 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMindCine: Multimodal EEG-to-Video Reconstruction with Large-Scale Pretrained Models
Jan 27, 2026Reconstructing human dynamic visual perception from electroencephalography (EEG) signals is of great research significance since EEG's non-invasiveness and high temporal resolution. However, EEG-to-video reconstruction remains challenging due to: 1) Single Modality: existing studies solely align EEG signals with the text modality, which ignores other modalities and are prone to suffer from overfitting problems; 2) Data Scarcity: current methods often have difficulty training to converge with limited EEG-video data. To solve the above problems, we propose a novel framework MindCine to achieve high-fidelity video reconstructions on limited data. We employ a multimodal joint learning strategy to incorporate beyond-text modalities in the training stage and leverage a pre-trained large EEG model to relieve the data scarcity issue for decoding semantic information, while a Seq2Seq model with causal attention is specifically designed for decoding perceptual information. Extensive experiments demonstrate that our model outperforms state-of-the-art methods both qualitatively and quantitatively. Additionally, the results underscore the effectiveness of the complementary strengths of different modalities and demonstrate that leveraging a large-scale EEG model can further enhance reconstruction performance by alleviating the challenges associated with limited data.
MindCross: Fast New Subject Adaptation with Limited Data for Cross-subject Video Reconstruction from Brain Signals
Nov 18, 2025



Reconstructing video from brain signals is an important brain decoding task. Existing brain decoding frameworks are primarily built on a subject-dependent paradigm, which requires large amounts of brain data for each subject. However, the expensive cost of collecting brain-video data causes severe data scarcity. Although some cross-subject methods being introduced, they often overfocus with subject-invariant information while neglecting subject-specific information, resulting in slow fine-tune-based adaptation strategy. To achieve fast and data-efficient new subject adaptation, we propose MindCross, a novel cross-subject framework. MindCross's N specific encoders and one shared encoder are designed to extract subject-specific and subject-invariant information, respectively. Additionally, a Top-K collaboration module is adopted to enhance new subject decoding with the knowledge learned from previous subjects' encoders. Extensive experiments on fMRI/EEG-to-video benchmarks demonstrate MindCross's efficacy and efficiency of cross-subject decoding and new subject adaptation using only one model.
NeuroLM: A Universal Multi-task Foundation Model for Bridging the Gap between Language and EEG Signals
Aug 27, 2024Recent advancements for large-scale pre-training with neural signals such as electroencephalogram (EEG) have shown promising results, significantly boosting the development of brain-computer interfaces (BCIs) and healthcare. However, these pre-trained models often require full fine-tuning on each downstream task to achieve substantial improvements, limiting their versatility and usability, and leading to considerable resource wastage. To tackle these challenges, we propose NeuroLM, the first multi-task foundation model that leverages the capabilities of Large Language Models (LLMs) by regarding EEG signals as a foreign language, endowing the model with multi-task learning and inference capabilities. Our approach begins with learning a text-aligned neural tokenizer through vector-quantized temporal-frequency prediction, which encodes EEG signals into discrete neural tokens. These EEG tokens, generated by the frozen vector-quantized (VQ) encoder, are then fed into an LLM that learns causal EEG information via multi-channel autoregression. Consequently, NeuroLM can understand both EEG and language modalities. Finally, multi-task instruction tuning adapts NeuroLM to various downstream tasks. We are the first to demonstrate that, by specific incorporation with LLMs, NeuroLM unifies diverse EEG tasks within a single model through instruction tuning. The largest variant NeuroLM-XL has record-breaking 1.7B parameters for EEG signal processing, and is pre-trained on a large-scale corpus comprising approximately 25,000-hour EEG data. When evaluated on six diverse downstream datasets, NeuroLM showcases the huge potential of this multi-task learning paradigm.
BatGPT-Chem: A Foundation Large Model For Retrosynthesis Prediction
Aug 19, 2024



Retrosynthesis analysis is pivotal yet challenging in drug discovery and organic chemistry. Despite the proliferation of computational tools over the past decade, AI-based systems often fall short in generalizing across diverse reaction types and exploring alternative synthetic pathways. This paper presents BatGPT-Chem, a large language model with 15 billion parameters, tailored for enhanced retrosynthesis prediction. Integrating chemical tasks via a unified framework of natural language and SMILES notation, this approach synthesizes extensive instructional data from an expansive chemical database. Employing both autoregressive and bidirectional training techniques across over one hundred million instances, BatGPT-Chem captures a broad spectrum of chemical knowledge, enabling precise prediction of reaction conditions and exhibiting strong zero-shot capabilities. Superior to existing AI methods, our model demonstrates significant advancements in generating effective strategies for complex molecules, as validated by stringent benchmark tests. BatGPT-Chem not only boosts the efficiency and creativity of retrosynthetic analysis but also establishes a new standard for computational tools in synthetic design. This development empowers chemists to adeptly address the synthesis of novel compounds, potentially expediting the innovation cycle in drug manufacturing and materials science. We release our trial platform at \url{https://www.batgpt.net/dapp/chem}.
