 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep FisherNet for Object Classification
Jul 31, 2016
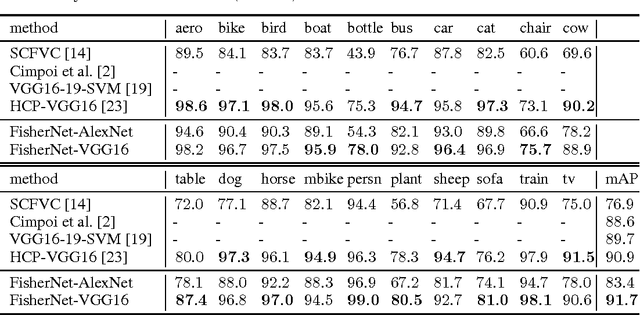
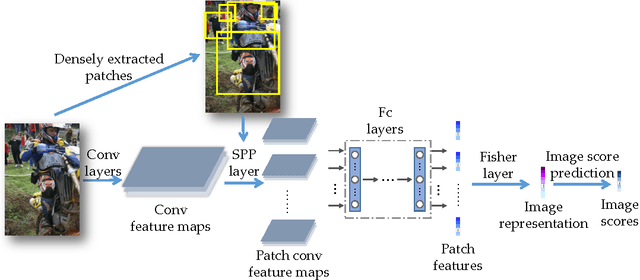
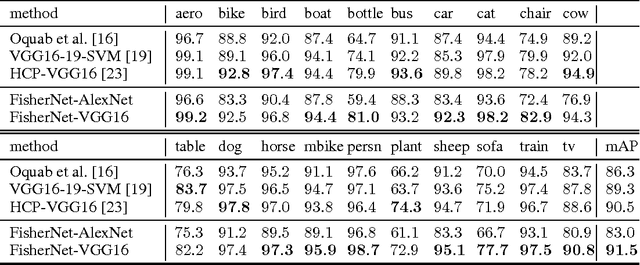
Despite the great success of convolutional neural networks (CNN) for the image classification task on datasets like Cifar and ImageNet, CNN's representation power is still somewhat limited in dealing with object images that have large variation in size and clutter, where Fisher Vector (FV) has shown to be an effective encoding strategy. FV encodes an image by aggregating local descriptors with a universal generative Gaussian Mixture Model (GMM). FV however has limited learning capability and its parameters are mostly fixed after constructing the codebook. To combine together the best of the two worlds, we propose in this paper a neural network structure with FV layer being part of an end-to-end trainable system that is differentiable; we name our network FisherNet that is learnable using backpropagation. Our proposed FisherNet combines convolutional neural network training and Fisher Vector encoding in a single end-to-end structure. We observe a clear advantage of FisherNet over plain CNN and standard FV in terms of both classification accuracy and computational efficiency on the challenging PASCAL VOC object classification task.
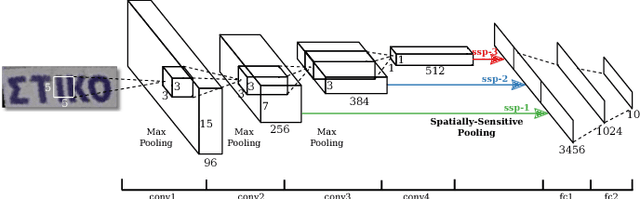
Robust Scene Text Recognition with Automatic Rectification
Apr 19, 2016
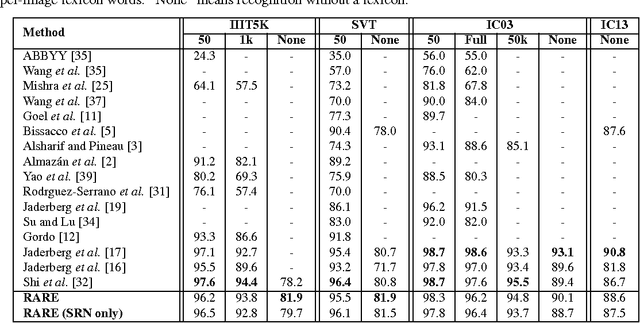
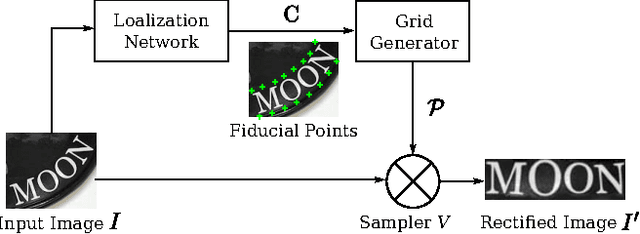
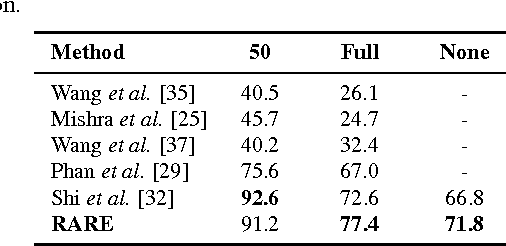
Recognizing text in natural images is a challenging task with many unsolved problems. Different from those in documents, words in natural images often possess irregular shapes, which are caused by perspective distortion, curved character placement, etc. We propose RARE (Robust text recognizer with Automatic REctification), a recognition model that is robust to irregular text. RARE is a specially-designed deep neural network, which consists of a Spatial Transformer Network (STN) and a Sequence Recognition Network (SRN). In testing, an image is firstly rectified via a predicted Thin-Plate-Spline (TPS) transformation, into a more "readable" image for the following SRN, which recognizes text through a sequence recognition approach. We show that the model is able to recognize several types of irregular text, including perspective text and curved text. RARE is end-to-end trainable, requiring only images and associated text labels, making it convenient to train and deploy the model in practical systems. State-of-the-art or highly-competitive performance achieved on several benchmarks well demonstrates the effectiveness of the proposed model.
