has recently emerged as a promising approach to the image parsing task. However, most prior works have relied on supervised learning methods, which require ground truth programs for each training image. We present an unsupervised learning algorithm that can parse constructive solid geometry (CSG) images into context-free grammar with a non-differentiable renderer. We propose a grammar-encoded tree LSTM to effectively constrain our search space by leveraging the structure of the context-free grammar while handling the non-differentiable renderer via REINFORCE and encouraging the exploration by regularizing the objective with an entropy term. Instead of using simple Monte Carlo sampling, we propose a lower-variance entropy estimator with sampling without replacement for effective exploration. We demonstrate the effectiveness of the proposed algorithm on a synthetic 2D CSG dataset, which outperforms baseline models by a large margin.
Learned Interpolation for 3D Generation
Jan 24, 2020

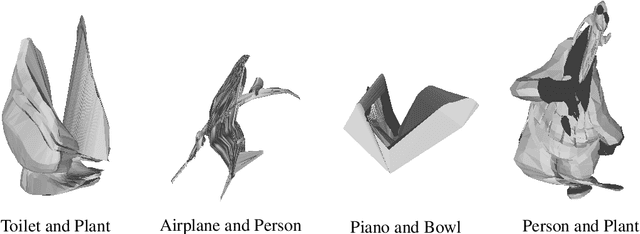
In order to generate novel 3D shapes with machine learning, one must allow for interpolation. The typical approach for incorporating this creative process is to interpolate in a learned latent space so as to avoid the problem of generating unrealistic instances by exploiting the model's learned structure. The process of the interpolation is supposed to form a semantically smooth morphing. While this approach is sound for synthesizing realistic media such as lifelike portraits or new designs for everyday objects, it subjectively fails to directly model the unexpected, unrealistic, or creative. In this work, we present a method for learning how to interpolate point clouds. By encoding prior knowledge about real-world objects, the intermediate forms are both realistic and unlike any existing forms. We show not only how this method can be used to generate "creative" point clouds, but how the method can also be leveraged to generate 3D models suitable for sculpture.
RotationOut as a Regularization Method for Neural Network
Nov 18, 2019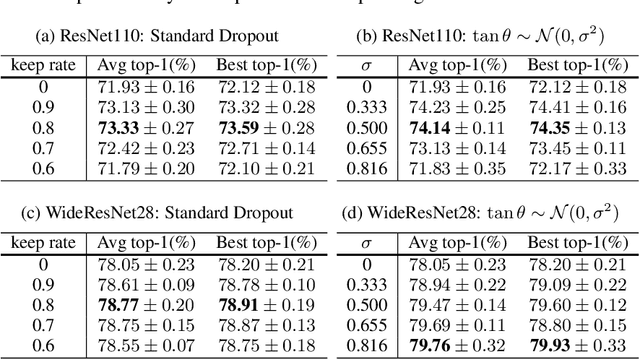
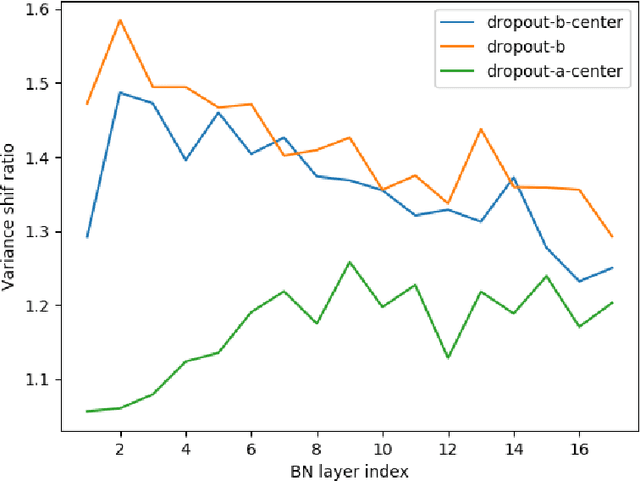
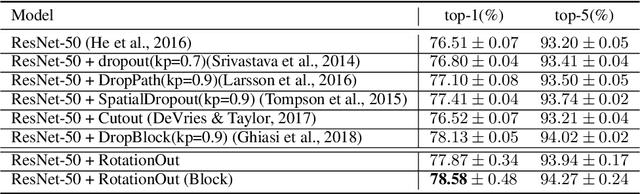