Large Brain Model for Learning Generic Representations with Tremendous EEG Data in BCI
May 29, 2024The current electroencephalogram (EEG) based deep learning models are typically designed for specific datasets and applications in brain-computer interaction (BCI), limiting the scale of the models and thus diminishing their perceptual capabilities and generalizability. Recently, Large Language Models (LLMs) have achieved unprecedented success in text processing, prompting us to explore the capabilities of Large EEG Models (LEMs). We hope that LEMs can break through the limitations of different task types of EEG datasets, and obtain universal perceptual capabilities of EEG signals through unsupervised pre-training. Then the models can be fine-tuned for different downstream tasks. However, compared to text data, the volume of EEG datasets is generally small and the format varies widely. For example, there can be mismatched numbers of electrodes, unequal length data samples, varied task designs, and low signal-to-noise ratio. To overcome these challenges, we propose a unified foundation model for EEG called Large Brain Model (LaBraM). LaBraM enables cross-dataset learning by segmenting the EEG signals into EEG channel patches. Vector-quantized neural spectrum prediction is used to train a semantically rich neural tokenizer that encodes continuous raw EEG channel patches into compact neural codes. We then pre-train neural Transformers by predicting the original neural codes for the masked EEG channel patches. The LaBraMs were pre-trained on about 2,500 hours of various types of EEG signals from around 20 datasets and validated on multiple different types of downstream tasks. Experiments on abnormal detection, event type classification, emotion recognition, and gait prediction show that our LaBraM outperforms all compared SOTA methods in their respective fields. Our code is available at https://github.com/935963004/LaBraM.
Seeing through the Brain: Image Reconstruction of Visual Perception from Human Brain Signals
Aug 16, 2023



Seeing is believing, however, the underlying mechanism of how human visual perceptions are intertwined with our cognitions is still a mystery. Thanks to the recent advances in both neuroscience and artificial intelligence, we have been able to record the visually evoked brain activities and mimic the visual perception ability through computational approaches. In this paper, we pay attention to visual stimuli reconstruction by reconstructing the observed images based on portably accessible brain signals, i.e., electroencephalography (EEG) data. Since EEG signals are dynamic in the time-series format and are notorious to be noisy, processing and extracting useful information requires more dedicated efforts; In this paper, we propose a comprehensive pipeline, named NeuroImagen, for reconstructing visual stimuli images from EEG signals. Specifically, we incorporate a novel multi-level perceptual information decoding to draw multi-grained outputs from the given EEG data. A latent diffusion model will then leverage the extracted information to reconstruct the high-resolution visual stimuli images. The experimental results have illustrated the effectiveness of image reconstruction and superior quantitative performance of our proposed method.
Towards Scale-Invariant Graph-related Problem Solving by Iterative Homogeneous Graph Neural Networks
Oct 26, 2020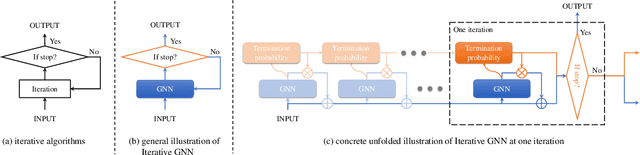
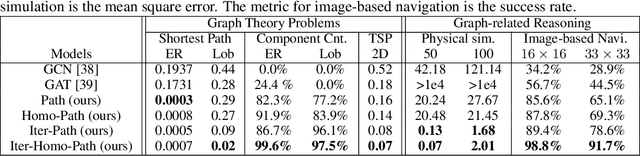
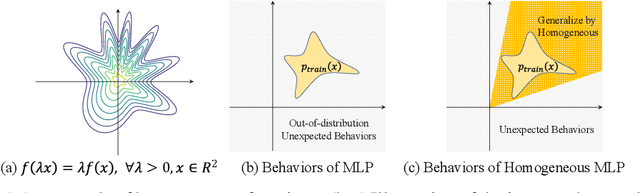

Current graph neural networks (GNNs) lack generalizability with respect to scales (graph sizes, graph diameters, edge weights, etc..) when solving many graph analysis problems. Taking the perspective of synthesizing graph theory programs, we propose several extensions to address the issue. First, inspired by the dependency of the iteration number of common graph theory algorithms on graph size, we learn to terminate the message passing process in GNNs adaptively according to the computation progress. Second, inspired by the fact that many graph theory algorithms are homogeneous with respect to graph weights, we introduce homogeneous transformation layers that are universal homogeneous function approximators, to convert ordinary GNNs to be homogeneous. Experimentally, we show that our GNN can be trained from small-scale graphs but generalize well to large-scale graphs for a number of basic graph theory problems. It also shows generalizability for applications of multi-body physical simulation and image-based navigation problems.