An End-to-End Trainable Neural Network for Image-based Sequence Recognition and Its Application to Scene Text Recognition
Jul 21, 2015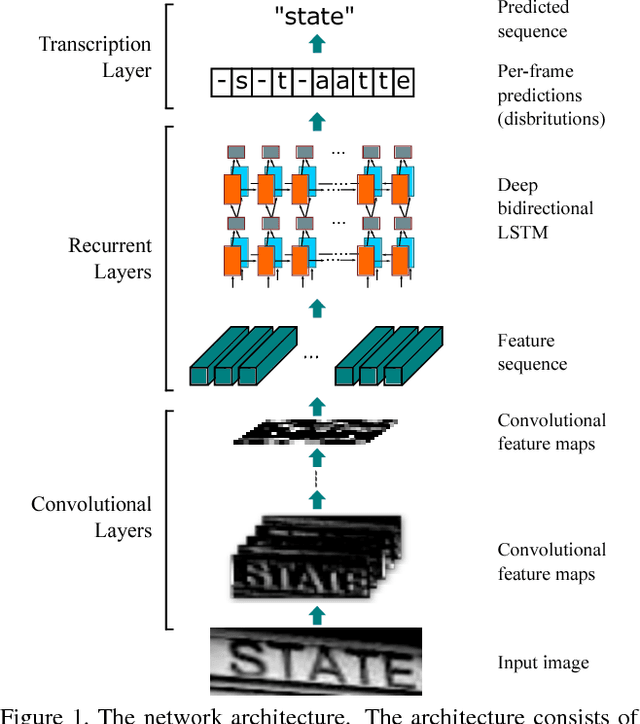
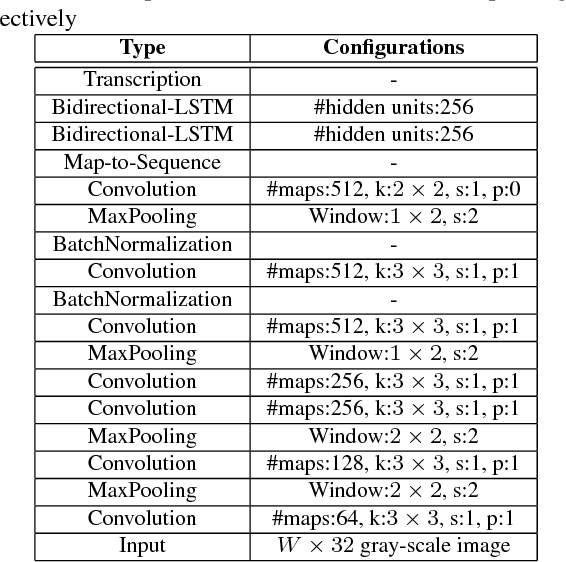
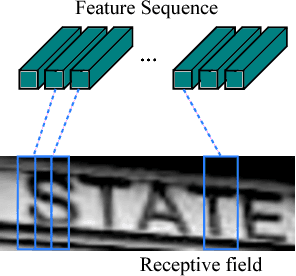
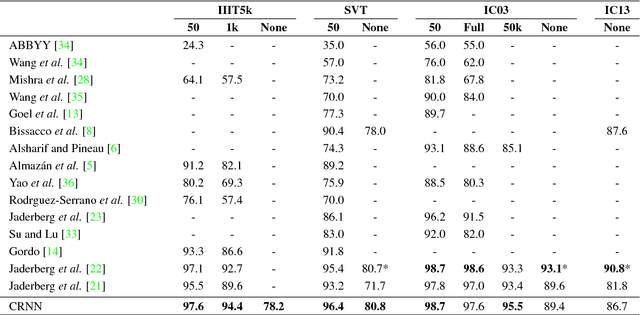
Image-based sequence recognition has been a long-standing research topic in computer vision. In this paper, we investigate the problem of scene text recognition, which is among the most important and challenging tasks in image-based sequence recognition. A novel neural network architecture, which integrates feature extraction, sequence modeling and transcription into a unified framework, is proposed. Compared with previous systems for scene text recognition, the proposed architecture possesses four distinctive properties: (1) It is end-to-end trainable, in contrast to most of the existing algorithms whose components are separately trained and tuned. (2) It naturally handles sequences in arbitrary lengths, involving no character segmentation or horizontal scale normalization. (3) It is not confined to any predefined lexicon and achieves remarkable performances in both lexicon-free and lexicon-based scene text recognition tasks. (4) It generates an effective yet much smaller model, which is more practical for real-world application scenarios. The experiments on standard benchmarks, including the IIIT-5K, Street View Text and ICDAR datasets, demonstrate the superiority of the proposed algorithm over the prior arts. Moreover, the proposed algorithm performs well in the task of image-based music score recognition, which evidently verifies the generality of it.