In this paper, we propose a novel regularization method, RotationOut, for neural networks. Different from Dropout that handles each neuron/channel independently, RotationOut regards its input layer as an entire vector and introduces regularization by randomly rotating the vector. RotationOut can also be used in convolutional layers and recurrent layers with small modifications. We further use a noise analysis method to interpret the difference between RotationOut and Dropout in co-adaptation reduction. Using this method, we also show how to use RotationOut/Dropout together with Batch Normalization. Extensive experiments in vision and language tasks are conducted to show the effectiveness of the proposed method. Codes are available at \url{https://github.com/RotationOut/RotationOut}.
Developing Creative AI to Generate Sculptural Objects
Aug 20, 2019

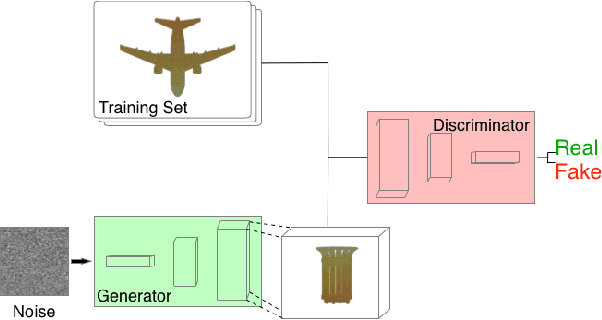
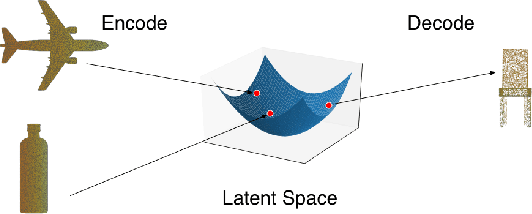
We explore the intersection of human and machine creativity by generating sculptural objects through machine learning. This research raises questions about both the technical details of automatic art generation and the interaction between AI and people, as both artists and the audience of art. We introduce two algorithms for generating 3D point clouds and then discuss their actualization as sculpture and incorporation into a holistic art installation. Specifically, the Amalgamated DeepDream (ADD) algorithm solves the sparsity problem caused by the naive DeepDream-inspired approach and generates creative and printable point clouds. The Partitioned DeepDream (PDD) algorithm further allows us to explore more diverse 3D object creation by combining point cloud clustering algorithms and ADD.
ChemBO: Bayesian Optimization of Small Organic Molecules with Synthesizable Recommendations
Aug 05, 2019

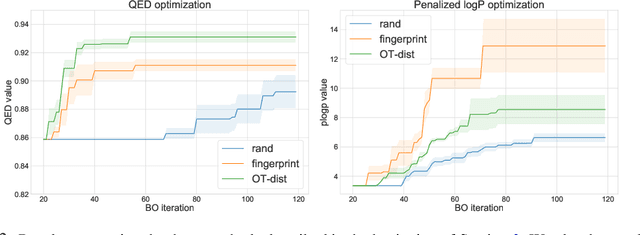
We describe ChemBO, a Bayesian Optimization framework for generating and optimizing organic molecules for desired molecular properties. This framework is useful in applications such as drug discovery, where an algorithm recommends new candidate molecules; these molecules first need to be synthesized and then tested for drug-like properties. The algorithm uses the results of past tests to recommend new ones so as to find good molecules efficiently. Most existing data-driven methods for this problem do not account for sample efficiency and/or fail to enforce realistic constraints on synthesizability. In this work, we explore existing kernels for molecules in the literature as well as propose a novel kernel which views a molecule as a graph. In ChemBO, we implement these kernels in a Gaussian process model. Then we explore the chemical space by traversing possible paths of molecular synthesis. Consequently, our approach provides a proposal synthesis path every time it recommends a new molecule to test, a crucial advantage when compared to existing methods. In our experiments, we demonstrate the efficacy of the proposed approach on several molecular optimization problems.