Document-level Neural Machine Translation with Document Embeddings
Sep 16, 2020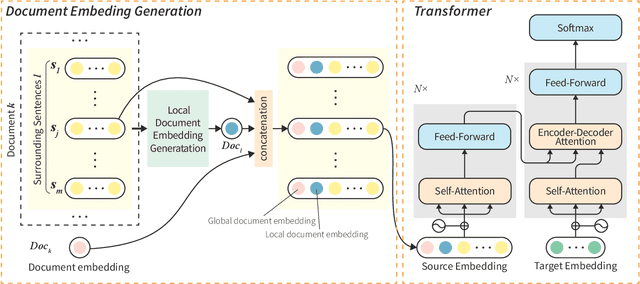
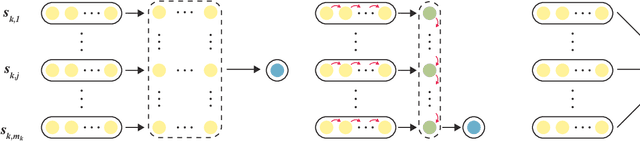
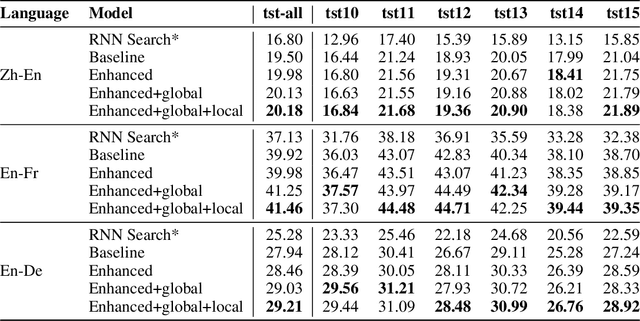
Standard neural machine translation (NMT) is on the assumption of document-level context independent. Most existing document-level NMT methods are satisfied with a smattering sense of brief document-level information, while this work focuses on exploiting detailed document-level context in terms of multiple forms of document embeddings, which is capable of sufficiently modeling deeper and richer document-level context. The proposed document-aware NMT is implemented to enhance the Transformer baseline by introducing both global and local document-level clues on the source end. Experiments show that the proposed method significantly improves the translation performance over strong baselines and other related studies.