Automatic Script Identification in the Wild
May 12, 2015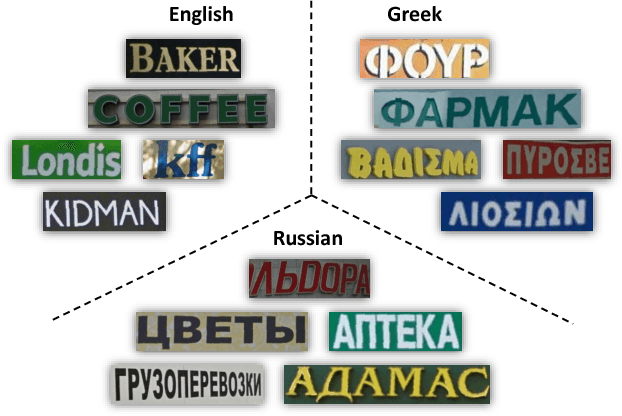


With the rapid increase of transnational communication and cooperation, people frequently encounter multilingual scenarios in various situations. In this paper, we are concerned with a relatively new problem: script identification at word or line levels in natural scenes. A large-scale dataset with a great quantity of natural images and 10 types of widely used languages is constructed and released. In allusion to the challenges in script identification in real-world scenarios, a deep learning based algorithm is proposed. The experiments on the proposed dataset demonstrate that our algorithm achieves superior performance, compared with conventional image classification methods, such as the original CNN architecture and LLC.
Deep Regression for Face Alignment
Sep 18, 2014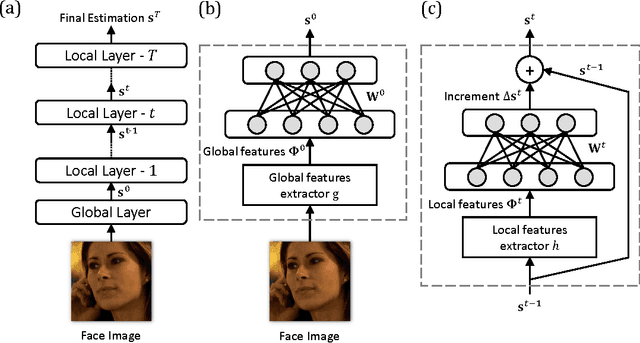
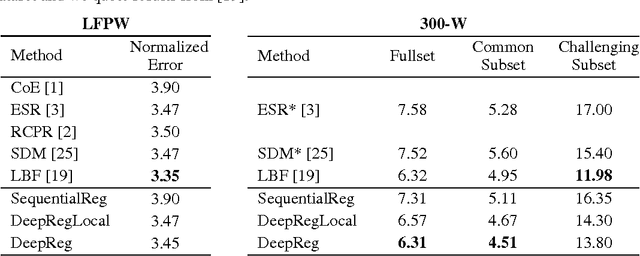
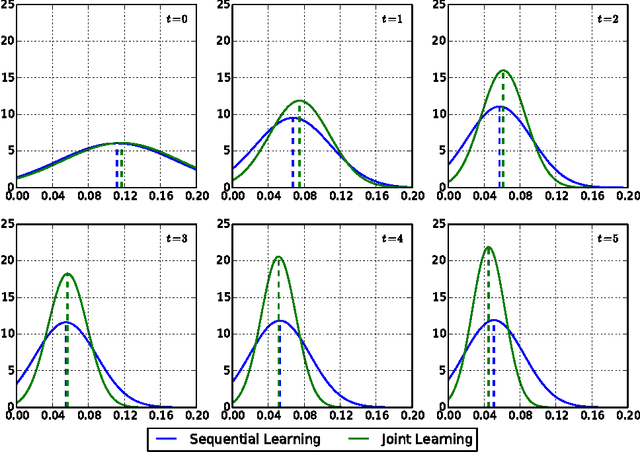

In this paper, we present a deep regression approach for face alignment. The deep architecture consists of a global layer and multi-stage local layers. We apply the back-propagation algorithm with the dropout strategy to jointly optimize the regression parameters. We show that the resulting deep regressor gradually and evenly approaches the true facial landmarks stage by stage, avoiding the tendency to yield over-strong early stage regressors while over-weak later stage regressors. Experimental results show that our approach achieves the state-of-the-art