Data Augmentation for Enhancing EEG-based Emotion Recognition with Deep Generative Models
Jun 17, 2020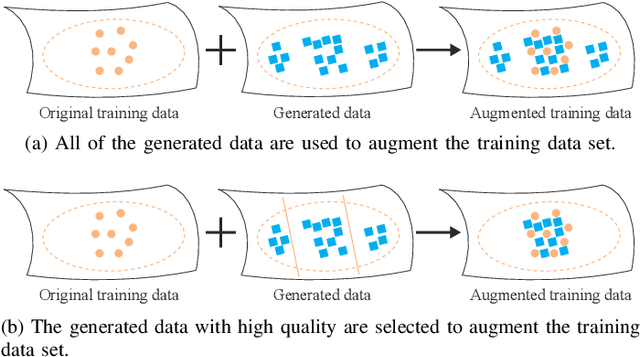
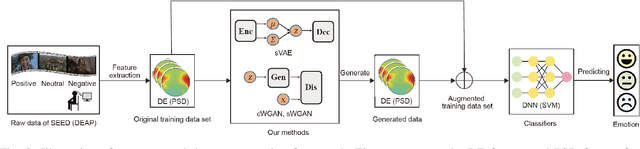
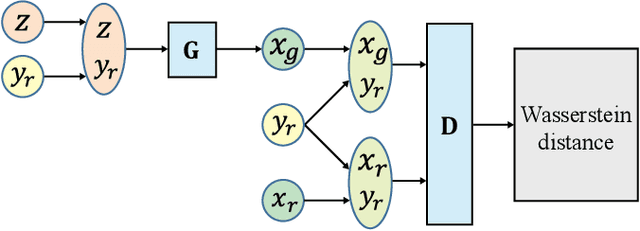

The data scarcity problem in emotion recognition from electroencephalography (EEG) leads to difficulty in building an affective model with high accuracy using machine learning algorithms or deep neural networks. Inspired by emerging deep generative models, we propose three methods for augmenting EEG training data to enhance the performance of emotion recognition models. Our proposed methods are based on two deep generative models, variational autoencoder (VAE) and generative adversarial network (GAN), and two data augmentation strategies. For the full usage strategy, all of the generated data are augmented to the training dataset without judging the quality of the generated data, while for partial usage, only high-quality data are selected and appended to the training dataset. These three methods are called conditional Wasserstein GAN (cWGAN), selective VAE (sVAE), and selective WGAN (sWGAN). To evaluate the effectiveness of these methods, we perform a systematic experimental study on two public EEG datasets for emotion recognition, namely, SEED and DEAP. We first generate realistic-like EEG training data in two forms: power spectral density and differential entropy. Then, we augment the original training datasets with a different number of generated realistic-like EEG data. Finally, we train support vector machines and deep neural networks with shortcut layers to build affective models using the original and augmented training datasets. The experimental results demonstrate that the augmented training datasets produced by our methods enhance the performance of EEG-based emotion recognition models and outperform the existing data augmentation methods such as conditional VAE, Gaussian noise, and rotational data augmentation.
Transfer Learning for EEG-Based Brain-Computer Interfaces: A Review of Progress Made Since 2016
May 06, 2020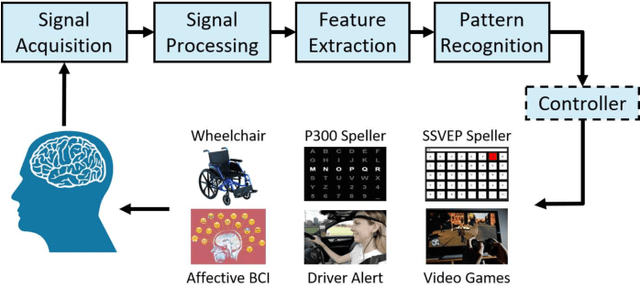
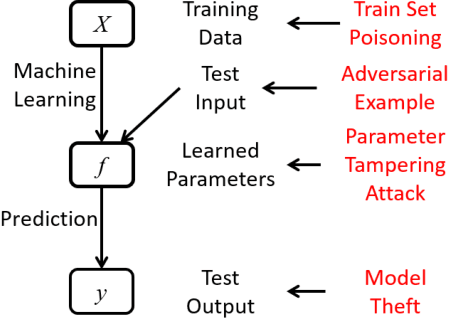
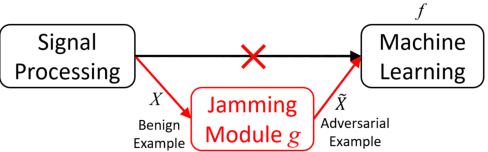

A brain-computer interface (BCI) enables a user to communicate with a computer directly using brain signals. Electroencephalograms (EEGs) used in BCIs are weak, easily contaminated by interference and noise, non-stationary for the same subject, and varying across different subjects and sessions. Therefore, it is difficult to build a generic pattern recognition model in an EEG-based BCI system that is optimal for different subjects, during different sessions, for different devices and tasks. Usually, a calibration session is needed to collect some training data for a new subject, which is time consuming and user unfriendly. Transfer learning (TL), which utilizes data or knowledge from similar or relevant subjects/sessions/devices/tasks to facilitate learning for a new subject/session/device/task, is frequently used to reduce the amount of calibration effort. This paper reviews journal publications on TL approaches in EEG-based BCIs in the last few years, i.e., since 2016. Six paradigms and applications -- motor imagery, event-related potentials, steady-state visual evoked potentials, affective BCIs, regression problems, and adversarial attacks -- are considered. For each paradigm/application, we group the TL approaches into cross-subject/session, cross-device, and cross-task settings and review them separately. Observations and conclusions are made at the end of the paper, which may point to future research directions.